-
借助 MLX 在 Apple 芯片上探索大语言模型
了解 MLX LM,这款工具专为在 Apple 芯片上轻松高效地处理大语言模型而设计。我们将介绍如何在 Mac 上微调先进的大语言模型并以此运行推理,以及如何将这些模型无缝整合到基于 Swift 的应用程序和项目中。
章节
资源
- MLX Swift Examples
- MLX Examples
- MLX Swift
- MLX LM - Python API
- MLX Explore - Python API
- MLX Framework
- MLX Llama Inference
- MLX
相关视频
WWDC25
-
搜索此视频…
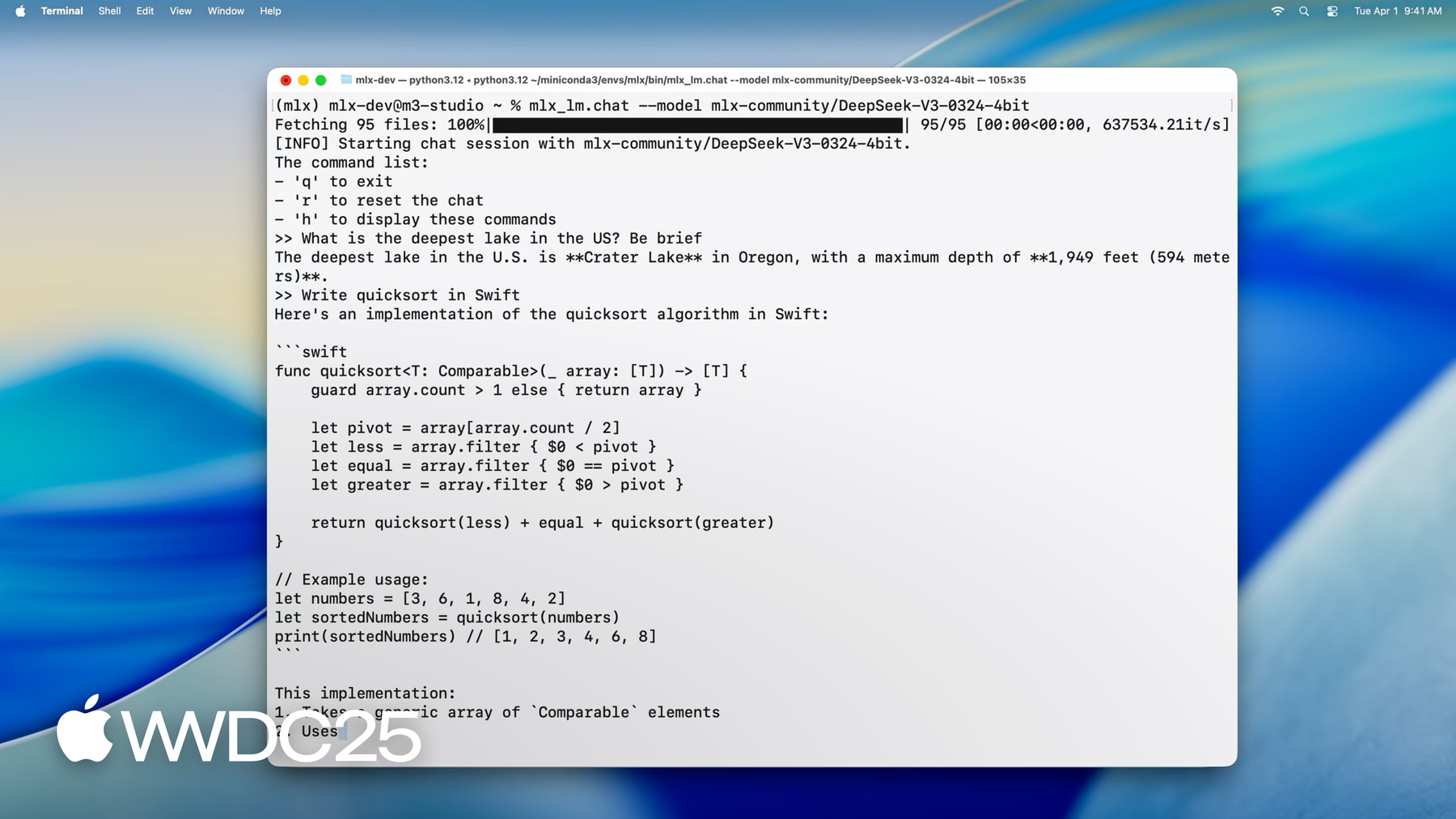
大家好 我是 MLX 团队的工程师 Angelos 今天我将展示 MLX 如何完美适配 Apple 芯片上的大语言模型 有了它 你可以直接在 Mac 上 对大规模模型 执行推理和微调 你可以使用 CLI 应用程序、Python 或 Swift 来完成所有这些工作 如果你是 MLX 新手 这里先介绍一下 它是一个开源库 专为在 Apple 芯片上执行 机器学习任务而构建 它利用 Metal 在 GPU 上实现加速 并借助统一内存 使 CPU 和 GPU 上的操作 能够同时处理相同的数据 你可以用自己喜欢的语言来使用 MLX 因为它提供了 Python、Swift、C++ 甚至 C 语言的 API 要进一步了解请观看讲座“开始使用 适用于 Apple 芯片的 MLX” 在 Apple 芯片上 运行大语言模型方面 MLX 解锁了强大的新功能 让你只需一行命令 就能在 Mac 上运行最新的尖端模型 我们来加载 DeepSeek AI 的 最新模型 它拥有惊人的 6700 亿个参数
即便将每个权重量化到 4.5 位 仅模型权重就需要约 380GB 的内存 为了解决这个问题 我们使用了 配备 512GB 超大统一内存的 M3 Ultra 芯片 这是其他任何消费级设备 都无法比拟的 模型加载完成后 我们就可以开始与它交互了 我们可以向它询问问题 比如 “美国最深的湖是哪个?”
或者让它为我们编写代码
如你所见 即使是包含数百亿参数的模型 MLX 也能实现流畅的实时交互和生成 比阅读速度还快 而且所有这些都直接 在你的 Mac 桌面上本地运行 现在你已经了解了 MLX 的潜力 接下来让我们深入探讨 如何使用 MLX 在你自己的 Mac 上 运行这些强大的模型 我们将首先介绍 MLX LM 它是一个 Python 库 和一组命令行应用程序 可以满足你所有的 大语言模型需求 为各种应用 提供强大且灵活的解决方案
随后 我们将深入研究 如何使用 MLX LM 生成文本 并展示从 Python 或终端生成文本 是多么容易 此外 我们还将介绍 如何从 Hugging Face 下载模型 并对模型进行量化 以便在设备上进行更快的推理
不过 MLX 可以做的远不止推理 接下来 我们将使用 MLX LM 基于我们自己的数据 对语言模型进行微调 具体来说 我们将训练一个低秩适配器 然后将它融合到模型中 以便更轻松地部署 并加快推理速度 最后 我们将介绍 如何在 Swift 中使用 MLX 届时你将看到 只需几行代码 就能在 Swift 应用程序中 集成大语言模型
在 MLX 中开始使用语言模型 最简单的方法是 使用 MLX LM MLX LM 是构建在 MLX 之上的 Python 包 旨在运行和实验大语言模型 它提供了一组命令行工具 让你无需编写任何代码 就可以生成文本或微调模型 如果你希望获得更多控制权 它还提供了一个 Python API 让你可以根据自己的喜好 自定义生成或训练过程 它还与 Hugging Face 紧密集成 这意味着你可以快速从互联网上下载 数千个模型 甚至可以上传自己的模型与社区分享
开始使用很简单 只需运行 pip install mlx-lm
现在让我们深入了解 语言模型最常见的用例 生成文本
这是一个命令行工具 让你可以直接从终端 使用语言模型生成文本 无需编写代码 它的工作原理是这样的 你给它一个 来自 Hugging Face 的模型或 本地路径 以及一个文本提示 剩下的事情它会处理 如果需要 它会下载模型 将提示输入模型 并打印生成的响应 因此 与其只是谈论 让我们来运行这个命令
短短几秒钟内 我们就得到了 快速排序的 Swift 实现
你可以调整模型的行为 添加诸如采样温度、 top-p 或最大词元数等标志 就像任何标准的文本生成设置一样 如果你对所有可用选项感兴趣 可以随时运行 mlx_lm.generate --help 因此无论你是要构思原型、 生成代码 还是仅仅探索模型的功能 这都是最简单的起点 我们刚刚看到了 使用 mlx_lm.generate 从命令行生成文本是多么容易 但 MLX LM 的真正优势之一是 它不仅限于终端工具 它还提供了一个简洁灵活的 Python API 非常适合需要更精细的控制 或者需要将生成 整合到更大的工作流程中 让我们看看 如何仅用几行 Python 代码 就能做同样的事情 即生成文本
首先 我们导入两个实用程序 load 和 generate 顾名思义 load 处理 与模型加载相关的一切 它从你的本地磁盘 或直接从 Hugging Face 获取请求的模型 并设置模型对象 和分词器 然后我们调用 generate 这个函数执行 词元生成循环 并返回输出文本 我们可以在 Python 中 进一步处理、记录 或将它馈送到其他系统中
因此 只需这两步 加载然后生成 我们就获得了与 CLI 相同的功能 但在 Python 中拥有完全的控制权 和灵活性 这是 MLX LM Python API 的 另一个强大之处 从 load 获得的模型 不是某种 只能通过固定接口交互的不透明对象 它是完全结构化的 MLX 神经网络 这意味着你可以检查它 探索它的架构 甚至修改它 我来给大家看一个快速演示
我们可以先打印构成模型的层列表
这为我们提供了 Transformer 堆栈 的逐层完整分解 我们还可以查看模型的参数 本质上是模型学习到的权重和偏差
如果我们想深入研究 网络的特定部分 比如第一层中的自注意力模块 我们也可以这样做
这种级别的透明度非常有用 不仅在调试或学习方面 而且在你想尝试诸如层交换、 自定义微调例程 或低级模型修改等操作时 也同样有用
到目前为止 我们已经了解了 如何从单个提示生成文本 但是如果你想要维持对话 或者生成多轮响应 并且每个新提示 都建立在前一个提示的基础上 该怎么办? 这就是键值缓存 (KV 缓存) 的用武之地 语言模型使用注意力机制 来处理输入词元 并在生成过程中反复 计算所有先前生成的词元的注意力 这可能会很耗时 尤其是对于长提示或多轮场景 KV 缓存解决这个问题的方法是 存储先前步骤的中间结果 特别是键和值
模型无需从头开始重新计算所有内容 而是重用这个缓存 从而节省时间和计算资源 在 MLX LM 中 使用 KV 缓存非常简单
让我们更新之前的 Python 示例 使用显式创建的 KV 缓存 这个缓存可以重用于多个生成过程
我们首先创建缓存对象 使用 make_prompt_cache 函数 我们可以用它来原地编辑历史记录 保存以供以后使用 或在对话之间无缝切换
然后我们将它传递给 generate 函数 随着新词元的生成 缓存会被更新 每次调用都从上一次中断的地方继续 从而在不同回合之间保持上下文一致 这在一些用例中特别有用 比如构建聊天机器人、 虚拟助手 或任何需要跟踪历史记录的 交互式应用程序
现在让我们稍微转换一下话题 谈谈模型量化 我们已经了解了如何生成文本 和以交互方式使用模型 但对于实际部署来说 效率变得与功能同样重要 模型的发布精度通常与训练时相同 比如 float32 或 float16 这虽然准确 但却会使模型变得 庞大而缓慢 尤其是在较小的设备上 这就是量化发挥作用的地方
它将模型降低到更低的精度 例如 Int8 甚至 4 位 从而减少内存占用 并加快推理速度 而且通常对质量的影响很小 但通常情况下 量化会涉及 额外的工具、转换脚本 以及兼容性问题 在 MLX 中 这要简单得多 量化是内置的 你可以以不同级别压缩模型 并立即将它们用于推理或训练 无需额外设置 让我们来看看它是如何工作的
要使用 MLX 量化 或一般性地转换模型 可以使用 mlx_lm.convert 命令 这个工具负责从 Hugging Face 下载模型 将模型转换为不同的精度 并保存在本地 均在一步中完成 在这个例子中 我们获取 原始的 16 位 Mistral 模型 并将它量化为每个权重大约 4 位
最终结果是模型体积显著缩小 运行速度更快 内存占用更少 转换后 模型将保存到 指定的文件夹 并可立即使用相同的 MLX LM 工具 进行推理或训练
如果你想与他人分享你的量化模型 只需传入存储库名称 就可以轻松将它 上传回 Hugging Face 因此 无论你是优化速度 节省空间 还是回馈社区 这一个命令就能满足你的需求
与文本生成一样 使用 Python API 对模型进行转换和量化 模型可以提供更大的灵活性 而不会增加复杂性 事实上 MLX LM 可以轻松地将 不同的量化设置 应用于模型的不同部分 或从 Python 中应用
例如 通常的做法是 保持嵌入层 和最终投影层的较高精度 因为它们往往对量化更敏感 在这个例子中 我们将这些层 量化为 6 位 而模型的其余部分使用 4 位 在质量和效率之间取得了很好的平衡 这是通过传递一个量化谓词函数 来完成的 这是一个小函数 接收每个层并返回 要用于它的量化参数 其他一切都完全相同 我们调用 convert 传递 Hugging Face 路径 和本地输出目录 MLX 会处理剩下的事情 包括下载模型和保存量化结果 当你尝试模型压缩 或试图在性能和准确性之间 找到最佳平衡点时 这种细粒度的控制特别有用
到目前为止 我们已经了解了 如何使用大语言模型生成文本 以及如何对它们进行量化 以实现更快的推理 和更轻量的部署 但 MLX 可以做得更多 尤其是在训练方面 使用 MLX LM 你可以直接在自己的 Mac 上 根据自己的数据微调大语言模型 最重要的是 这些数据绝不会离开你的设备 最棒的是 你不编写任何代码 就能做到这一点 我们来看看微调是如何工作的
大语言模型通常使用 来自互联网的大规模 通用数据集进行训练 这赋予了它们广博的知识 但这也意味着它们可能 在专业领域缺乏深度 或者无法捕捉特定任务的 语气和语言特征 微调是我们使这些模型适应 新上下文的方式 通过在较小的特定领域数据集上 进一步训练模型 我们可以赋予它们新的能力 或根据特定需求调整它们的响应 传统上 这个过程 是在云中完成的 在处理私人或敏感数据时成本高昂 并且效果通常并不理想 但有了 MLX 你可以在自己的 Mac 上 本地微调大语言模型 不需要云 数据也不会离开你的机器 它高效、安全 并且无缝集成到 MLX 工作流程中
MLX LM 开箱即用地支持 两种类型的微调 完整模型微调 和低秩适配器训练 在完整微调中 我们更新了 预训练模型的所有参数 这给你最大的灵活性 但也更消耗资源 相比之下 适配器训练 特别是低秩适配器 会向模型添加少量新参数 并仅训练这些参数 同时保持原始网络冻结 这使得训练更快、更轻量 而且通常更节省内存 尤其是在本地硬件上 让我们来看看如何 在实践中应用这一点 我们将在自定义数据集上 微调 Mistral 模型 让我们看看使用 MLX LM 启动微调作业是多么简单 它只需要一个命令 和几个关键参数 我们指定要微调的模型、 数据集的路径以及训练时长 由于量化已深度集成到 MLX 中 mlx_lm.lora 命令 甚至可以在量化模型的基础上 训练适配器 这显著降低了内存占用 同时又不影响有效微调的能力
在这个例子中 我们使用 Mistral 的 4 位量化版本进行训练 与全精度版本相比 这将模型权重的内存占用 减少了约 3.5 倍 因此 即使模型规模较大 直接在 Mac 上进行微调 仍然是切实可行和高效的 这条单行命令非常适合快速训练 尤其是在你刚开始使用的时候 但如果你想真正微调性能 你可能需要对训练过程进行更多控制 这就是训练配置文件 发挥作用的时候 MLX LM 支持的配置文件 可让你对训练的各个方面 进行精细控制 包括路径大小、 学习速率计划、 优化器设置、评估间隔等 这让你可以根据特定的数据集、 硬件或优化目标定制训练设置 并充分发挥适配器的能力 现在让我们看看微调的实际应用 以及它如何更新模型的知识 我们首先询问 Mistral 7b 谁赢得了最新一届超级碗
不出所料 答案是正确的 但已经过时了 模型的知识界限意味着 它无法访问最近的事件 但微调的妙处在于 我们可以在几分钟内解决这个问题 通过在一个小型数据集上进行训练 这个数据集包含有关 最新一届超级碗的问题和答案 我们可以更新模型的知识 让它准确回答
经过几分钟的微调 模型现在能够对 球队、球员、比分等 给出最新的答案
现在我们已经训练好了适配器 我们可以使用 MLX LM 将它们 融合回基本模型中 这对于部署和共享尤其有用 因为它生成一个独立模型 易于分发和使用
融合过程将适配器与原始权重相结合 生成一个与预训练版本 具有相同架构和参数数量的模型 只是功能有所更新 因此 从外部看 它的行为与任何其他模型一样 但其中融入了经过你微调的知识
为了将适配器融合到模型中 我们使用 mlx_lm.fuse 命令 它会计算融合后的权重 并将结果保存到指定路径 所有这些只需一步即可完成 无需手动进行任何反量化或重新量化 MLX 会自动处理这些操作 并保留 训练期间使用的量化 如果你想与他人分享 你新近微调的模型 也同样简单 你只需提供 一个 Huggin Face 存储库名称 融合模型就会被上传 并可供使用 到目前为止 我们已经使用 Python 生成文本并微调大语言模型 但 MLX 的突出特点之一是 它为 Swift 带来了同样的简洁性 和灵活性 我们来看看借助 MLX 在 Swift 中使用大语言模型 是多么简单
这个完整的示例展示了如何 从 Swift 加载量化的 Mistral 模型 并生成文本 整个过程只需要 28 行代码 首先导入 MLX 和语言模型库 然后创建一个模型容器 这是一个可以安全地管理 对模型和分词器的并发访问的 actor 接下来 我们准备输入 我们将提示进行分词 并将它转换为 模型能够理解的数字格式 最后 运行生成循环 并打印结果 就像之前在 Python 中看到的那样 工作流程相同 功能相同 但现在完全原生于 Swift 中 现在让我们看看如何 在与模型的多次交互中 保留对话历史记录 就像我们之前在 Python 中 所做的那样 在 Swift 中 这只需要几行额外代码 关键理念是一样的 我们需要显式 创建一个键值缓存 以便可以在多个生成过程中重用它 这只需要一行额外的代码即可完成 不会增加任何复杂性 为了更精确地管理交互 我们还使用了词元迭代器 它允许我们 直接设置键值转换 并逐步控制生成 这种设置使我们能够 从 Swift 灵活地处理 多轮对话和高级提示 在这个讲座中 我们看到了 使用 MLX 执行推理、 训练和量化是多么简单 无论是通过代码还是终端命令 我们使用的一切 从高级语言模型 API 到为它们提供动力的 Metal 内核 都是完全开源的 MLX 提供 C、C++、Python 和 Swift 语言的核心操作 以及 Python 和 Swift 语言的高级 API 让你在整个堆栈中 获得灵活性和控制力 这使得 MLX 在 Apple 硬件上 运行语言模型和 机器学习工作流程方面 具有独特的强大功能 现在让我们看看 你接下来可以做什么 我们已经探讨了 MLX LM 的一些主要功能 但你可以做的远不止于此 我们的文档深入探讨了 高级功能 例如分布式推理和训练、 学习量化 以及自定训练循环 为了帮助你快速上手 MLX 和 MLX Swift 示例存储库 提供了用于多种任务的现成项目 例如使用扩散模型进行图像生成、 语音识别 以及完整的语言模型训练 无论你是构建自己的 AI 应用程序 还是探索底层机制 只需点击几下 即可获得所需的一切 我们迫不及待地想看到 你利用 MLX 和大语言模型的力量 在 Apple 硬件上创造出 令人惊叹的体验
-
-
1:12 - Running DeepSeek AI's model with MLX LM
mlx_lm.chat --model mlx-community/DeepSeek-V3-0324-4bit -
3:51 - Text generation with MLX LM
mlx_lm.generate --model "mlx-community/Mistral-7B-Instruct-v0.3-4bit" \ --prompt "Write a quick sort in Swift" -
4:35 - Changing the model's behavior with flags
mlx_lm.generate --model "mlx-community/Mistral-7B-Instruct-v0.3-4bit" \ --prompt "Write a quick sort in Swift" \ --top-p 0.5 \ --temp 0.2 \ --max-tokens 1024 -
4:48 - Getting help for MLX LM
mlx_lm.generate --help -
5:26 - MLX LM Python API
# Using MLX LM from Python from mlx_lm import load, generate # Load the model and tokenizer directly from HF model, tokenizer = load("mlx-community/Mistral-7B-Instruct-v0.3-4bit") # Prepare the prompt for the model prompt = "Write a quick sort in Swift" messages = [{"role": "user", "content": prompt}] prompt = tokenizer.apply_chat_template( messages, add_generation_prompt=True ) # Generate the text text = generate(model, tokenizer, prompt=prompt, verbose=True) -
6:24 - Inspecting model architecture
from mlx_lm import load, generate model, tokenizer = load("mlx-community/Mistral-7B-Instruct-v0.3-4bit") print(model) print(model.parameters()) print(model.layers[0].self_attn) -
8:01 - Generation with KV cache
from mlx_lm import load, generate from mlx_lm.models.cache import make_prompt_cache # Load the model and tokenizer directly from HF model, tokenizer = load("mlx-community/Mistral-7B-Instruct-v0.3-4bit") # Prepare the prompt for the model prompt = "Write a quick sort in Swift" messages = [{"role": "user", "content": prompt}] prompt = tokenizer.apply_chat_template( messages, add_generation_prompt=True ) cache = make_prompt_cache(model) # Generate the text text = generate(model, tokenizer, prompt=prompt, prompt_cache=cache, verbose=True) -
9:37 - Quantization
mlx_lm.convert --hf-path "mistralai/Mistral-7B-Instruct-v0.3" \ --mlx-path "./mistral-7b-v0.3-4bit" \ --dtype float16 \ --quantize --q-bits 4 --q-group-size 64 -
10:33 - Model quantization with MLX LM in Python
from mlx_lm.convert import convert # We can choose a different quantization per layer def mixed_quantization(layer_path, layer, model_config): if "lm_head" in layer_path or "embed_tokens" in layer_path: return {"bits": 6, "group_size": 64} elif hasattr(layer, "to_quantized"): return {"bits": 4, "group_size": 64} else: return False # Convert can be used to change precision, quantize and upload models to HF convert( hf_path="mistralai/Mistral-7B-Instruct-v0.3", mlx_path="./mistral-7b-v0.3-mixed-4-6-bit", quantize=True, quant_predicate=mixed_quantization ) -
13:37 - Model fine-tuning
mlx_lm.lora --model "mlx-community/Mistral-7B-Instruct-v0.3-4bit" --train --data /path/to/our/data/folder --iters 300 --batch-size 16 -
15:06 - Prompting before fine-tuning
mlx_lm.generate --model "./mistral-7b-v0.3-4bit" \ --prompt "Who won the latest super bowl?" -
15:34 - Fine-tuning to learn new knowledge
mlx_lm.lora --model "./mistral-7b-v0.3-4bit" --train --data ./data --iters 300 --batch-size 8 --mask-prompt --learning-rate 1e-5 -
15:48 - Prompting after fine-tuning
mlx_lm.generate --model "mlx-community/Mistral-7B-Instruct-v0.3-4bit" \ --prompt "Who won the latest super bowl?" \ --adapter "adapters" -
16:29 - Fusing models
mlx_lm.fuse --model "mlx-community/Mistral-7B-Instruct-v0.3-4bit" --adapter-path "path/to/trained/adapters" \ --save-path "fused-mistral-7b-v0.3-4bit" \ --upload-repo "my-name/fused-mistral-7b-v0.3-4bit" # Fusing our fine-tuned model adapters mlx_lm.fuse --model "./mistral-7b-v0.3-4bit" \ --adapter-path "adapters" \ --save-path "fused-mistral-7b-v0.3-4bit" -
17:14 - LLMs in MLX Swift
import Foundation import MLX import MLXLMCommon import MLXLLM @main struct LLM { static func main() async throws { // Load the model and tokenizer directly from HF let modelId = "mlx-community/Mistral-7B-Instruct-v0.3-4bit" let modelFactory = LLMModelFactory.shared let configuration = ModelConfiguration(id: modelId) let model = try await modelFactory.loadContainer(configuration: configuration) try await model.perform({context in // Prepare the prompt for the model let prompt = "Write a quicksort in Swift" let input = try await context.processor.prepare(input: UserInput(prompt: prompt)) // Generate the text let params = GenerateParameters(temperature: 0.0) let tokenStream = try generate(input: input, parameters: params, context: context) for await part in tokenStream { print(part.chunk ?? "", terminator: "") } }) } } -
18:00 - Generation with KV cache in MLX Swift
import Foundation import MLX import MLXLMCommon import MLXLLM @main struct LLM { static func main() async throws { // Load the model and tokenizer directly from HF let modelId = "mlx-community/Mistral-7B-Instruct-v0.3-4bit" let modelFactory = LLMModelFactory.shared let configuration = ModelConfiguration(id: modelId) let model = try await modelFactory.loadContainer(configuration: configuration) try await model.perform({context in // Prepare the prompt for the model let prompt = "Write a quicksort in Swift" let input = try await context.processor.prepare(input: UserInput(prompt: prompt)) // Create the key-value cache let generateParameters = GenerateParameters() let cache = context.model.newCache(parameters: generateParameters) // Low level token iterator let tokenIter = try TokenIterator(input: input, model: context.model, cache: cache, parameters: generateParameters) let tokenStream = generate(input: input, context: context, iterator: tokenIter) for await part in tokenStream { print(part.chunk ?? "", terminator: "") } }) } }
-
-
- 0:00 - 简介
MLX 是一个针对 Apple 芯片优化的开源库,可在 Mac 上实现高效的机器学习。它利用 Metal 为 GPU 加速,并通过统一内存实现无缝的 CPU-GPU 协作。MLX 支持 Python、Swift、C++ 和 C 语言。 MLX LM 是一个 Python 库和 CLI 工具,可简化在 Apple 芯片上运行、微调和集成大语言模型的过程。你可以在 Mac 上本地载入最先进的模型 (例如 DeepSeek AI 的 670B 参数模型),并与之交互和生成文本,速度和性能表现都非常出色。
- 3:07 - MLX LM 简介
MLX LM 是基于 MLX 构建的 Python 软件包,用于运行和试验大语言模型。它提供用于文本生成和微调的命令行工具和 Python API,并与 Hugging Face 集成以完成模型下载和共享。你可以通过 pip install mlx-lm 安装 MLX LM。
- 3:51 - 文本生成
MLX LM 是一种工具,支持使用 Hugging Face 中的语言模型或存储在本地的模型生成文本。它提供了两个主要接口:命令行工具和 Python API。 通过命令行工具,你可以使用简单的提示和基本的自定选项生成文本。Python API 提供了更高的灵活性,让你能够载入模型、生成文本以及检查和修改模型的架构。 Python API 还通过键值缓存支持多轮对话,该缓存可以有效地存储中间结果,从而节省时间和计算资源。这使得 MLX LM 非常适合用于构建聊天机器人、虚拟助手等需要在多轮提示中保留上下文的交互式应用程序。
- 8:42 - 量化
模型量化是一种可用于降低机器学习模型精度的技术,能够减小模型体积、提升运行速度,尤其适合在小型设备上部署。MLX 通过其量化 API 简化了这一过程。 使用“mlx_lm.convert”命令,只需一步即可下载、转换和保存模型。该命令支持精细化控制,让你能够对模型的各个部分应用不同的量化设置,从而在模型质量与运行效率之间取得平衡。量化后的模型可以立即在 MLX 中用于推理或训练,也可以通过 Hugging Face 与他人共享。
- 11:39 - 微调
借助 MLX LM,你可以在 Mac 本地微调大语言模型,无需编写代码或将数据发送到云端。这一过程通过使用较小的、特定领域的数据集,将通用模型适配到具体的领域或任务中。 MLX LM 支持两种主要的微调方法:完整模型微调和低秩适配器训练。适配器训练更快速、更轻量,且内存占用更低,非常适合在本地硬件上运行。 你可以使用单个命令启动微调,同时指定模型、数据集和训练持续时间。如果需要更精细的控制,还可以使用训练配置文件。微调完成后,适配器可以重新融合回基础模型,生成一个独立的更新模型,以便轻松分发和使用,甚至可以上传到 Hugging Face 存储库进行共享。
- 17:02 - 采用 MLXSwift 的 LLM
MLX 为在 Swift 中使用大语言模型带来了简洁性与灵活性。只需几行代码,就可以载入量化模型、进行分词处理并生成文本。 要管理多轮对话,只需额外几行代码即可创建键值缓存。MLX 提供 C、C++、Python 和 Swift 的开源核心操作,以及 Python 和 Swift 中的高级 API,从而在 Apple 硬件上实现高效的机器学习工作流程。