-
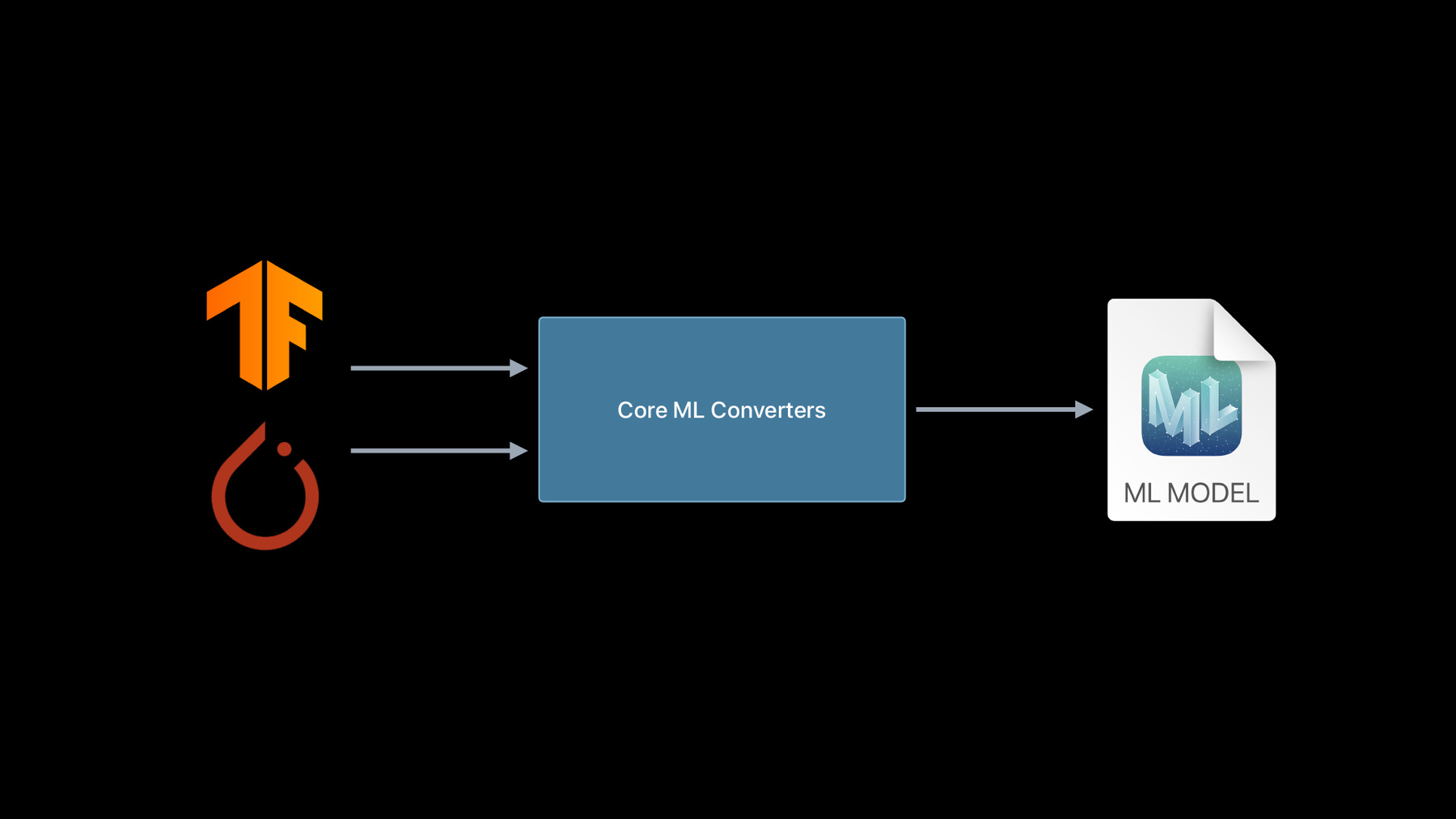
使用 Core ML 转换器 为设备获取模型
借助 Core ML,你可以将优秀的机器学习模型应用至你的 app,并在设备上完整运行。 并且,在你使用 Core ML 转换工具时,几乎可以将 TensorFlow 或 PyTorch 中的所以训练过的模型都应用其中,并充分利用图形处理器,中央处理器和神经网络引擎。了解如何从其他 ML 平台转换现有模型,并了解如何创建可扩展模型功能的自定义操作。
如果你已经将模型转换为 Core ML,想进一步了解有关这些模型的部署策略,请观看 “通过 Core ML 使用模型部署和安全性”。资源
相关视频
WWDC23
WWDC22
WWDC21
WWDC20
-
搜索此视频…
(你好 WWDC 2020)
你好 欢迎来到 WWDC
(使用 Core ML 转换器 为设备获取模型) 你好 我是 Core ML 团队的 Aseem 在本视频中 我想与大家分享 Core ML 转换器几个令人兴奋的新进展 我们一直在努力优化 将模型转换为 Core ML 的使用体验 并且我们对转换工具进行了重大更新
不过 让我们首先来看一下 为什么说 Core ML 刚好为 将机器学习集成到你的 app 中 提供了一个绝佳的解决方案 自从 2017 年发布 Core ML 以来 我们的任务一直是让机器学习模型 可以尽可能轻松地部署到你的 app 中 从而创造出各种引人入胜的体验 通过 Core ML 我们可以很方便地 将同一个模型 部署到所有类型的 Apple 设备中 并且保证了跨 OS 和不同代设备之间的 最佳兼容性和性能 Core ML 模型无缝地利用了 设备上所有可用的硬件加速 不管是中央处理器、图形处理器 还是专门为加速神经网络 而设计的 Apple 神经网络引擎 此外 随着每次新版本的发布 你都可以获得最佳的 Apple 生态系统 例如 今年我们推出了 Core ML 模型部署 以使你可以轻松地更新模型 而且 现在还可以加密 Core ML 模型 想了解更多详情 请查看 “Core ML 模型部署与安全”视频 因此 说实话 Core ML 模型开启了 通向这些出色体验的大门 本视频的主题就是 如何创建 Core ML 模型 Core ML 可以表达多种机器学习模型 从深度学习模型到基于树的模型 都可以通过 Core ML 进行表达 当然 Create ML app 是创建 Core ML 的最佳资源之一 但是你也可以 使用 Core ML Tools Python 套件 从你最喜爱的框架中 轻松地创建一个 ML 模型 随着时间的推移 ML 生态系统不断发展 Core ML 转换器会不断 向更多的框架提供支持 今年 我们发布了一些激动人心的消息 是有关我们对神经网络库的支持
目前 我们已支持 转换其中一个框架之中的神经网络模型 今年我们重点介绍了 深度学习社区最常用的两个资料库 分别是 PyTorch 和 TensorFlow 让我们首先来看一下 TensorFlow
目前 如果你想要 将 TensorFlow 模型转换为 Core ML 则必须另外安装 tfcoreml 并使用其 API 该 API 的内部 依赖于 Core ML Tools 套件 但这已经发生了变化 现在你只需要 Core ML Tools 我们现已将 TensorFlow 转换 完全集成到 Core ML Tools 中了 我们也很高兴地宣布 对 TensorFlow 2 的支持得到极大扩展 TensorFlow 1 现已通过 TF Core ML 得到了一段时间的支持 并且在去年 我们增加了对 TF 2 卷积模型的支持 今年 我们的支持大大地扩展至动态模型 例如 LSTM、编解码器等
新型转换器支持 TensorFlow 模型 导出的所有不同格式 让我们现在看看从 PyTorch 进行的转换 目前 我们是使用 PyTorch 导出工具 来生成一个 ONNX 模型进行转换的 然后使用 ONNX Core ML 以获得 ML 模型 但是很多时候 第一个导出步骤可能会失败 因为 ONNX 是一个独立进化的开放式标准 因此它可能缺少 PyTorch 的新增特性 或者是 torch 导出器未更新 又或者是可能存在错误 因为我们使用了新的 PyTorch 转换器 所以消除了这一额外依赖性 现在 从 torch_script_model 开始 只需一步就可完成这一过程
你可能已经注意到 调用 PyTorch 转换器的 API 与之前 TensorFlow 使用的 API 完全相同 这是因为我们重新设计了 API 以保留一个调令来调用所有转换器 它都可以进行调用 不管模型需要从哪个源框架进行转换
通过这些变化 Core ML Tools 现在成为了 从 TensorFlow 和 PyTorch 进行模型转换的一站式商店 并且不仅仅是 API 发生了更改 我们不只是添加了两个新的转换器通道 相反 我们付出了巨大的努力 来重新设计转换器架构 以显著提升用户体验和代码质量 因此 我们从之前拥有分开的转换器管道 这些管道是在不同时间点 通过添加不同的转换器所建立的 转变成了一个最大限度 重用代码的单一转换器堆栈 而为了实现这种整合 我们引入了一种新的内存表式法 称为模型中间语言 简称 MIL MIL 旨在简化转换过程 并使为新框架添加支持更加简单 它通过提供一个共同的接口来统一堆栈 以从不同的框架中获取信息
它具有一套运算、优化过程 和模型构建器 API 作为终端用户 你通常不会与 MIL 进行交互 但它在某些场景中确实非常有用 我们会在本视频稍后部分再次讨论 MIL 我们首先来看一些使用新转换器的示例
让我们从简单的图像分类器示例开始 以熟悉新的统一 API 为此 让我切换到 Jpyter 笔记本 这是在 Jpyter 笔记本中 而且我已经导入了 Core ML Tools 让我们首先从 TensorFlow 2 进行转换 这个我也已经导入了 我会从 TensorFlow 2 模型 zoo 中 抓取一个模型
我正在使用 MobileNet 模型 这是用于图像分类最流行的卷积模型 让我们加载它
然后进行转换
为此 我只需键入 ct.convert
并为其提供 TensorFlow 模型对象 然后按下回车键
转换器就会自动检测模型的类型 它的输入形状、输出等 然后继续通过 MIL 进行转换 好了 完成 这非常简单 我们为什么不再试一次呢? 这次我们使用 PyTorch 的模型
为此 我先导入 torch 和 torchvision 我这次从 torchvision 中抓取 mobilenet v2 模型
现在 我们需要一个 TorchScript 模型转换为 Core ML 这可以通过脚本编制或追踪来实现 在这里我将使用追踪的方法
我们可以通过 PyTorch 提供的函数进行追踪 让我们来看看这是如何进行的 我们首先使用 eval 以在推理模式下获得该模型 然后调用 jit.trace 方法 该方法需要一个示例输入才能起作用 让我们按下回车键 好了 我们有追踪模型了 现在我们可以 使用 Core ML Tools 来进行转换
我再次键入 ct.convert 这次 我提供了追踪模型 现在还有一件事 通常 输入形状的信息 不存在于 TorchScript 模型中 但这是进行转换所必需的 因此 让我们将其提供给转换器 这可以通过使用输入参数来完成 我会提供输入的类型和形状 而我可以通过 TensorType 类来实现这点 TensorType 类可接受形状
就是这样 让我们按下回车键
我们看到了转换到 MIL 的熟悉步骤 经过几次优化 最后转换到 ML 模型 这样就完成了 让我们通过打印 ML 模型对象 来检查模型界面
让我们一起来看看 我们看到 这有个名为 input.1 的输入 并且它是 multiArray 类型 因为我们在这里提供了 TensorType 这里有个名为 1648 的输出 嗯 这有一点奇怪 实际上 这是 torch 模型中输出张量的名称 转换器自动地从这里取得了它 好的 我们可以很容易地 将其重命名为更有意义的名称 让我们来看看如何进行
因此 我使用 Core ML Tools 中的 重命名功能实用程序 将输入和输出重命名为我想要的名称 在本例中 我使用了占位符名称 让我们按下回车键 然后再次打印 ML 模型对象 很好 因此 我们看到输入和输出的名称 已更新为我所提供的名称
现在 让我进行最后一次转换 这次从 TensorFlow 1 进行转换 为此 我换个笔记本 在这里 我已经设置好了 TensorFlow 1 环境 我也提前下载了 mobilenet TensorFlow 1 模型 它的格式是 protobuf pb 随着该模型一起的还有 label.txt 文件 其中包含了这个模型所训练的类的名称 我们来转换下该模型
我们会调用熟悉的转换 API 现在 我们可以为其提供 protobuf pb 文件 这样就可以了 但是 这次我们通过一些额外的事情 来构建一个不错的 Core ML 模型 之前 我们使用过 TensorType 但你知道 由于此模型确实可以在图像上运行 所以最好让转换器知道这一点 我可以 通过使用 ct.ImageType 类来实现这点 我将向该类提供几个预处理参数 为每个
RGB 图像中的通道 提供偏差和比例
这将按照 mobilenet 模型的预期 将图像标准化
我要更改的另一件事是 由于该模型执行分类 因此 生成一个分类器 Core ML 模型 可能是一个好主意 这可以 通过使用 ClassifierConfig 类来实现 它可以原样采用 label.txt 文件 是不是很棒? 让我们按下回车键
我们完成了 让我们把该模型保存到磁盘上 不过在此之前我将添加一些 关于许可证和作者的有用的元数据 然后我将键入 mlmodel.save 来保存该模型
我会将模型命名为 mobilenet.mlmodel
现在我可以看到它已经在磁盘上了 让我们在 Finder 中检查该模型 我们可以看到模型在这里 让我单击打开它 它会在 Xcode 中自动打开 今年 我们更新了 Xcode 用户界面 对于现在的分类器来说 可以在这里看到类标签 如我们所见 该模型大概有 1000 类 还有一个名为 Preview 的新标签 这非常方便 我非常喜欢这个标签 我们可以在这里简单地拖放一些图像 它将自动在这些图像上运行我们的模型 并显示预测结果 就像我们在这里看到的那样 我们的模型在这些图像上看起来表现不错 转换 API 演示到此结束了 让我们一起来回顾一下 我们使用不同的模型类型调用了转换函数 并且该函数起作用了 现在让我们尝试转换 一个稍微复杂的模型 为此 我想邀请我的同事 Gitesh 他将对用于将音频转换为文本的模型 进行转换 谢谢 Aseem 你好 我是 Core ML 团队的工程师 Gitesh 在此次演示中 我将演示灵活形状的自动处理 以及新的 Core ML Tools 转换 API 的相关功能 我将使用自动语音识别任务进行演示 在此任务中 输入的是一个语音音频文件 而输出的是其文本转录 自动语音识别有很多方法 我在示例中使用的系统包括三个阶段 有预处理和后处理阶段 中间还有一个 完成主要工作的神经网络模型
预处理包括 从原始音频文件中提取 mel 频谱 也称为 MFCC 这些 MFCC 会输入给神经网络模型 该模型返回一个概率分布的 字符级时间序列
然后由 CTC 解码器进行后处理 生成最终的转录
预处理和后处理阶段采用了 很容易实现的标准技术 因此 我的重点是转换此模型的中间部分 我使用了一个名为 DeepSpeech 的 预训练 TensorFlow 模型
在高层次上 该模型使用一个 LSTM 和几个堆叠的密集层 而这样的架构 对于 seq2seq 模型来说相当常见 现在 让我们直接进入 Jupyter 笔记本 将模型转换为 Core ML 并对一些音频样本进行尝试 我们从导入一些套件开始 我从 Mozilla 的 GitHub 存储库中 找到了 DeepSpeech 模型的预训练权重 并且已经下载了这些权重和一个脚本 以从该存储库中导出 TensorFlow 1 模型 让我们运行此脚本
我们现在有一个 protobuf 格式的 TensorFlow 冻结图 让我们来看看该图的输出内容 为此 我已经编写了一些检查应用程序
所以 这个模型有四个输出 这是第一个输出名为”mfccs“ 代表预处理阶段的输出 这意味着输出的 TensorFlow 图 不仅包含 DeepSpeech 模型 还包含了预处理子图 让我们把剩下的三个输出名 提供给统一的转换器函数 从而将这个预处理组件剥离出来 有了这些信息 让我们调用 Core ML 转换器
非常好 转换很成功 现在让我们 在音频样本上运行此转换后的模型 首先 我们加载并播放音频文件
从前 这里有一只怒气冲冲的鸡 他遇到了一只金色的老虎 他们一起穿过绿色的森林 完 接下来 我们对其进行预处理 为了使整个管道都能在此笔记本中使用 我已经使用 DeepSpeech 存储库中的代码 构造了这些预处理和后处理函数
所以 这个预处理已经把音频文件 转化成了这个形状的张量对象 这个形状可以看作是一个音频文件 被预处理成 636 个序列 每个序列的宽度是 19 且包含 26 个系数 这些序列的数量 会随着音频长度的变化而变化 对于这个 12 秒的音频文件 我们有 636 个序列 现在 让我们检查下模型期望的输入形状
我们看到这个模型的第一个输入 几乎有了正确的形状 唯一的区别是 它可以一次处理 16 个序列 因此 我将编写一个循环 把输入的特性分成几块 并把每一段逐一提供给模型 我已经写了这段代码 让我把它粘贴在这里 你不需要遵循所有这些代码 基本上 我们将预处理后的特性 分解为大小为 16 的切片 并在循环中 通过状态管理 在每个切片上运行预测 让我们运行它
很好 转录看起来非常准确 现在 一切看起来都不错 但是如果我们可以 一次就对整个预处理特性进行预测 那不是很棒吗? 这是有可能的 为此 我们需要一个动态的 TensorFlow 模型 让我们从 DeepSpeech 存储库中重新运行相同的脚本 以获得动态图 这次 我们提供了 一个名为“n_steps”的附加标志 该标志对应于序列长度 并且默认值为 16 但是现在我们把它设置为 -1 这意味着序列长度可以取任意的正值
我们有了新的 TensorFlow 模型 让我们对其进行转换
太棒了 转换完成 让我们看看这个模型与前一个有何不同
我看到的一个区别是 这种 Core ML 模型 可以处理任意序列长度的输入 而区别不仅仅在于形状 在后台 这种动态 Core ML 模型 比前面的静态模型要复杂得多 它有很多动态运算 比如获取形状 动态重塑等等 但是 我们进行转换的体验是完全相同的 转换器可以像之前一样轻松地进行处理 现在让我们在相同的音频文件上验证模型
这次 我们不需要循环 可以直接将整个输入特性提供给模型 让我们运行它
太棒了 转录看起来又是非常完美的 让我们回顾一下在演示中看到的内容 我们使用了 DeepSpeech 模型的两种变体 在静态 TensorFlow 图表中 转换器生成了 Core ML 模型 该模型具有固定形状的输入 利用动态变体 我们获得了 接受任何序列长度输入的 Core ML 模型 转换器清晰明了地处理了这两种情况
并且没有对转换调用进行任何的更改 在演示中我没有机会展示的一件事是 我们可以 从一个动态 TensorFlow 图形开始 然后得到一个静态 Core ML 模型 让我们看看这是如何进行的 首先 我们定义一个 Type 描述对象
其输入名称为
其形状为
然后我们将该对象提供给转换 API
这样就可以了 在后台 类型和值推断 会传播此形状信息 从而删除掉所有不必要的动态运算 因此 静态模型可能会表现更好 而动态模型肯定会更灵活
使用哪种模型取决于你的 app 需求 至此 我们看到了 成功转换为 Core ML 的几个案例 然而 在某些情况下 我们可能会遇到一个不支持的操作错误 事实上 我最近遇到了这个问题 让我来给大家演示一下 我正在这个资料库中探索 称为”transformers“的自然语言模型 一个名为 T5 的近期模型引起了我的注意 让我们对它进行转换 首先 我们从资料库中加载预训练的模型 因为返回的对象是 tf.keras 模型的实例
所以我们可以 直接将其传到 Core ML 转换器中 让我们一起做一下
在这里 我们看到“Einsum”运算 不受支持的操作错误 现在我把时间交回给 Aseem 他将介绍一些处理该问题的方法 然后我们再回来转换这个模型 我们认识到 在不断发展的机器学习领域 遇到此错误是一个挑战 因为新的操作会定期添加到 TensorFlow 或 PyTorch 中 或者你可能正在使用自己定制的操作 在这种情况下 该怎么做呢? 那么 一个选择是使用 Core ML 自定义层 它允许你将 ML 模型 与自己的操作的 swift 实施一起使用 这很好 但是在许多情况下 可以采用另一种更简单的方法 你可以使用我们所说的“composite op” 因为它可以 将所有内容绑定在 ML 模型文件中 所以不需要编写额外的 Swift 代码 composite op 是 根据现有的 MIL 操作构建的 让我们深入研究一下 MIL 是什么 以及如何使用它来构建 composite op 我们开发了模型中间语言 来统一转换器堆栈 如果我们展开看其内部结构 这个堆栈由三个部分组成 前端、中间 MIL 部分 和后端 每一个源框架都有一个单独的前端 它用于捕获框架特定的表达式 之后 将构建一个 MIL 程序 此时 该表达式将与源无关 许多常见的优化过程 如运算符融合、死代码消除 常量传播等 都是在这里进行的 之后图会被序列化为 protobuf ML 模型格式 看待同一张图片的另一种方式是 每个源框架都有自己的方言 这些方言被转换为 MIL 作为一个整合点 再转换为 ML 模型 这是转换器转换为 MIL 格式的一种方法 但是还有另一种方法 可以使用 builder API 直接写出 MIL 程序 MIL 是一种独立语言 可用于直接表达神经网络模型 它的 API 和很多人 已经很熟悉的 API 非常相似 无论你是 TensorFlow 2 还是 PyTorch 用户 让我们来看看这个 builder API 下面是我们如何用 Python 编写 MIL 程序的方法 我们导入这一 builder 并通过指定其形状来定义输入 在本例中为 1、100、100、3 我们只需调用打印 就可打印程序的描述 在下面的描述中 我们可以看到 输入的类型被推断为 Float32 这是默认类型 现在我们添加第一个 op 我们使用这个简单的句法 添加了一个 ReLu op 让我们添加另一个 op 这次是转置 op MIL builder 的一大优点是 它可以立即执行类型和形状推断 我们可以看到 在下面的描述中 转置输出的形状已正确更新 让我们在最后两个轴上添加归约运算 我们看到 和预期一样 现在张量的形状是1, 3 让我们添加最后一个 op 最后 程序返回日志 op 的输出 因此 我们看到 用于在 MIL 中定义网络的 API 非常简单 现在 让我们来看看 如何将其用于实施复合操作 并绕过不受支持的操作错误 让我交回给 Gitesh 由他为大家进行说明 我们正在转换 T5 模型 然后遇到了 Einsum 不受支持的操作错误 我阅读了 TensorFlow 说明文档 发现它引用了 Einstein 求和标记法 许多运算 比如 reduce_sum、transpose、trace 等 都可以在这种标记法中使用字符串来表达 对于这种特定的转换 让我们集中讨论一下该模型使用的标记法 通过查看错误跟踪 我们可以看到 这个模型使用了 Einsum 和这个标记 也就是下面的数学表达式 这可能看起来很复杂 但实际上 它只是第二个输入上 带有转置的批处理矩阵乘法 这非常棒 因为 MIL 直接支持此运算 让我们编写一个复合操作 首先 我们导入 MIL Builder 和一个修饰符
然后我们定义一个 与 TensorFlow 运算同名的函数 在本例中是 Einsum 接下来 我们修饰该函数 以将其注册到转换器中 这样可以确保在转换过程中 每当遇到 Einsum 运算 都会调用正确的函数
最后 我们抓取输入 并使用 MIL Builder 定义 MatMul 运算 好了 让我们再次调用 Core ML 转换器
完成转换 让我们通过 打印 ML 模型来验证转换是否成功
完美! 回顾一下 在转换 T5 模型时 我们遇到了 Einsum 不受支持的操作错误 一般来说 Einsum 是一个复杂的运算 可以表达很多张量运算 但是我们不必担心所有可能的情况 我们只要处理此模型所需的特定参数化 并且可以通过复合操作轻松实现 总而言之 我们在 Core ML Tools 中 加入了许多新特性 比如强大的类型推断 用户友好的 API 等等 这些特性使得 Core ML 转换器更易于使用和扩展 要了解有关这些功能的更多信息 请访问我们的新说明文档 里面提供了几个示例 本视频中的演示内容也包含在内 最后 我们宣布了 新的 PyTorch 转换器和 对 TensorFlow 2 所增强的支持 这些可以通过新的统一 API 进行获取 并可以通过 MIL 进行获取
我们邀请大家进行尝试 你们的反馈有助于 让 Core ML Tools 变得更好 谢谢大家
-
-
2:58 - TensorFlow conversion using tfcoreml
# pip install tfcoreml # pip install coremltools import tfcoreml mlmodel = tfcoreml.convert(tf_model, mlmodel_path="/tmp/model.mlmodel") -
3:16 - New TensorFlow model conversion
# pip install coremltools import coremltools as ct mlmodel = ct.convert(tf_model) -
3:57 - ONNX conversion to Core ML
# pip install onnx-coreml # pip install coremltools import onnx_coreml onnx_model = torch.export(torch_model) mlmodel = onnx_coreml.convert(onnx_model) -
4:28 - New PyTorch model conversion
# pip install coremltools import coremltools as ct mlmodel = ct.convert(torch_script_model) -
4:52 - Unified conversion API
import coremltools as ct model = ct.convert( source_model # TF1, TF2, or PyTorch model ) -
6:42 - Demo 1: TF2 conversion
import coremltools as ct import tensorflow as tf tf_model = tf.keras.applications.MobileNet() mlmodel = ct.convert(tf_model) -
7:41 - Demo 1: Pytorch conversion
import coremltools as ct import torch import torchvision torch_model = torchvision.models.mobilenet_v2() torch_model.eval() example_input = torch.rand(1, 3, 256, 256) traced_model = torch.jit.trace(torch_model, example_input) mlmodel = ct.convert(traced_model, inputs=[ct.TensorType(shape=example_input.shape)]) print(mlmodel) spec = mlmodel.get_spec() ct.utils.rename_feature(spec, "input.1", "myInputName") ct.utils.rename_feature(spec, "1648", "myOutputName") mlmodel = ct.models.MLModel(spec) print(mlmodel) -
10:37 - Demo 1 : TF1 conversion
import coremltools as ct import tensorflow as tf mlmodel = ct.convert("mobilenet_frozen_graph.pb", inputs=[ct.ImageType(bias=[-1,-1,-1], scale=1/127.0)], classifier_config=ct.ClassifierConfig("labels.txt")) mlmodel.short_description = 'An image classifier' mlmodel.license = 'Apache 2.0' mlmodel.author = "Original Paper: A. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, "\ "T. Weyand, M. Andreetto, H. Adam" mlmodel.save("mobilenet.mlmodel") -
13:33 - Demo 1 Recap: Using coremltools convert
import coremltools as ct mlmodel = ct.convert("./tf1_inception_model.pb") mlmodel = ct.convert("./tf2_inception_model.h5") mlmodel = ct.convert(torch_model, inputs=[ct.TensorType(shape=example_input.shape)]) -
15:45 - Converting a Deep Speech model
import numpy as np import IPython.display as ipd import coremltools as ct ### Pretrained models and chekpoints are available on the repository: https://github.com/mozilla/DeepSpeech !python DeepSpeech.py --export_dir /tmp --checkpoint_dir ./deepspeech-0.7.1-checkpoint --alphabet_config_path=alphabet.txt --scorer_path=kenlm.scorer >/dev/null 2>&1 ls /tmp/*.pb tf_model = "/tmp/output_graph.pb" from demo_utils import inspect_tf_outputs inspect_tf_outputs(tf_model) outputs = ["logits", "new_state_c", "new_state_h"] mlmodel = ct.convert(tf_model, outputs=outputs) audiofile = "./audio_sample_16bit_mono_16khz.wav" ipd.Audio(audiofile) from demo_utils import preprocessing, postprocessing mfccs = preprocessing(audiofile) mfccs.shape from demo_utils import inspect_inputs inspect_inputs(mlmodel, tf_model) start = 0 step = 16 max_time_steps = mfccs.shape[1] logits_sequence = [] input_dict = {} input_dict["input_lengths"] = np.array([step]).astype(np.float32) input_dict["previous_state_c"] = np.zeros([1, 2048]).astype(np.float32) # Initializing cell state input_dict["previous_state_h"] = np.zeros([1, 2048]).astype(np.float32) # Initializing hidden state print("Transcription: \n") while (start + step) < max_time_steps: input_dict["input_node"] = mfccs[:, start:(start + step), :, :] # Evaluation preds = mlmodel.predict(input_dict) start += step logits_sequence.append(preds["logits"]) # Updating states input_dict["previous_state_c"] = preds["new_state_c"] input_dict["previous_state_h"] = preds["new_state_h"] # Decoding probs = np.concatenate(logits_sequence) transcription = postprocessing(probs) print(transcription[0][1], end="\r", flush=True) !python DeepSpeech.py --n_steps -1 --export_dir /tmp --checkpoint_dir ./deepspeech-0.7.1-checkpoint --alphabet_config_path=alphabet.txt --scorer_path=kenlm.scorer >/dev/null 2>&1 mlmodel = ct.convert(tf_model, outputs=outputs) inspect_inputs(mlmodel,tf_model) input_dict = {} input_dict["input_node"] = mfccs input_dict["input_lengths"] = np.array([mfccs.shape[1]]).astype(np.float32) input_dict["previous_state_c"] = np.zeros([1, 2048]).astype(np.float32) # Initializing cell state input_dict["previous_state_h"] = np.zeros([1, 2048]).astype(np.float32) # Initializing hidden state probs = mlmodel.predict(input_dict)["logits"] transcription = postprocessing(probs) print(transcription[0][1]) -
21:52 - Deep Speech Demo Recap: Convert with input type
import coremltools as ct input = ct.TensorType(name="input_node", shape=(1, 16, 19, 26)) model = ct.convert(tf_model, outputs=outputs, inputs=[input]) -
26:26 - MIL Builder API sample
from coremltools.converters.mil import Builder as mb @mb.program(input_specs=[mb.TensorSpec(shape=(1, 100, 100, 3))]) def prog(x): x = mb.relu(x=x) x = mb.transpose(x=x, perm=[0, 3, 1, 2]) x = mb.reduce_mean(x=x, axes=[2, 3], keep_dims=False) x = mb.log(x=x) return x -
28:20 - Converting with composite ops
import coremltools as ct from transformers import TFT5Model model = TFT5Model.from_pretrained('t5-small') mlmodel = ct.convert(model) # Einsum Notation $$ \Large "bnqd,bnkd \rightarrow bnqk" $$ $$ \large C(b, n, q, k) = \sum_d A(b, n, q, d) \times B(b, n, k, d) $$ $$ \Large C = AB^{T}$$ from coremltools.converters.mil import Builder as mb from coremltools.converters.mil import register_tf_op @register_tf_op def Einsum(context, node): assert node.attr['equation'] == 'bnqd,bnkd->bnqk' a = context[node.inputs[0]] b = context[node.inputs[1]] x = mb.matmul(x=a, y=b, transpose_x=False, transpose_y=True, name=node.name) context.add(node.name, x) mlmodel = ct.convert(model) print(mlmodel) -
29:50 - Recap: Custom operation
@register_tf_op def Einsum(context, node): assert node.attr['equation'] == 'bnqd,bnkd->bnqk' a = context[node.inputs[0]] b = context[node.inputs[1]] x = mb.matmul(x=a, y=b, transpose_x=False, transpose_y=True, name=node.name) context.add(node.name, x) -
29:50 - Deep Speech demo utilities
import numpy as np import pandas as pd import tensorflow as tf from tensorflow.python.ops import gen_audio_ops as contrib_audio from deepspeech_training.util.text import Alphabet from ds_ctcdecoder import ctc_beam_search_decoder, Scorer ## Preprocessing + Postprocessing functions are constructed using code in DeepSpeech repository: https://github.com/mozilla/DeepSpeech audio_window_samples = 512 audio_step_samples = 320 n_input = 26 audio_sample_rate = 16000 context = 9 lm_alpha = 0.931289039105002 lm_beta = 1.1834137581510284 scorer_path = "./kenlm.scorer" beam_width = 1024 cutoff_prob = 1.0 cutoff_top_n = 300 alphabet = Alphabet("./alphabet.txt") scorer = Scorer(lm_alpha, lm_beta, scorer_path, alphabet) def audiofile_to_features(wav_filename): samples = tf.io.read_file(wav_filename) decoded = contrib_audio.decode_wav(samples, desired_channels=1) spectrogram = contrib_audio.audio_spectrogram(decoded.audio, window_size=audio_window_samples, stride=audio_step_samples, magnitude_squared=True) mfccs = contrib_audio.mfcc(spectrogram = spectrogram, sample_rate = decoded.sample_rate, dct_coefficient_count=n_input, upper_frequency_limit=audio_sample_rate/2) mfccs = tf.reshape(mfccs, [-1, n_input]) return mfccs, tf.shape(input=mfccs)[0] def create_overlapping_windows(batch_x): batch_size = tf.shape(input=batch_x)[0] window_width = 2 * context + 1 num_channels = n_input eye_filter = tf.constant(np.eye(window_width * num_channels) .reshape(window_width, num_channels, window_width * num_channels), tf.float32) # Create overlapping windows batch_x = tf.nn.conv1d(input=batch_x, filters=eye_filter, stride=1, padding='SAME') batch_x = tf.reshape(batch_x, [batch_size, -1, window_width, num_channels]) return batch_x sess = tf.Session(graph=tf.Graph()) with sess.graph.as_default() as g: path = tf.placeholder(tf.string) _features, _ = audiofile_to_features(path) _features = tf.expand_dims(_features, 0) _features = create_overlapping_windows(_features) def preprocessing(input_file_path): return _features.eval(session=sess, feed_dict={path: input_file_path}) def postprocessing(logits): logits = np.squeeze(logits) decoded = ctc_beam_search_decoder(logits, alphabet, beam_width, scorer=scorer, cutoff_prob=cutoff_prob, cutoff_top_n=cutoff_top_n) return decoded def inspect_tf_outputs(path): with open(path, 'rb') as f: serialized = f.read() gdef = tf.GraphDef() gdef.ParseFromString(serialized) with tf.Graph().as_default() as g: tf.import_graph_def(gdef, name="") output_nodes = [] for op in g.get_operations(): if op.type == "Const": continue if all([len(g.get_tensor_by_name(tensor.name).consumers()) == 0 for tensor in op.outputs]): output_nodes.append(op.name) return output_nodes def inspect_inputs(mlmodel, tfmodel): names = [] ranks = [] shapes = [] spec = mlmodel.get_spec() with open(tfmodel, 'rb') as f: serialized = f.read() gdef = tf.GraphDef() gdef.ParseFromString(serialized) with tf.Graph().as_default() as g: tf.import_graph_def(gdef, name="") for tensor in spec.description.input: name = tensor.name shape = tensor.type.multiArrayType.shape if tensor.type.multiArrayType.shapeRange: for dim, size in enumerate(tensor.type.multiArrayType.shapeRange.sizeRanges): if size.upperBound == -1: shape[dim] = -1 elif size.lowerBound < size.upperBound: shape[dim] = -1 elif size.lowerBound == size.upperBound: assert shape[dim] == size.lowerBound else: raise TypeError("Invalid shape range") coreml_shape = tuple(None if i == -1 else i for i in shape) tf_shape = tuple(g.get_tensor_by_name(name + ":0").shape.as_list()) shapes.append({"Core ML shape": coreml_shape, "TF shape": tf_shape}) names.append(name) ranks.append(len(coreml_shape)) columns = [shapes[i] for i in np.argsort(ranks)[::-1]] indices = [names[i] for i in np.argsort(ranks)[::-1]] return pd.DataFrame(columns, index= indices)
-