-
Tune your Core ML models
Bring the power of machine learning directly to your apps with Core ML. Discover how you can take advantage of the CPU, GPU, and Neural Engine to provide maximum performance while remaining on device and protecting privacy. Explore MLShapedArray, which makes it easy to work with multi-dimensional data in Swift, and learn more about ML Package support in Core ML, which includes support for ML Programs. This modern, programmatic approach to machine learning provides typed execution and tremendous flexibility. We'll also show you how to analyze performance of your models and tune the execution of each operation in a model using ML Programs.
리소스
관련 비디오
WWDC23
WWDC20
-
비디오 검색…
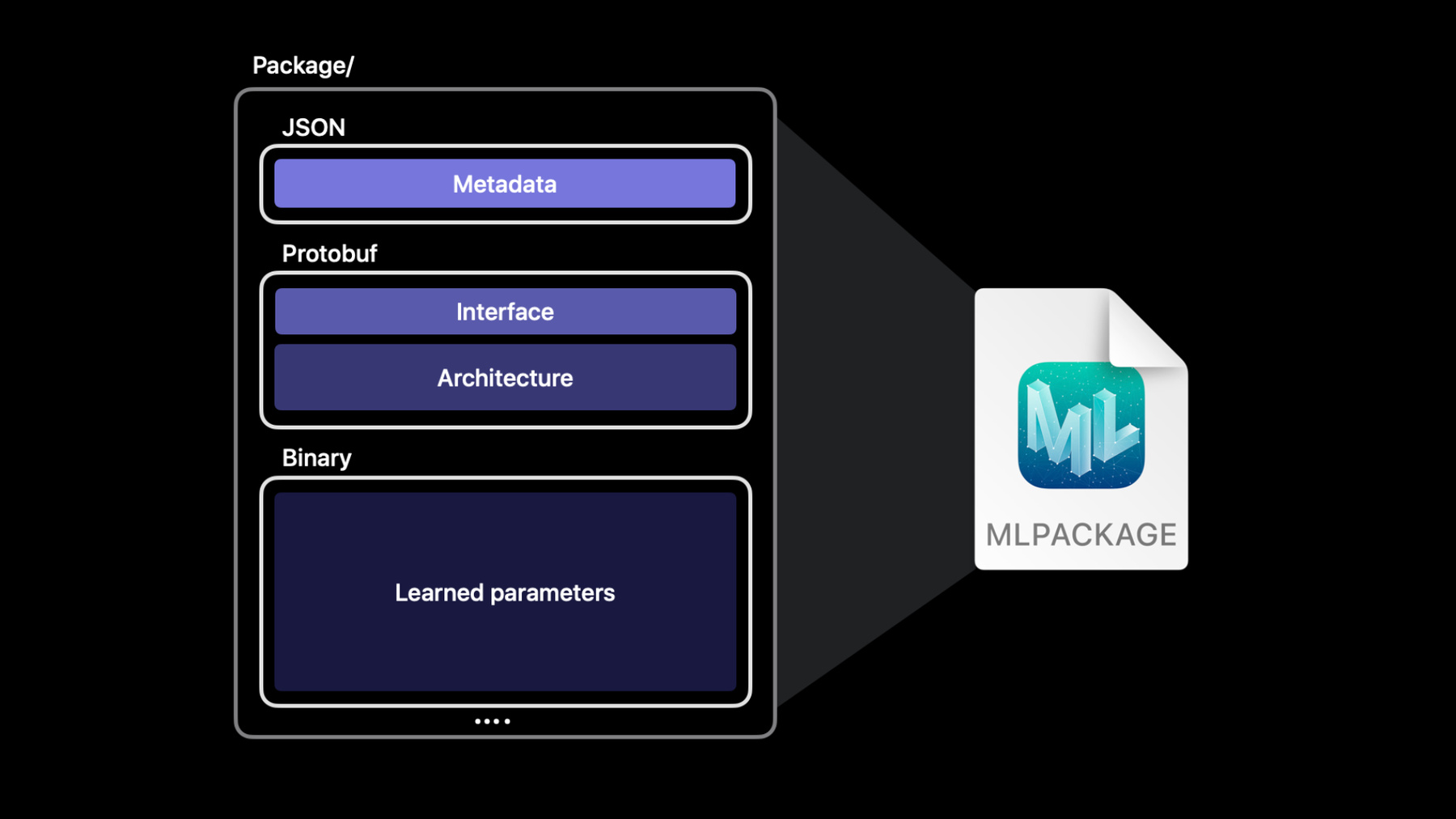
Hello, and welcome to WWDC. My name’s John, and I work on Core ML, Apple’s machine learning framework. Together with my colleague Brian, we're excited to show you how to tune up your models as you bring the magic of machine learning to your apps. To start things off, I’m going to show you some enhancements to our machine learning APIs. After that, we’ll dive into file format improvements that open up a range of new possibilities. Later on, Brian will show us ML Programs and take us under the hood and walk us through typed execution and how you can use it to fine-tune the accuracy and performance of your models. You can use these improvements to streamline your workflow and push your ML-powered experiences even further. Let’s start with the API improvements. Core ML provides you with a simple API to work with models on your user’s device. These models can be designed to work with a variety of inputs and outputs, such as strings or primitive values or more complex inputs like images and MultiArrays. Let’s talk more about this last type, MultiArray. Core ML makes it easy to work with multidimensional data using MLMultiArray. While it’s a simple API, the code you have to write to manipulate data with it doesn't always feel natural in Swift. For example, to initialize a MultiArray with a bunch of integers, you have to pass in the type at runtime. Plus you have to use NSNumber instead of regular integers, and that’s not type-safe and doesn’t really look like elegant Swift. Core ML is introducing MLShapedArray to make it easier for you to work with multidimensional data. MLShapedArray is a pure Swift type that’s similar to a normal array but supports multiple dimensions. Like array, it’s a value type, with copy-on-write semantics and a rich slicing syntax that works easily with your existing MLMultiArray code. To initialize a two-dimensional MLMultiArray, you typically use two nested “for” loops. With an MLShapedArray, you can initialize the same 2D array with a single line. MLShapedArray fits naturally in Swift and makes writing and reviewing your code that much easier. Here’s another example. To access the second row as a slice, you can just index into it like this. To access multiple rows and columns as a slice, you can use a range for each dimension. MLShapedArray and MLMultiArray are fully compatible with each other. You can easily convert one type into the other by using the initializer that takes an instance of the other type. You can also convert data types by using the converting initializer. For example, this code converts a MultiArray of doubles to a ShapedArray of Floats. Shaped arrays come in handy anytime you need to work with multidimensional data. For example, the YOLO object detection model finds objects in an image, and then it outputs a 2-dimensional array. The table shows the data from one prediction. Each row represents a bounding box, and the values in each column range between 0 and 1. Each value represents how confident the model is that the bounding box contains a person, bicycle, or car, et cetera. I want to write some code to pick the most likely label for each bounding box. Here’s an example of how to do that. The code starts with the output’s confidence property, which is a 2-dimensional MultiArray. This function loops through each row to find the highest confidence score in that row. Notice it has to frequently cast integers to NSNumber. This code uses MLShapedArray instead and does the same job in fewer lines that are easier to read. Notice the model’s prediction result gives us a ShapedArray property that contains the confidence values. This code is simpler because MLShapedArray and its scalars conform to the standard Swift collection protocols. This provides a nice strongly typed experience that’s more readable and a joy to work with in Swift. Next up, let’s talk about Core ML models and how they’re represented in the file system. Core ML makes it easy to build rich machine learning-powered experiences for your user. An ML model is the engine that brings these experiences to life. The .mlmodel file format encodes and abstracts the model’s functionality so you don’t need to worry about it. The format stores all the implementation details and complexities of a model. As a developer, you don’t need to care about whether it’s a tree ensemble or a neural network with millions of parameters. An ML Model is just a single file that you simply add to an Xcode project and write code that works with it, just like any other API. Each Core ML model file consists of several components. The metadata stores information such as the author, license, version, and a short description. The interface defines the model’s inputs and outputs. The architecture defines the model’s internal structure. For example, with a neural network, the architecture section describes the model's layers and all the connections between them. Finally, the last section stores the massive array of values that the model learned during the training phase. An ML Model file encodes all these sections into a protobuf binary format, which file systems and source control software see as a single binary file. Source control software can’t tell that the binary model file is actually a combination of several distinct components. To solve that, Core ML is adding a new model format that breaks these components into separate files, using macOS’ built-in package functionality. Which brings us to the new Core ML Model Package. It’s a container that stores each of a model’s components in its own file, separating out its architecture, weights, and metadata. By separating these components, model packages allow you to easily edit metadata and track changes with source control. They also compile more efficiently and provide more flexibility for tools which read and write models. Core ML and Xcode still fully support the original ML model format. But you can move to a more extensible format and compile more efficiently by updating to a model package. Let’s try this out in Xcode. Here’s a simple app that uses an object detection model to identify animals in an image. Notice that some of the metadata fields are empty. It’s fairly common to come across models where the metadata isn’t filled in. In the past, you couldn’t edit these fields in Xcode. But now that Xcode supports model packages, you can. Right now the model’s file type is ML Model, but when I click on the Edit button, Xcode prompts me to update the ML Model file to an ML Package. Xcode tells me that it’s about to update any of my workspace’s references to the original model file to point at the new.mlpackage. I’ll go ahead and click Update and Edit.
Xcode’s UI now indicates the model is in the ML Package format. Now I can fill in the missing values directly in Xcode. I’ll go ahead and update the description with the word “animals.” Since this model came from my coworker, Joseph, I’ll put his name in the Author field. I’ll say MIT License and version 2.0.
I can also add, modify, and remove additional metadata fields as well. I’ll add a new metadata item that indicates which year we used this model at WWDC. So we’ll say 2021. Now, in addition to the UI support, all of this information is also accessible using Core ML’s MLModelDescription API at runtime. I can also modify the description of the model's Inputs and Outputs in the Predictions tab. Here I’ll change the description of this Input. We'll add "of an animal." And down here, I’ll fix a typo by adding a missing hyphen. Now, a model with good metadata is a lot like code with good comments. It helps you and your team understand the model's intent, and so it’s particularly important to make sure you write good descriptions for your model’s inputs and outputs. I’ll click Done to save the changes. Now if I click on Source Control and then Commit, Xcode shows the changes in a diff view.
The metadata is now in its own.json file, which makes it easy to verify my changes. Similarly, the Feature Descriptions have their own separate.json file. If we had changed a few bytes of a 62-megabyte binary ML Model file, we’d have a 62-megabyte binary diff. Model packages, however, are much more efficient and easy to work with, especially for small text changes. Xcode supports both model packages and model files equally. For example, I can use the Preview tab to test out my model package. If I bring in an image of two bears, we’ll see that we get two bounding boxes, one for each bear. Similarly, I can go to the Utilities tab, where I can generate an encryption key or an ML archive for a model package the same as I would for an ML model file. So that’s model packages in Xcode. Packages can do everything a model file can and more, such as editing model metadata. The last thing I want to show is the code that Xcode automatically generates for each model you add to a project. I’m going to click on this icon to see the generated code. Earlier, we took a look at MLMultiArray and its new Swift counterpart, MLShapedArray. Xcode now adds a new shaped array property for each MultiArray output in the wrapper class. For example, the generated class now has a confidenceShapedArray property for the model’s output. You can still use the original confidence MLMultiArray property if you like. Note that your project’s deployment target must be one of these OS versions, for example, macOS 12 or iOS 15, to take advantage of the new shaped array property. Now that we’ve seen all this in action, let’s take a look at ML Model and ML Package side by side. ML Packages support all the same types that ML Model files support, including trees, SVMs, neural networks, and so on. In addition to these types, ML Packages also support a powerful new model type called ML Program. ML Program is a model type that represents neural networks in a more code-oriented format. To tell you more about ML Programs and the new features they enable, I’ll hand it over to Brian. Thanks, John. My name is Brian Keene, and I’m excited to talk about ML Programs and how typed execution gives you more control over accuracy and better model performance. There are various ways a machine learning model may have been presented to you. If you’re taking a machine learning course or reading a paper, you may encounter a model described with respect to its mathematical or statistical formulation. However, these mathematical expressions are often abstracted and alternatively presented to you in the form of a computation graph or network. This graphical representation as depicted in the middle two figures, describes how data flows through a series of layers, each of which applies their own specific transform. In a machine learning software library, the model is instead expressed as operations in code. Machine learning engineers are increasingly leveraging this more generic program structure composed of blocks, functions, and control flow. The new ML Program model type in Core ML aligns itself with this last representation. This is a representative ML Program. It’s in a human readable text format, although the intention is that you don’t have to write it yourself. The ML Program will be generated automatically by Core ML’s converter. An ML program consists of a main function. This main function consists of a sequence of operations, or ops. Each op produces a variable, and this variable is strongly typed. For operations that have weights, such as the linear or convolution ops, the weights are typically serialized into a separate binary file. This is a brief summary of how ML Programs compare to Neural Networks. Neural networks have layers, while ML Programs have ops. Weights in neural network models are embedded in their layer descriptions, while ML Programs serialize the weights separately. And neural networks don’t specify the intermediate tensor types. Instead, the compute unit determines these types at runtime. ML Programs, on the other hand, have strongly typed tensors. Today I’ll focus on ML Program’s strongly typed syntax and the implications that typed intermediate tensors have for on-device machine learning with ML Programs. But first, how do you get an ML Program? Core ML previously introduced a unified converter API. This unified converter API provides a convenient means to get your model from Tensorflow or PyTorch to the Core ML neural network model with a single function call. You can now use the same API to convert to an ML Program by selecting iOS 15 as the minimum deployment target. Under the hood, the Core ML converter selects an on-disk representation for the model at conversion time. For ML Programs, the on-disk intermediate representation is provided by Model Intermediate Language, a feature introduced at WWDC 2020. The unified converter API is where you can opt-in to deploy your model as an ML Program. Moving forward, ML Program will be the favored format over neural network. And ML Program is available beginning with iOS15 and macOS Monterey. Core ML supports both ML Model and ML Package formats for neural networks models, but ML Program must be an ML Package to store its weights separately from the architecture. Core ML is investing in ML Program as a foundation for the future. There will be continued support for neural networks, but ML Program will be central to new features. So if ML Program is the future, what are the benefits of adopting ML Program today? This brings us to typed execution. To highlight the benefits of typed execution with ML Programs, let’s first discuss what happens with neural networks. Shown here is an example input and output to a Core ML Neural Network model that specifies Float32 for the input and output tensors. Inputs and outputs can also be double or 32-bit integer types. So the neural network model strongly types these input and output tensors. What about the types of the intermediate tensors? A neural network doesn’t strongly type its intermediate tensors. There is no information about the types of these tensors in the on-disk model. Instead, the compute unit that runs the model infers the tensor’s types after Core ML loads the model. When the Core ML runtime loads a neural network, it automatically and dynamically partitions the network graph into sections: Apple Neural Engine friendly, GPU friendly, and CPU. Each compute unit executes its section of the network using its native type to maximize its performance and the model’s overall performance. The GPU and the Neural Engine both use Float16, and CPU uses Float32. As the developer, you have some control over this execution scheme by selecting .all, .cpuAndGPU, or .cpuOnly with the model’s computeUnits property. This property defaults to .all, which instructs Core ML to partition the model across the neural engine, GPU, and CPU at runtime to give your app the best performance possible. And if you set it to cpuOnly, Core ML will not use either the Neural Engine or the GPU, which ensures your model is only executing the Float32 precision on the CPU. To summarize, neural networks have intermediate tensors, which are automatically typed at runtime by the compute unit responsible for producing them. You do have some control of their precision by configuring the set of allowed compute units, but doing so is a global setting for the model and may leave some performance on the table. What about ML Program? In the ML Program depicted here, the input and output tensors are strongly typed, and so is every intermediate tensor of the program. You can even mix and match precision support within a single compute unit, say, the CPU or GPU, and these types are well defined at the time of model conversion. That’s long before you would use Core ML to load and run the model in a deployment scenario. ML Programs use the same automatic partioning scheme that distributes work to the Neural Engine, GPU, and CPU. However, it adds a type constraint. Core ML retains the ability to promote a tensor to a higher precision, but the Core ML runtime never casts intermediate tensors to a lower precision than that specified in the ML Program. This new support for typed execution has been made possible via expanded op support on both GPU and CPU, particularly for Float32 ops on GPU and selected ops in Float16 on CPU. With this expanded support, you can still see the performance benefits of the GPU when your ML Program specifies Float32 precision. Let’s try out the unified converter API to produce ML Programs with different precisions. OK, I’m now in a Jupyter notebook, which is a convenient tool for executing Python code in an interactive way. I’ll go over the process of converting a model to the new ML Program format. The model I’m going to use today is a style transfer model. I’ve already downloaded a pretrained Tensorflow model from Open Source. This model takes in an image and produces a stylized image. The first thing needed is a few import statements. I’ll import coremltools, the Python image library, as well as a couple helper libraries and simple helper functions that I’ve written to keep the code I use here succinct.
Now I’ll specify the path of the style transfer model and the path to the image I’m going to stylize. I’m going to also set up the input types for the conversion. In this case, it’ll be an image input type which specifies the dimensions of the image on which the model was trained. Finally, there’s some additional setup to prepare the input dictionary that I can use to run the Core ML model post conversion. So the input has been loaded, and the source model is available. At this point, all of the external resources are ready for conversion to an ML Program.
For conversion, I’ll use the Unified Converter API. The first argument is the source model path. Next, pass the array of input types. Here, there’s just the one. Finally, the minimum deployment target argument will determine if Core ML Tools produces a neural network or an ML Program. It defaults to iOS 13 and produces a neural network. Right now I want to get an ML Program, so I’ll set the deployment target to iOS 15. I want to eventually deploy this model on an iOS app. I could have alternatively specified a deployment target of macOS 12, if my target device was a Mac. I’ll press Shift-Enter to convert the model. And conversion has completed. There is a graph transform that happens automatically for ML Programs during conversion. It’s called the FP16ComputePrecision pass. This graph pass casts every Float32 tensor in the original Tensorflow graph to a Float16 tensor in the ML program. OK, now since the conversion is done, the next step is to check the correctness of the ML program. I can compare the output numerics with the original Tensorflow model by calling prediction with the same image with both the models. It’s worth noting for ML Programs, I’m using exactly the same Core ML Tools APIs as in previous years for prediction, model saving, and other utilities. To do the comparison, I have already written a utility method called _get_coreml_tensorflow_output. It will print out multiple error metrics to evaluate the output from Tensorflow and the output from Core ML.
So since this is an image, the most appropriate error metric may be the signal to noise ratio, or SNR. In practice, an SNR above 20 or 30 is usually indicative of good results. Here I have an SNR of 71, and that’s pretty great. There’s a couple other metrics: max absolute error, average absolute error. I’m curious, though, what’s the accuracy cost of using Float16? What have I lost? To find out, I can disable the Float16 transform and convert again. I’ll use the same convert command, but this time I’ll specify a compute_precision argument and set it to Float32. This will tell the converter to not inject those Float16 casts, and so the Core ML Tools converter will produce a Float32 ML Program. OK, now I’ll compare this Float32 ML Program to the original Tensorflow one.
And the SNR has increased to over 100, and the maximum absolute error has decreased from about 1 down to 0.02. I still haven’t answered whether the error I got earlier with the Float16 model had any discernible impact. This is a style transfer model, so the verdict could be made based on a simple plot of the output image.
I’ll plot the source image and the stylized versions from all three models that I have: the Float16 ML Program, the Float32 ML program, and the Tensorflow model.
And I really don’t see any difference between the three model outputs. Of course, this evaluation of a single image, once with a couple of metrics and a visual inspection is really just a smoke test. Things look OK. In practice, I’d evaluate with more error metrics across a large dataset, evaluate failure cases within the pipeline used by the machine learning model, and triage those. I have a small dataset handy, and to go one step further with this example, I can compare the two ML Programs with the Tensorflow model for each image within the dataset. The SNR of the Float32 ML program versus Tensorflow is depicted as a red line with Xs, and the Float16 ML Program is a blue line with circles. The Float32 ML Program seems to average an SNR around 100, and the Float16 ML Program stays around 70. The Float16 precision does affect the numerics a little bit, but it doesn't seem significant for this use case. Although, even in this small dataset of 131 images, there are a few outliers. Overall, the model is doing pretty well what it’s expected to do. And this is the case for a majority of deep learning models. They typically tend to work just fine, even with Float16 precision. That’s why we have turned the Float16 transform on by default in the Core ML converter. A Float16 typed ML program will be available to execute on the neural engine, which can present a substantial performance boost and reduction in power consumption. Since the runtime treats the types of the tensors as a minimum precision during execution, a Float32 ML Program will execute on a combination of only the GPU and the CPU. This demo demonstrated how easy it is now to control the minimum precision in which the ML Program will execute right at conversion time. And unlike neural network Core ML models, if your model needs higher precision, you do not have to change the setting of the compute unit to cpuOnly in the app code to achieve that. And as a final note, this demo notebook will be available as an example on the Core ML Tools documentation site. To recap, to get an ML program, use the convert function and pass an additional argument to specify the deployment target, and set it to at least iOS 15 or macOS 12. By default, the Core ML converter will produce an optimized Float16 model that is eligible for execution on the neural engine. If, as it might happen in some cases, the model is sensitive to Float16 precision, it’s simple to set the precision to Float32 instead. There are, in fact, more advanced options available in the Core ML Tools API, using which you can select specific ops to execute in Float32 while keeping the rest in Float16 to produce a mixed type ML Program. Please check out our documentation for these examples. In summary, Core ML has several new enhancements that make it easier to tune and work with your models. The new MLShapedArray type makes it easy to work with multidimensional data. The ML Package format allows you to edit metadata directly in Xcode. An ML Package with the new ML Program model type supports typed execution with Float32 support on GPU, giving you more options to play with as you tune your model’s performance and accuracy. We encourage you to upgrade your model to ML Packages and use ML Programs. Thanks for watching our session, and enjoy the rest of WWDC. [music]
-