Retired Document
Important: This document does not describe current best practices, and is provided for support of existing apps only. New apps should adopt Cocoa or Core Text. See Core Text Programming Guide for information on Core Text.
Introduction to Programming With the Text Encoding Conversion Manager
This chapter introduces the Text Encoding Conversion Manager. As a prelude, it explains why text encoding conversion is necessary. Then it describes the Text Encoding Conversion Manager’s two main components—the Text Encoding Converter and the Unicode Converter—suggesting why you should choose one over the other for your conversion processes. The remainder of the chapter explores some of the terms and concepts that pervade text encoding and the process of converting from one encoding to another, including
Characters, codes, coded character sets, and character encoding schemes
Text representation and text elements
Text encoding specifications
Unicode, in the context of its emergence as a solution to text encoding complexities
Round-trip fidelity, strict and loose mapping, Corporate Use Zone mappings, and fallback mappings
Finally, the chapter highlights the Text Encoding Conversion Manager package contents and gives a terse history of its past releases.
You should read this chapter if you are developing
Internet-savvy applications, such as web browsers or e-mail applications.
Applications that transfer text across platforms.
Applications based in Unicode, such as a word processor or file system that operates in Unicode.
You can find descriptions of the basic text types for specifying text encodings and other aspects of conversion, the Text Encoding Converter, and the Unicode Converter in the following reference documents:
Text Encoding Conversion Manager Reference
The reference documents are meant to be used as you develop your applications. You can consult the descriptions of data structures and functions to gain a high-level understanding of how to use the converters.
For general information about how the Mac OS handles text, see Handling Unicode Text Editing With MLTE.
Why You Need to Convert Text From One Encoding to Another
This section explains in broad terms why you need to convert text from one encoding used to represent the text to another, and uses terminology fundamental to the text encoding conversion process. These terms and the concepts they represent are explored in depth later in Character Encoding and Other Concepts Fundamental to Text Encoding Conversion and in Character Encoding Concepts In-Depth.
Central to any discussion of text encoding and text encoding conversion is the concept of a character, which is an abstract unit of text context. Characters are often identified with or confused with one or more of the following concepts, but it is important to keep the notion of an abstract character separate from these concepts:
A graphic representation corresponding to a character (this graphic representation is what most people think of as the character)
A key or key sequence used to input a character
A number or number sequence used in a computer system to represent a character
In this document we are concerned primarily with abstract characters and with their numeric representation in a computer system. In order to represent textual characters in a file or in a computer’s memory, some sort of mapping must be used to assign numeric values to the textual characters. The mapping can vary depending on the character set, which may depend on the language being used and other factors.
For example, in the ASCII character set, the character A is represented by the value 65, B is represented by 66, and so on. Because ASCII has 128 characters, 7 bits is enough to represent any member of the set (7-bit ASCII characters are usually stored in 8-bit bytes). Each integer value represented by a bit combination is called a code point. (The terms bit combination and code point are further explained in Character Encoding and Other Concepts Fundamental to Text Encoding Conversion.) Larger character sets, such as the Japanese Kanji set, must use more bytes to represent each of their members.
Interpretive problems can occur if a computer attempts to read data that was encoded using a mapping different from what it expects. The other mapping might contain similar characters mapped in a different order, different characters altogether, or the characters may be specially encoded for data transmission. To handle text correctly in these and other similar cases, some method of identifying the various mappings and converting between them is necessary. Text encoding conversion addresses these problems and requirements.
Here are two examples of the many cases for which text conversion is necessary:
A Mac OS computer receives text in asynchronous packets over the Internet from a remote server. The Mac OS expects text to use the Mac OS Arabic character set, while the server uses the ISO 8859-6 standard.
A Mac OS application attempts to read a text file created on a Windows 95 computer. The Mac OS application expects text to use the Mac OS Roman character set, while the Windows 95 file uses the Windows Latin-1 character set.
Deciding Which Encoding Converter to Use
The Text Encoding Conversion Manager provides two converters—the Text Encoding Converter and the Unicode Converter—that you can use to handle text encoding conversion on the Mac OS.
The Text Encoding Converter is the primary converter for converting between different text encodings. It was designed to address most of your conversion requirements, and you should use it for most cases. You can use it to convert from one supported encoding to another. When you use the Text Encoding Converter, neither the source encoding nor the destination one must be Unicode, although they can be.
The Unicode Converter can convert most non-Unicode encodings to or from the no-subset variant of Unicode in either the UTF-16 or UTF-8 formats. For example, it can convert directly from Windows Latin-1 to UTF-8. It can also convert Mac encodings, most CJK encodings, and Latin-1 to or from the HFS+ decomposed variant of Unicode in either the UTF-16 or UTF-8 formats. Finally, it can convert the no-subset variant of Unicode (in either the UTF-16 or UTF-8 formats) to any of the normalized variants of Unicode in the UTF16 format.
You might want to use the Unicode Converter if you are writing applications based in Unicode, such as a word processor or file system that operates in Unicode. Even when your application is not Unicode based, you might want to use the Unicode Converter for special cases where you want to control the conversion behavior more closely. The Unicode Converter is also the better choice if you want to map offsets for style run boundaries for styled text; the Text Encoding Converter does not offer this service.
The Text Encoding Converter
The Text Encoding Converter uses plug-ins, which are code fragments containing the information required to perform a conversion. A plug-in can handle one or more types of conversions. Plug-ins are the true conversion engines. The Text Encoding Converter provides a uniform conversion protocol, but includes no implementation for any specific kind of conversion. In other words, it supplies a generic framework for conversion but does none of the conversion work itself; rather, the plug-ins perform the actual conversions.
This section looks briefly at plug-ins while Writing Custom Plug-Ins describes them in greater detail.
When you launch your application, the Text Encoding Converter scans the system in search of available plug-ins. The Text Encoding Converter includes many predefined plug-ins—the Unicode converter is one of them—but you can also write and provide your own.
The Text Encoding Converter examines available plug-ins to determine which one or more to use to establish the most direct conversion path. Plug-ins can handle algorithmic conversions such as conversion from JIS to Shift-JIS. (Algorithmic conversions are different from conversion processes that use mapping tables. Mapping tables, which the Unicode Converter uses exclusively, are explained later.) Plug-ins can also handle code-switching schemes such as ISO 2022.
If a plug-in exists for the exact conversion required, then the Text Encoding Converter calls that plug-in’s conversion function to convert the text. Such a one-step conversion is called a direct conversion. Otherwise, the Text Encoding Converter attempts an indirect conversion by finding two or more plug-ins that can be used in succession to perform the required translation. In such cases, the Unicode Converter might be treated as a plug-in.
For example, Figure I-1 shows a conversion path from encoding X to encoding Y that uses both the Unicode Converter and another plug-in. The Unicode Converter converts encoding X to Unicode, then it converts the Unicode text to text in encoding Z. The other plug-in converts the text from encoding Z to encoding Y.
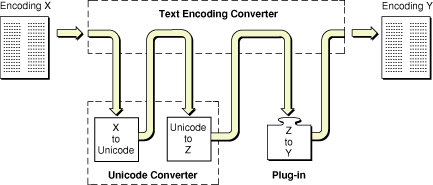
In general, you do not need to be concerned about the conversion path taken by the Text Encoding Converter; it is resolved automatically. However, if you want to explicitly specify the conversion path, there are functions you can call to do so.
When you use the Text Encoding Converter, you specify the source and destination encodings for the text. To convert text, you must create a converter object. This object describes the conversion path required to perform the text conversion. You can also create a converter object to handle multiple encoding runs. If the requisite plug-ins are available, the Text Encoding Converter can convert text from any encoding to runs of any other encodings.
When handling code-switching schemes, the Text Encoding Converter automatically maintains state information that identifies the current encoding in the converter object. Any escape sequences, control characters, and other information pertaining to state changes in the converter object are also detected and generated as necessary.
Because each converter object can maintain state information, you can use the same converter object to convert multiple segments of a single text stream. For example, suppose you receive text containing 2-byte characters in packets over a network. If the end of a packet transmission splits a character—that is, only 1 of the 2 bytes is received—the converter object does not attempt to convert the character until it receives the second byte.
In some cases, you may not be able to determine the encoding used to express text you receive from an unknown source, such as text delivered over the Internet. To minimize the amount of guesswork required to successfully convert such text, the Text Encoding Converter allows the use of sniffers. Sniffers are to text encodings what protocol analyzers are to networking protocols. They analyze the text and provide a list of the most probable encodings used to express it. Several sniffers are provided; you can also write your own sniffers when creating text conversion plug-ins.
The Unicode Converter
This section describes the Unicode Converter, which you can use to convert between any available non-Unicode text encoding and the various, supported implementations of Unicode. For background information on Unicode, the problems it addresses, and the standards bodies responsible for its emergence, see About Unicode and Character Encoding Concepts In-Depth. For definition of some of the terms used in this section, see Character Encoding and Other Concepts Fundamental to Text Encoding Conversion.
The Unicode Converter does not itself incorporate any knowledge of the specifics of any text encoding. Instead, it uses loadable, replaceable mapping tables that provide the information about any text encoding required to perform the conversion.
All information about a particular coded character set used in a text encoding is incorporated in a mapping table. A mapping table associates coded representations of characters belonging to one coded character set with their equivalent representations in another and accounts for the various conditions that arise when coded representations of characters cannot be directly mapped to each other.
The Unicode Converter can also handle conversions between Unicode and text encodings that use a packing scheme.
To convert text using the Unicode Converter, you must create a Unicode converter object, which references the necessary mapping tables and maintains state information. Because each Unicode converter object is discrete, you can retain several objects concurrently within your application, one for each type of conversion you need to make.
The Unicode Converter supports multiple encoding runs. An encoding run is a continuous sequence of text all of which is expressed in the same text encoding; a given string might contain multiple encoding runs, such as a sequence of text in Mac OS Roman encoding followed by a sequence in Mac OS Arabic. The Unicode Converter allows you to convert a single block of Unicode text to multiple runs in other text encodings. For example, you could convert a Unicode string into one that contains both Mac OS Arabic and Mac OS Roman encodings. You might find this useful when preparing text to display using the Script Manager.
Character Encoding and Other Concepts Fundamental to Text Encoding Conversion
In considering how text is converted from one encoding to another, it is useful to understand what constitutes coded character sets and character encoding schemes. To do so, it is helpful to have a set of terms that describe the discrete entities comprising a coded character set, a character encoding scheme, and their underlying concepts.
This section explores characters and character repertoires, coded character sets and code points, presentation forms, and character encoding schemes. For a more complete treatment of these and other concepts such as packing schemes, multiple character sets, and code-switching schemes for multiple character sets, see Character Encoding Concepts In-Depth.
Characters
A person using a writing system thinks of a character in terms of its visual form, its written structure and its meaning in conjunction with other characters. A computer, on the other hand, deals with characters primarily in terms of their numeric encodings.
A character is a unit of information used for the organization, control, or representation of text data. Letters, ideographs, digits, and symbols in a writing system are all examples of characters. A character is associated with a name, and optionally, but commonly, with a representative image or rendering called a glyph. Glyph images are the visual elements used to represent characters. Aspects of text presentation such as font and style apply to glyph images, not to characters.
A character repertoire is a collection of distinct characters. Two characters are distinct if and only if they have distinct names in the context of an identified character repertoire. Two characters that are distinct in name may have identical images or renderings (for example, LATIN CAPITAL LETTER A and GREEK CAPITAL LETTER ALPHA). Characters constituting a character repertoire can belong to different scripts.
Coded Character Sets
A coded character set comprises a mapping from a set of abstract characters (that is, the character repertoire) to a set of integers. The integers in the set are within a range that can be expressed by a bit pattern of a particular size: 7 bits, 8 bits, 16 bits, and so on. Each of the integers in the set is called a code point. The set of integers may be larger than the character repertoire; that is, there may be “unassigned” code points that do not correspond to any character in the repertoire. Examples of coded character sets include
ASCII, a fixed-width 7-bit encoding
ISO 8859-1 (Latin-1), a fixed-width 8-bit encoding
JIS X0208, a Japanese standard whose code points are fixed–width 14-bit values (normally represented as a pair of 7-bit values). Many other standards for East Asian languages follow a similar pattern, using code points represented as two or three 7-bit values. These standards are typically not used directly, but are used in one of the character encoding schemes discussed in Character Encoding Schemes.
Presentation Forms
The term presentation form is generally used to mean a kind of abstract shape that represents a standard way to display a character or group of characters in a particular context as specified by a particular writing system. The term glyph by itself may refer to either presentation forms or to glyph images. Examples of characters with multiple presentation forms include
Arabic characters that vary in appearance depending on the characters surrounding them
Latin or Arabic ligatures, which are single forms that represent a sequence of characters
Japanese kana and CJK punctuation characters, which vary in appearance depending on whether they are to be displayed horizontally or vertically
Katakana full-width and half-width variants
A coded character set may encode presentation forms instead of or in addition to its basic characters.
Character Encoding Schemes
A character encoding scheme is a mapping from a sequence of elements in one or more coded character sets to a sequence of bytes. A character encoding scheme can include coded character sets, but it can also include more complex mapping schemes that combine multiple coded character sets, typically in one of the following ways:
Packing schemes use a sequence of 8-bit values to encode text. Because of this, they are generally not suitable for electronic mail. In these schemes, certain characters function as a local shift, which controls the interpretation of the next 1 to 3 bytes. The most well known example is Shift-JIS, which includes characters from JIS X0201, JIS X0208, and space for 2444 user-defined characters. The EUC (Extended UNIX Coding) packing schemes were originally developed for UNIX systems; they use units of 1 to 4 bytes. (Appendix B describes Shift-JIS, EUC, and other packing schemes, in detail.) Packing schemes are often used for the World Wide Web, which can handle 8-bit values. Both the Text Encoding Converter and the Unicode Converter support packing schemes.
Code-switching schemes typically use a sequence of 7-bit values to encode text, so they are suitable for electronic mail. Escape sequences or other special sequences are used to signal a shift among the included character sets. Examples include the ISO 2022 family of encodings (such as ISO 2022-JP), and the HZ encoding used for Chinese. Code switching schemes are often used for Internet mail and news, which cannot handle 8-bit values. The Text Encoding Converter can handle code-switching schemes, but the Unicode Converter cannot.
A character encoding scheme may also be used to convert a single coded character set into a form that is easier for certain systems to handle. For example, the Unicode standard defines two universal transformation formats that permit the use of Unicode on systems that make assumptions about certain byte values in text data. The two universal transformation formats are UTF-7 and UTF-8. The Text Encoding Converter can handle both formats, but the Unicode Converter can only handle the UTF-8 format.
Many Internet protocols allow you to specify a “charset” parameter, which is designed to indicate the character encoding scheme for text.
A transfer encoding syntax (also called “content transfer encoding”) is a transformation applied to text encoded using a character encoding scheme to allow it to be transmitted by a specific protocol or set of protocols. Examples include “quoted-printable” and “base64”. Such a transformation is typically needed to allow 8-bit values to be sent through a channel that can handle only 7-bit values, and may even handle some 7-bit values in special ways. The Text Encoding Conversion Manager does not currently handle transfer encoding syntax.
Text Encoding Specifications
One of the primary data types used by both the Text Encoding Converter and the Unicode Converter is a text encoding specification. This section highlights the text encoding specification. Inside Mac OS X: Text Encoding Converter Manager Reference describes it fully, including its three components, and the values you specify for them.
A text encoding specification is a set of numeric codes used to identify a text encoding, which may be simple coded character set or a character encoding scheme. It contains these three parts that specify the text encoding: the text encoding base, the text encoding variant, and the text encoding format. You use two text encoding specifications—one for the source encoding of the text and one for its the destination encoding—when you call the Text Encoding Converter or the Unicode Converter to convert text.
The text encoding base value is the primary specification of the source or target encoding. The text encoding variant specifies one among possibly several minor variants of a particular base encoding or group of base encodings. A text encoding format specifies a way of formatting or algorithmically transforming a particular base encoding. (UTF-7 format is the Unicode standard formatted for transmission through channels that can handle only 7-bit values.)
Unicode and the Complexities of Conversion
This section looks briefly at Unicode, its emergence in response to the problems it addresses, and the standards bodies who sponsor it. Then it discusses some of the complexities involved in converting text between various encodings when conversion exceeds the simplicity of a one-to-one mapping. The section discusses these concepts in the context of how the Unicode Converter handles them.
About Unicode
Most character sets and character encoding schemes developed in the past are limited in their coverage, usually supporting just one language or a small set of languages. In addition, character encoding schemes are often complex, usually involving byte values whose interpretation depends on preceding byte values. Multilingual software has traditionally had to implement methods for supporting and identifying multiple character encodings.
A simpler solution is to combine the characters for all commonly used languages and symbols into a single universal coded character set. Unicode is such a universal coded character set, and offers the simplest solution to the problem of text representation in multilingual systems. Because Unicode also contains a wide assortment of technical, typographic, and other symbols, it offers advantages even to developers of applications that only handle a single language. Unicode provides more representational power than any other single character set or encoding scheme. However, because Unicode is a single coded character set, it doesn’t require the use of escape sequences or other complexities to identify transitions between coded character sets.
Because Unicode includes the character repertoires of most common character encodings, it facilitates data interchange with other platforms. Using Unicode, text manipulated by your application and shared across applications and platforms can be encoded in a single coded character set; this text can also be easily localized.
Unicode provides some special features, such as combining or nonspacing marks and conjoining jamos. These features are a function of the variety of languages that Unicode handles. If you have coded applications that handle text for the languages these features support, they should be familiar to you. If you have used a single coded character set such as ASCII almost exclusively, these features will be new to you.
The following two bodies, involved in the effort to standardize the world’s languages for use in computing, define Unicode standards:
The Unicode Consortium, a technical committee composed of representatives from many different companies, publishes the Unicode standard. Version 2.0 of the Unicode Standard was published in July 1996. However, the standard is evolving constantly, and updates are posted at the Unicode Consortium Web site:.
ISO (the International Organization for Standardization) and the IEC (the International Electrotechnical Commission), two of the international bodies active in character encoding standards, publish ISO/IEC 10646. This standard specifies the Universal Multiple-Octet Coded Character Set (UCS), a standard whose code point assignments are identical with Unicode.
ISO/IEC 10646
The ISO/IEC 10646 standard defines two alternative forms of encoding:
a 32-bit encoding, which is the canonical form. The 32-bit form is referred to as UCS-4 (Universal Character Set containing 4 bytes)
a 16-bit form that is referred to as UCS-2
The ISO/IEC 10646 nomenclature refers to coded characters as multiples of octets, while the Unicode nomenclature refers to coded characters as indivisible 16-bit entities. The Unicode standard does not include the UCS-4 format.
Round-Trip Fidelity
When the Unicode Converter is able to convert a text string expressed in one text encoding to Unicode and back again to the original text encoding, with the final text string matching exactly the source text string—that is, without incurring any changes to the original—round-trip fidelity has been achieved.
For certain national and international standards that the Unicode Consortium used as sources for the Unicode coded character set, Unicode provides round-trip fidelity. Because the repertoires of those coded character sets have been effectively incorporated into the Unicode coded character set, conversion involving them will always produce round-trip fidelity. Text in one of those coded character sets can be mapped to Unicode and back again with no loss of information. Coded characters that were distinct in the source encoding will be distinct in Unicode.
However, perfect round-trip conversion is not always possible. Many character encodings include characters that do not have distinct representations in Unicode, or which may have no representation at all. For example, a source text string from a vendor coded character set might contain a ligature that is not represented in Unicode. In this case, that information may be lost during the round trip.
The Unicode Converter uses a variety of conventional methods to attempt to find some way to map the source coded representation of a character onto a sequence of Unicode coded representations in such a way as to preserve its identity and interchangeability.
Here are some of the methods used to map code representations of characters when high fidelity achieved through an exact or strict mapping is not possible:
loose mapping
fallback mapping
mapping of characters to the Corporate Use Zone
Multiple Semantics and Multiple Representations
In many character encodings, certain characters may have multiple semantics, either by explicit definition, ambiguous definition, or established usage.
For example, the JIS X0208 standard specifies the JIS X0208 character 0x2142 as having two meanings: double vertical line and parallel to. Each meaning corresponds to a distinct Unicode code representation. The meaning “double vertical line” corresponds to the Unicode coded representation U+2016 “DOUBLE VERTICAL LINE”. The meaning “parallel to” corresponds to the Unicode coded representation U+2225 “PARALLEL TO”. Either one is a valid match for the JIS character.
Multiple representation exists when an encoding provides more than one way of representing a particular element of text. For example, in Unicode the text element consisting of an ‘a’ with acute accent can be represented using either the single character LATIN SMALL LETTER A WITH ACUTE or the sequence LATIN SMALL LETTER A plus COMBINING ACUTE ACCENT. The presentation forms encoded in Unicode can also be represented using coded representations for the abstract forms, and this also constitutes a condition of multiple representation.
Strict and Loose Mapping
A strict mapping preserves the information content of text and permits round-trip fidelity. A loose mapping preserves the information content of text but does not permit round-trip fidelity. A mapping table has both strict equivalence and loose mapping sections that identify how a mapping is to occur. Loose and strict mappings occur within the context of multiple semantics and multiple representations.
First, an example that illustrates the difference in the case of multiple semantics. The ASCII character at 0x2D is called HYPHEN-MINUS. Unicode includes a HYPHEN-MINUS character at U+002D for ASCII compatibility. However, Unicode also has separate characters HYPHEN (U+2010) and MINUS SIGN (U+2212); each of these characters represents one aspect of the meaning of HYPHEN-MINUS.
The ASCII character HYPHEN-MINUS is typically mapped to Unicode HYPHEN-MINUS. All three of the Unicode characters—HYPHEN-MINUS, HYPHEN, and MINUS SIGN—should typically be mapped to ASCII HYPHEN-MINUS, since it includes all of their meanings. The mapping from Unicode HYPHEN-MINUS to ASCII is strict, since mapping from ASCII back to Unicode produces the original Unicode character. However, the mappings from Unicode HYPHEN and MINUS SIGN to ASCII are loose, since they do not provide round-trip fidelity. The mapping from ASCII HYPHEN-MINUS to Unicode is, of course, strict.
Second, an example that illustrates the difference in the case of multiple representation. The Latin-1 character LATIN SMALL LETTER A WITH ACUTE (0xE1) is typically mapped to Unicode LATIN SMALL LETTER A WITH ACUTE (U+00E1), so the reverse is a strict mapping. However, the Unicode sequence LATIN SMALL LETTER A plus COMBINING ACUTE ACCENT can also be mapped to the Latin-1 character as a loose mapping.
There are two important things to note here. First, calling a mapping from one character set to another strict or loose depends on how the second character set is mapped back to the first; strictness or looseness depends on the mappings in both directions. Second, neither strict nor loose mappings necessarily preserve the number of characters; either can map a sequence of one or more characters in the source encoding to one or more characters in the destination encoding.
Fallback Mappings
A fallback mapping is a sequence of one or more coded characters in the destination encoding that is not exactly equivalent to a character in the source encoding but which preserves some of the information of the original. For example, (C) is a possible fallback mapping for ©. In general, fallback mappings are used as a last resort in converting text between encodings because they are not reversible and therefore do not lend themselves to round-trip fidelity conversions.
Corporate Use Zone
Code space in the Unicode standard is divided into areas and zones. One area, called the Private Use Area, includes a zone called the Corporate Use Zone.
Some characters which are in Mac OS encodings but not in Unicode are mapped to code points in the Unicode Corporate Use Zone. This permits round-trip fidelity for these characters. The Apple logo is an example.
Apple provides a registry of its assignments in the Unicode Corporate Use Zone that you can check to ensure that you don’t use the same code representations. The URL is:
ftp://ftp.unicode.org/Public/MAPPINGS/VENDORS/APPLE/CORPCHR.TXT
Although they allow the Unicode Converter to guarantee perfect round trips for certain code representations, characters in the Unicode Corporate Use Zone are not portable to other systems.
The Text Encoding Conversion Manager
The Text Encoding Conversion Manager comprises the Text Encoding Converter, the Unicode Converter, Basic Text Types, and the Text Encodings folder that includes files containing mapping tables and text plug-ins. The first three of these components are delivered as shared libraries called UnicodeConverter (the Unicode Converter), TextEncodingConverter (the Text Encoding Converter), and TextCommon (Basic Text Types).
About Earlier Releases
Text Encoding Conversion (TEC) Manager 1.0.x was released for use with Cyberdog 1.0 and 1.2 and with Mac OS Runtime for Java (MRJ) 1.0. TEC Manager 1.1 was released for use with Cyberdog 2.0.
TEC Manager 1.2 was included with Mac OS 8 in July 1997, and with MRJ 1.5; the corresponding interfaces were in Universal Interfaces 3.0. TEC Manager 1.2.1 was released as an SDK in September 1997.
TEC Manager 1.3 was included with Mac OS 8.1 in January 1998, and with MRJ 2.0. TEC Manager 1.3.1 (with one additional bug fix) was released as an SDK. The corresponding interfaces were in Universal Interfaces 3.1.
TEC Manager 1.4 was released as an SDK in September 1998, and was included with Mac OS 8.5 in October 1998. The corresponding interfaces were in Universal Interfaces 3.2. TEC Manager 1.4.2 was released as an SDK in February 1999, and was included with MRJ 2.1. TEC Manager 1.4.3 was included with Mac OS 8.6 in May 1999.
In older documentation for the Text Encoding Conversion Manager, the Unicode Converter was called the Low- Level Encoding Converter and the Text Encoding Converter was called the High-Level Encoding Converter.
Checking the Version
Versions 1.2.1 and later of the Text Encoding Conversion Manager include the TECGetInfo function, which returns the product version number and other information. This function does not exist in previous releases; absence of this function identifies the version in use as 1.2 or earlier.
You can determine if an earlier release of the Text Encoding Conversion Manager is in use by soft-linking to the TECGetInfo function.
Copyright © 2005 Apple Computer, Inc. All Rights Reserved. Terms of Use | Privacy Policy | Updated: 2005-07-07