-
计算机视觉框架中的文本识别
借助计算机视觉框架中的文稿摄像机和文本识别功能,您可以从图像中提取文本数据。了解如何在您的 app 中利用这项内建的机器学习技术。更深入地了解快速处理和准确处理之间的区别,以及基于字符的识别和基于语言的识别之间的区别。
资源
- Structuring Recognized Text on a Document
- Extracting phone numbers from text in images
- Locating and displaying recognized text
- 演示幻灯片 (PDF)
相关视频
WWDC21
WWDC20
WWDC19
-
搜索此视频…
大家下午好 我是 Frank Doepke 我将要探讨的是 Vision 框架中的文本识别 如今 熟悉 Vision 的人 都知道我们已经有了 VNDetectRectangleRequest 它可以告诉你图像中的文本在哪里
出于某些原因 我们总会遇到一个问题 文本是什么 所以我们需要一些 额外的代码来解答 它将你的结果以数组存放
然后你需要训练 实际上可以读取这些内容的 Core ML 模型
接下来运行 Core ML 模型 滤除不好的特征 你把所有这些字符 放到一个字符串中 然后想出一些 启发性的方法并从中真正 形成句子和单词
所以现在你明白 为什么我们需要一个完整的会议 来讨论文本识别 但今天我想让这更容易些
我们带来了一些新东西 那就是 VNRecognizedTextRequest 也就是你在这里 看到的一小段文本 它让你从这样的图像中 进入这样的可识别文本 谢谢 好的 那么今天 我们要介绍什么呢 首先我们来谈一谈 文本识别的工作原理
我们有许多示例 App 它们也都 添加到了会议资料中 因此你可以下载示例代码
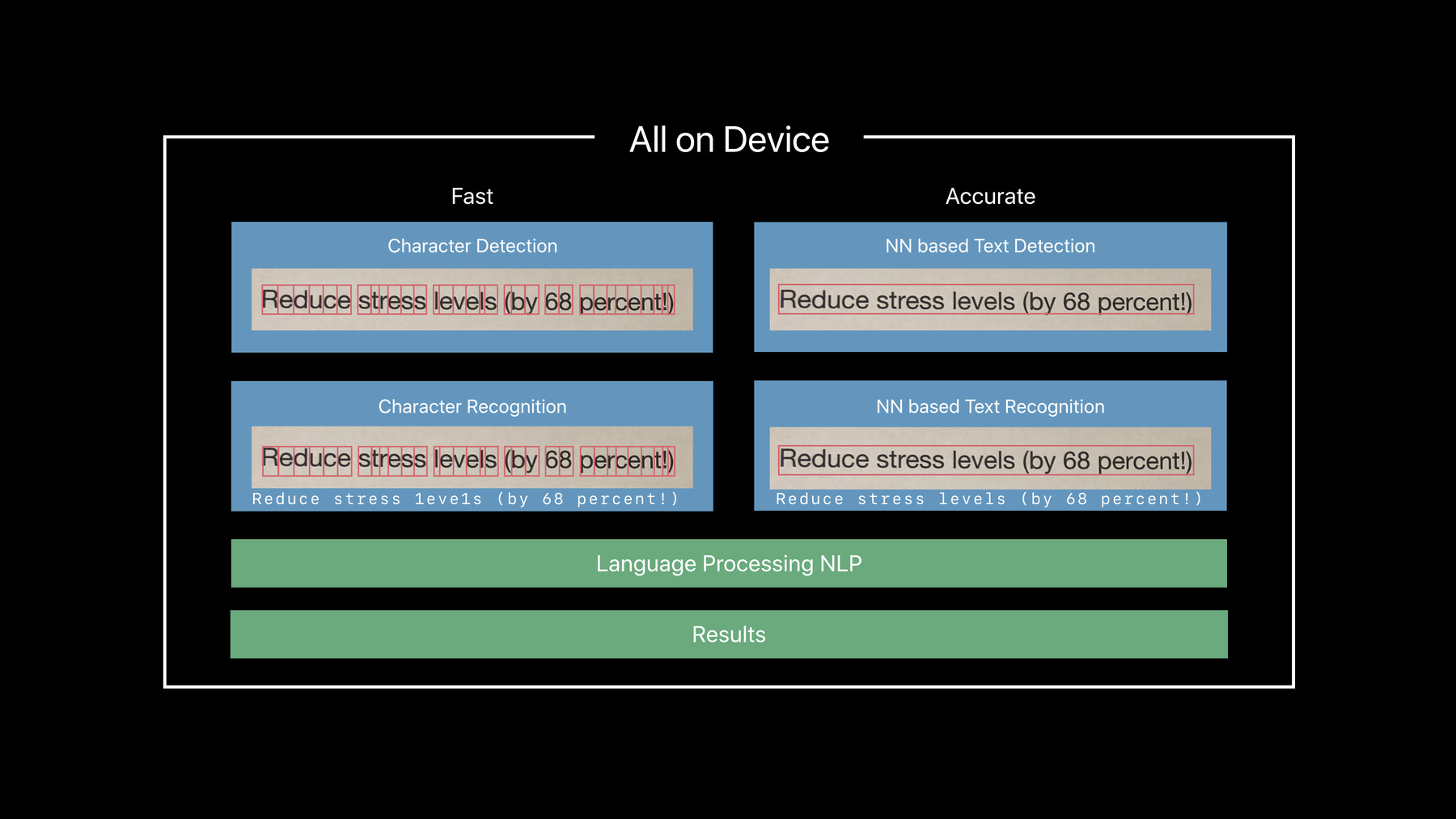
最后我们将介绍一些关于 如何在 Vision 中使用文本识别技术 来工作的最佳实践 那么 文本识别是如何在 Vision 中实现的呢 我们有两条路可供选择 快速路径和精确路径
快速路径实际上 是通过查找字符来实现 文本检测器之前所做的工作 然后推进一个小型机器学习模型 来实际地识别 这些字符 逐个识别
而精确路径 则使用最先进的 神经网络 通过首先以字符串和整行 来识别文本
然后将其识别为 单词和句子
因此它要求一个 深度学习模型 这要花费更多时间来计算 但它读得更多 就像我们实际阅读文本
我们不逐字阅读 我们以单词为单位阅读 这有助于我们了解 你也知道某些字符可能有点 难以阅读 这也是为什么 当我们试图校对我们的文本时 我们看不到错别字 因为我们的大脑 会对这些错误进行插补 所以我们在精确路径中 使用相同类型的技术 来帮助我们克服 一些识别错误
之后的两个阶段 实际上都会经历一个 语言矫正阶段 这有助于我们再次 消除一些典型的误读
我们得到了结果 你可能认为这是一个复杂的机器 但这一切都发生在设备上
下面我们一起来看一下 快速路径与精确路径的区别
我做了一个 阅读这个文件的屏幕录制 因为我是在一个相对较旧的 MacBook Pro 上做的 所以你看到的时间 不一定具有代表性 不过我想给你一个直观感觉 接下来我们看看快速路径有多快
已经完成了 下面再来看看 精确路径需要多长时间 你看到了过程吗 它花的时间更长一点 正如我所说 这些数字并不能说明一切 但它能给你一个直观感受
另外你还可以看到 在阅读整篇文章方面 精确路径的效果更棒 快速路径顶部的 程式化字体有一点问题
因此在这两条路径之间 有一些方面需要权衡 让我们来看看这些权衡 快速路径是为了 实时阅读 并为此进行了优化 但是精确路径 更有可能以一种 异步方式使用 在内存预算方面 快速路径使用较少的内存 因为它不需要运行大型神经网络
但是当涉及到 旋转文本或透视错位文本时 精确路径会为你 提供更广泛的支持
当涉及到样式或字体时 就如同你在示例中 看到的那样 当涉及到样式化文本时 精确路径再次提供 更广泛的支持
最后 当涉及到自然语言的 真实阅读时 我们会推荐精确路径 因为它在该部分
表现最好 那么你如何在这两者之间做出选择呢
你所拥有的用例 是实际驱动你 想要如何使用请求的 重要部分
你还需要考虑一些事情 比如我的输入是什么 我是在使用相机 还是已经在照片库中 得到了要处理的图像
我的处理限制是什么 我可以在这个请求上花费多少时间 我有多少可用的内存 一些进程可能会 受到内存限制以及最后 我将如何处理这些结果 用它们来转录吗 还是用来搜索呢 或者只是根据我 通过相机读取的内容执行操作 下面我们再来谈谈 相机捕捉的细节
相机捕捉技术 可以用作实时捕捉 所以你现在实际上 想要使用字符串读取 并保持帧速率 在这种情况下 快速路径最有可能是 你想要使用的路径 不过这里也存在着 机会性捕捉 我的意思是 例如 你拍了一张照片 照片中的某个地方有文本 你想处理它 你不需要跟上 相机的帧速率 但你事实上希望 使用它来读取文本 因此精确路径 最有可能提供更好的结果
当我们谈论相机时 还有一件事要考虑 我需要在我的 App 中 设计使用哪种分辨率 而文本大小 实际上会驱动这个问题 如果出于某种原因 你想阅读 法律文件的细则 你可能真的需要 增加相机的分辨率 或者当你阅读 带有大文字的广告牌时 你实际上可以降低分辨率 用更少的内存工作 且速度实际上也会更快
现在涉及到后期处理 我们已经在一个文件中 保存了图像
你最有可能选用精确路径 因为这样你可以 实际使用更好的准确性 而速度显得并不那么重要
接下来 我们来谈谈语言处理 正如我提到的 语言处理 是文本识别中 可以使用的阶段之一
它有利于帮助我们 克服一些在阅读文本时 可能会发生的典型误读 但另一方面 它也会产生阻碍 当我想读取 代码或序列号时 像 C001 这样的序列号 它很容易被误认为是 Cool
此外这种语言修正 不是免费的 它确实需要一些处理时间 并且需要使用一点点内存
现在我们已经掌握了 一些基本的方法 接下来我们就来谈谈 如何执行文本识别
Vision 中的所有内容 都从 ImageRequestHandler 开始
下面我创建我的请求 我在上面设置了 completionHandler 这就是我 处理结果的地方 然后设置 recognitionLevel 如我所说 我可以在快速和精确之间切换
接下来 我建议你实际设置 revision 当然这里只有一个修订版 但是接下来我们将 推出改进的版本 你可能已经将算法 调到了我们拥有的特定行为 如果不指定修订版 你将始终获得最新版本 这样的话 可能会出现一些意外
所以 我建议你们 了解如何使用修订版 最后 我可以打开和关闭语言修正 当然我还需要 执行我的请求
当执行请求时 我们会得到结果 这些结果作为 VNRecognizedTextObservation 返回 我们得到的基本上 就是我们要找的行和字符串
因此我们需要迭代这些结果 然后我们想要得出文本 实际上我们有多种候选 稍后我会谈一下 其中一些候选 为了简单起见 我只得到了我的最佳候选 并且得到了自己的文本 我可以获取边界框 这帮助我 把所有的文本 放在屏幕上或屏幕上的图像中
但现在当我想使用搜索时 例如用户键入 在文档中读到的单词 我们想在图像中 再次找到 这个单词的实际位置时 我可以向候选询问 我在结果中实际看到的 这个字符串的 边界框在哪里
现在了解完整个理论 我们来看一些例子 做一些实时的文本识别 这就是我们想要使用 快速路径的时候 这里使用的例子是 我想读取序列号 或代码之类的东西 我在这里使用的序列号 实际上是一个电话号码 因为它对每个人来说 都是最容易理解的 我真的想 像读条形码一样读它们 有了这个 我就可以限制相机 如何实际地查找文本 不过交互性是关键 因为它应该是活跃的 它也应该很快 以便可以引导用户 并立即读取文本
所以这就是我为什么 在这里选择快速路径 然后我们来看看演示
好了 我这里的示例代码 就像我之前说的 也附在这个会议资料中 允许我读取电话号码 所以当我扫描这个文本时 你会看到一个小白框 这意味着我找到了文本 但我没有读它 因为它不是电话号码 甚至不是邮政编码
但一旦我找到一个电话号码 它就会读出来并停止扫描 我再展示一次 它给人以互动感 作为一个用户 我很容易使用它 即使我的手在颤抖
那么这在代码中 看起来如何呢 因为这是真正有趣的部分
所以我从创建文本请求开始
正如我所说 我将在这里使用快速路径 我禁用了语言修正 因为我知道 我正在寻找代码 而不是在找自然文本 然后我使用 regionOfInterest 这是一个设想的概念 并且普遍可用 你会注意到 在我的 App 中有一个小方框 可以指导用户 在想要的位置构建文本 但是我也可以将这个区域 作为兴趣区域 这会使 Vision 只针对该特定对象 这有助于我消除周围的所有噪音 因为它需要处理的数据更少 提高了性能 现在我有我的请求 我在这里使用 AVCapture 会话
关于捕捉输出 我所要做的就是 从会话中获取我的图像 创建 RequestHandler 并执行请求 然后 这主要是框的绘制 那还不是有趣的部分
有趣的部分发生在 我们的字符串工具中 就像我说的 我们关闭了语言修正 我现在只能自己去修正其中的一些结果 不过我能做好这一点 因为我对这里 需要解决的内容有内在的了解 我知道我正在寻找电话号码 而不是找其他字符 我只是在寻找数字路径 所以我可以简单地说 如果它读取的内容类似于 S 这将是一个 5 或者如果我得到一个 L 这应该是 1 我使用我的领域知识 来修正一些可能发生的典型错误
因此这个方式 帮助我们 不让任何字母通过 接下来是下一部分 我是如何区分 邮政编码和电话号码的呢 我知道其结构 美国电话号码的结构 非常简单 我再次利用这些知识 来过滤掉我不想要的结果
最后是字符串跟踪器 让我发现了这一点 现在我在这里使用一个小技巧 如果你曾经处理过 从相机输入中读取的东西 你会意识到 从一帧到另一帧 你会得到不同的结果 由于噪音 灯光等原因 它们略有波动 但是如果我拨错了电话号码 那就太糟糕了 因此我会尽量避免 显示错误结果 我在这里使用了一种技术 在其中我可实际查看 多个帧并随着时间的推移 建立证据 随着时间的推移 这种证据的建立意味着 我只需存储电话号码 最后 我所做的都非常简单 如果相同的数字 出现在 10 个连续的帧中 我就知道我已经读过它 并实际传播给了用户 现在我们选择 10 作为实验数字 它对我们来说非常有效 有了这个 我基本上过滤掉了 所有的噪音 这就是我们进行演示 运行中需要做的 现在我们回到幻灯片
我们来快速回顾一下 我使用快速路径 来保持相机的帧速率 我能够指导用户 如何使用相机 我通过感兴趣的区域 裁剪出我真正 想阅读的内容 以消除周围的噪音并提高性能 我关掉了语言修正 因为我知道 现在正在读代码 我使用自己的领域知识 来正确地读取它们 这就像你和 App 开发人员 对这个电话号码 所做的一样 最后 随着时间的推移 我使用这些证据 来实际帮助减少一些噪音
接下来我想介绍一下 扫描文稿相机
两年前 备忘录已经介绍了 扫描文稿相机 当你不需要 使用实时流捕捉它时 它是一个非常好的伙伴 今年你已经在 备忘录邮箱文件 和信息中看到过它 它已经非常适合 阅读文档 因为正如你在这里看到的 它可以找到文档 裁剪出来 现在我可以简单地将其输入到我的文本识别请求中 它是一个很好的伙伴 因为它所做的 只是对这些扫描的 一个前瞻性的修正 它均匀地照亮了图像 这使得后续处理 变得更加容易
那么这在代码中看起来如何 首先,我需要引入 VisionKit 这是一个新的框架 然后我创建了 VNDocumentCameraViewController 我把它呈现在屏幕上 我的相机正在运行
一旦用户完成了任务 我将在我的 Delegate 中得到结果 现在有一件事要记住 我们实际上可以 一次扫描多个文档 它们会以页面形式返回
从每一个图像中 我只需把我的 CG 图像 输入到我的 Vision 请求中 就可以得到相应结果 下面 关于一些最佳实践 就由我的同事 Cedric Bray 向大家介绍更多有关的详细信息 谢谢 谢谢 Frank 我很高兴我们今年 能将文本识别 纳入 Vision 框架当中 为了帮助你 充分利用这个新 API 我们将讨论最佳实践
因此在本节中 你将学习到语言知识 以及如何利用 语言知识获得最佳结果 你还将学习 如何在 App 中调优 以获得更好的性能 你将学习更多 关于如何以最有效的方式 处理结果的知识
所以你正在 处理的图像 可能使用了你 已经识别的语言 如果在这个 特定的语言中存在 那么你会想要利用这个信息 为此你需要启用 基于语言的集合 首先你必须 设定目标语言 这里 我们支持英语 一旦启用基于语言的校正 它将使用设备上的 语言模型 来改进结果的转录 设备上的语言模型很棒 它们有很大的 通用覆盖范围 但文档中可能会出现 特定于域的单词 特定于域的词汇表 如医学术语 或特定于业务的代码 或文档中出现的引用 我们可以通过 将自定义词典 传递给文本识别请求 来指定此信息 即此词汇表
当这样做时 这个自定义词汇表 将补充基于语言的校正 以便为你提供 正确的转录 即使在图像更具挑战性的情况下也是如此
接下来让我们看看代码中的情况
首先作为前提条件 你需要检查 基于语言的更正所支持的语言
因此此受支持语言列表 是针对识别级别 和你要定位的 API 版本的组合定义的
启用基于语言的校正很简单 只需在文本识别请求中 将相应的属性设置为 true 初始化自定义单词 可以将此单词列表 指定为字符串数组 并在文本识别请求时 传递给自定义单词属性
因此这对于 优化准确性 转录准确性非常有用 但是性能呢 还有一个很常见的情况 你可能对 图像中的较小文本不感兴趣
对于这种情况 我们建议你调整 minimumTextHeight 它的工作方式是 当设置这些 minimumTextHeight 时 所有小于指定高度的文本 都将被忽略 它不会被处理 不会成为结果的一部分 输入图像会缩小 执行时间也会缩短 识别速度会更快 内存使用率也会下降
关于这个属性 一个重要注意事项是 它表示为图像高度的一部分 正如你在示例中看到的那样 如果我说 0.5 则表示将返回大于 或等于图像高度 一半的文本 当你想更快识别文本时 就会出现这种情况
但是如果文本识别 不是 App 中最高优先级的任务呢 也许你还有其他 更高优先级的任务要运行 例如在前景中运行的 ARKit 视图可能是你 App 中的最高优先级 或者例如你正在运行 和实时处理的相机 AR 帧也可能是 那么在后台任务的情况下 我们只允许你 在 CPU 上运行文本识别 这样你可以将 GPU 资源 和可选的神经引擎 保留给 App 的更高优先级任务
你可以使用 useCPUOnly 属性执行此操作 它是一个可用于 其他 VN 请求的属性 也适用于所有 其他 VN 请求和文本识别支持
当你故意让文本识别 运行得更慢的时候 就会出现这种情况 但也有一些情况下 图像非常大 文本和文本识别会很多 需要的时间更长 除非你提供进度管理 否则用户会感到困惑 我们强烈建议你
在 App 中关注进度管理 这是今年 Vision 的一个新概念 文本识别完全实现了这一概念 它有两种方式 第一种你可以 根据请求设置 ProgressHandler
这样做时你将获得进度比率 它是作为 ProgressHandler 的参数
另外你也可以在 App 中支持取消 例如如果向用户 提供按钮 则可以取消 在其前面运行的文本识别 所以这是一系列概念 为了解释它们 我想向你们 展示一个示例 App 的演示 我们也在会议资料中提供它 我将它称为 My First Image Reade 下面我们一起来看看这个 App
所以正如你将看到的 这个示例代码 My First Image Reader 作为主窗口 以及一个转录面板 主窗口将显示 图像和结果的几何图形 转录窗口将显示文本 如果仔细看窗口顶部
在工具栏上 你会发现可以在精确 和快速之间进行选择 所以这真是一个非常好的 简单的 App 下面我们一起来看看 还有我们刚才 提到的其他设置 性能设置 最小文本高度 稍后我会再回过头来看 在此视图中 你还可以 访问语言设置 启用语言模型 以及自定义单词 现在我用一个
精心设计的示例快速向你展示
假设我拿出一张 我拍摄的图片 并说这是一本书的封面 上面有非常小的文本 恰好是我的名字
你能发现你得到的文本非常小 我的名字在这里被找到 并被识别出来 显然对于非常大的文本 亦是如此
现在假设 我有一堆这样的图片 我只想索引这些图片的标题 我不太关心小字体 特别是我的名字 因此我将调整 最小文本高度 以使识别运行更快 你可以将其设置为 0.1 那么文本必须 至少为图像高度的 90% 这就是大文本 Desert Dunes 的情况 下面将这些设回 0
我来向你展示语言设置 特别是自定义单词的影响
如果我把这个传单拖到这里 这个项目名为 Hill Side 它也有一个可能的数字 一个参考数字 碰巧是 HI11 所以这里可能存在混淆 现在我来给你看转录结果
可以看到参考数字实际上 在这里被误识别了
所以我们要不断改进 如果因为 HI11 是 已知的引用的一部分 我将其指定为自定义单词 那么我们通过修正 完成了自定义 尤其是自定义单词列表 并为我们 提供了正确的转录 回到幻灯片 谢谢
快速回顾一下
你需要选择 最适合你 App 用例的识别级别 快速 准确 找到对的那个 语言设置方面 我们建议你 根据所拥有的文档类型进行检查 如果存在明显的语言 相邻语言修正 如果你具有特定于域的词汇表 请启用自定义词 指定自定义词
此外非常重要的是 你需要在 App 中 支持进度更新 以获得最佳用户体验
现在就算你 遵循这个建议 仍然有一个非常重要的方面 需要去注意
那就是你需要处理结果
你还需要提供一个方法 用自己的方法 来向你的用户展示结果 不过这个方法
可能并不与字母相关
我的意思是 为了获得最佳用户体验 你需要以最有效的方式处理结果
那么我们来看看怎么做
首先要声明很重要的一点 你应该预料到输入中存在歧义
这就是计算机视觉 这是一个开放式问题 我们的参数术语将影响你 正在处理的图像的内容 事实上 这里的门牌号是很有趣的
因为其中的一些非常风格化 当你对它们运行 生成文本识别器时 它们并不知道自己应该成为数字 对吗 你得到的不是 101 而是 lol 或者你可能得到文本表情 一个快乐的人举起手 在那种情况下 不知道你有没有听过 但我们坚持认为 从观察结果来看 你需要利用候选名单 拥有的最佳候选名单 请参考此候选列表 如果它适用于你的 App 请查看前一个 前两个 前三个或更多结果 有一个典型的例子 比如你想要 索引图像的内容 如果你想增加召回率 你可以为每个结果 索引更多的候选对象 当然 以精度为代价 对吗 所以这个候选名单 我们需要深入研究 但这只是一个维度 这是预测置信规模 其他维度怎么样呢 那么图像空间呢 我们建议你 评估并重新考虑 使用几何图形来映射结果
你有边界框 它为你提供空间信息 你可以使用 结果的位置 比例 以及旋转 将这些结果映射到一起 我们在这里 显示的示例 如果是收据 你可以将项目名称 映射到价格
这是几何的 但是对于 每个孤立的结果 你还有机会 使用解析器并尝试 理解每个结果 在这种情况下 数据检测是你最好的朋友 它会为你感兴趣的类型 启动 NSDataDetectorr 你也可能明白 它支持地址 URL 日期和电话号码
在我的名片示例中 我可以使用它 来理解一些结果 但是如果这还不够 你可以使用自己的 特定于域的功能 拥有自己的词汇表 来匹配字符串 或者使用自己的正则表达式
为了说明这些原则 我们有另一个示例 App 这次是一个 iOS App 名为 Business Companion
假设你因为想要 收据扫描仪 坐在房间里 有人是这么想的吗 也许吧 亦或是一台名片读卡器 也可能是对名片感兴趣的人
那么这个 App 就是你真正要看的东西 因为它将两个流混合到同一个 App 流中 我来教你怎么做
首先它有文档类别选择器 很快就会看到它是如何工作的 这只是第一个屏 这样就可以选择 你感兴趣的文档类型 从那里进入你之前听说过的 文稿扫描相机 从文稿扫描相机那里 我们运行文本识别 从识别的结果中 我们执行一些分析 来理解这些结果 这才是真正重要的 因为基于这种分析 我们将能获得一些 收据名片的数据模型 在本例中 我们对文档类型进行了分析 从这个结果分析中 假设你了解数据 在表格视图中 显示收据的情况下 你还可以更适当地 将结果可视化 如果我们有名片 会显示联系人名片 下面我来展示这个 App
在这里切换到 iOS 设备
所以这是 Business Companion 正如我告诉你的 我们可以在收据 卡片和其他类型的文件 之间进行选择 我们从收据开始 首先是扫描文稿相机 我们在这里有一些挑战性的亮点
当文档被捕捉和处理时 是的 我们的结果 是结构化的 你可以看到项目名称 你可以看到每个部分的 类别名称和值 现在假设我看一张名片 00:34:14.456 --> 00:34:18.686 A:middle 同样我会分析
名片的每个字段 这就是我的迷你名片 谢谢大家
就像我说的这很好 但看看这个前面的屏 仍然需要你 手动选择文档类型 它并不是真的无缝 你可以使它更加无缝 对吧 实际上我们已经做到了 现在我来展示 这个 App 的进阶版本 它被称为 Better Business Companion 其实我们所做的 就是我们使用 Create ML 训练了一个分类器模型 我们将这个分类器 作为第一步 这样就不必指定文档类型了 它将自动选中 说得差不多了 我来演示一下
很明显 第一个按钮从大按钮 变成非常小的按钮
这里只有 Scan 按钮 我这里有收据 你同样可以看到
无需用户指定文档类型
即可作为 收据处理
为了向你展示 它如何与名片一起使用 再次用我名片举例
好的 我们正确处理了名片 我说过我们为这个 集成了 Core ML 模型 我想向你展示一下
我们在这里进入 Xcode 这是代码 实际上这是我们 从 Business Companion 修改的代码 我们添加了一个插入 Core ML 模型 在这里 我们插入此 Core ML 模型 以使用 completionHandler 设置请求 作为处理程序的一部分 你可以看到 我们处理了 topObservation 和标识符的日期 抱歉 topObservation 的标识符 我们为 App 设置扫描模式 以确定该 App 其余部分的流 00:36:56.906 --> 00:36:58.916 A:middle 因此我们鼓励你
思考如何使用文本识别 来改进 App 流 以及如何适当地 处理结果 同时利用像这样的 ML 模型 好 再次回到幻灯片 简单回顾一下
正如我所提到的 我们鼓励在有意义的时候 使用几何信息 通过使用数据检测器 或自己的解析器 来解析理解结果 最重要的是 你要明白自己在创建什么 你知道需要查看 哪种类型的数据 因此我们建议 利用你的领域知识 获得最佳用户体验
我们也希望这能 给你提供一个很好的参考 帮助你将文本识别集成到 你的 App 中 我已迫不及待想看到 你将用这项技术创建的 所有精彩的 App 如果你还有疑问 可以访问机器学习实验室 明天还有一场 谢谢大家 [掌声]
-