Constructing XML Tree Structures
Generally, if you wish to add or modify the content of an XML document, you must construct a static tree structure that completely represents the elements and other constructs in the document. Tree representations are also essential if you intend to validate an XML document against the DTD (or other language schema) that prescribes the logical structure of the document.
When most developers want to construct DOM-style tree representations of XML documents, they use a tree-based parser, not a streaming parser such as NSXMLParser. (Tree-based parsing engines, however, are typically built on top of streaming parsers.) Nonetheless, that does not mean that you cannot create tree structures using an NSXMLParser instance. Although this article does not go into great detail about techniques for constructing XML tree structures using NSXMLParser, it outlines a general approach that you could take.
You can represent any XML document as a hierarchical tree whose “nodes” are elements exhibiting relationships of parent and child with other elements. Each element can have one or more children and, with the exception of the root element, has exactly one parent element. The tree is anchored by a root element, which is the only element in the tree without a parent. The “leaf” nodes of the tree are typically those elements containing nothing but text, although they can also be mixed elements or empty elements.
For example, consider the following short XML document:
<?xml version="1.0" encoding="UTF-8"?> |
<!DOCTYPE addresses SYSTEM "addresses.dtd"> |
<addresses> |
<person idnum="0123"> |
<lastName>Doe</lastName> |
<firstName>John</firstName> |
<phone location="mobile">(201) 345-6789</phone> |
<email>jdoe@foo.com</email> |
<address> |
<street>100 Main Street</street> |
<city>Somewhere</city> |
<state>New Jersey</state> |
<zip>07670</zip> |
</address> |
</person> |
</addresses> |
The following tree of element nodes represents this document:
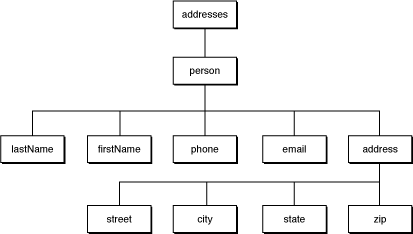
There are several possible ways to construct a tree representation of an XML document using NSXMLParser. This article, however, looks at a recursive, object-oriented approach that dynamically transfers delegation responsibilities among the objects representing the elements of a document. (This strategic shifting of the NSXMLParser delegate is discussed further in Using Multiple Delegates.) The programmatic result is doubly-linked lists of objects and arrays of objects; the abstract result is a tree representation of the document.
The procedure for constructing a tree using this approach entails the following steps:
Create a class whose instances represent the elements of an XML document. The class should define the name of the element and its parent (one-to-one) and children (one-to-many) relationships; it should also encapsulate the attributes associated with the element. As a shorthand notation for this procedure, we’ll call this class MyElement.
From a top-level object in the application, load an XML document, create an NSXMLParser instance for it, assign the top-level object as delegate, and begin parsing the document (see XML Parsing Basics).
The parser encounters the document’s root element first and sends
parser:didStartElement:namespaceURI:qualifiedName:attributes:to its delegate. The delegate creates a MyElement object to represent this root element and sets its parent tonil. The method that creates and initializes the object also sets it to be the new delegate of the NSXMLParser instance.The parser encounters the next element of the document—the first child of the root element—and again sends the delegate
parser:didStartElement:namespaceURI:qualifiedName:attributes:. The delegate is now the MyElement object recently created to represent the root element. It creates another MyElement object to represent the new element (in the process setting the new object to be the delegate and setting itself to be the parent) and adds the new object to its list of children.The new delegate receives the next
parser:didStartElement:namespaceURI:qualifiedName:attributes:message, identifying its first child element, and it creates it and adds it to its list of children.This recursive descent through the first branch of the tree ends when the parser encounters “leaf” elements containing text, mixed content, or empty elements. If there is mixed content the descent is not truly over since
parser:didStartElement:namespaceURI:qualifiedName:attributes:is sent to the delegate even after it receivesparser:foundCharacters:for the current element. Processing depends on the kind of element:If it’s an empty element, processing skips ahead to the next step (end-element tag)
If there is only text associated with the current element node, the delegate responds to the
parser:foundCharacters:message by accumulating text (in sequentialparser:foundCharacters:invocations).If there is mixed content, the delegate will process the text even after it receives messages notifying it of the start-element and end-element tags for the embedded elements. One way to handle this is to wrap the text in special text-element objects and insert these (in the proper order) in the element’s child list.
Finally, the parser sends the
parser:didEndElement:namespaceURI:qualifiedName:to the delegate, notifying it that the element is now complete. The delegate sets the new delegate to be its parent and returns.If the parent has more children elements, the parser sends it the next
parser:didStartElement:namespaceURI:qualifiedName:attributes:message; the parent MyElement object creates a MyElement instance to represent its next child (in the process setting it to be the new delegate and setting itself to be the parent of the new MyElement) and adds the newly created object to its list of children. However, if the parent has no more children to add to its list (that is, it receives theparser:didEndElement:namespaceURI:qualifiedName:message instead) it sets the new delegate to be its parent and returns.The procedure continues in this fashion until the entire XML document is processed and all branches of the tree are constructed.
The objects that are the nodes of the tree (representing mostly elements) should be able to print themselves out as XML code. Your application should also implement an algorithm that asks the objects to print themselves in the proper document sequence.
Copyright © 2004, 2010 Apple Inc. All Rights Reserved. Terms of Use | Privacy Policy | Updated: 2010-03-24