Speech Synthesis in OS X
OS X includes an advanced speech synthesizer that provides high-quality synthesized speech and comprehensive speech synthesis APIs that allow developers to create and customize spoken output.
This chapter discusses some of the benefits of using speech synthesis in your application and describes the components of the OS X Speech Synthesis framework. In addition, this chapter provides an overview of the ways in which you can customize the speech your application generates. You should read this chapter if you’re unfamiliar with the concepts of speech synthesis or if you’re wondering how to take advantage of synthesized speech in your application.
Why Use Synthesized Speech?
Although people have learned to communicate with computers and applications using display screens and various input devices, these methods represent an effort on the part of users to conform to the computer’s communication paradigm, not vice versa. When an application produces synthesized speech, however, it communicates with users in human terms, in a natural and efficient way. Using speech, an application can communicate an almost infinite range of information to the user. Because it is not limited to producing a small set of sounds users must learn to associate with specific conditions or actions, an application that generates speech can give users precise information about complex subjects and conditions.
Consider, for example, a home accounting application in which users enter data about their expenditures for the month. If the application speaks each number as it is entered, users know immediately when they’ve entered an incorrect number without ever having to look at the display screen. Another example is an email program that tells users not only when a new message arrives but also from whom.
Applications can also customize spoken output to meet specific requirements. For example, a language-learning application can customize speech to produce accurately pronounced words and phrases users can mimic. Games and other entertainment applications can use speech customization to emphasize the individuality of different onscreen characters.
Of course, an application that generates speech might also benefit from allowing users to speak to it, using a technology called speech recognition. However, this document focuses on the speech synthesis side of the computer-user conversation. You can find reference documentation on the OS X speech recognition APIs in Speech Recognition Manager Reference.
Spoken Output and Accessibility
It’s important to understand that adding synthesized speech to an application and making an application accessible to all users (a process called access enabling) are different processes with different goals. In particular, adding support for synthesized speech to your application is not the same as meeting accessibility requirements, such as those set by section 508 of the United States Rehabilitation Act of 1973.
Although both application-generated speech and the speech produced by a screen reader or other assistive application might sound the same (and use much of the same underlying technology), they perform different functions. Synthesized speech enhances an application’s user interface and helps accomplish application-specific tasks, such as describing error conditions or providing verbal feedback on users’s actions. In contrast, speech generated by an assistive application enables users to access all parts of the operating system and drive the user interfaces of other applications without using the mouse or display screen. Because an assistive application must be able to help users access all applications they might run, it focuses on providing access to the features all applications have in common, such as menus, buttons, and text-input fields.
To illustrate the difference between the roles of an application’s spoken output and the speech generated by an assistive application, consider an access-enabled chess application. For the purposes of this discussion, assume that this chess application produces spoken output that describes the moves taken by both the user and the application. Using an assistive application, visually impaired users can run this chess application and activate all the buttons and other controls in its user interface. However, an assistive application cannot describe the move the chess application makes in its turn, because that information arises from a change in the internal state of the chess application, not from a button click or menu-item selection. If the chess application did not produce its own spoken output, visually impaired users would be able to move their own chess pieces but would not be able to find out how the application responded.
In OS X v10.3 Apple introduced VoiceOver, an alternative way of interacting with the Macintosh that allows visually impaired users to use applications and OS X itself using only the keyboard. Because VoiceOver and many other assistive applications generate spoken output, they use the same OS X speech synthesizer your application uses when it generates spoken output. While VoiceOver is running, therefore, users may experience interruptions in your application's speech or cross-talk (overlapping speech). To find out how VoiceOver interacts with your application’s spoken output and how to avoid interrupting the spoken output of other applications, see Avoid Cross-Talk.
Speech Synthesis Concepts and Components
In OS X, the Speech Synthesis framework supports the conversion of text into speech, using a common API for managing voices and synthesizers. This architecture supports multiple, plug-in synthesizers and languages from different vendors, as well as multiple voices for each synthesizer. Application developers interact with the Speech Synthesis framework using the C-based API defined in the Application Services framework, the Objective-C API defined in the Application Kit, or the AppleScript say command. Developers of command-line tools and other processes can link with the Application Services framework to produce spoken output, because there is no graphical user interface inherent in synthesized speech. Even if you don’t plan to offer any customized speech features, your application or process benefits from the systemwide feature that allows users to hear spoken aloud nearly any text they can select.
The Speech Synthesis framework includes:
The Carbon speech synthesis API (also called the Speech Synthesis Manager), which is defined in the Speech Synthesis subframework in the Application Services framework. The Carbon speech synthesis API provides extensive control over speech synthesis to applications that can link with the Application Services framework.
The
NSSpeechSynthesizerclass, which is defined in the Application Kit framework. TheNSSpeechSynthesizerclass provides basic speech-synthesis functionality to Cocoa applications.Speech synthesizers, which are contained in loadable bundles and which reside in
/System/Library/Speech/Synthesizers. Synthesizers perform the conversion of text to speech and contain code that performs lexical analysis and determines pronunciations. Apple’s built-in synthesizer is the MacinTalk synthesizer, which is described in The MacinTalk Synthesizer.Speech voices, which are bundles that contain individual voice characteristics and, sometimes, code. Apple provides more than 20 built-in voices, which reside in
/System/Library/Speech/Voices. For more information about voices and their relationship to synthesizers, see Voices.
The following sections outline the OS X speech generation process and describe components of the Speech Synthesis framework and concepts of speech generation. The information in these sections is applicable to any application or process that produces synthesized speech, regardless of the speech synthesis API it uses.
The Speech Generation Process
Essentially, the Speech Synthesis framework is a dispatch mechanism that allows your application to take advantage of the capabilities of whatever speech synthesizers, voices, and hardware are installed on a user’s computer. The Speech Synthesis framework provides a convenient programming interface that manages access to the speech synthesizers and, indirectly, to the sound hardware. Figure 1-1 illustrates the speech generation process at a high level.
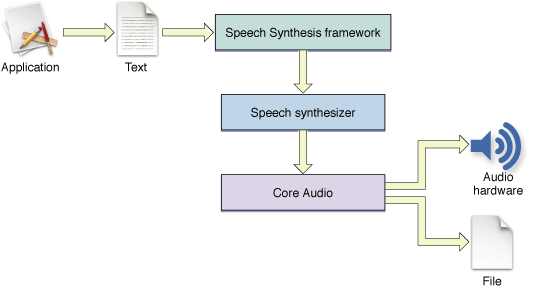
As outlined in Figure 1-1, your application initiates speech generation by passing a string or buffer of text to the Speech Synthesis framework, via the appropriate API. The Speech Synthesis framework is responsible for sending the text to a speech synthesizer, a component containing executable code that manages all communication between the Speech Synthesis framework and Core Audio.
A synthesizer contains a set of built-in dictionaries and pronunciation rules that it uses to determine how to pronounce text. The synthesizer receives text from an application and converts it to phonemes (described in Representations of Speech), and sends the result, including optional pronunciation directives, to a voice. Each synthesizer can work with only those voices that are designed for it; it cannot use voices designed for other synthesizers, even if the voices are installed in the computer.
As shown in Figure 1-1, Core Audio receives digital sound-wave input from the synthesizer and sends this data to the current sound output device or to a file. Because all communication between the Speech Synthesis framework and Core Audio is transparent to your application, you do not need to be concerned with potential changes to the underlying technology or implementations in this area.
An application can participate in the speech generation process at different levels, ranging from simple to complex. At one end of the spectrum, an application can be completely passive, allowing users to use system-supplied speech features to choose when to hear the application’s text spoken aloud and with which voice. At the other end, an application can supply the Speech Synthesis framework with precise information about how the speech should be produced and with which voice it should be spoken. For more on the ways you can use synthesized speech in your application, see Opportunities for the Customization of Synthesized Speech.
Representations of Speech
There are two ways your application can represent speech: textually and phonemically. Textual representation consists of a sequence of standard, human-readable words in a string or buffer. Phonemic representation is text converted into phonemes, which are distinct units that distinguish one word from another. Different languages have different sets of phonemes. For example, in English, the words “pad” and “bad” are distinguished by the phonemes “p” and “b.” Each phoneme is represented by a unique symbol, which consists of single or paired upper-case or lower-case letters (for a complete list of North American English phoneme symbols recognized by the MacinTalk synthesizer, see Phonemes). For example, the phonemic representation of the word “pad" is “pAEd,” where the phoneme symbols “p,” “AE,“ and “d” stand for “p,“ the short “a” sound, and “d,“ respectively.
A speech synthesizer always converts text to phonemes before sending it to a voice because the phonemic representation allows it to encode the precise pronunciation of each word. The Speech Synthesis framework provides a function that allows your application to convert text into phonemes before it is sent to the synthesizer. In applications that speak only text that users enter this feature is of limited usefulness, because you can’t anticipate what a user might type. However, if your application speaks a finite set of words or phrases that you create, it can be useful to represent at least some of that text phonemically to ensure its desired pronunciation.
Performing your own text-to-phoneme conversion has the following advantages:
You can use a text-to-phoneme conversion process that might be of higher quality than that provided by the available synthesizer. You can then use the phonemic data you generate in this way with any speech synthesizer to produce better speech.
You can use phoneme modifiers to adjust the pronunciation of words, giving you a very high degree of control over the spoken output. For example, you can change the placement of the primary stress within a word.
You can use the TUNE format to shape the overall melody and timing of an utterance. The TUNE format (described in Use the TUNE Format to Supply Complex Pitch Contours) allows you to create a template of pitch and rate changes and apply it to the phonemic representation of a word or phrase. For example, you can use the TUNE format to make an utterance sound as if it is spoken with emotion.
The Speech Synthesis framework also allows you to intersperse phonemic representations of specific words and phrases in a buffer of text. This is useful if the text that your application needs to speak contains words with nonstandard pronunciations, such as proper names, or words you want to be spoken in a particular way. To combine textual and phonemic representations of speech in this way, you must use embedded speech commands (described in Control Speech Quality Using Embedded Speech Commands).
Voices
A voice is a set of characteristics that exhibit particular qualities of speech, such as pitch and tone. Just as each person’s voice has unique tonal qualities, so too does each synthesized voice. A synthesized voice might sound male or female and might sound like an adult or a child. Some synthesized voices sound distinctively synthetic, while others sound more natural. To explore the range of voices that come installed in OS X, go to the Speech pane of System Preferences, click the Text to Speech tab, and listen to the voices listed in the System Voice menu. Your application can use the default system voice to generate speech, or it can use the speech synthesis API to select (or allow users to select) one of the other voices available on the user’s system.
Although a single voice supports only one language and region, a synthesizer may contain any number of voices, each of which can support a different language. Figure 1-2 shows how different synthesizers and their voices can coexist on a computer.
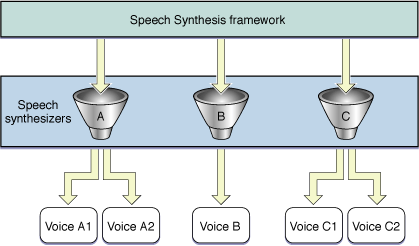
The Speech Synthesis framework defines a data structure, called a voice description record, that holds information about a voice, such as its name, gender, age, language, and the synthesizer with which it’s associated. The framework provides functions that allow you to identify how many voices are currently available in the user’s system and to get the information in a voice description record for a specific voice. Although most of the information in voice description records should not be exposed to users, you can display some of it, such as the voice name, to help users make informed choices.
Note that, in general, your application does not need to know which speech synthesizer it is using or with which speech synthesizer a given voice is associated. However, some speech synthesizers provide special capabilities in addition to those provided by the Speech Synthesis framework. For example, a speech synthesizer might allow you to select an option to speak all numbers in a nonstandard way, such as digit-by-digit. For these circumstances, the Speech Synthesis framework provides APIs that allow you to determine which synthesizer is associated with a voice and provides hooks that allow your application to take advantage of synthesizer-specific capabilities.
As speech technology continues to develop, it’s likely that the voices your application can access will sound increasingly human. When you use the OS X speech synthesis APIs, you automatically benefit from any improvements made to the voices built into the system. Regardless of the voice used to speak the output, you can customize the way it speaks your text, using techniques outlined in Adjust Speech Attributes and Control Speech Production Using the Speech Synthesis APIs and Control Speech Quality Using Embedded Speech Commands.
Speech Channels
To send text to a synthesizer and to specify which voice or attributes you would like it to use, your application uses a speech channel. Conceptually, a speech channel is the conduit between your application and the Speech Synthesis framework. Your application acquires a speech channel, sends through it the text to be spoken, and, optionally, sets speech-channel attributes that affect the synthesized speech.
Precisely how your application interacts with a speech channel is defined by the API it uses. The Carbon speech synthesis API includes functions you use to create and manage speech channels, as well as functions that allow you to get and set speech-channel attributes. On the other hand, in the Cocoa speech synthesis API, speech-channel management is transparent to you. When you use the Cocoa API to generate spoken output, the necessary speech channels are created, used, and destroyed automatically. Similarly, the AppleScript say command does not expose the use of speech channels. Whichever API you use, however, it’s useful to understand the role of speech channels in the speech generation process. The remainder of this section describes this role and how some applications might need to create multiple speech channels.
At any point in time, a speech channel is associated with a particular voice and specific speech attributes. However, multiple speech channels can coexist in a single application, which allows your application to create more than one vocal environment to, for example, simulate a dialogue among different characters in a game. Alternatively, you can use a single speech channel and switch to different voices when necessary, but this approach can be inefficient. An example of an application that requires multiple speech channels is one that needs to generate speech in more than one language. As mentioned in Voices, a voice is associated with only one language and region, so an application that needs to produce spoken output in a bilingual or multilingual environment would need a separate speech channel for each language.
Separate speech channels in a single application can generate speech simultaneously, subject to processor capabilities. However, this capability should be used with restraint, because it is very difficult for users to make sense of speech when more than one channel is generating speech at the same time. Of course, different speech channels created by different applications may also produce speech simultaneously; for this reason, it’s a good idea to implement an arbitration scheme in your application (for more information on how to do this, see Avoid Cross-Talk).
Notifications, Callbacks, and Speech Synchronization
The Speech Synthesis framework allows you to receive notifications of certain events during the speech generation process. Using these notifications, you can synchronize speech with actions in your application, such as highlighting the word being spoken or animating a character’s mouth to correspond to the phoneme being pronounced.
Not surprisingly, the Cocoa and Carbon speech synthesis APIs support different sets of notifications and implement them differently (AppleScript does not support synchronization of speech with application actions). The Cocoa API defines delegate methods you can implement; the Carbon API defines a large number of callbacks for which you can provide handler functions.
Some of the notifications you can receive tell you when:
A word is about to be spoken
A phoneme is about to be spoken
Speaking has finished
The text has been processed, but not necessarily spoken yet (available only in the Carbon API)
A
syncembedded speech command is encountered (available only in the Carbon API). For more information about this command, see The OS X Embedded Speech Commands.
For more information about the specific notifications available and how to use them in your application, see Synchronize Speech with Application-Specific Actions.
The MacinTalk Synthesizer
The MacinTalk synthesizer is the built-in synthesizer in OS X. It generates North American English from unrestricted text, and supports the addition of a number of text-embedded commands to control pronunciation and intonation. The output of the MacinTalk synthesizer can be played through the computer’s speakers or saved to a file.
In general, a synthesizer produces the most natural-sounding speech when it combines its built-in text processing rules with pronunciation hints provided by the author of the text. The MacinTalk synthesizer contains a sophisticated lexical analyzer that allows it to make a “best guess” at how a human might speak a given sample of text. But the MacinTalk synthesizer (like all synthesizers) does a better job when you provide precise pronunciation information. Whether synthesized speech is an optional feature or constitutes the centerpiece of your application’s functionality, you should consider using the customization strategies described in Opportunities for the Customization of Synthesized Speech to ensure the production of high-quality speech that meets your specifications.
Attributes of Synthesized Speech
Any given person has only one voice, but can significantly alter the characteristics and meaning of his or her speech by varying the pitch, volume, and speed of delivery. People instinctively respond to these vocal attributes and rely on them to provide layers of meaning in addition to the semantic meaning of the words they hear. The Speech Synthesis framework supplies functions that allow you to manipulate speech attributes, such as pitch and speed, to achieve the effects you want.
A speech attribute is a setting defined on a speech channel that affects the quality of the spoken output for a specific subset of voices, or for all voices associated with a particular synthesizer. At any single point in time, there is a one-to-one correspondence between a voice and a speech channel, so you can think of a speech attribute as applying to either a voice or to a speech channel. Using functions in the Carbon speech synthesis API, you can alter four speech attributes: rate, pitch, pitch modulation, and volume. Alternatively, you can use embedded speech commands to set these four attributes, plus the prosody attribute, on a per-word basis, regardless of the programming language you’re using. For more information on how to use embedded commands, see Use Embedded Speech Commands to Fine-Tune Spoken Output.
Speech Rate
The speech rate of a speech channel is the approximate number of words of text that the synthesizer speaks in one minute. Although a slower speech rate can make the speech easier to understand, listening to words that are spoken too slowly can be tedious. Be sure to test your application to determine the optimum speech rate for your target audience, so you can ship your application with a reasonable default setting. Visually impaired users, for example, are often comfortable listening to much faster speech rates than sighted users.
Speech rates are expressed as real values. For example, typical, conversational speech is at a rate of about 180 words per minute, whereas some visually impaired users can comfortably listen to VoiceOver at rates of up to 500 words per minute. Each speech synthesizer determines its own range of speech rates that can be applied to the voices it uses. The Carbon speech synthesis API includes functions that allow you to get and change the current speech rate on a speech channel (for more information on how to do this, see Adjust Speech Channel Settings Using the Carbon Speech Synthesis API).
Speech Pitch, Frequency, and Pitch Modulation
Pitch is a combination of the average speaking frequency and its variations around that average. When you listen to a voice speaking, you’re aware of variations in pitch that create a sort of melody. Often, you’re more aware of this musical quality when you listen to conversations in a language you don’t speak, because you’re not focused on the semantic meaning of what you’re hearing. To produce human-like speech, therefore, a synthesizer must try to replicate these pitch variations in its voices.
The speech pitch of a speech channel represents the middle pitch of a voice, from which the actual pitches of the speech can vary with rising and falling tunes. You can think of speech pitch as roughly corresponding to the key in which a song is played. A speech pitch is expressed as a real value in the range of 0.000 through 127.000, where 60.000 corresponds to middle C on a conventional piano. Each 1.000-unit change in a speech-pitch value corresponds to a musical half-step. You may notice that this is the same scale that is used to specify MIDI note values. Although the scale is the same, however, speech-pitch values differ from MIDI note values in two fundamental ways: speech-pitch values do not have to be integral and they occupy a narrower range than MIDI note values.
On this scale, a change of +12 units corresponds to a doubling of frequency (an increase of one octave) and a change of -12 units corresponds to a halving of frequency (a decrease of one octave). A frequency is a precise indication of the number of hertz (Hz) of a sound wave at any instant. Typical voice frequencies might range from about 75 Hz for a low-pitched male voice to about 300 Hz for a high-pitched child’s voice. These frequencies correspond to approximate speech-pitch values in the ranges of 30.000 to 40.000 and 55.000 to 65.000, respectively. If you need to convert between speech pitches and hertz, note that a speech pitch of 60.000 corresponds to 261.625 Hz.
The Carbon speech synthesis API includes functions to determine the current speech pitch on a speech channel and to change the speech pitch (see Adjust Speech Channel Settings Using the Carbon Speech Synthesis API for more information on how to do this).
To simulate the variability in frequency in human speech, the Speech Synthesis framework defines a speech attribute called pitch modulation. The pitch modulation of a speech channel is the maximum amount by which the actual frequency of generated speech may deviate from the speech pitch.
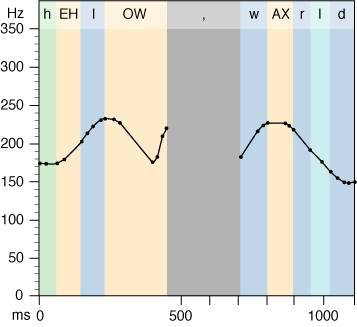
Pitch modulation is expressed as a real value in the range of 0.000 through 100.000. A pitch modulation value of 0.000 corresponds to a monotone in which all speech is generated at the frequency corresponding to the speech pitch. Speech generated at this pitch modulation sounds unnaturally robotic.
Speech Volume
The speech volume of a speech channel is the average amplitude at which the channel generates speech. Speech volumes are expressed as real values ranging from 0.0 through 1.0. A value of 0.0 corresponds to silence and a value of 1.0 corresponds to the maximum volume that can be produced by the available audio hardware. Volume units lie on a scale that is linear with amplitude or voltage; therefore, a doubling of the speech-volume value corresponds to a doubling of perceived loudness.
Just as a synthesizer does not usually generate speech at a constant frequency, it does not generate speech at a constant amplitude. Even when the speech rate is high, brief occurrences of silence (such as pauses between phrases) break up a steady stream of speech. The speech volume, like speech pitch, is an indicator of an average. The Carbon speech synthesis API provides a function you can use to set the volume of the current speech channel (see Adjust Speech Channel Settings Using the Carbon Speech Synthesis API to find out how to do this).
Prosody
The most complex speech attribute is prosody. The prosody speech attribute describes the rhythm, modulation, and emphasis patterns of speech, such as word and syllable stress and the pitch at the end of a sentence. Although there is no simple mechanism for your application to determine what rhythmic patterns a speech synthesizer automatically applies to speech, you can exert some control over this aspect of spoken output by using the emph embedded speech command (described in The OS X Embedded Speech Commands). In addition, you can use functions in the Carbon speech synthesis API to enable or disable ending prosody, which is the pitch modulation that a speech synthesizer applies to the end of a sentence.
The primary way you can affect the prosody of your application’s spoken output is by using the TUNE format to supply pitch and rate specifications for individual words or phrases. For more information on how to do this, see Use the TUNE Format to Supply Complex Pitch Contours.
Perhaps more than with other speech attributes, you can spend a lot of time fine-tuning the prosody of the speech your application generates. If you have a limited set of strings your application needs to speak, however, it’s well worth the effort to adjust the prosody (along with the other speech attributes) to achieve your goal. For some other ways to produce better-sounding speech, see Four Ways to Improve Spoken Output.
Opportunities for the Customization of Synthesized Speech
The Speech Synthesis framework supports many techniques for customizing the speech your application generates, ranging from simple to complex. This section outlines the various options available to you.
When you’re ready to begin designing your application to include some or all of the customizations described in this section, you should read Designing and Implementing an Application That Speaks for a survey of the available APIs, guidance on design considerations, and information on implementing basic speech synthesis tasks. Then, read Techniques for Customizing Synthesized Speech for in-depth customization information.
Use Different Voices
One of the first things users notice about the speech your application produces is the voice that speaks it. Consequently, using a specific voice is an easy way to customize the spoken output of your application.
If the voice itself is not an important feature in your application, you can simply use the system default voice (note that users can set the default voice in the Speech System Preferences). However, you may want to designate a specific voice (or voices) or give your users the ability to choose a voice. For example, if you’re developing a game that displays more than one distinct character, you need to be able to give each character its own voice. If, on the other hand, you’re developing an interactive application for children, you might want to give them a selection of entertaining voices from which to choose.
Designating a specific voice or set of voices requires you to find out which voices are available on the user’s system, examine individual voice descriptions to determine which ones you want, and tell the synthesizer which voice to use. Both the Cocoa and Carbon speech synthesis APIs provide programmatic ways to do this (see the code listings in Implementing Basic Speech Synthesis Tasks Using Cocoa and Carbon for some examples).
Adjust Speech Attributes and Control Speech Production Using the Speech Synthesis APIs
As described in Attributes of Synthesized Speech, the Speech Synthesis framework defines several attributes that describe aspects of speech, such as volume and pitch. The Speech Synthesis framework provides functions that allow you to adjust rate and pitch. Note that these functions act on speech channels, not on the text itself. This means that, for example, changing the speech rate of a speech channel effectively changes the rate of all speech that channel produces. In addition, you cannot assume that such a change will persist if you change the voice on the channel. This is because telling a channel to use a different voice can cause all the channel’s parameters to be reset to default values. In addition, the new voice may not support some of the attribute settings. However, there may be cases in which it makes sense for your application to change the speech rate or pitch, such as in response to a user request. For an example of how to do this, see Adjust Speech Channel Settings Using the Carbon Speech Synthesis API.
You can exert control over the production of spoken output by using speech synthesis functions to stop, pause, and continue speech. For example, you might allow users to select a Stop Speaking menu item or click a Pause button to control the spoken output. For more information on the functions and methods you can use to control the flow of speech and examples of how to use them, see Implementing Basic Speech Synthesis Tasks Using Cocoa and Carbon.
Although you can use speech synthesis functions to adjust speech attributes, such as volume and pitch, you cannot use them to successfully adjust the pronunciation of words. To fine-tune the pronunciation or prosody of individual words and phrases, you need to use embedded speech commands (described in Control Speech Quality Using Embedded Speech Commands).
Control Speech Quality Using Embedded Speech Commands
An embedded speech command allows you to control the quality of spoken output with great precision, because you associate it with an individual word or phrase you want to affect. Embedded commands can be used in buffers (or strings) of both textual and phonemic representations of speech. In fact, you can combine phonemic representations of specific words or phrases with textual representations in the same string or buffer.
Embedded commands allow you to make precise adjustments to the pronunciation of words, the way words are emphasized in a sentence, and the overall cadence of the speech. You can use embedded commands to make speech easier to understand and more human-sounding or to mimic particular pronunciations and intonations. In addition, using this technique confers a significant advantage: you do not need to make any changes to the API your application calls to generate speech, because the embedded commands are contained in the text your application passes to the synthesizer. Your application need only call the standard functions or methods that begin the speech generation process, such as SpeakString or startSpeakingString: (for more information on these, see the examples in Implementing Basic Speech Synthesis Tasks Using Cocoa and Carbon).
Although embedded commands are most useful for controlling the speech you create, you can also add embedded commands to control the speech generated from text users enter. For example, a word processing application might embed commands that tell the synthesizer to emphasize the pronunciation of words the user has boldfaced or underlined. For a description of the available embedded commands and examples of how to use them, see Use Embedded Speech Commands to Fine-Tune Spoken Output.
One embedded command, the [[inpt <mode>]] command, tells the synthesizer to interpret the content following the command in the mode designated by the value of the <mode> parameter, until it reaches another [[inpt <mode>]] command. For example, to supply a precise, phonemic representation of a word that appears in a buffer of text, you precede the word with the [[inpt PHON]] command, which tells the synthesizer to interpret the following content phonemically, and insert the [[inpt TEXT]] command after the word to signal the return to textual representation.
The [[inpt <mode>]] command also includes a mode that allows you to take advantage of the TUNE format, which is an input format that encodes a precise intonation for a word or phrase. You can use the TUNE format to replicate the intonation and timing of a particular utterance. For more information on this format and how to use it, see Use the TUNE Format to Supply Complex Pitch Contours.
Copyright © 2006 Apple Computer, Inc. All Rights Reserved. Terms of Use | Privacy Policy | Updated: 2006-09-05