-
Create ML 구성 요소 알아보기
Create ML을 이용하면 이미지 분류, 사물 인식, 사운드 분류, 손 동작 분류, 동작 분류, 테이블 형식 데이터 회귀 분석 등을 위한 맞춤형 머신 러닝 모델을 손쉽게 빌드할 수 있습니다. 또한 Create ML 구성 요소 프레임워크를 이용하면 기반 작업을 맞춤화하고 모델을 개선할 수 있습니다. 이러한 작업을 구성하는 특징 추출기, 트랜스포머 및 추정기를 살펴보고, 이러한 기능을 다른 구성 요소 및 사전 처리 단계와 결합하여 이미지 회귀 분석과 같은 개념에 대한 맞춤형 작업을 빌드하는 방법을 살펴보겠습니다. 복잡한 맞춤형 작업 생성에 대한 자세한 내용을 보려면 WWDC22의 ‘Compose advanced models with Create ML Components(Create ML 구성 요소를 통한 고급 모델 작성)'을 시청하시기 바랍니다.
리소스
관련 비디오
WWDC23
WWDC22
WWDC21
Tech Talks
WWDC20
WWDC19
-
비디오 검색…
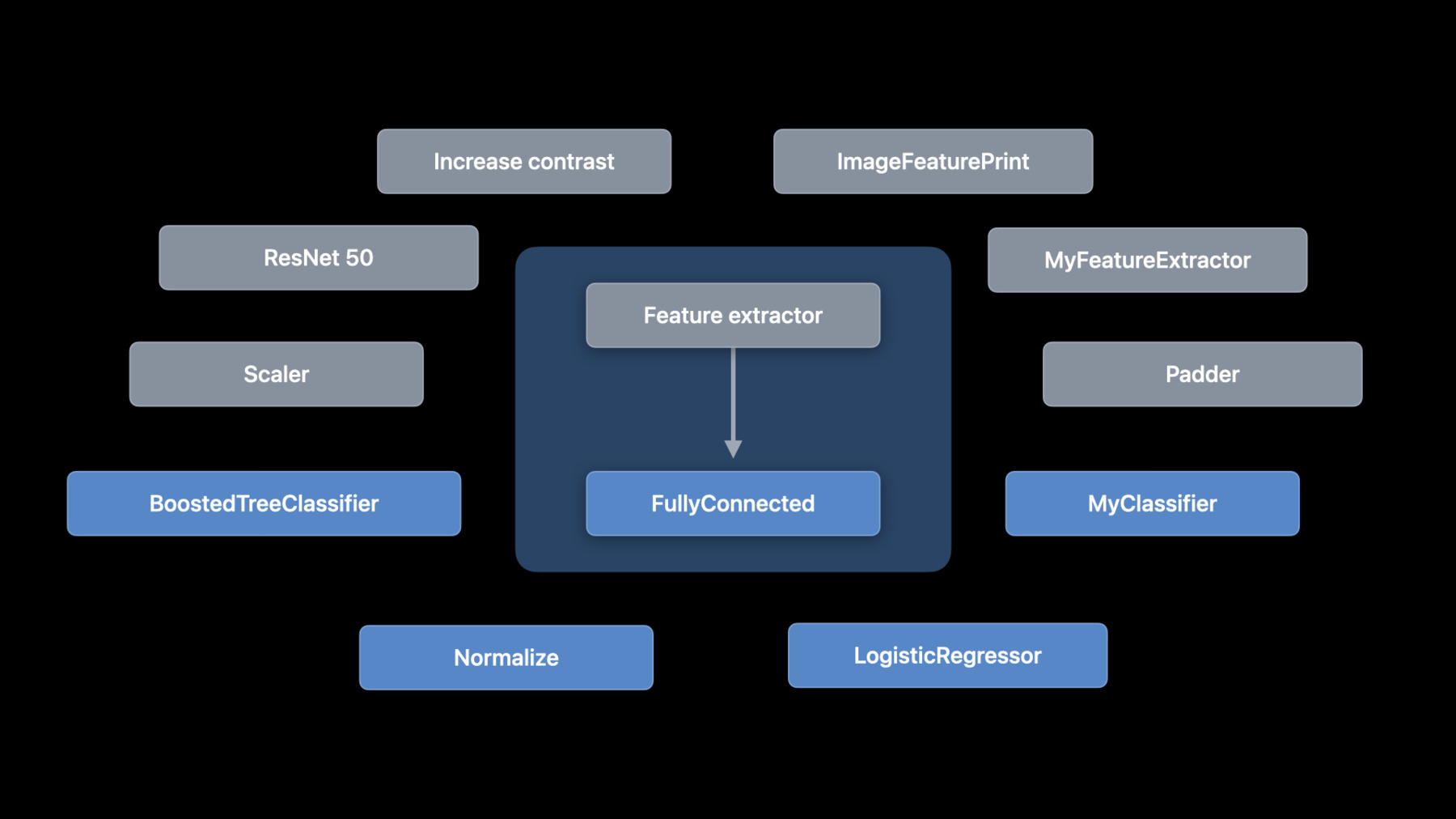
♪ 잔잔한 힙합 연주 음악 ♪ ♪ 안녕하세요, 저는 Alejandro입니다 CreateML 팀의 엔지니어예요 오늘 제가 설명할 건 구성 요소를 이용해서 기계 학습 모델을 구축하기 위한 새로운 API입니다 Create ML은 기계 학습 모델 훈련을 위한 단순한 API를 제공합니다 그건 지원받는 작업들의 집합에 기반을 두는데요 그 예로는 이미지 분류 사운드 분류 등이 있습니다 WWDC 2021에서 우린 Create ML 프레임워크에 관한 두 가지 멋진 발표를 했습니다 보신 적 없으면 꼭 확인해보세요 그런데 전 미리 정의된 작업을 넘어서는 걸 설명하고 싶습니다 Create ML이 제공하는 것 외에 여러분이 특정 문제에 대한 작업을 맞춤화하고 싶다면 어떨까요? 아니면 다른 유형의 작업을 구축하고 싶다면 어떨까요? 구성 요소를 사용해서 이제 새롭고 창의적인 방식으로 작업을 구성할 수 있습니다 자세히 알아보죠 먼저 ML 작업을 분리해서 각 구성 요소가 하는 일을 설명하겠습니다 그런 다음 구성 요소들을 하나로 합치는 방법을 말씀드리죠 이어서 맞춤형 이미지 작업의 예를 들겠습니다 그런 다음 표로 나타낸 작업을 설명하겠습니다 그리고 배치 전략으로 마무리하겠습니다 먼저 기계 학습 작업의 내부를 자세히 알아봐서 거기에 들어가는 것과 그게 작동되는 방식을 여러분에게 알려드리죠 그렇게 해서 우리가 맞춤형 작업을 구축하기 시작할 때 제 얘기를 여러분이 알 수 있게요 이미지 분류자를 예로 사용해보겠습니다 이미지 분류자는 레이블이 붙은 이미지 목록을 써서 모델을 훈련시킵니다 이 사례에서는 각각의 레이블이 있는 고양이와 강아지의 이미지가 있습니다 그런데 각 단계에서 이미지가 변환되는 방식을 살펴봅시다 그러기 위해 저는 이미지 분류 작업을 확대해서 내부에 있는 걸 보겠습니다 개념 측면에서 이미지 분류자는 아주 간단합니다 그건 특징 추출자와 분류자로 구성됩니다 하지만 중요한 부분은 Create ML 구성 요소가 이 구성 요소에 대한 접근권을 독립적으로 준다는 겁니다 구성 요소를 추가, 제거, 전환해서 새 작업을 구성할 수 있습니다 저는 구성 요소를 상자로 표현하겠습니다 화살표는 데이터의 흐름을 나타냅니다 이미지 분류자의 첫 단계를 확대해서 보죠 특징 추출입니다 일반적으로 특징 추출자는 입력의 차원성을 감소시킵니다, 흥미로운 부분만 보관하는 방식으로요 그 부분이 특징들입니다 이미지의 경우 특징 추출자는 이미지에서 패턴을 찾습니다 Create ML은 Vision Feature Print를 쓰는데 이는 Vision Framework에서 제공하는 훌륭한 이미지 특징 추출자예요 이제 두 번째 부분을 얘기해보죠 분류자입니다 분류자는 사례들의 집합을 써서 분류를 배웁니다 흔한 실행으로는 로지스틱 회귀와 부스티드 트리와 신경망이 있습니다 이미지 분류자를 훈련시키는 건 주석이 달린 이미지로 시작해서 주석이 달린 특징으로 간 다음 분류자에서 끝납니다 그런데 우린 그걸 왜 부분들로 나누려 할까요? 이유는 가능성을 확장하고 싶기 때문입니다 여러분은 대비를 증가시켜서 전처리를 하고 싶을 수도 있습니다 아니면 모든 이미지를 정규화해서 특징을 추출하기 전에 밝기를 균일하게 하고 싶을 수 있습니다 아니면 다른 특징 추출자를 써보고 싶을 수도 있고요 아니면 다른 분류자를 써보고 싶을 수도 있습니다 가능성은 무한합니다 이것들은 옵션 중 몇 가지에 불과하죠 그래서 우린 ML 구성 요소에 대한 지원을 추가했습니다 macOS, iOS, iPadOS, tvOS에서요 우리가 바라는 건 우리가 제공하는 구성 요소들과 여러분만의 구성 요소들 아니면 커뮤니티에서 다른 사람들이 구축한 구성 요소들까지 함께 사용해서 여러분이 새 모델을 구성하는 겁니다 그리고 그걸 모든 플랫폼에서 활용할 수 있는 거죠 이건 Create ML Components에 내장된 구성 요소 몇 가지입니다 그런데 한 걸음 물러서서 몇 가지 개념을 소개하겠습니다 구성 요소의 종류에는 두 가지가 있습니다 변환자와 추정자입니다 변환자는 변환을 수행할 수 있는 타입입니다 그건 입력 타입과 출력 타입을 규정합니다 예를 들어 이미지 특징 추출자는 입력 이미지를 갖고 특징들의 형상 배열을 생성합니다 반면에 추정자는 데이터로부터 학습해야 합니다 그건 입력 사례를 갖고 처리 작업을 좀 하고 변환자를 생성합니다 우린 이 과정을 '피팅'으로 부릅니다 좋아요, 그 개념 설명을 다 마쳤으니 Create ML Components가 구성을 사용해서 개별 구성 요소로부터 이미지 분류자를 구축하게 해주는 방법을 설명하겠습니다 이건 구성 요소를 사용하는 이미지 분류자입니다 거기엔 ImageFeaturePrint가 특징 추출자로 있고 LogisticRegressionClassifier가 분류자로 있습니다 구성 요소가 변환자든 추정자든 상관 없이 첨부 기법을 사용해서 그것들을 결합합니다 바로 이 지점에서 구성 요소들은 무한한 가능성을 제공합니다 여러분은 완전히 연결된 신경망을 분류자로 쓸 수 있습니다 단순한 변화만 있는 로지스틱 회귀 대신에요 아니면 CoreML model의 맞춤형 특징 추출자를 쓸 수 있습니다 예를 들어 모델 갤러리에서 발견할 수 있는 헤드가 없는 ResNet-50 model이 있죠 두 가지 구성 요소를 구성할 때 첫 번째 구성 요소의 출력은 두 번째의 입력과 일치해야 합니다 이미지 분류자의 경우 특징 추출자의 출력은 CoreML 프레임워크의 형상 배열입니다 이는 로지스틱 회귀 분류자의 입력이기도 합니다 여러분이 첨부 기법을 사용할 때 컴파일러 오류가 나오면 다음을 먼저 확인하세요 타입들이 꼭 일치하게 하세요 하지만 피팅과 관련해서 중요한 점을 분명히 하고 싶습니다 피팅은 추정자에서 변환자로 가는 과정이라고 제가 앞에서 말했습니다 그럼 이걸 구성된 추정자의 관점에서 살펴보도록 하죠 구성된 추정자에 변환자와 추정자 모두가 있을 때는 이미지 분류자에서처럼 말이죠 추정자 부분만이 피팅됩니다 하지만 변환자는 그 과정에서 중요한 부분입니다 그건 추정자의 맞춤 기법에 올바른 특징들을 넣어주는 데 사용되기 때문입니다 이게 코드입니다 이미지 분류자에는 주석이 달린 특징들의 모음이 필요합니다 거기에서 특징은 이미지이고 주석은 문자열입니다 특징들을 로딩하는 건 시연으로 들어갈 때 설명하겠습니다 데이터가 저한테 있으면 저는 맞춤 기법을 부를 수 있습니다 이는 훈련된 모델인 변환자를 돌려줍니다 반드시 주목해야 할 점은 피팅할 때 사용되는 타입들은 그 결과물인 변환기의 타입과 관련이 있지만 다르다는 겁니다 특히 맞춤 기법에서 사용되는 타입은 언제나 모아 놓은 겁니다 감시받는 추정자들의 경우 특징들에 주석이 포함되어야 합니다 Create ML Components는 AnnotatedFeature 타입을 써서 그 주석과 함께 특징을 나타냅니다 저한테 그 모델이 있으면 전 예측할 수 있습니다 그게 제가 피팅했던 모델이든 디스크에서 파라미터를 제가 로딩하든 그건 중요하지 않습니다 API는 두 경우 모두에 동일합니다 저는 분류자를 훈련시키고 있으므로 그 결과는 분류 분포입니다 그 분포에는 각 레이블에 대한 확률이 포함됩니다 이 경우에 저는 이미지에 가장 가능성이 높은 레이블을 인쇄할 뿐입니다 맞춤 기법은 훈련 이벤트를 관찰하는 메커니즘도 제공합니다 확인 수치도 포함해서요 이 예에서 저는 확인 데이터를 전달하고 확인 정확도를 인쇄 중입니다 주목하실 건 관리받는 추정치만이 확인 측정치를 제공한다는 겁니다 일단 모델을 훈련시키면 학습된 파라미터를 저장할 수 있습니다 나중에 재사용하거나 앱에 배치하기 위해서요 쓰기 기법을 사용해서 그렇게 합니다 나중에 읽기 기법을 써서 읽을 수 있습니다 여기까지 구성이었습니다 지금부터 흥미로워집니다 새 작업을 작성하는 것에 관해 설명하죠 그건 이전까지 Create ML에서 지원하지 않았습니다
여러분이 모델을 훈련시켜서 이미지에 점수를 준다면 어떨까요? 여러분한테 과일 사진이 있다고 가정해보죠 그런데 과일을 분류하는 대신 그것에 평점을 주고 싶어요 과일이 익은 정도를 바탕으로 점수를 주는 겁니다 이렇게 하려면 여러분은 분류 대신 회귀를 해야 합니다 그럼 제가 이미지 회귀자를 작성하겠습니다 그건 익은 정도에 따라 바나나 이미지에 점수를 줍니다 저는 각각의 이미지에 1부터 10까지 익은 정도 값을 줍니다 이미지 회귀자는 이미지 분류자와 아주 비슷합니다 유일한 차이는 우리의 추정자가 분류자 대신 회귀자가 될 거란 겁니다 이미 추측하셨을 수도 있지만 이건 쉬울 겁니다 여러분의 기억을 되살려드리죠 이건 이미지 분류자입니다 그리고 이건 이미지 회귀자입니다 저는 로지스틱 회귀 분류자를 선형 회귀자로 대체했습니다 이 단순한 변동은 맞춤 기법에 대한 예상 입력도 바꿔줍니다 전에 그건 이미지와 레이블을 예상했습니다 이제는 이미지와 점수를 예상하죠 개념 얘기는 여기까지만 하겠습니다 실제 코드로 이걸 시연해보죠
맞춤형 이미지 회귀자를 작성하는 방법을 보여드리겠습니다 먼저 ImageRegressor 구조를 정의해서 코드를 요약하겠습니다
저한테 익은 정도가 다른 바나나 이미지들이 있는 폴더가 있습니다 먼저 그 URL을 정의하겠습니다
다음 단계는 훈련 기법을 추가하는 겁니다 여기에서 여러분은 훈련 데이터를 사용해서 모델을 생성합니다 저는 리턴 타입에 'some'을 키워드로 써서 리턴 타입이 바뀌지 않게 하겠습니다 제가 구성된 추정자에 있는 단계를 추가하거나 수정할 때요 이제 추정자를 정의하겠습니다 그건 그저 특징 추출자에 선형 회귀자를 첨부한 겁니다 이제 저는 훈련 이미지를 그 점수와 함께 로딩해야 합니다 AnnotatedFiles를 사용하면 됩니다 그건 URL과 문자 레이블이 들어 있는 AnnotatedFeatures의 모음입니다 그건 제 필요 사항에 맞는 편의 이니셜라이저를 제공합니다 제 파일은 이름과 그걸 잇는 대시 기호와 또 이어지는 익은 정도 값으로 구성됩니다 따라서 저는 분리자가 대시라고 명시할 거고 주석은 파일 이름 구성 요소의 색인 1에 있습니다 그리고 저는 타입 argument를 써서 이미지 파일만 요청하겠습니다 이제 저한테 URL이 있으니 이미지 로딩을 해야 합니다 이를 위해 저는 mapFeatures 기법과 ImageReader를 사용할 수 있습니다 저는 점수를 문자열에서 부동 소수점 값으로 전환시켜야 하기도 합니다 이를 위해 mapAnnotations 기법을 사용할 수 있습니다
그렇게 해서 저는 훈련 데이터를 확보했습니다 그런데 전 그 일부를 인증을 위해 따로 두고 싶습니다 이렇게 하기 위해 randomSplit 기법을 쓰면 됩니다 저는 훈련을 위해 80%를 두고 나머지는 승인을 위해 사용할 겁니다 이제 피팅할 준비가 됐습니다
훈련된 파라미터들은 저장해서 제 앱에 배치할 수 있게 합니다 그걸 저장할 위치를 고릅니다
그리고 쓰기 기법을 호출합니다
마지막으로 변환자를 돌려줍니다
이것이 구성 요소를 이용해서 모델을 정의하고 훈련시키는 것의 핵심입니다 저는 구성된 추정자를 정의했고 제 훈련 데이터를 로딩했고 맞춤 기법을 호출했고 쓰기를 써서 파라미터를 저장했습니다 그런데 제가 개선할 수 있는 것들이 있습니다 먼저 저는 승인 데이터 세트를 전달하는데 승인 오류는 관찰하지 않습니다 그래서 그렇게 할 겁니다 맞춤 기법에는 수치를 수집하는 데 쓸 수 있는 이벤트 처리자가 필요합니다
일단 저는 훈련 및 승인 최대 오류 값을 인쇄하겠습니다 저는 또한 최종 모델에 대한 절대 오차 평균을 얻고 싶습니다
저는 승인 특징들에 맞춤 변환자를 적용해서 그걸 계산한 다음 실제 점수와 함께 그걸 meanAbsoluteError 함수에 전달합니다 제가 이걸 돌려봤는데 모델이 훌륭하지 못했습니다 오류가 많았습니다 이유는 저한테 바나나 이미지가 많지 않기 때문입니다 이미지를 더 구해야 하는데 그렇게 하기 전에 제 데이터 세트에 대한 증대를 시도할 수 있습니다 이미지를 회전시키고 확대해서 예를 더 많이 얻을 수 있습니다 이를 위해 저는 새로운 기법을 작성할 건데 그건 주석이 달린 이미지를 갖고 증대해줍니다 그건 주석 달린 이미지의 배열을 되돌려줍니다
제가 먼저 할 증대는 회전입니다
저는 -π와 π 사이의 각도를 임의로 고르고 그걸 써서 이미지를 회전시킵니다 무작위 확대도 하겠습니다
그리고 세 개의 이미지를 되돌려줍니다 원본 이미지, 회전된 이미지 확대된 이미지입니다
이제 제가 증대 함수를 갖게 됐으니 그것과 flaMap을 써서 제 훈련 이미지를 증대하겠습니다
제 데이터 세트의 각 요소는 배열로 전환됩니다 FlatMap은 그 배열들을 단일 배열로 평평하게 합니다 제 맞춤 기법에 필요한 거죠 주의해야 할 건 증대는 피팅할 때만 적용되고 예측에는 적용되지 않는다는 겁니다 좋아요, 이게 정확도를 높여줬어요 그런데 제 모델을 더 좋게 만들어줄 개선 사항을 하나 더 말씀드릴게요 저는 Vision 프레임워크를 써서 핵심 물체로 이미지들을 잘라내고 싶습니다 이건 제 훈련 데이터에 있는 이미지들 중 하나입니다 누군가 배경에 다른 과일들 속에서 바나나를 들고 있습니다 모델은 사진에 있는 다른 물체들로 혼동할 수 있어요 Vision 프레임워크 API를 써서 저는 가장 핵심적인 물체로 이미지를 자동으로 잘라낼 수 있습니다 그렇게 하려면 WWDC 2019의 Vision 발표를 확인해보세요 저는 제 모든 이미지에 이 변환을 쉽게 적용할 수 있어요 피팅할 때와 예측할 때 모두요 제가 맞춤형 변환자를 작성한다면요 방법을 보여드리죠 변환자 프로토콜 준수를 위해 제가 해야 할 유일한 건 응용 기법을 실행하는 겁니다 이 경우에 저는 이미지를 갖고 이미지를 되돌려주고 싶습니다 이 코드는 설명하지 않겠습니다 이것만 말해두죠, 제가 핵심 물체를 얻지 못한다면 원본 이미지를 되돌려줄 겁니다 이제 저한테 맞춤형 변환자가 있으니 그걸 제 이미지 회귀자에 넣겠습니다
특징 추출 전에 제 맞춤형 변환자를 사용하기만 하면 됩니다
이제 중요점이 제 작업 정의의 일부가 됐으니 그건 모든 훈련 이미지를 잘라내는 데 사용될 거고 추론할 때도 사용될 겁니다 이것이 훈련과 추론 사이에서 작업 정의를 공유하는 것의 장점 중 하나입니다 다음 작업으로 넘어가기 전에 핵심 요점들을 강조해보겠습니다 구성 요소를 사용해서 전 이제 맞춤형 작업을 만들 수 있습니다 저는 첨부 기법을 써서 이걸 했습니다 AnnotatedFiles를 써서 주석이 달린 파일 이름이 있는 제 파일들을 로딩했는데 디렉토리 별로 주석이 달린 파일들도 로딩할 수 있습니다 저는 ImageReader를 써서 URL을 이미지에 매핑했고 주석을 문자열에서 값으로 매핑했습니다 저는 randomSplit을 써서 승인 데이터 세트를 따로 두고 훈련된 파라미터들은 추후 사용을 위해 저장했습니다 그리고 전 증대를 가하고 맞춤형 변환자를 정의해서 제 모델을 개선했습니다 그런데 이건 이미지에만 효과가 있는 게 아닙니다 주제를 바꿔서 다른 종류의 작업을 설명하겠습니다 표로 나타낸 작업입니다 그건 표로 나타낸 데이터를 사용하는 작업입니다 표로 나타낸 데이터는 다양한 타입의 다중 기능을 갖는 특징이 있습니다 거기에는 수치 데이터와 범주 데이터가 포함될 수 있습니다 유명한 사례는 주택 가격 책정 데이터입니다 지역과 건축 연령 같은 게 있고 주변 동네 같은 것과 건물 종류 등이 있습니다 값을 예측하는 방법도 배우는 게 좋습니다 값의 예로는 판매가가 있겠죠 2021년에 우린 TabularData 프레임워크를 도입했습니다 이제 여러분은 TabularData 프레임워크를 Create ML Components와 함께 사용해서 표로 나타낸 분류자와 회귀자를 구축하고 훈련시킬 수 있습니다 저는 TabularData에 관한 기술 토론도 추천합니다 그건 데이터 탐색에 대한 멋진 소개로 표로 나타낸 작업을 구축할 때 필요할 가능성이 높습니다 자세히 알아보죠 표로 나타낸 데이터를 다룰 때는 표의 각 열에 여러 종류의 특징이 있을 겁니다 여러분은 각 열을 다르게 처리하고 싶을 수 있습니다 거기에 들어 있는 정보의 종류에 따라서 말이죠 분포와 값의 범위와 기타 요인들이 있습니다 Create ML Components는 ColumnSelector로 이걸 하게 하죠 예는 다음과 같습니다 제가 주택 가격을 언급했었는데 그건 황당한 수준이죠 그 대신 아보카도 가격을 사용하겠습니다 여기 아보카도 가격표가 있습니다 저는 표로 나타낸 회귀자를 구축해서 그걸 바탕으로 아보카도 가격을 예측하고 싶습니다 여기에는 수치 데이터가 있는 열이 있습니다 그 데이터엔 포대 년도, 부피가 있고 유형과 지역 같은 범주형 데이터가 있는 열도 있죠 일부 회귀자들은 이 값들의 표현 방식이 더 좋아서 혜택을 받습니다 예를 들어 이건 데이터 세트의 부피 값 분포입니다 정규 분포에 가깝지만 많은 값이 15,000 주위에 몰려 있습니다 이건 정규화로 혜택을 받을 수 있는 데이터 세트의 멋진 사례라고 봅니다 따라서 먼저 하면 좋은 건 이 값들을 정규화하는 겁니다 이렇게 하기 위해 저는 정규화하고 싶은 열 이름을 ColumnSelector에 전달하고 일반 스케일러를 사용합니다 코드는 이렇습니다 먼저 ColumnSelector를 만듭니다 그리고 스케일하고 싶은 열 이름을 전달합니다 모든 열에 동일한 종류의 요소가 들어 있어야 합니다 이 경우에 그건 Double입니다 그리고 옵셔널을 풀어줍니다 제가 이렇게 할 수 있는 이유는 결측 값이 없단 걸 알기 때문이죠 그런데 전 결측 값을 대체할 귀속자를 사용할 수도 있습니다 그런 다음 StandardScaler를 언래퍼에 덧붙입니다 저는 이 표에서 시작했는데 거기에서 포대의 수는 만 자리였고 부피의 수는 10만 자리였습니다 그 열들에 대한 스케일링 후 그 결과 나오는 값들은 이제 규모가 1에 가까워졌습니다 그건 제 모델의 성능을 향상시킬 수 있습니다 구체적으로 말해서 제 값들은 이제 그 평균이 0이고 표준 편차가 1입니다 이것도 유사한 사례지만 이 사례에서 저는 유형과 지역 열을 선택합니다 그것들은 문자열 타입이고 '원 핫 인코딩'을 수행합니다 원 핫 인코딩은 배열을 써서 범주형 데이터를 인코딩하여 각 범주의 존재를 표시하는 걸 지칭합니다 이 사례에서는 범주가 세 가지입니다 금, 은, 동입니다 각각은 배열 내에서 독특한 위치에 있는데 그 위치에서 1로 표시됩니다 한 가지 대안은 서수 인코더를 쓰는 건데 그건 각 범주에 연속적인 번호를 부여합니다 범주가 몇 개만 있으면 원 핫 인코더를 쓰고 그 외에는 서수 인코더를 쓰세요 이제 그것들을 모두 합쳐서 표로 나타낸 회귀자를 구축해보죠
앞에서처럼 저는 구조를 만들기 시작하고 데이터 URL과 파라미터 URL을 정의합니다
저는 또한 예측하고 싶은 열인 가격에 대한 열 ID를 정의하는 게 좋습니다
전 제 작업을 별도로 정의해서 훈련 기법과 예측 기법 모두에서 이용할 수 있게 할 겁니다
언급했듯이 저는 부피를 정규화할 겁니다
그런 다음 부스티드 트리 회귀자를 사용해서 가격을 예측하겠습니다 그건 주석 열의 이름을 갖고 가서... 그 열은 예측 결과가 있는 열이기도 하죠 세 가지 특징 열 모두의 이름을 갖고 갑니다 이 세 열로 시작하겠습니다 그런 다음 첨부 기법을 써서 그 부분들을 합치고 작업을 되돌려줍니다
이제 제 작업 정의가 있으니 이전처럼 훈련 기법을 추가하겠습니다
역시 전처럼 저는 리턴 타입이 제 모델의 세부 사항에 달려 있지 않게 하고 싶습니다 첫 단계는 CSV 파일을 데이터 프레임에 로딩하는 겁니다 이걸 하기 위해 저는 TabularData 프레임워크를 씁니다 그리고 전처럼 데이터의 일부를 인증을 위해 분리하고 싶습니다
저는 훈련과 인증 데이터 세트를 맞춤 기법에 전달합니다
또한 전처럼 인증 오류를 보고합니다 그리고 추후 사용을 위해 훈련된 파라미터를 저장합니다
마지막으로 저는 변환자를 되돌려줍니다
일단 훈련된 변환자를 확보하면 전 그걸 써서 데이터 프레임에 가격 예측을 할 수 있습니다 저는 이걸 하기 위해 예측 기법을 작성할 겁니다
먼저 작업 정의와 파라미터 URL에서 모델을 로딩합니다
제가 예측을 위해 사용하는 데이터 프레임에 제가 특징으로 썼던 열들이 있게 해야 합니다 유형, 지역, 부피입니다 예측 값은 가격 열에 있을 겁니다 제가 상단에서 정의했던 열 ID를 사용하겠습니다
이것으로 표를 나타낸 제 회귀자를 마무리하겠습니다 저한텐 훈련 기법이 있는데 훈련된 파라미터를 생성하려면 그걸 한 번만 호출하면 됩니다 그리고 예측 기법도 있는 데 그건 아보카도 가격을 돌려줍니다 아보카도의 유형과 지역과 부피를 바탕으로 한 예측이죠 제 앱에 쓰기 위해 필요한 건 그게 다입니다 표로 나타낸 작업에서 일할 때 명심해야 할 것들은 다음과 같습니다 여러분은 ColumnSelector 연산을 사용해서 특정한 열들을 처리할 수 있습니다 주목할 만한 점은 트리 분류자와 회귀자는 모두 표로 나타내지만 그렇지 않은 추정자도 쓸 수 있단 겁니다 가령 표로 나타낸 작업에서의 선형 회귀자를요, Annotated FeatureProvider를 써서요 문헌을 참고해주세요 예측할 때는 필요한 열이 있는 데이터 프레임을 구축하세요 반드시 올바른 타입을 사용해서요 이제 여러분이 맞춤형 작업을 구축하는 방법을 알았으니 배치를 설명하겠습니다 지금까지 저는 훈련과 추론을 위해 동일한 API를 사용했습니다 제가 강조하고 싶은 건 Create ML Components를 사용할 때 여러분의 모델이 곧 여러분의 코드란 겁니다 여러분에겐 작업 정의가 필요합니다 파일에서 훈련된 파라미터를 로딩할 때도요 이는 일부 상황에서 유용하지만 배치를 위해 Core ML을 사용하는 게 좋을 때도 있습니다 Core ML을 사용할 때는 여러분은 코드를 버립니다 그 모델은 모델 파일로 완전하게 표현됩니다 여러분이 이미 Core ML을 쓰고 있으면 이건 작업 흐름으로 좋을 수 있습니다 그리고 거기엔 최적화된 텐서 연산이란 장점이 있습니다 그런데 명심해야 할 몇 가지 고려 사항이 있습니다 Core ML이 모든 연산을 지원하는 건 아닙니다 구체적으로 맞춤형 변환자와 추정자가 지원되지 않습니다 그리고 Core ML은 이미지나 형상 배열처럼 몇 가지 타입만 지원합니다 여러분이 맞춤형 타입을 사용한다면 Core ML 모델을 쓸 때는 그걸 여러분의 앱에서 전환해야 할 수 있습니다 이게 여러분의 전환자를 Core ML 모델로 내보낼 수 있는 방법입니다 여러분의 전환자에 지원받지 않는 연산이 들어 있으면 이건 오류를 발생시킵니다 여러분이 훈련된 파라미터와 함께 작업 정의를 배치하는 걸 고수하고 싶다면 그것들을 Swift 패키지로 묶는 걸 고려해야 합니다 그런 방식으로 여러분은 간단한 기법을 제공해서 파라미터를 로딩하고 예측할 수 있습니다 Swift 패키지 자료에 관한 자세한 정보를 원하면 WWDC 2020의 Swift 패키지 발표를 확인해보세요 제 발표는 여기까지입니다 잊지 말아야 할 중요한 건 이제 구성으로 맞춤형 작업을 만들 수 있단 겁니다 가능성은 무한합니다 여러분이 구축한 걸 보길 기대합니다 오디오 및 비디오 작업을 비롯한 고급 기술을 자세히 알고 싶으면 다음을 확인해보세요 'Compose advanced models with Create ML Components'입니다 거기에서 제 동료 데이비드가 더욱 고급스러운 맞춤형 작업들을 제시해줄 겁니다 감사합니다, WWDC 2022의 남은 일정도 즐기세요 ♪
-
-
8:59 - Image regressor
import CoreImage import CreateMLComponents struct ImageRegressor { static let trainingDataURL = URL(fileURLWithPath: "~/Desktop/bananas") static let parametersURL = URL(fileURLWithPath: "~/Desktop/parameters") static func train() async throws -> some Transformer<CIImage, Float> { let estimator = ImageFeaturePrint() .appending(LinearRegressor()) // File name example: banana-5.jpg let data = try AnnotatedFiles(labeledByNamesAt: trainingDataURL, separator: "-", index: 1, type: .image) .mapFeatures(ImageReader.read) .mapAnnotations({ Float($0)! }) let (training, validation) = data.randomSplit(by: 0.8) let transformer = try await estimator.fitted(to: training, validateOn: validation) try estimator.write(transformer, to: parametersURL) return transformer } } -
12:18 - Image regressor with metrics and augmentations
import CoreImage import CreateMLComponents struct ImageRegressor { static let trainingDataURL = URL(fileURLWithPath: "~/Desktop/bananas") static let parametersURL = URL(fileURLWithPath: "~/Desktop/parameters") static func train() async throws -> some Transformer<CIImage, Float> { let estimator = SaliencyCropper() .appending(ImageFeaturePrint()) .appending(LinearRegressor()) // File name example: banana-5.jpg let data = try AnnotatedFiles(labeledByNamesAt: trainingDataURL, separator: "-", index: 1, type: .image) .mapFeatures(ImageReader.read) .mapAnnotations({ Float($0)! }) .flatMap(augment) let (training, validation) = data.randomSplit(by: 0.8) let transformer = try await estimator.fitted(to: training, validateOn: validation) { event in guard let trainingMaxError = event.metrics[.trainingMaximumError] else { return } guard let validationMaxError = event.metrics[.validationMaximumError] else { return } print("Training max error: \(trainingMaxError), Validation max error: \(validationMaxError)") } let validationError = try await meanAbsoluteError( transformer.applied(to: validation.map(\.feature)), validation.map(\.annotation) ) print("Mean absolute error: \(validationError)") try estimator.write(transformer, to: parametersURL) return transformer } static func augment(_ original: AnnotatedFeature<CIImage, Float>) -> [AnnotatedFeature<CIImage, Float>] { let angle = CGFloat.random(in: -.pi ... .pi) let rotated = original.feature.transformed(by: .init(rotationAngle: angle)) let scale = CGFloat.random(in: 0.8 ... 1.2) let scaled = original.feature.transformed(by: .init(scaleX: scale, y: scale)) return [ original, AnnotatedFeature(feature: rotated, annotation: original.annotation), AnnotatedFeature(feature: scaled, annotation: original.annotation), ] } } -
20:23 - Tabular regressor
import CreateMLComponents import Foundation import TabularData struct TabularRegressor { static let dataURL = URL(fileURLWithPath: "~/Downloads/avocado.csv") static let parametersURL = URL(fileURLWithPath: "~/Downloads/parameters.pkg") static let priceColumnID = ColumnID("price", Double.self) static var task: some SupervisedTabularEstimator { let numeric = ColumnSelector( columns: ["volume"], estimator: OptionalUnwrapper() .appending(StandardScaler<Double>()) ) let regression = BoostedTreeRegressor<String>( annotationColumnName: priceColumnID.name, featureColumnNames: ["type", "region", "volume"] ) return numeric.appending(regression) } static func train() async throws -> some TabularTransformer { let dataFrame = try DataFrame(contentsOfCSVFile: dataURL) let (training, validation) = dataFrame.randomSplit(by: 0.8) let transformer = try await task.fitted(to: DataFrame(training), validateOn: DataFrame(validation)) { event in guard let validationError = event.metrics[.validationError] as? Double else { return } print("Validation error: \(validationError)") } try task.write(transformer, to: parametersURL) return transformer } static func predict( type: String, region: String, volume: Double ) async throws -> Double { let model = try task.read(from: parametersURL) let dataFrame: DataFrame = [ "type": [type], "region": [region], "volume": [volume] ] let result = try await model(dataFrame) return result[priceColumnID][0]! } }
-