Retired Document
Important: OpenCL was deprecated in macOS 10.14. To create high-performance code on GPUs, use the Metal framework instead. See Metal.
Sharing Data Between OpenCL and OpenGL
OpenGL (Open Graphics Library) is an API for writing applications that produce two- and three-dimensional computer graphics. OpenCL and OpenGL are designed to interoperate. In particular, OpenCL and OpenGL can share data, which reduces overhead. For example, OpenGL objects and OpenCL memory objects created from OpenGL objects can access the same memory. In addition, GLSL (OpenGL Shading Language) shaders and OpenCL kernels can access the shared data.
To make sure OpenCL and OpenGL work together smoothly:
Set your program up to do all its computation and rendering on the GPU.
This will improve performance because you’ll avoid having to transfer data between the host and the GPU.
Allocate memory to ensure that data is shared efficiently.
This chapter shows how the OpenCL API can be used to create OpenCL memory objects from OpenGL vertex buffer objects (VBOs), texture objects, and renderbuffer objects. It also shows how to create OpenCL buffer objects from OpenGL buffer objects and how to create an OpenCL image object from an OpenGL texture or renderbuffer object.
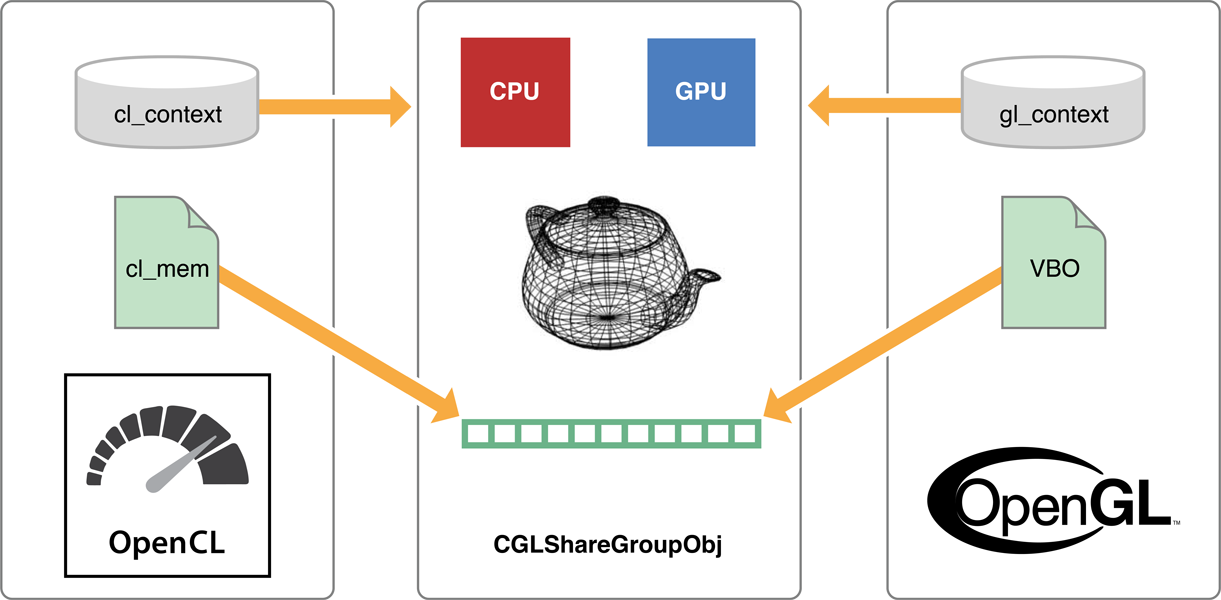
Sharegroups
To allow an OpenCL application to access an OpenGL object, use an OpenCL context that is created from an OpenGL sharegroup (CGLShareGroupObj) object. OpenCL objects you create in this context will reference these OpenGL objects. When an OpenCL context is connected to an OpenGL sharegroup object in this way, both the OpenCL and OpenGL contexts can reference the same objects.
Figure 10-1 illustrates a typical scenario in which OpenCL generates geometry on the GPU and OpenGL renders the shared geometry, also on the GPU. They may see what they are looking at as different objects - in this case, OpenGL sees the data as a VBO and OpenCL sees it as a cl_mem. The result is that both the OpenCL and OpenGL contexts end up referencing the same sharegroup (CGLShareGroupObj) object, see the same devices, and access this shared geometry.
To interoperate between OpenCL and OpenGL:
-
Set the sharegroup:
CGLContextObj cgl_context = CGLGetCurrentContext();
CGLShareGroupObj sharegroup = CGLGetShareGroup(cgl_context);
gcl_gl_set_sharegroup(sharegroup);
...
After the sharegroup has been set, you can create OpenCL memory objects from the existing OpenGL objects:
To create an OpenCL buffer object from an OpenGL buffer object, call:
void * gcl_gl_create_ptr_from_buffer(GLuint bufobj);
To create an OpenCL image object from an OpenGL texture object, call:
cl_image gcl_gl_create_image_from_texture(
GLenum texture_target,
GLint mip_level,
GLuint texture);
To create an OpenCL two-dimensional image object from an OpenGL render buffer object, call:
cl_image gcl_gl_create_image_from_renderbuffer(GLuint render_buffer);
Synchronizing Access To Shared OpenCL / OpenGL Objects
To ensure data integrity, the application must synchronize access to objects shared by OpenCL and OpenGL. Failure to provide such synchronization may result in race conditions or other undefined behavior including non-portability between implementations. For information about synchronizing OpenCL and OpenGL events and fences, see Controlling OpenCL / OpenGL Interoperation With GCD.
Example: OpenCL and OpenGL Sharing Buffers
This code example is excerpted from the OpenCL Procedural Geometric Displacement Example with GCD Integration. It shows how OpenCL can bind to existing OpenGL buffers in order to avoid copying data back from a compute device when it needs to use the results of the computation for rendering. In this example, an OpenCL compute kernel displaces the vertices of an OpenGL-managed vertex buffer object (VBO). The compute kernel calculates several octaves of procedural noise to push the resulting vertex positions outwards and calculates new normal directions using finite differences. The vertices are then rendered by OpenGL.
To build this application:
Include the header file generated by Xcode. This header file contains the kernel block declaration.
#include "displacement_kernel.cl.h"Declare the dispatch queue and the dispatch semaphore used for synchronization between OpenCL and OpenGL. For more information about the dispatch semaphores, see Synchronizing A Host With OpenCL Using A Dispatch Semaphore.
static dispatch_queue_t queue;
static dispatch_semaphore_t cl_gl_semaphore;
Declare the memory objects that will hold input and output data.
static void *InputVertexBuffer;
static void *OutputVertexBuffer;
static void *OutputNormalBuffer;
Set the sharegroup, create the dispatch queue and the dispatch semaphore, and get the compute device.
static int setup_compute_devices(int gpu)
{int err;
size_t returned_size;
ComputeDeviceType =
gpu ? CL_DEVICE_TYPE_GPU : CL_DEVICE_TYPE_CPU;
printf(SEPARATOR);
printf("Using active OpenGL context...\n");// Set the sharegroup.
CGLContextObj kCGLContext =
CGLGetCurrentContext();
CGLShareGroupObj kCGLShareGroup =
CGLGetShareGroup(kCGLContext);
gcl_gl_set_sharegroup(kCGLShareGroup);
// Create a dispatch queue.
queue = gcl_create_dispatch_queue(
ComputeDeviceType, NULL);
if (!queue)
{printf("Error: Failed to create a dispatch queue!\n");return EXIT_FAILURE;
}
// Create a dispatch semaphore.
cl_gl_semaphore = dispatch_semaphore_create(0);
if (!cl_gl_semaphore)
{printf("Error:Failed to create a dispatch semaphore!\n");
return EXIT_FAILURE;
}
// Get the device ID.
ComputeDeviceId =
gcl_get_device_id_with_dispatch_queue(queue);
// Report the device vendor and device name.
cl_char vendor_name[1024] = {0};cl_char device_name[1024] = {0};err = clGetDeviceInfo(
ComputeDeviceId, CL_DEVICE_VENDOR,
sizeof(vendor_name), vendor_name,
&returned_size);
err|= clGetDeviceInfo(
ComputeDeviceId, CL_DEVICE_NAME,
sizeof(device_name), device_name,
&returned_size);
if (err != CL_SUCCESS)
{printf(
"Error: Failed to retrieve device info!\n");
return EXIT_FAILURE;
}
printf(SEPARATOR);
printf(
"Connecting to %s %s...\n",
vendor_name, device_name);
return CL_SUCCESS;
}
Create the memory objects that will hold input and output data and initialize the input memory object with the input data.
This example creates a new memory object,
InputVertexBuffer, using thegcl_mallocfunction. It then uses thegcl_gl_create_ptr_from_bufferfunction to create OpenCL objects (OutputVertexBufferandOutputNormalBuffer) from existing OpenGL VBOs (VertexBufferIdandNormalBufferId). TheInputVertexBuffermemory object is initialized with input data stored inVertexBuffer, using thegcl_memcpyfunction.static int setup_compute_memory()
{size_t bytes =
sizeof(float) * VertexComponents * VertexElements;
printf(SEPARATOR);
printf("Allocating buffers on compute device...\n");InputVertexBuffer = gcl_malloc(bytes, NULL, 0);
if (!InputVertexBuffer)
{printf("Failed to create InputVertexBuffer!\n");return EXIT_FAILURE;
}
OutputVertexBuffer =
gcl_gl_create_ptr_from_buffer(VertexBufferId);
if (!OutputVertexBuffer)
{printf("Failed to create OutputVertexBuffer!\n");return EXIT_FAILURE;
}
OutputNormalBuffer =
gcl_gl_create_ptr_from_buffer(NormalBufferId);
if (!OutputNormalBuffer)
{printf("Failed to create OutputNormalBuffer!\n");return EXIT_FAILURE;
}
dispatch_async(queue,
^{gcl_memcpy(InputVertexBuffer,
VertexBuffer, VertexBytes);});
return CL_SUCCESS;
}
Create the compute kernel from the kernel block generated by Xcode.
static int setup_compute_kernels(void)
{int err = 0;
ComputeKernel =
gcl_create_kernel_from_block(displace_kernel);
// Get the maximum work group size for executing
// the kernel on the device.
size_t max = 1;
err = clGetKernelWorkGroupInfo(
ComputeKernel, ComputeDeviceId,
CL_KERNEL_WORK_GROUP_SIZE, sizeof(size_t),
&max, NULL);
if (err != CL_SUCCESS)
{printf("Error:Failed to retrieve kernel work group
info! %d\n", err);
return EXIT_FAILURE;
}
MaxWorkGroupSize = max;
printf("Maximum Workgroup Size '%d'\n",MaxWorkGroupSize);
return CL_SUCCESS;
}
Use the
cl_ndrangestructure to specify the data parallel range over which to execute the kernel. Dispatch the kernel block asynchronously using thedispatch_asyncfunction. After you dispatch the kernel, signal the dispatch semaphore to indicate that OpenGL can now access the shared resources.static int recompute(void)
{size_t global[2];
size_t local[2];
cl_ndrange ndrange;
uint uiSplitCount = ceilf(sqrtf(VertexElements));
uint uiActive = (MaxWorkGroupSize / GroupSize);
uiActive = uiActive < 1 ? 1 : uiActive;
uint uiQueued = MaxWorkGroupSize / uiActive;
local[0] = uiActive;
local[1] = uiQueued;
global[0] = divide_up(uiSplitCount, uiActive) * uiActive;
global[1] = divide_up(uiSplitCount, uiQueued) * uiQueued;
ndrange.work_dim = 2;
ndrange.global_work_offset[0] = 0;
ndrange.global_work_offset[1] = 0;
ndrange.global_work_size[0] = global[0];
ndrange.global_work_size[1] = global[1];
ndrange.local_work_size[0] = local[0];
ndrange.local_work_size[1] = local[1];
dispatch_async(queue,
^{displace_kernel(&ndrange,
InputVertexBuffer,
OutputNormalBuffer,
OutputVertexBuffer,
ActualDimX, ActualDimY,
Frequency, Amplitude, Phase,
Lacunarity, Increment, Octaves,
Roughness, VertexElements);
dispatch_semaphore_signal(
cl_gl_semaphore);
});
return 0;
}
Free the OpenCL memory objects, release the compute kernel, the dispatch queue, and the semaphore.
static void shutdown_opencl(void)
{gcl_free(InputVertexBuffer);
gcl_free(OutputVertexBuffer);
gcl_free(OutputNormalBuffer);
clReleaseKernel(ComputeKernel);
if(VertexBuffer)
free(VertexBuffer);
if(NormalBuffer)
free(NormalBuffer);
dispatch_release(cl_gl_semaphore);
dispatch_release(queue);
}
Copyright © 2018 Apple Inc. All Rights Reserved. Terms of Use | Privacy Policy | Updated: 2018-06-04