

Triple Buffering
Best Practice: Implement a triple buffering model to update dynamic buffer data.
Dynamic buffer data refers to frequently updated data stored in a buffer. To avoid creating new buffers per frame and to minimize processor idle time between frames, implement a triple buffering model.
Prevent Access Conflicts and Reduce Processor Idle Time
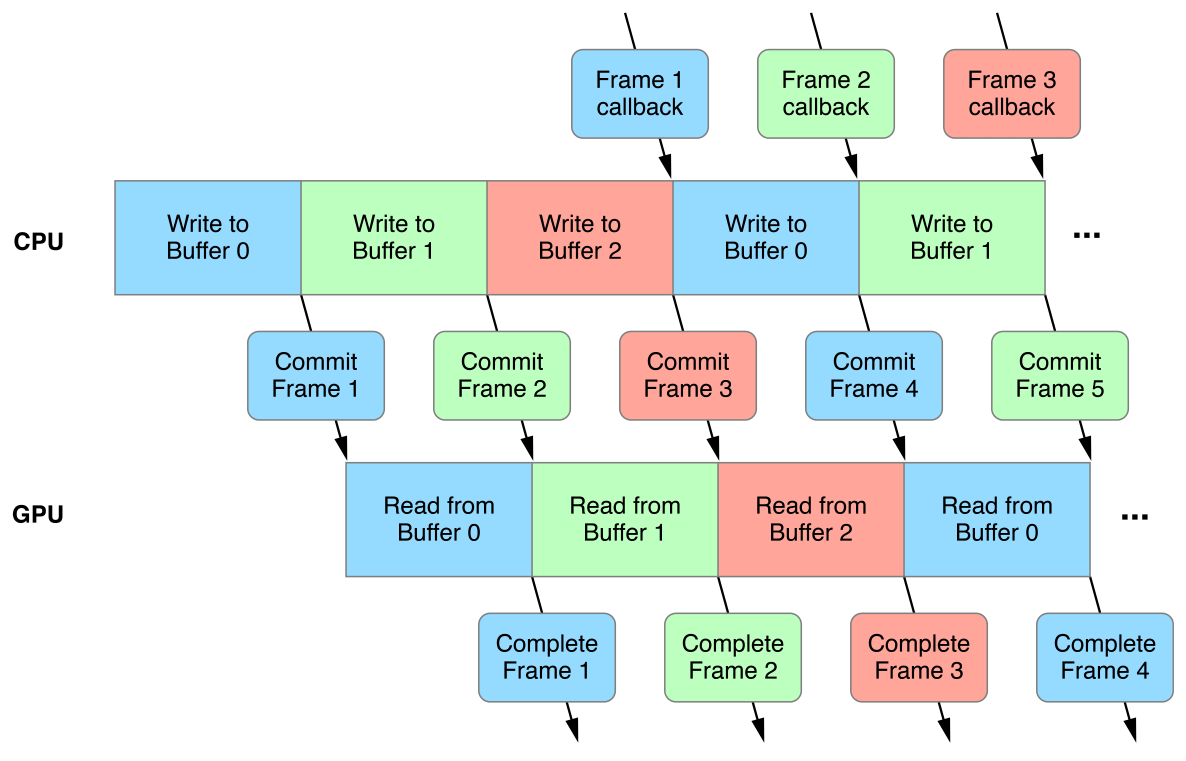
Dynamic buffer data is typically written by the CPU and read by the GPU. An access conflict occurs if these operations happen at the same time; the CPU must finish writing the data before the GPU can read it, and the GPU must finish reading that data before the CPU can overwrite it. If dynamic buffer data is stored in a single buffer, this causes extended periods of processor idle time when either the CPU is stalled or the GPU is starved. For the processors to work in parallel, the CPU should be working at least one frame ahead of the GPU. This solution requires multiple instances of dynamic buffer data, so the CPU can write the data for frame n+1 while the GPU reads the data for frame n.
Reduce Memory Overhead and Frame Latency
You can manage multiple instances of dynamic buffer data with a FIFO queue of reusable buffers. However, allocating too many buffers increases memory overhead and may limit memory allocation for other resources. Additionally, allocating too many buffers increases frame latency if the CPU work is too far ahead of the GPU work.
Allow Time for Command Buffer Transactions
Dynamic buffer data is encoded and bound to a transient command buffer. It takes a certain amount of time to transfer this command buffer from the CPU to the GPU after it has been committed for execution. Similarly, it takes a certain amount of time for the GPU to notify the CPU that it has completed the execution of this command buffer. This sequence is detailed below, for a single frame:
The CPU writes to the dynamic data buffer and encodes commands into a command buffer.
The CPU schedules a completion handler (
addCompletedHandler:), commits the command buffer (commit), and transfers the command buffer to the GPU.The GPU executes the command buffer and reads from the dynamic data buffer.
The GPU completes its execution and calls the command buffer completion handler (
MTLCommandBufferHandler).
This sequence can be parallelized with two dynamic data buffers, but the command buffer transactions may cause the CPU to stall or the GPU to starve if either processor is waiting on a busy dynamic data buffer.
Implement a Triple Buffering Model
Adding a third dynamic data buffer is the ideal solution when considering processor idle time, memory overhead, and frame latency. Figure 4-1 shows a triple buffering timeline, and Listing 4-1 shows a triple buffering implementation.
static const NSUInteger kMaxInflightBuffers = 3;/* Additional constants */@implementation Renderer{dispatch_semaphore_t _frameBoundarySemaphore;NSUInteger _currentFrameIndex;NSArray <id <MTLBuffer>> _dynamicDataBuffers;/* Additional variables */}- (void)configureMetal{// Create a semaphore that gets signaled at each frame boundary.// The GPU signals the semaphore once it completes a frame's work, allowing the CPU to work on a new frame_frameBoundarySemaphore = dispatch_semaphore_create(kMaxInflightBuffers);_currentFrameIndex = 0;/* Additional configuration */}- (void)makeResources{// Create a FIFO queue of three dynamic data buffers// This ensures that the CPU and GPU are never accessing the same buffer simultaneouslyMTLResourceOptions bufferOptions = /* ... */;NSMutableArray *mutableDynamicDataBuffers = [NSMutableArray arrayWithCapacity:kMaxInflightBuffers];for(int i = 0; i < kMaxInflightBuffers; i++){// Create a new buffer with enough capacity to store one instance of the dynamic buffer dataid <MTLBuffer> dynamicDataBuffer = [_device newBufferWithLength:sizeof(DynamicBufferData) options:bufferOptions];[mutableDynamicDataBuffers addObject:dynamicDataBuffer];}_dynamicDataBuffers = [mutableDynamicDataBuffers copy];}- (void)update{// Advance the current frame index, which determines the correct dynamic data buffer for the frame_currentFrameIndex = (_currentFrameIndex + 1) % kMaxInflightBuffers;// Update the contents of the dynamic data bufferDynamicBufferData *dynamicBufferData = [_dynamicDataBuffers[_currentFrameIndex] contents];/* Perform updates */}- (void)render{// Wait until the inflight command buffer has completed its workdispatch_semaphore_wait(_frameBoundarySemaphore, DISPATCH_TIME_FOREVER);// Update the per-frame dynamic buffer data[self update];// Create a command buffer and render command encoderid <MTLCommandBuffer> commandBuffer = [_commandQueue commandBuffer];id <MTLRenderCommandEncoder> renderCommandEncoder = [commandBuffer renderCommandEncoderWithDescriptor:_renderPassDescriptor];// Set the dynamic data buffer for the frame[renderCommandEncoder setVertexBuffer:_dynamicDataBuffers[_currentFrameIndex] offset:0 atIndex:0];/* Additional encoding */[renderCommandEncoder endEncoding];// Schedule a drawable presentation to occur after the GPU completes its work[commandBuffer presentDrawable:view.currentDrawable];__weak dispatch_semaphore_t semaphore = _frameBoundarySemaphore;[commandBuffer addCompletedHandler:^(id<MTLCommandBuffer> commandBuffer) {// GPU work is complete// Signal the semaphore to start the CPU workdispatch_semaphore_signal(semaphore);}];// CPU work is complete// Commit the command buffer and start the GPU work[commandBuffer commit];}@end
Copyright © 2018 Apple Inc. All rights reserved. Terms of Use | Privacy Policy | Updated: 2017-03-27