

Performance
Core Data is a rich and sophisticated object graph management framework capable of dealing with large volumes of data. The SQLite store can scale to terabyte-sized databases with billions of rows, tables, and columns. Unless your entities themselves have very large attributes or large numbers of properties, 10,000 objects is considered a fairly small size for a data set. When working with large binary objects, review Binary Large Data Objects (BLOBs).
Overhead versus Functionality in Core Data
For a very simple application Core Data adds some overhead—compare a plain Cocoa document-based application with a Cocoa Core Data document-based application. However, even a simple Core Data-based application supports undo and redo, validation, and object graph maintenance, and provides the ability to save objects to a persistent store. If you implemented this functionality yourself, it is quite likely that the overhead would exceed that imposed by Core Data. As the complexity of an application increases, the proportionate overhead that Core Data imposes typically decreases. At the same time the benefit typically increases. Implementing and supporting undo and redo in a large application, for example, is usually difficult.
NSManagedObject Storage Mechanism
NSManagedObject uses an internal storage mechanism for data that is highly optimized. In particular, it leverages the information about the types of data that is available through introspecting the model. When you store and retrieve data in a manner that is compliant with key-value coding and key-value observing, it is likely that using NSManagedObject will be faster than any other storage mechanism—including for the simple get/set cases. In a Cocoa application that leverages Cocoa bindings, given that Cocoa bindings are reliant upon key-value coding and key-value observing, it would be difficult to build a raw data storage mechanism that provides the same level of efficiency as Core Data.
Fetching Managed Objects
Each round trip to the persistent store (each fetch) incurs an overhead, both in accessing the store and in merging the returned objects into the persistence stack. Avoid executing multiple requests if you can instead combine them into a single request that will return all the objects you require. You can also minimize the number of objects you have in memory.
Fetch Predicates
How you use predicates can significantly affect the performance of your application. If a fetch request requires a compound predicate, you can make the fetch more efficient by ensuring that the most restrictive predicate is the first, especially if the predicate involves text matching (contains, endsWith, like, and matches). Correct Unicode searching is slow. If the predicate combines textual and nontextual comparisons, it is likely to be more efficient to specify the nontextual predicates first; for example, (salary > 5000000) AND (lastName LIKE 'Quincey') is better than (lastName LIKE 'Quincey') AND (salary > 5000000). For more about creating predicates, see Predicate Programming Guide.
Fetch Limits
You can set a limit to the number of objects a fetch will return using the method setFetchLimit:, as shown in the following example:
Objective-C
NSFetchRequest *request = [[NSFetchRequest alloc] init];[request setFetchLimit:100];
Swift
let request = NSFetchRequest()request.fetchLimit = 100
If you are using the SQLite store, you can use a fetch limit to minimize the working set of managed objects in memory and so improve the performance of your application.
If you need to retrieve many objects, you can make your application appear more responsive by executing multiple fetches. In the first fetch, you retrieve a comparatively small number of objects—for example, 100—and populate the user interface with these objects. You then execute subsequent fetches to retrieve the complete result set via the fetchOffset method.
Preventing a Fault from Firing
Firing faults can be a relatively expensive process (potentially requiring a round trip to the persistent store), and you may wish to avoid unnecessarily firing a fault. You can safely invoke the following methods on a fault without causing it to fire: isEqual:, hash, superclass, class, self, zone, isProxy, isKindOfClass:, isMemberOfClass:, conformsToProtocol:, respondsToSelector:, description, managedObjectContext, entity, objectID, inserted, updated, deleted, and isFault.
Because isEqual: and hash do not cause a fault to fire, managed objects can typically be placed in collections without firing a fault. Note, however, that invoking key-value coding methods on the collection object might in turn result in an invocation of valueForKey: on a managed object, which would fire a fault. In addition, although the default implementation of description does not cause a fault to fire, if you implement a custom description method that accesses the object’s persistent properties, this will cause a fault to fire.
Note that just because a managed object is a fault, it does not necessarily mean that the data for the object is not in memory—see the definition for isFault.
Decreasing Fault Overhead
When you execute a fetch, Core Data fetches only instances of the entity you specify. In some situations (see Faulting Limits the Size of the Object Graph), the destination of a relationship is represented by a fault. Core Data automatically resolves (fires) the fault when you access data in the fault. This lazy loading of the related objects is much better for memory use, and much faster for fetching objects related to rarely used (or very large) objects. It can also, however, lead to a situation where Core Data executes separate fetch requests for a number of individual objects, which incurs a comparatively high overhead. For example, consider this model:
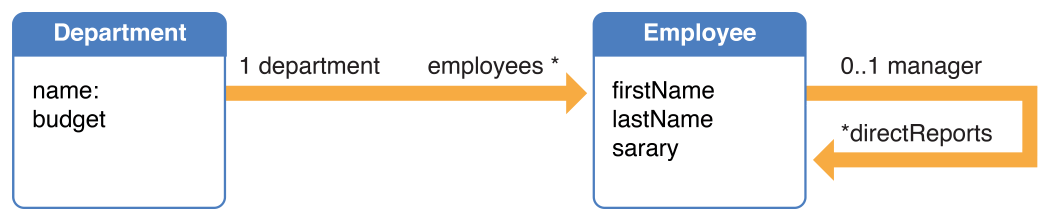
You might fetch a number of Employees and ask each in turn for their Department's name, as shown in the following code fragment.
Objective-C
NSFetchRequest * employeesFetch = [NSFetchRequest fetchRequestWithEntityName:@"Employee"];NSArray *fetchedEmployees = [moc executeFetchRequest:employeesFetch error:&error];if (fetchedEmployees == nil) {NSLog(@"Error fetching: %@\n%@", [error localizedDescription], [error userInfo]);abort();}for (Employee *employee in fetchedEmployees) {NSLog(@"%@ -> %@ department", employee.name, employee.department.name);}
Swift
let employeesFetch = NSFetchRequest<EmployeeMO>(entityName: "Employee")do {let fetchedEmployees = try moc.executeFetchRequest(employeeFetch)for employee in fetchedEmployees {print("\(employee.name) -> \(employee.department!.name)")}} catch {fatalError("Failed to fetch employees: \(error)")}
This code might lead to the following behavior:
Jack -> Sales [fault fires]Jill -> Marketing [fault fires]Benjy -> SalesGillian -> SalesHector -> Engineering [fault fires]Michelle -> Marketing
Here, there are four round trips to the persistent store (one for the original fetch of Employees and three for individual Departments). These trips represent a considerable overhead on top of the minimum two trips to the persistent store.
There are two techniques you can use to mitigate this effect—batch faulting and prefetching.
Batch Faulting
You can batch fault a collection of objects by executing a fetch request using a predicate with an IN operator, as illustrated by the following example. (In a predicate, self represents the object being evaluated—see Predicate Format String Syntax.)
Objective-C
NSArray *array = @[fault1, fault2, ...];NSPredicate *predicate = [NSPredicate predicateWithFormat:@"self IN %@", array];
Swift
let array = [fault1, fault2, ...]let predicate = NSPredicate(format:"self IN %@", array)
When you create a fetch request you can use the NSFetchRequest method setReturnsObjectsAsFaults: to ensure that managed objects are not returned as faults.
Prefetching
Prefetching is in effect a special case of batch-faulting, performed immediately after another fetch. The idea behind prefetching is the anticipation of future needs. When you fetch some objects, sometimes you know that soon after you will also need related objects which may be represented by faults. To avoid the inefficiency of individual faults firing, you can prefetch the objects at the destination.
You can use the NSFetchRequest method setRelationshipKeyPathsForPrefetching: to specify an array of relationship key paths to prefetch along with the entity for the request. For example, given an Employee entity with a relationship to a Department entity, if you fetch all the employees, for each employee, print the employee’s name and the name of the department. You can avoid the possibility of a fault being fired for each department instance by prefetching the department relationship. This is illustrated in the following code fragment:
Objective-C
NSManagedObjectContext *moc = …;NSFetchRequest *request = [NSFetchRequest fetchRequestWithEntityName:@"Employee"];[request setRelationshipKeyPathsForPrefetching:@[@"department"]];
Swift
let moc = …let request = NSFetchRequest<EmployeeMO>(entityName:"Employee")fetchRequest.relationshipKeyPathsForPrefetching = ["department"]
If you know something about how the data will be accessed or presented, you can further refine the fetch predicate to reduce the number of objects fetched. Note, though, that this technique can be fragile—if the application changes and needs a different set of data, you can end up prefetching the wrong objects.
For more about faulting, and in particular the meaning of the value returned from isFault, see Faulting and Uniquing.
Reducing Memory Overhead
Sometimes you need to use managed objects on a temporary basis, for example, to calculate an average value for a particular attribute. Loading a large number of objects into memory causes your object graph, and memory consumption, to grow. You can reduce the memory overhead by refaulting individual managed objects that you no longer need, or you can reset a managed object context to clear an entire object graph. You can also use patterns that apply to Cocoa programming in general. Follow these guidelines to reduce memory overhead:
Refault an individual managed object using the
refreshObject:mergeChanges:method forNSManagedObjectContext. Doing so clears the object’s in-memory property values, thereby reducing its memory overhead. (Note that the values are retrieved on demand if the fault is again fired—see Faulting and Uniquing.)When you create a fetch request, set
includesPropertyValuestoNOfalseto reduce memory overhead by avoiding creation of objects to represent the property values. You should typically only do so, however, if you are sure that either you will not need the actual property data or you already have the information in the row cache. Otherwise you will incur multiple trips to the persistent store.Use the
resetmethod ofNSManagedObjectContextto remove all managed objects associated with a context, and start over as if you'd just created it. Note that managed objects associated with that context will be invalidated, and so you will need to discard any references to and refetch any objects associated with that context.If you iterate over a lot of objects, you may need to use local autorelease pool blocks to ensure temporary objects are deallocated as soon as possible.
If you do not intend to use Core Data’s undo functionality, reduce your application's resource requirements by setting the context’s undo manager to
nil. This may be especially beneficial for background worker threads as well as for large import or batch operations.If you have lots of objects in memory, determine the owning references. Core Data does not by default keep strong references to managed objects (unless they have unsaved changes). Managed objects maintain strong references to each other through relationships, which can easily create strong reference cycles. You can break cycles by refaulting objects (again by using the
refreshObject:mergeChanges:method ofNSManagedObjectContext).
Binary Large Data Objects (BLOBs)
If your application uses Binary Large OBjects (BLOBs) such as image and sound data, you need to take care to minimize overheads. Whether an object is considered small or large depends on an application’s usage. A general rule is that objects smaller than a megabyte are small or medium-sized and those larger than a megabyte are large. Some developers have achieved good performance with 10 MB BLOBs in a database. On the other hand, if an application has millions of rows in a table, even 128 bytes might be a CLOB (Character Large OBject) that needs to be normalized into a separate table.
In general, if you need to store BLOBs in a persistent store, use an SQLite store. The other stores require that the whole object graph reside in memory, and store writes are atomic (see Persistent Store Types and Behaviors), which means that they do not efficiently deal with large data objects. SQLite can scale to handle extremely large databases. Properly used, SQLite provides good performance for databases up to 100 GB, and a single row can hold up to 1 GB (although of course reading 1GB of data into memory is an expensive operation no matter how efficient the repository).
A BLOB often represents an attribute of an entity—for example, a photograph might be an attribute of an Employee entity. For small to modest BLOBs (and CLOBs), create a separate entity for the data and create a to-one relationship in place of the attribute. For example, you might create Employee and Photograph entities with a one-to-one relationship between them, where the relationship from Employee to Photograph replaces the Employee's photograph attribute. This pattern maximizes the benefits of object faulting (see Faulting and Uniquing). Any given photograph is only retrieved if it is actually needed (if the relationship is traversed).
It is better, however, if you are able to store BLOBs as resources on the file system and to maintain links (such as URLs or paths) to those resources. You can then load a BLOB as and when necessary.
Analyzing Fetch Behavior with SQLite
You can use the user default com.apple.CoreData.SQLDebug to log to stderr the actual SQL sent to SQLite. (Note that user default names are case-sensitive.) For example, you can pass the following as an argument to the application:
-com.apple.CoreData.SQLDebug 1
Higher levels of debug numbers produce more information, although this is likely to be of diminishing utility.
The information the output provides can be useful when debugging performance problems—in particular it may tell you when Core Data is performing a large number of small fetches (such as when firing faults individually). The output differentiates between fetches that you execute using a fetch request and fetches that are performed automatically to realize faults.
Analyzing Application Behavior with Instruments
There are several Instruments probes specific to Core Data:
Core Data Fetches. Records invocations of
executeFetchRequest:error:, providing information about the entity against which the request was made, the number of objects returned, and the time taken for the fetch.Core Data Saves. Records invocations of
save:and the time taken to do the save.Core Data Faults. Records information about object and relationship fault firing. For object faults, Instruments records the object being faulted; for relationship faults, it records the source object and the relationship being fired. In both cases, it records the time taken to fire the fault.
Core Data Cache Misses. Traces fault behavior that specifically results in file system activity—the instrument indicates that a fault was fired for which no data was available—and records the time taken to retrieve the data.
All the instruments provide a stack trace for each event so that you can see what caused the event.
Additional Performance Information
Like all technologies, Core Data can be abused. You still need to consider basic Cocoa patterns, such as memory management. Also consider how you fetch data from a persistent store. Take into account factors not directly related to Core Data, such as overall memory footprint, object allocations, use and abuse of other APIs such as the key-value technologies, and so on. If you find that your application is not performing as well as you would like, use profiling tools such as Instruments to determine where the problem lies. See Performance in the Mac Developer Library.
Copyright © 2018 Apple Inc. All rights reserved. Terms of Use | Privacy Policy | Updated: 2017-03-27