 Table of Contents
Table of Contents  Previous Section
Previous Section
Entities and Attributes
Entities and attributes represent structures that contain data. In a relational database, entities represent tables; an entity's attributes represent the table's columns. A sample table that could be represented by an Employee entity is shown below:
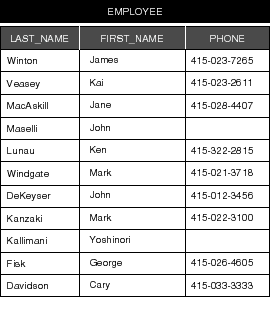
Figure 53. The "EMPLOYEE" Table
Each row in the table can be thought of as an "instance of an entity." Thus, an employee record is called an instance of the Employee entity. In the Enterprise Objects Framework, each instance of an entity typically maps to one enterprise object.
Contained within an entity is a list of features, or attributes, of the thing that's being modeled. The Employee entity would contain attributes such as the employee's last name, first name, phone number, and so on. This simple model is depicted in Figure 54.
Figure 54. The Employee Entity
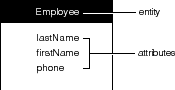
Names and the Data Dictionary
The table and column names shown in Figure 54 are the names that a hypothetical server might use. The collection of a server's table and column names is called its data dictionary. In your application, you can't refer directly to items in the server's data dictionary. To identify the server's "EMPLOYEE" table, for example, you must refer to the entity that represents the table-in other words, the Employee entity. The correspondence between the server's names and the names of the modeling objects that you create isn't coincidental; you have to tell each modeling object which data dictionary name it represents. This is done as you create the model.
Server names (in other words, names in a server's data dictionary) can be case-insensitive (depending on the database server). The names of modeling objects, on the other hand, are always case-sensitive. Throughout this chapter (and the rest of this manual) modeling objects are given names that match, except for case, the corresponding dictionary names (given the hypothetical relational database server that's used in the examples). To further distinguish the two, server names are uppercase and quoted-for example, the "EMPLOYEE" table-while modeling object names use a different font: AnEntity, anAttribute, aRelationship. Note that entity names are capitalized like class names, while attribute and relationship names are lowercase with intervening capital letters. Attributes are occasionally identified by their definition, with the entity and attribute names connected by a period: AnEntity.anAttribute.
Attribute Data
When you use an attribute to identify a particular datum in a table, you refer to the value for that attribute, given a particular record. An employee's phone number, for example, is the value for the Employee.phone attribute. The "value for an attribute" construction enforces the notion that the attribute itself doesn't contain data. Data Types
Every database attribute is assigned a data type (such as int, String, and so on). All values for a particular attribute take the data type of that attribute. In other words, the values in a particular column are all of the same type. When an enterprise object is fetched from the database, the value for each attribute is converted from its external data type into a suitable scalar or value class type that can be used by the enterprise object. For example, a Sybase varchar would become a java.lang.String (or NSString in Objective-C) in an enterprise object.
Attribute Types
An attribute may be simple, derived, or flattened. A simple attribute corresponds to a single column in the database, and may be read or updated directly from or to the database. The Primary Key
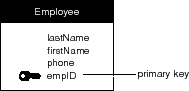
Each of the records in a table must be unique-no two records can contain exactly the same values. To ensure this, each entity must contain an attribute that's guaranteed to represent a unique value for each record. This attribute is called the entity's primary key.
Figure 55. The Employee Entity with a Primary Key
Compound Primary Keys
Typically, the primary key for an entity is a single attribute. However, you can designate a combination of attributes as a compound primary key. In a compound primary key, the value for any one of the constituent attributes isn't necessarily unique, but the combination of all of them is.
Figure 56. An Entity with a Compound Primary Key

Table of Contents  Next Section
Next Section