-
Creating Great Apps Using Core ML and ARKit
Take a journey through the creation of an educational game that brings together Core ML, ARKit, and other app frameworks. Discover opportunities for magical interactions in your app through the power of machine learning. Gain a deeper understanding of approaches to solving challenging computer vision problems. See it all come to life in an interactive coding session.
리소스
관련 비디오
WWDC19
-
비디오 검색…
Good morning, and thank you for coming to our session.
At Apple, we build technologies. We build technologies so that you can make great apps with amazing experiences. And my favorite apps are the ones that seamlessly blend those technologies and really immerse us in the experience.
Today we'd like to talk to you about two of these technologies: Core ML and ARKit. Both of these help our devices gain a level of understanding about the world around us.
They help us blend the physical and virtual worlds.
Today we're going to take you on a journey of building an app that does just that. Along the way, we're going to look at some challenges that we faced and how we overcame them, and we're going to look at some themes that arose from facing those challenges.
The first, being the question, can machine learning help? Well, okay, if I said no, then this would be a pretty short session. But I can't just say a blanket yes, because the answer really depends on the type of problem you're trying to solve and the data you have to solve it, because machine learning is about understanding data. It's about understanding patterns in data, patterns in data that may be difficult to write down programmatically. And this data exists in your apps. Your users enter it every day. They use the keyboard and they enter text. They use the microphone and they record sound.
They use the camera and they capture video and pictures. So when facing a problem, asking yourself, can machine learning help, is a good question to ask. Now, you need to take a close look at the problem you're trying to solve and the data you have available to solve it.
The second theme that we're going to look at today is understanding the behavior of your model. These models are trained to expect certain inputs in certain formats and to provide outputs in certain formats. And so if your input is not in the format that's expected for the model, then the output is going to be unexpected as well. And speaking of outputs, if you don't understand what's being output from your model, it's going to be difficult to use it to make that magical experience in your app.
We're going to look at a couple ways that you can visualize the inputs and the outputs of some models. But for now, on with our journey. We said that we're going to combine technologies to blend the physical and virtual worlds, and what better context to do this in than an app? We thought that it would be fun to build an educational game app for children to practice their math skills, like counting, or addition, or multiplication. And we know that children sometimes use dice to practice these skills. Now, we could've just put virtual dice in the app and let those roll around on the screen, but we thought, wouldn't it be a lot more fun if the children could play with physical dice and roll those on the table and then interact with our app? So that's what we did. And the first challenge that we ran into was, how do you get an app to recognize dice? Well, there's a couple approaches. Let's start programmatically. But this is going to be a little difficult.
If we constrain our problem to only six-sided dice, we can start to look at the properties of a die. For instance, the die behind me, its color is gray.
But not all dice are gray, so that's not necessarily helpful.
If you look at it in a 2D plane, it's a hexagon shape and it has three skewed squares for sides.
But those move and change as the die rolls around on the table. If we take a closer look at each side, there's a number of dots on them; but again, that's different depending on the side you're looking at and depending on your perspective of the die.
So with all of these properties changing, it's going to be pretty difficult to write a program to recognize dice. So let's take a look at the machine learning approach.
We could train an image classification model to recognize dice in an image. But we want to know how many dice are in an image -- not just the existence of dice in an image.
So instead, we looked at using an object detection model. An object detection model will tell us if there's dice in an image, but it will also tell us where it is in the image; and if we know where the dice are in the image, then we can count them. To do this, we needed to get data, so we took a bunch of pictures of dice rolling around on the table. Next, we took those pictures and we annotated them with bounding boxes, indicating where the dice are in the images. After that, we used the new Create ML to train our custom object detection model.
If you'd like to learn more about this training, please see the Create ML for Object Detection and Sound Classification session. Now I'd like to invite Scott up to show you this in action.
Scott? Good morning, everyone. Morning! As Brent discussed, we're going to be exploring adding the ability for our app to count dice using a machine learning technique called object detection. And I'm sure you're all eager to see it in action, so let's get right to it.
So here, we have a very simple app that's wired with a live camera view, and we've added our object detector trained to detect dice so that we can count them. So let's see what happens when we add dice to the frame.
One, two, three, and four. We can even take a roll for more fun. So this is great. Our app is able to count dice using object detection. But one of the themes that we want to discuss with you today is understanding your model's behavior. So let's actually take a look at a debug visualization of what the model is seeing. As you can see, we're drawing bounding boxes around each of the detected objects -- in this case, dice -- on the board. And if we move them around, those boxes will move as well. This is important to you because if you are training an object detector and you start playing around with it, and you don't notice certain boxes around objects that aren't what you're trying to detect, or you're not seeing boxes around the objects that you are trying to detect, this is probably the opportunity for you to go and collect more data in this kind of lighting. You may want to collect more data with different kinds of backgrounds, different lighting, with a different number of objects -- in this case, we have four, but you may want to collect with five, six, up to ten dice, or less, or even images without them to train it to not recognize other objects.
Let's take a look at some code to do this. When you use your object detector that you've trained with Create ML, in the Vision framework, what you get back as a result is a list of VN recognized object observations. So here we have a function that handles those observations and does a couple things for us. The first one is the easiest: we're just counting dice. And this just is as simple as counting the number of observations because we have one per die. Next, we have a couple helper functions that help us draw these bounding boxes on screen based on these recognized object observations. We have a first function that matched the bounds you get from each recognized object observation, which come in normalized coordinates based on the input image you provide to Vision, so that function maps those back to our view controller's views coordinate system so that we can appropriately draw them on screen, overlaying them on top of the actual objects.
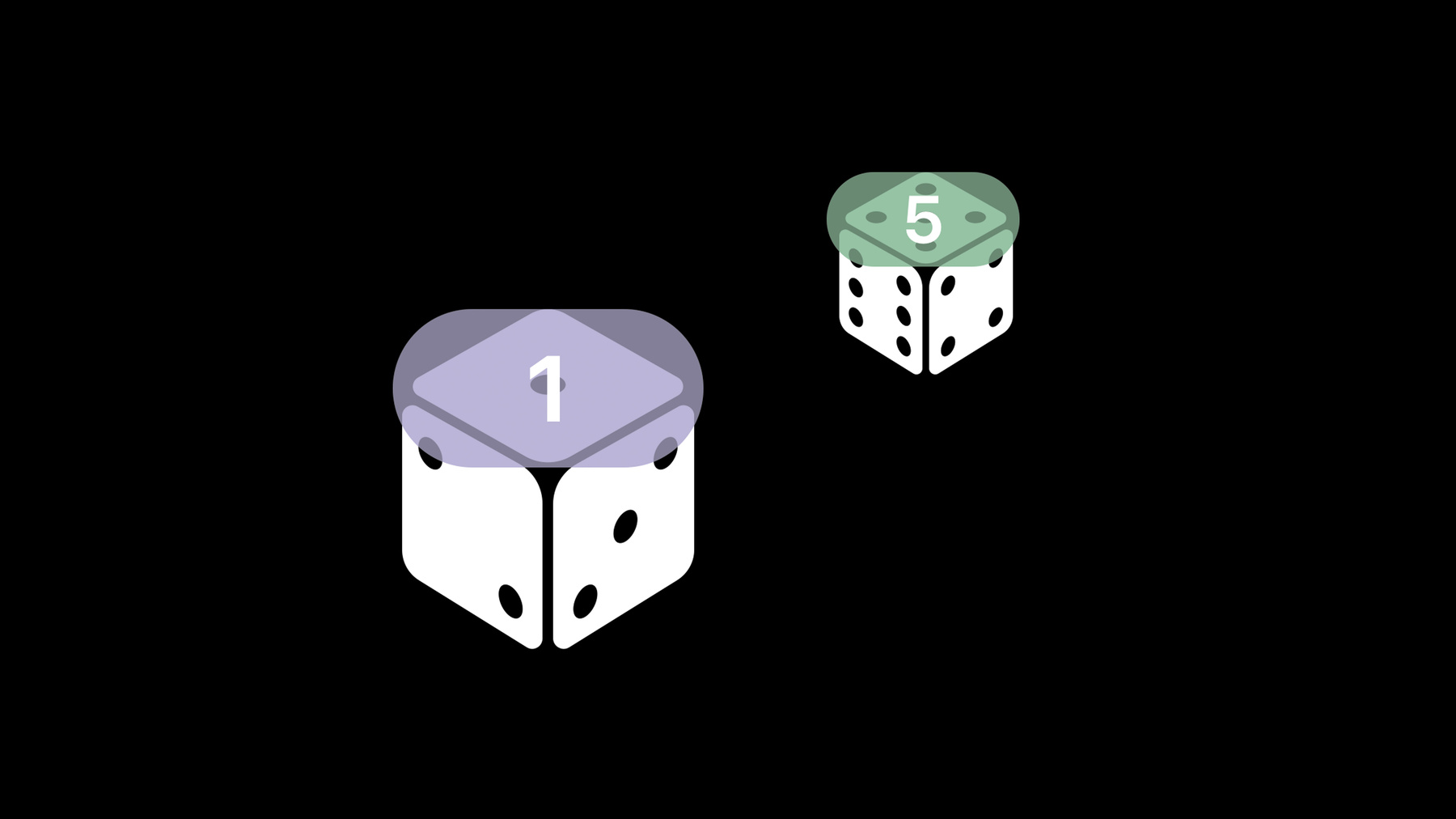
Next we have a helper function that creates our beautiful rounded rectangles that we display on screen, which is a CALayer, and we add that CALayer to an overlay layer to be rendered on screen. All this code is available in the sample app associated with this session, which I encourage you to check out. So this is really promising: our app is able to count dice using object detection. But you may have already realized or thought about the fact that games typically don't rely on the count of dice; they typically rely on the values displayed on them. So we need to take this one step further and figure out how to recognize the values displayed on these dice. This is ultimately the goal that we want our app to have: we want it to be able to tell that the die on the right side is a 5 and the one on the left is a 1. Luckily for us, as Brent mentioned, object detectors can not only detect but classify objects, because they're built to be able to recognize all sorts of different objects and images. So we went ahead and updated all our training data to actually consider dice with different values to be of a different class, just like you can see on the screen.
So this sounded really promising, and so we gave it a try in our app. Let's take a look at some of the examples that we ran into. In most cases, it worked perfectly fine. As you can see in the picture behind me, our object detector is able to correctly and accurately detect and classify the dice on the left of the screen; but if we focus in on the other side, we can see that our object detector is actually detecting the 6 and the 4 as one single die.
And if we think a little bit about what's happening, it's clear that the model isn't able to tell those apart as two separate dice, and it really comes down to the fact that the 4 is being occluded by the one in front.
So after thinking about this a little bit, what we realized was that we really care about the tops of these dice, and those are always visible in our frame.
So we went ahead and we helped our model a little bit. We updated all our training data to actually focus in on the tops of these dice. So now we're actually training an object detector, not to detect dice, but to detect tops of dice. So let's take a look at what happened when we did that. As you can see, our model was still able to correctly predict and classify the same dice as before, but now it's also able to correctly detect and identify the dice on the right.
We wanted to share with you another anecdote today.
At some point along our journey, we noticed this behavior, where our model was actually detecting the left side of the dice, consistently.
This was very confusing at first, but if we actually rotate this image, we can understand how the model thought these were the tops. This was super easy to realize as soon as we looked at the input of our model. We were simply not handling the image orientation according to our device's orientation, which is a very common problem for Vision tasks. So the key lesson here is, if you notice odd behavior in your model's output, it doesn't hurt to take a look at the input. It may be as simple as rotating your image based on the orientation of the device. So let's see this new model in action.
So here we have the same app, but we updated it to have our model that's able to detect and classify diced as well. For simplicity, I'm going to focus on three dice. We can see that our model is predicting 6, 5 and 2. So let's take a roll.
Four, 6 and 5. Awesome. This is really promising. So I want to bring your attention to a detail here that I think is very important. If I move the dice around, you can see that the list updates. We're actually displaying the list of values according to the order in which the dice are laid out on the table. This is a minor design detail, but it really brings consistency to the experience, because the user is seeing these dice laid out in that fashion on the table. So since we're blending the physical and virtual worlds, we're actually giving the user a very consistent display of the predictions.
There's another thing we need to figure out: when does a roll end? Again, games typically don't rely on transient states of a roll; they rely on the result of a roll. When you play a game, you roll some dice, and based on the result of that, your pawn either moves or you make some decision. In this case, we may want to animate something or provide feedback to the user. And you may have noticed in the demos that I just showed, I didn't show the numbers until the roll had ended. So how do we do this? Well, first we need to ask our self, what do we observe? In this case, we notice that the dice stop moving and the values are stable between different camera frames.
So can machine learning help us here? Perhaps we could build a sequential model that takes in frames and decides when the roll has ended, but we already have a model that has a really good understanding of dice on the table. So what we really need to do is interpret the output of our model.
So let's take a look at how to do this in code. Here we have a function that takes in two lists of object observations: one from the current camera frame and one from the previous camera frame. So there's a few things we need to check in order to decide that the roll has ended. The first is, do we have as many dice now as we had before? If not, maybe one die has entered the camera frame, so we now have more than before. If we have less than before, maybe one of them is bouncing around so the detector isn't picking that up. So if we don't have as many now as before, the roll is still happening. Next we're going to compare each of the observations in the previous prediction and in the current one.
If the values represented on top of the dice aren't the same, our roll has not ended yet. And we also check that the bounding boxes overlap between these predictions by more than 85%. If the bounding boxes between the prediction we're looking at and the one we're comparing it with don't overlap, either we're looking at two completely different dice, or it's the same one that has moved by a significant amount.
Finally, if we have as many matches now as we have dice on the table, the roll has ended. So now that our app can find, count, recognize dice on a table and figuring out the end of a roll, we have a foundation for building something more. And it's time to talk about the next steps of our journey. To do that, I'd like to welcome Brent back up to the stage. Thank you, Scott.
All right. As Scott said, our app can now recognize dice on the table. The next thing we need to look at is, how do we handle user input? We know that our users are going to be entering numbers into our app, because we're practicing math skills. And we could've just put a large number pad up on the screen and have them tap in the numbers, but we wanted to facilitate a more natural interaction with the app. And remember: we're working with children here, and children are also practicing writing their numbers. So we thought, why not just let them draw directly on the screen? Well, to do this, we're going to need our app to be able to recognize handwritten digits.
Fortunately, machine learning is already doing a very good job at solving this problem; in fact, there's an entire dataset available to let you train your own models to recognize handwritten digits. It's called MNIST.
Well, we did that, and we put that model on our new Core ML Models page.
So let's take a look in code at how we'd use this model. We're going to use Vision and PencilKit here. We set up Vision to use our Core ML model; in this case, MNISTClassifier. Next, we get our image from the PencilKit canvas view. After that, we set up our Vision request handler to use that image.
Then, we perform the request and we get the results. It's as easy as that.
So we integrated this into our model, and it started working pretty well. We were recognizing quite a few handwritten digits.
But as we started drawing some larger digits, we noticed something interesting: our model was sometimes getting the predictions incorrect. So what's happening? Well, to understand, we need to see what image is being input to our model. And we can do that in Xcode. So we set a break point where we get the image from PencilKit, and we use Xcode's quick view to actually look at what that image is. And when we did, we saw something interesting: our 7s from the example are not looking like 7s to the model. They're looking a lot more like 1s. So what's happening here? We need to think about what the model's expecting for an input.
This model is expecting a 28 by 28 pixel image, but the image that we get drawn on the screen is much bigger than that.
So to get the image in the right format, we have to downscale it. But as we downscaled it, we lost information about the strokes that were being drawn on the screen, and our 7s started looking a lot more like 1s. Once we knew that, the fix was pretty easy: we just needed to have a thicker stroke on the screen. And when we did that, after we downscaled, our images going to the model looked a lot more like what was being drawn on the screen, and the model started getting the predictions correct.
PencilKit makes this really easy.
Here we have allowsFingerDrawing set to true, since we're drawing on the screen with our fingers; and then, we set the tool to be something like a marker with a thicker stroke.
All right. Our model is now predicting single digits really well, but we have another couple challenges. Some digits are written with multiple strokes. Our model takes a static image of a digit, not stroke information about that digit. So how do we know when to take what's being drawn on the screen and pass it to our model to get a prediction? Additionally, since we're adding dice or possibly multiplying dice, we may be working with numbers that have multiple digits, and our model is only trained to recognize single digits, not multiple digits. So how do we handle that? We could've used machine learning to solve these problems. We could've trained a model to recognize stroke information about digits, or we could've trained a model to recognize numbers with multiple digits, but we already know a lot of information about what's being drawn on the screen. So instead, we decided to solve this problem programmatically, and I'll show you how. Let's take this example. Someone draws the first stroke of a 1 on the screen. We take that, we pass it as an image to our model, and we get a prediction, and it's a 1.
Next, they draw the second stroke of a 1, the base. We look to see if any of that stroke is overlapping any of the first stroke. Since it is, we know that it's the same number, so we get rid of the first prediction, we combine the first stroke with the second stroke into one image, and we pass that entire image to the model. And that gets predicted to be a 1. Next, the user draws another stroke on the screen.
We look at that third stroke and see if any of it overlaps either of the first two strokes. Since it doesn't, we know that it's a separate number, so we pass it separately to the model, and it gets predicted to be a 2. Now I'd like to invite Scott back up to show you this in the app. Scott? Thanks, Brent. We now have an updated app that still has our object detector that's able to detect and classify dice and their values, but we've also added the ability to draw input just like Brent discussed with you.
So I think it's time to do some math.
Here, the user has the option to either add the values displayed on the dice or multiply them. And so to keep things simple, I'm going to start with addition. So let's see how input handling works.
Yes.
So if we multiply these values, I'm pretty sure we get 24. Now, that's an interesting number. I want you to pay close attention to what happens when I draw the 4 on screen.
If you think about a 4 that's drawn with two strokes, our model's going to have a pretty hard time figuring out that's a 4 when it only sees the first stroke, so it may predict some other digit until I draw the second stroke. Let's have a look.
Did you notice that the first stroke of my 4 was predicted as a 1, but as soon as I had the second stroke, that was a 4? There's one other answer that is always correct, and I just want to show you more 4s, so let's try it.
Cool. So our app can recognize dice on the table, understand a roll, it can check our math, we can input that using drawing to draw the digits on screen, but we're talking about blending the physical and virtual worlds together, so we thought it would be a lot of fun and also very interactive if the kids playing with our game could input their answers in the form of voice. So let's take a look at that. Again, I'm going to add or multiply these two together and get 24. And let's do that using speech.
Twenty-four.
Cool.
This is super easy to do using the speech framework. And new this year in speech, we have offline speech recognition. This means that speech recognition can work in your app even when your device is not connected to the internet. And if you really want your user's data to remain on their device, you can actually require speech recognition to happen on device by setting requiresOnDeviceRecognition to true on your speech recognizer.
So now our app can understand a dice roll and handle input in various different ways, but we need to move on with our journey and finish this up. So I'd like to welcome Brent back up to the stage. Thank you, Scott.
As Scott mentioned, we have our app recognizing dice, and we know how to handle user input. But we said this was going to be a game, right? So let's make it that. Next we're going to integrate in ARKit and really finalize the whole experience. Of course, any game needs rules, so let's go over those first.
Our game is played on a circular board with nine sections. Each player starts on section one, and the goal is to move clockwise around the board and land directly on section nine. A roll that's too small, and you don't go far enough.
A roll that's too large, and you're going to overshoot your goal. During each player's turn, they roll the dice, and they have two options: they can take the sum of that dice and move that number in a clockwise direction, or they can take the difference of the dice and move that number in a clockwise direction.
So Scott, you up for a game? So we've now integrated our virtual board into our ARKit game that's also using Core ML to recognize dice. How about you start off, Brent? Sounds good.
All right. The 5 -- I've got a 5 and a 2. All right. I think I'm going to add those.
All right. Ooh, you got really close. Close.
So we got 6 and 1; I can either subtract these and get 5 or add them and join Brent on the 8 slot, so let's add these.
All right. I don't think I'm going to be able to get a 1. Let's see.
I think I'll subtract this time. Let me do a 2.
Okay. So I got 6 and 1 again. This time I'm going to change it up and do a 5. And Brent really thinks -- yeah.
Brent thinks I draw funny 5s. You know, this game could probably go on pretty long, but I think Scott might've mentioned something about a number always being correct, so let's see if this works in our game.
Ah, you found the secret, Brent. Good job. Success. All right. Today we looked at combining multiple technologies together to blend our physical and virtual worlds.
We built an experience that goes beyond any single technology and it let us play this fun game in this enhanced new world.
We used object detection to recognize dice on the table. We used image classification to recognize handwritten digits on the screen.
We used speech recognition as another way to interact with our app. And we brought in ARKit to really finalize the whole experience.
If you'd like more information, please see our session 228 on the developer website or come talk to us in the labs tomorrow. Thank you, and have a great rest of the show. [ Applause ]
-