-
调整您的 Core ML 模型
利用 Core ML 将机器学习能力直接融入到您的 app。探索如何利用 CPU、GPU 和神经引擎提供最高性能,同时仍保留在设备上并保护隐私。探索能轻松处理 Swift 中多维数据的 MLShapedArray,并进一步了解 Core ML 中的 ML 包支持,包括 ML 程序支持。这种现代化的机器学习编程方法提供类型化执行和极大的灵活性。我们还将向您展示如何分析模型的性能,并使用 ML 程序调整模型中的各项操作执行。
资源
相关视频
WWDC23
WWDC20
-
搜索此视频…
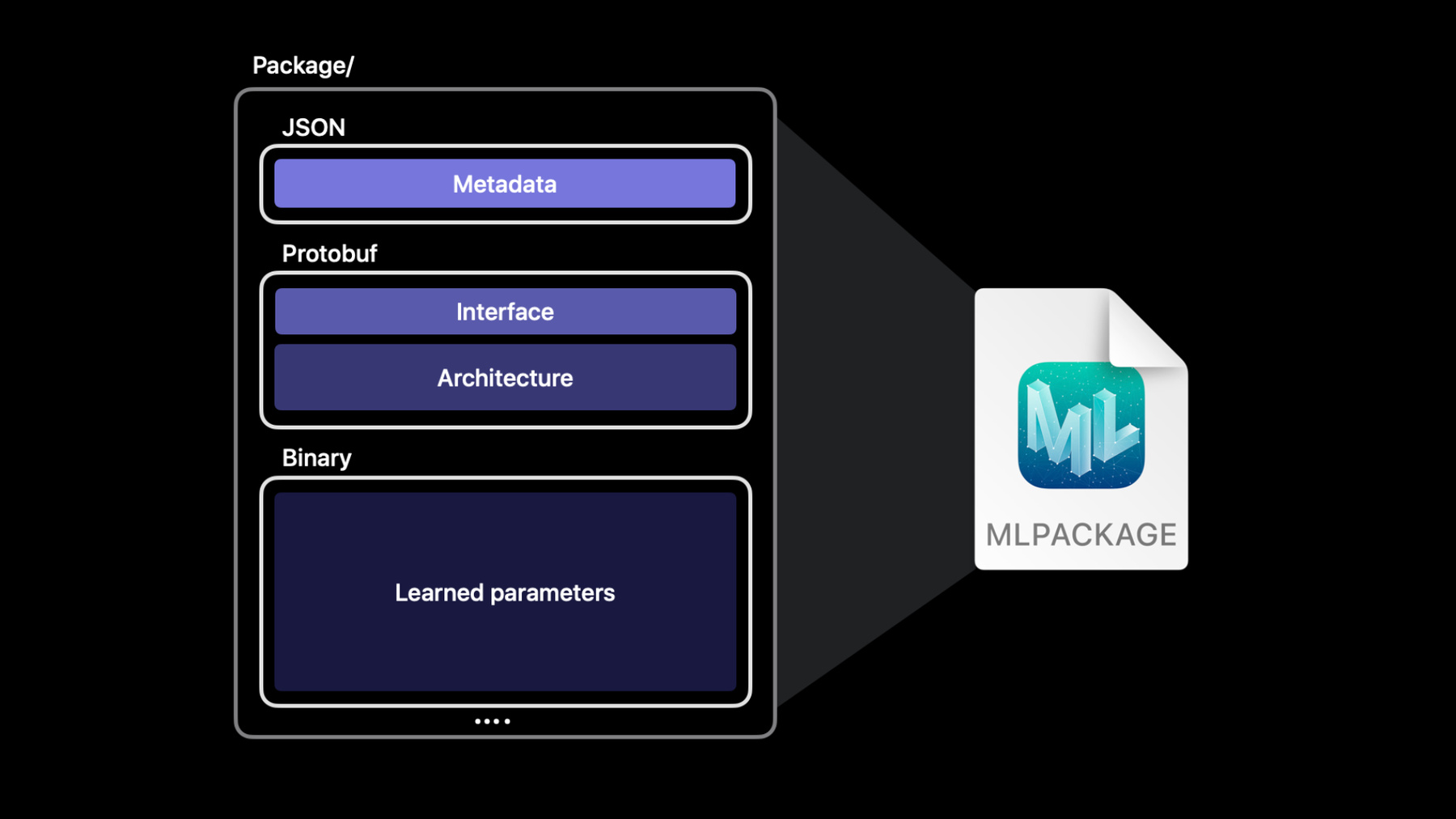
大家好 欢迎来到WWDC 我是约翰 我的工作内容是Core ML Apple的机器学习框架 我和我的同事布莱恩 我们很期待向各位介绍 随着你将机器学习的魔力 用在你的应用程序 可以如何调整你的模型 在一开始 我要向各位介绍 我们的机器学习API的一些加强 在那之后 我们会谈谈文件格式改进 这能打开一系列新的可能性 之后 布莱恩会介绍ML Program 让我们了解背后原理 并解释类型执行 和你可以怎么用它 来微调模型的准确度和表现 你可以用这些改进使工作流更精简 并让你机器学习驱动的体验更上一层楼 我们先谈谈API的改进 Core ML提供一个简单的API 能用在你的用户设备上的模型 这些模型可以设计为 接受多种输入和输出 例如字符串或原始值 或更复杂的输入 像是图像和MultiArray 我们进一步聊聊最后这一种 MultiArray Core ML让你能轻松用 MLMultiArray 处理多维数据 虽然它是简单的API 但在Swift里 用它操作数据需要写的代码 有时感觉不自然 例如 要初始化 有一堆整数的MultiArray 必须在运行时输入类型 另外你必须用NSNumber 而不是一般整数 那不符合类型安全 而且看起来不像是优美的Swift Core ML导入MLShapedArray 让你能更轻松运用多维数据 MLShapedArray是一种纯Swift类型 类似正常数组但支持多个维度 就像数组 它是一种值类型 有写时复制语义 还有丰富的切片语法 能轻松和现有的MLMultiArray代码 一起使用 若要初始化二维MLMultiArray 通常会用两个嵌套“for”循环 若是用MLShapedArray 只需用一行 就能初始化同样的二维数组 MLShapedArray自然融于Swift 让编程和检查代码容易很多 这是另一个例子 若要将第二行作为切片访问 你可以像这样直接编制索引 若要将多个行列作为一个切片访问 你可以为每个维度用一个值域 MLShapedArray和MLMultiArray 完全兼容 你可以用采取另一类型的实例的 初始值设定项 轻易将一种转换成另一种 你也可以用转换初始值设定项 转换两种 例如 这个代码将double的 MultiArray 转换成Float的ShapedArray 形数组在需要处理多维数据时 很好用 例如YOLO物体检测模型 会找到图像中的物体 然后输出一个二维数组 表格显示一次预测的数据 每一行都代表一个边界框 每一列的值域在0和1之间 每个值代表模型对于边界框包含人 脚踏车或汽车等的 置信度 我想写一些代码 选出每个边界框 最有可能的标签 这个例子示范如何做到这点 代码一开始是输出的置信度属性 那是二维MultiArray 这个功能会在每一行循环 以找到那一行最高的置信度分数 注意它必须常常将整数转换成 NSNumber 这个代码则用MLShapedArray 用更少行完成同样的任务 更容易阅读 请注意模型的预测结果给我们 一个包含置信度值的 ShapedArray属性 这个代码比较简单 因为MLShapedArray和它的标量 符合标准Swift集合协议 这提供很好的强类型体验 更容易阅读 并能轻松在Swift里使用 接下来 我们聊聊Core ML模型 还有它如何在文件系统里呈现 Core ML让人能轻松构建 丰富的机器学习驱动体验 提供给你的用户 ML模型是为这些体验 赋予生命的引擎 .mlmodel文件格式 编码并抽象化模型的功能 让你不需烦恼 这个格式会存储模型的所有实现细节 和复杂性 作为开发者 你不需要在意 它到底是决策树集成学习 或有几百万个参数的 神经网络 ML Model就是一个单一文件 只需将它添加至 Xcode项目 并写出和它兼容的代码 就像任何其他API 每个Core ML模型文件 都由几个组件组成 元数据存储信息 例如作者、许可证 版本和简短描述 界面定义模型的输入和输出 架构定义模型的内部结构 例如 若是神经网络 架构部分形容模型的分层 还有它们之间所有关联 最后的部分存储 模型在训练阶段中学习到的 大量数组的值 ML Model文件将这些所有部分 编码成protobuf二进制格式 文件系统和源代码管理软件 将其视为单一的二进制文件 源代码管理软件 无法分辨二进制模型文件 其实是由数个不同组件组成 为了解决这点 Core ML添加了新的模型格式 利用macOS的内置包功能 将这些组件分成个别的文件 这让我们谈到新的Core ML Model Package 它是一个容器 将每个模型的组件 存储在自己的文件 将架构 权重和元数据分离出来 通过将组件分离 模型包让你能轻易编辑元数据 并用源代码管理追踪变更 模型包也能更有效地编译 并为读取和写入模型的工具 提供更多灵活度 Core ML和Xcode仍然完全支持 原始的ML模型格式 但你可以改用更可扩展的格式 通过升级成模型包 更有效率地编译 我们在Xcode里试试 这是个简单的应用程序 它用物体检测模型 识别图像中的动物 注意有些元数据字段是空的 这很常见 常会遇到 元数据没有填写的模型 以前你无法在Xcode里编辑这些字段 但现在Xcode支持模型包 所以可以了 现在这个模型的文件类型是 ML Model 但当我点击编辑按钮 Xcode提示我 将ML Model文件更新成ML Package Xcode告诉我 它将把 我的工作空间中 任何原来模型文件的参考 更新成指向new.mlpackage 我要直接点击更新并编辑
Xcode的UI现在显示 模型是ML Package格式 现在我可以直接在Xcode里 填写缺少的值 我会直接更新描述 为“动物” 既然这个模型来自我的同事约瑟夫 我要在作者字段写上他的名字 写上MIT许可证和版本2.0
我也可以添加 修改 和移除额外的元数据字段 我要添加一个新的元数据项目 显示我们是哪一年的WWDC 用这个模型 所以就写2021 现在 除了UI支持 这些信息也都能在运行时 通过Core ML的MLModelDescription API访问 我也可以在预测选项卡 修改模型的输入输出的描述 我要变更这个输入的描述 加上“一只动物的” 我要在这里补一个连字符 修正打字错误 有良好元数据的模型 跟有良好注释的代码很类似 它协助你和团队了解模型的意图 所以特别要注意 一定要为模型的输入输出 写很好的描述 我要点击完成 保存变更 现在我若点击源代码管理 然后提交 Xcode会以差异视图显示变更
现在元数据在它自己的.json文件中 因此很容易验证我的变更 类似的情形 功能描述 也有自己的个别.json文件 如果我们变更了 一份62MB二进制ML Model文件的 几个字节 我们会有一个62MB二进制比较 不过模型包有效率多了 很容易使用 特别是对于小型文字变更来说 Xcode同样支持模型包 和模型文件 例如我可以用预览选项卡 测试模型包 如果我引进一个两只熊的图像 我们会看到有两个边界框 一只熊一个 类似地 我可以前往 实用程序选项卡 从这里为模型包生成加密密钥 或是ML存档 就像为ML模型文件生成那样 以上就是Xcode的模型包 模型包可以做到模型文件 可以做得的所有事 还有更多 例如编辑模型元数据 最后一个我想展示的东西 是Xcode自动为你添加至项目的 每个模型 所生成的代码 我要点击这个图标 看看生成的代码 稍早之前 我们看了MLMultiArray 还有它的新Swift对应物 MLShapedArray Xcode现在会为包装类中 每个MultiArray输出 添加一个新的形数组属性 例如 生成类现在有了 模型输出的 置信度ShapedArray属性 若想要的话 你还是可以用原始的 置信度MLMultiArray属性 注意你的项目的部署目标 必须是这些OS版本其中一个 例如macOS 12或iOS 15 才能利用新的形数组属性 现在我们已经看过这些运作方式 我们来看看ML Model 和ML Package的比较 ML Package支持所有 ML Model文件支持的类型 包括树、SVM、神经网络等 除了这些类型外 ML Package也支持 叫做ML Program的强大新模型类型 ML Program这种模型类型 以更面向代码的格式 表示神经网络 为了介绍更多关于ML Program 还有它带来的新功能 我要把麦克风交给布莱恩 谢谢约翰 我是布莱恩基恩 我很兴奋能分享 ML Program和类型执行如何 让你更能控制准确度 达到更好的模型表现 机器学习模型 之前可能以各种方式呈现在你面前 如果你上机器学习课程 或是阅读论文 你可能会看到 模型的描述方式 是它的数学或统计公式 但是这些数学表达式通常是抽象的 或者以计算图或网络的形式 呈现在你面前 中间两个图形的图形表示形式 描述数据流如何经过 一系列的层 每一层都应用它们自己的特定转换 在机器学习软件库中 模型则是表达成代码中的操作 机器学习工程师越来越常利用 这个由程序块、函数和控制流组成的 较通用的程序结构 Core ML中的新ML Program模型类型 就是使用最后一种表示形式 这是ML Program的范例 这是人类可读的文字格式 虽然意图是让你不需要自己写 ML Program会由Core ML的转换器 自动生成 一个ML program 由一个主要函数组成 这个主要函数由一系列 操作组成 或称op 每个op生产一个变量 这个变量是强类型 对于有权重的操作 例如线性操作 或卷积操作 通常权重 会序列化成分开的二进制文件 这是ML Program 和神经网络的简短比较 神经网络有层 ML Program则有op 神经网络模型的权重 嵌入层描述中 而ML Program将权重分别序列化 而且神经网络不会指定 中间tensor类型 相反地 计算单元在运行时 判断类型 另一方面 ML Program 有强类型tensor 今天我主要谈ML Program的 强类型语法 还有类型中间tensor如何影响 用ML Program进行的 设备内置机器学习 但首先 要怎么取得ML Program? Core ML先前导入了 一个统一转换器API 这个统一转换器API 提供一个方便的途径 让你的模型从Tensorflow 或PyTorch转移到 Core ML神经网络模型 一切只需要一次函数调用 你现在可以用同样的API 转换成ML Program 方法是选择iOS 15 作为最小部署目标 背后原理是 Core ML转换器 会在转换时 为模型选择一个磁盘上的表示形式 对于ML Program 磁盘上的中间表示形式 由Model Intermediate Language 提供 这是于WWDC2020推出的功能 统一转换器API让你可以选择 将你的模型部署成ML Program 从今以后 比起神经网络 ML Program会是较推荐的格式 ML Program一开始 会先于iOS15和macOS Monterey推出 对于神经网络模型 ML Model和ML Package格式 Core ML都支持 但ML Program必须是ML Package 才能让权重和架构分别存储 Core ML对ML Program寄予厚望 相信它会是未来的基础 我们会持续支持神经网络 但ML Program会是新功能的中心 所以如果ML Program就是未来 现在就采用ML Program有什么好处? 这让我们谈到类型执行 要强调ML Program类型执行的好处 我们先讨论 神经网络是什么样子 这是输入和输出的范例 它们来自一个Core ML神经网络模型 该模型指定Float32为 输入输出的张量,或称“tensor” 输入和输出也可以是double 或32位整数类型 所以神经网络模型会强类型化 这些输入和输出tensor 那中间tensor的类型呢? 神经网络不会强类型化 它的中间tensor 在磁盘上模型中 没有关于这些tensor类型的信息 相反的 执行模型的计算单元 在Core ML载入模型之后 才推断tensor的类型 当Core ML在运行时载入神经网络 它会自动且动态地 将网络图分成不同部分: Apple神经引擎友好、GPU友好 和CPU 每个计算单元会用它的原生类型 执行它的部分的网络 以让它的部分的表现 和模型的总体表现最大化 GPU和神经引擎都使用Float16 而CPU则用Float32 身为开发者 你对于这个执行方案有些控制权 可以选择.all cpuAndGPU 或是cpuOnly作为模型的 computeUnits属性 这个属性默认为.all 这会叫Core ML在运行时 将模型分成神经引擎 GPU和CPU 让你的应用程序达到最佳可能表现 如果你设定为cpuOnly Core ML不会用到神经引擎或GPU 这能确保你的模型只在CPU上执行 Float32精度 总结来说 神经网络有中间tensor 负责生产它们的计算单元 会在运行时自动类型化 你的确可以通过调整 允许的计算单元的配置 稍微调整精度 但这样设定会应用至整个模型 可能因此无法达到最佳表现 那ML Program呢? 这里描绘的ML Program 输入和输出tensor是强类型 每一个中间tensor也是 你甚至可以在单一计算单元中 例如CPU或GPU 混搭精度支持 这些类型在模型转换时已良好定义 那是远在你在部署场景里 用Core ML载入并运行模型前 ML Program用的是 将工作分配至神经引擎 GPU和CPU的 同一个自动分割方案 不过它添加了一个类型限制 Core ML保有 提升tensor精度的能力 但Core ML运行时 绝不会将中间tensor 转换成比ML Program的指定精度 更低的精度 对于类型执行的新支持 能够实现 是通过扩张的op支持 在GPU和CPU上都有 特别是对于GPU上的float32 op 还有CPU上的特定Float16 op 有了这个扩张支持 你还是可以 在你的ML Program指定 Float32精度时 能获得GPU在性能上的好处 我们试试用统一转换器API 以不同精度生产ML Program 好 我现在开了Jupyter笔记本 这是很方便的工具 能以交互方式 执行Python代码 我会讲解将模型转换成 新的ML Program格式的流程 我今天要用的模型是风格迁移模型 我已经从Open Source 下载了预先训练的 Tensorflow模型 这个模型会接受一个图像 并产出一个风格图像 第一个需要的东西是导入语句 我要导入coremltools Python图像库 还有几个助手库 还有我写的简单辅助函数 以让我在这里使用的代码简洁
现在我要指定风格迁移模型的路径 还有我要变更风格的图像的路径 我也会设定转换的 输入类型 在这个例子里 它会是图像输入类型 指明用来训练模型的图像的维度 最后 还有一些额外的设定步骤 要准备好输入字典 在转换后用来运行Core ML模型 所以输入已经载入了 源模型也可用 这时 所有外部资源都已准备好 可转换到ML Program
我会用统一转换器API进行转换 第一个参数是源模型路径 接着 输入输入类型的数组 这里只有一种 最后 最低部署目标参数 会判断Core ML Tools 是要产出神经网络 或是ML Program 它的默认设定是iOS 13 并产出一个神经网络 现在我想要获得一个ML Program 所以我会将部署目标设定为iOS 15 我希望最终能将这个模型 部属至iOS应用程序 也可以指定部署目标为macOS 12 如果我的目标设备是Mac的话 我要按Shift-Enter以转换模型 转换完成 转换成ML Program的过程中 会自动发生图变换 叫做FP16ComputePrecision pass 这个图pass 将原本Tensorflow图中 每个Float32 tensor 转换为ML program中的 Float16 tensor 好 既然现在转换完成了 下一步是 检查ML program的正确性 我可以拿输出数值 和原本Tensorflow模型比较 方法是 用同一个图像在两个模型中 分别调用预测 值得注意的是对于ML Program 我用的Core ML Tools API 跟前几年用来预测 模型存储和其他实用工具的API 一模一样 为了进行比较 我已经写了 一个实用工具方法 叫做 _get_coreml_tensorflow_output 它会印出多个误差测度 以评估Tensorflow的输出 和Core ML的输出
因为这是图像 最适合的误差测度 可能是信噪比 或称SNR 实务上 SNR若高于20或30 通常代表好的结果 这里我的SNR是71 这个数字很棒 有几个其他指标:最大绝对误差 平均绝对误差 但我很好奇 使用Float16 让准确度下降多少? 我损失了什么? 为了找到答案 我可以禁用Float16转换并再次转换 我会用同样的转换命 但这次e 我会指定一个compute_precision 参数并设定为Float32 这会告诉转换器不要注入 Float16转换 因此Core ML Tools转换器 会产出一个Float32 ML Program 好 现在我会将这个 Float32 ML Program 与原本的Tensorflow做比较
SNR增加到超过100 最大绝对误差下降了 从大约1下降到0.02 我还是不知道之前的 Float16模型的误差 是否有任何可辨别的影响 这是个风格迁移模型 所以可以基于输出图像的简单绘图 下结论
我会对我有的三个模型的源图像 和风格版本进行绘制 分别是Float16 ML Program Float32 ML program 和Tensorflow模型
我在三个模型输出之间 看不出有什么差别 当然 像这样仅评估一个图像 仅用几个指标用肉眼查看一次 这只是冒烟测试 看起来没问题 实务上 我会用更多误差测度 对更大的数据集进行评估 评估机器学习模型 使用的流程中的失败案例 并会审它们 我有一个小数据集在手边 而要用这个例子再更进一步 我可以拿这两个ML Program 和Tensorflow模型比较 比较数据集中的每个图像 Float32 MLProgram 和Tensorflow的SNR对比 是一条有叉叉的红线 而Float16 ML Program 则是一条有圈圈的蓝线 看来Float32 ML Program的SNR 平均约100 而Float16 ML Program则约70 Float16精度 的确稍微影响到数值 但对于这个用例来说并不显著 虽然就算在131个图像的小数据集里 还是有几个离群值 总体来说 模型表现还不错 有完成预期的任务 大部分深度学习模型 都是这样 它们通常运作上没问题 就算用Float16精度也是 所以我们才在Core ML转换器中 默认开启Float16转换 Float16类型ML program 能够在 神经引擎上执行 这可以带来显著的表现提升 并降低耗电 既然运行时间在执行时 将tensor的类型 视为最低精度 Float32 ML Program 会以仅有GPU和CPU的组合执行 这个演示示范了现在有多容易 控制ML Program 在转换时执行的最低精度 不像神经网络Core ML模型 如果你的模型 需要更高精度 不用将应用程序代码中 计算单元的设定改为cpuOnly 就能做到 最后一点 这个演示笔记本 将会作为范例提供给大家 可在Core ML Tools文档网站上找到 扼要重述 要获得一个ML program 利用转换功能 并通过一个额外的函数 以指定部署目标 设定为至少iO S15或macOS 12以上 Core ML转换器的默认模式 会产出优化的Float16模型 它可用来在神经引擎上执行 如果在某些情况中 模型会受到Float16精度影响 也能轻松将精度改为Float32 事实上Core ML Tools API里 还有更多高级选项可用 可以用来选择特定的op 在Float32中执行 同时让其余的维持Float16 以产出一个混合类型ML Program 请看我们的文档 以了解这些例子 总结来说 Core ML有几个新的改进 让你能更轻易调整和处理你的模型 新的MLShapedArray类型 让你能轻松处理 多维数据 ML Package格式让你能 直接在Xcode中编辑元数据 新的ML Program模型类型的 ML Package 支持类型执行 支持GPU用Float32 让你在调整模型的表现和准确度时 有更多选项能尝试 我们鼓励你将你的模型 升级成ML Package 并使用ML Program 谢谢你的收看 祝你有美好的WWDC [音乐]
-