-
Core ML 사용 최적화
Core ML이 CPU, GPU 및 Neural Engine과 함께 작동하여 기기 내에서 앱의 개인 정보를 보호하는 머신 러닝 경험을 지원하는 방법을 알아보세요. 여러분의 모델 성능을 이해하고 극대화하기 위한 최신 도구를 살펴보겠습니다. 또한 모델 성능 특성을 손쉽게 이해할 수 있도록 보고서를 생성하는 방법을 보여드리고, Core ML Instrument로 모델에 대한 통찰력을 얻는 데 도움을 드리며, 앱에서 Core ML 통합을 더욱 최적화할 수 있는 API의 향상된 기능을 안내합니다. 이 세션을 최대한 활용하려면 WWDC21의 ‘Tune your Core ML models(Core ML 모델 조정)'를 시청하시기 바랍니다.
리소스
관련 비디오
WWDC23
WWDC22
-
비디오 검색…
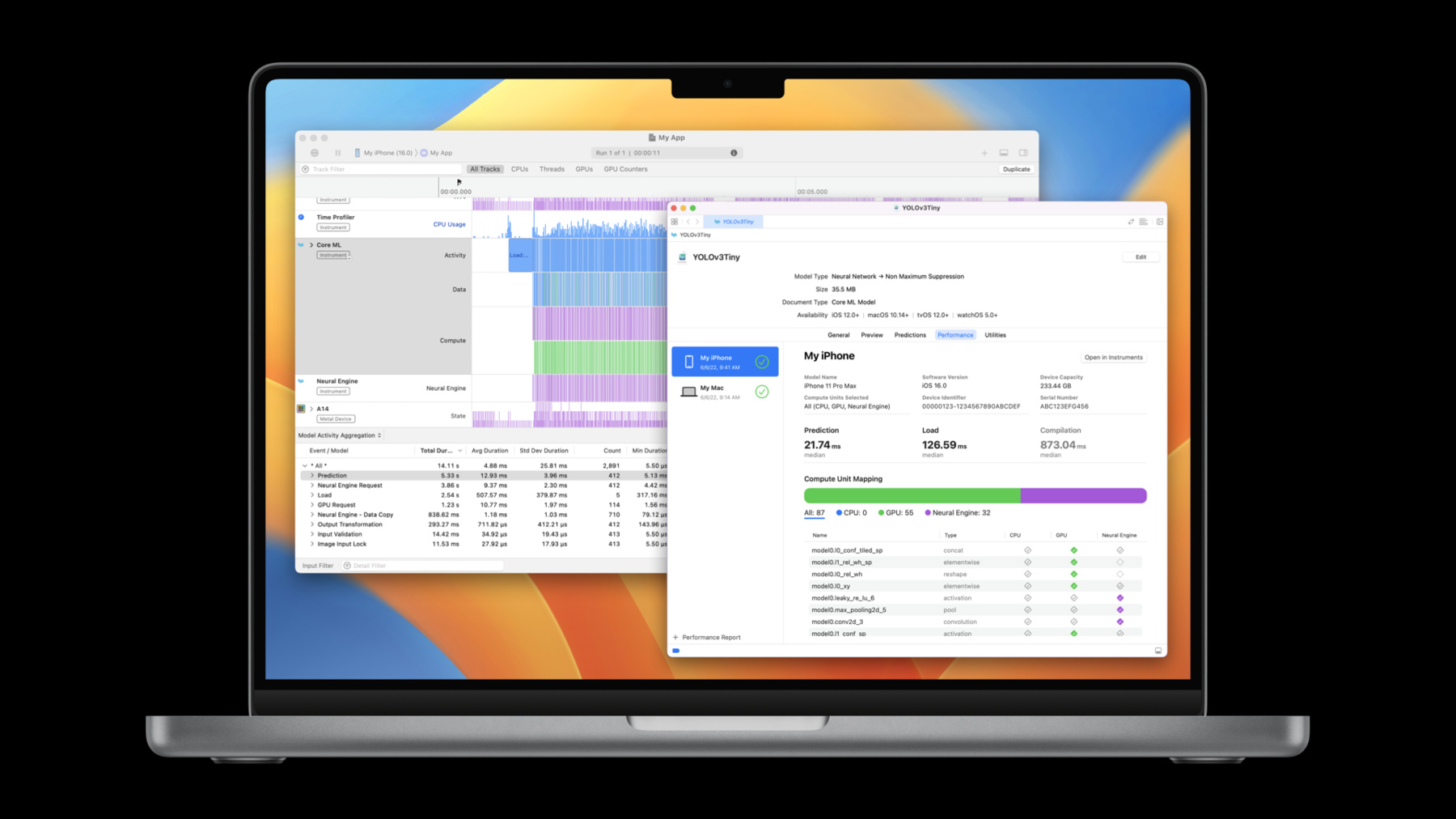
♪ 잔잔한 힙합 연주 음악 ♪ ♪ 안녕하세요, 저는 Ben입니다 Core ML 팀의 엔지니어죠 오늘 제가 보여드릴 건 Core ML에 추가되는 흥미진진한 새 기능들입니다 이 기능들이 집중하는 건 Core ML 사용의 최적화를 돕는 겁니다 이 세션에서는 현재 사용 가능한 성능 툴을 살펴보면서 여러분 모델의 성능을 이해하고 최적화하는 데 필요한 정보를 전해드리는 겁니다 Core ML을 사용할 때요 그리고 여러분의 최적화 작업을 가능하게 해주는 향상된 API들도 살펴보겠습니다 그리고 마지막으로 추가 Core ML 기능들과 통합 옵션들에 관한 개요를 설명하겠습니다 성능 툴부터 시작해보죠 배경을 알려드리기 위해 여러분의 앱에서 Core ML을 사용할 때 표준 작업 흐름을 요약하면서 시작하겠습니다 첫 단계는 모델을 선택하는 겁니다 그건 다양한 방식으로 할 수 있습니다 가령 Core ML 툴을 사용해서 PyTorch나 TensorFlow 모델을 Core ML 형식으로 전환하거나 기존 Core ML 모델을 사용하거나 Create ML을 사용해서 모델을 훈련시키거나 내보내는 겁니다 모델 전환에 관해 자세히 알고 싶거나 Create ML을 학습하고 싶으면 이 세션들을 확인하시는 걸 추천합니다 다음 단계는 그 모델을 여러분의 앱에 결합시키는 겁니다 이는 여러분의 애플리케이션으로 모델을 묶는 작업과 Core ML API들을 써서 그 모델을 로딩하고 추론을 돌리는 겁니다 여러분의 앱이 실행되는 동안요 마지막 단계는 Core ML의 사용 방식을 최적화하는 겁니다 먼저 모델 선택을 설명하겠습니다 여러분이 고려하면 좋은 모델의 측면은 많습니다 그 모델을 여러분의 앱에서 써야 할지 판단할 때요 또한 여러분이 선택하고 싶은 모델 후보자들이 다수가 있을 수 있는데 어떤 걸 써야 할지 어떻게 판단할까요? 여러분이 보유해야 할 모델은 그 기능이 여러분이 가능하게 하고 싶은 특징을 충족시키는 겁니다 그것에는 모델의 정확성과 함께 그 성능을 아는 것도 포함됩니다 Core ML 모델을 학습할 아주 좋은 방법은 그걸 Xcode에서 여는 겁니다 어느 모델에든 더블 클릭하면 이런 화면이 뜹니다 상단에 여러분은 모델 타입과 그 크기와 운영 체제 요건이 보입니다 General 탭에서는 모델의 메타데이터에서 확보된 추가 세부 정보들과 그것의 계산 및 저장 정확성과 정보가 보입니다, 가령 그게 예측할 수 있는 클래스 레이블이죠 Preview 탭은 모델을 테스트하기 위한 겁니다 예시 입력을 제공하고 그게 예측하는 걸 보는 방식으로요 Predictions 탭은 모델의 입력과 출력을 나타냅니다 런타임 때 Core ML이 예상할 타입과 크기도 나타내고요 그리고 마지막으로 Utilities 탭은 모델 암호화와 배치 작업을 도울 수 있습니다 전체적으로 이 뷰들은 여러분에게 모델의 기능에 대한 간단한 개요와 그 정확성의 미리 보기를 제공합니다 그런데 여러분 모델의 성능은 어떨까요? 모델 로딩의 비용이나 한 번의 예측에 필요한 시간이나 그것이 활용하는 하드웨어는 여러분의 이용 사례에 결정적인 요인일 수 있습니다 여러분에겐 실시간 스트리밍 데이터 제약과 관련된 중대한 목표가 있거나 인식된 지연 시간에 따른 사용자 인터페이스와 관련된 핵심 디자인 판단을 내려야 할 수 있습니다 모델의 성능에 관한 통찰을 얻는 한 가지 방법은 여러분 앱으로의 최초 통합을 하거나 여러분이 설치하고 측정할 수 있는 작은 프로토타입을 만드는 겁니다 성능은 하드웨어에 의존하므로 여러분은 지원되는 다양한 하드웨어에서 이 측정들을 하고 싶을 가능성이 높습니다 Xcode와 Core ML은 이제 이 작업을 도울 수 있습니다 코드 한 줄을 작성하기도 전에요 Core ML은 이제 성능 보고서를 만들 수 있게 해줍니다 제가 보여드리죠
이제 전 Xcode 모델 뷰어를 YOLOv3 객체 감지 모델을 위해 열어놨습니다 Predictions와 Utilities 탭 사이에 이제 Performance 탭이 있습니다 성능 보고서를 생성하기 위해 좌측 하단에 있는 + 아이콘을 선택하겠습니다 그걸 돌리고 싶은 기기를 선택합니다 그건 제 iPhone이죠 Next를 클릭한 다음 Core ML이 사용했으면 하는 계산 단위를 선택합니다 저는 그걸 All에 놔둬서 Core ML이 이용 가능한 모든 계산 단위에서 지연 시간을 최적화할 수 있게 합니다 이제 Run Test를 눌러서 마무리합니다 테스트가 돌아갈 수 있게 하기 위해 선택된 기기의 잠금이 풀렸는지 꼭 확인하세요 성능 보고서가 생성되는 동안 그건 회전하는 아이콘을 보여줍니다 보고서를 만들기 위해 모델은 기기에 전송되고 컴파일, 로딩, 예측의 몇 차례 반복이 있습니다 그건 모델로 실행됩니다 그것들이 일단 완료되면 성능 보고서의 수치들이 계산됩니다 이제 그게 제 iPhone에서 모델을 돌렸고 성능 보고서를 보여줍니다 상단에서 그건 테스트가 돌아갔던 기기에 관한 자세한 내용과 함께 어떤 계산 단위가 선택됐는지를 보여줍니다 다음으로 그건 돌린 것에 관한 통계치를 보여줍니다 예측 시간의 중앙값은 22.19ms였고 로딩 시간 중앙값은 약 400ms였습니다 또한 기기에서 여러분의 모델을 컴파일할 계획이라면 이건 번역 시간이 약 940ms이었단 걸 보여줍니다 약 22ms의 예측 시간으로 알 수 있는 건 이 모델이 초당 약 45프레임을 지원할 수 있다는 겁니다 제가 그걸 실시간으로 돌리고 싶다면요
이 모델에는 신경망이 들어 있기 때문에 성능 보고서의 하단으로 가면서 레이어 뷰가 나옵니다 이게 보여주는 건 모든 레이어의 이름 및 타입과 함께 각각의 레이어가 어떤 계산 단위에서 돌았는지예요 채워진 체크 표시는 그 계산 단위에서 레이어가 실행됐다는 뜻입니다 채워지지 않은 체크 표시는 그 계산 단위에서 레이어가 지원되긴 하지만 Core ML이 그걸 거기에서 돌리기로 하지 않았단 뜻이죠 그리고 빈 다이아몬드는 그 계산 단위에서 레이어가 지원되지 않는다는 뜻입니다 이 경우에는 54개의 레이어가 GPU에서 돌아갔고 32개의 레이어가 Neural Engine에서 돌아갔습니다 여러분은 레이어들 위에 클릭해서 계산 단위로 그걸 필터링할 수도 있습니다
그게 Xcode 14를 사용해서 Core ML 모델의 성능 보고서를 생성하는 방법이었습니다 이번엔 iPhone에서 돌아가는 걸 보여드렸지만 그건 여러분이 다수의 운영 체제와 하드웨어 조합에서 테스트할 수 있게 해줍니다 코드 한 줄도 작성하지 않은 채로요 이제 여러분이 자신의 모델을 선택했으니 다음 단계는 이 모델을 여러분의 앱에 결합시키는 겁니다 여기에는 여러분의 앱으로 모델을 묶는 일과 Core ML API를 사용해서 모델을 로딩하고 그걸로 예측하는 게 포함됩니다 이 경우에 저는 앱을 하나 만들었는데 앱은 Core ML 스타일 전송 모델을 사용해서 실시간 카메라 세션에서 프레임에 스타일 전송을 수행합니다 이건 제대로 돌아갑니다 하지만 프레임률이 제 예상보다 느려서 전 그 이유를 알고 싶습니다 이때 여러분은 3단계로 넘어갑니다 그건 Core ML 사용을 최적화하는 겁니다 성능 보고서를 생성하는 일은 모델이 독립형 환경에서 성취할 수 있는 성능을 보여줄 수 있습니다 하지만 여러분에겐 앱에서 실시간으로 돌아가는 모델의 성능을 프로파일링할 방법도 필요합니다 이를 위해 여러분은 이제 Xcode 14의 Instruments 앱에서 보이는 Core ML Instrument를 쓸 수 있습니다 이 Instrument는 여러분의 모델이 앱에서 실시간으로 돌아갈 때 성능을 볼 수 있게 해주고 잠재적인 성능 문제들을 파악할 수 있게 해줍니다 그게 사용되는 방법을 보여드리죠 저는 Xcode로 들어갔습니다 제 스타일 전송 앱 작업 공간이 열려 있고 저는 앱을 프로파일링할 준비가 됐습니다 Run 버튼을 강제로 클릭하고 Profile을 선택하겠습니다
그건 제 기기의 최신 버전의 코드를 설치하고 저를 위해 Instruments를 열어줍니다 제 목표 기기와 앱이 선택된 상태에서요 저는 Core ML 사용을 프로파일링하고 싶으니 Core ML 템플릿을 선택하겠습니다 이 템플릿에는 Core ML Instrument가 포함되죠 Core ML 사용을 프로파일링해주는 다른 유용한 Instrument들도요 흔적을 캡처하기 위해 저는 Record를 누르겠습니다
앱은 이제 제 iPhone에서 돌아가고 있습니다 몇 초 동안 돌아가게 한 다음 다른 스타일들을 쓰겠습니다 이제 Stop 버튼을 눌러서 흔적 캡처를 마치겠습니다 이제 제 Instruments 흔적을 확보했습니다 Core ML Instrument에 집중하겠습니다 Core ML Instrument는 흔적에서 캡쳐된 모든 Core ML event를 보여줍니다 초기 뷰는 모든 이벤트를 세 개의 레인으로 묶습니다 Activity, Data, Compute입니다 Activity 레인은 최고 수준의 Core ML 이벤트들을 보여주는데 이벤트들은 여러분이 직접 호출하는 실제 Core ML API들과 1대 1 관계를 맺고 있습니다 그 예로는 로딩이나 예측이 있죠 Data 레인은 Core ML이 데이터 확인이나 데이터 변환을 수행하는 이벤트들을 보여줍니다 그게 모델의 입력 및 출력과 안전하게 작동할 수 있게 하기 위해서요 Compute 레인은 Core ML이 특정 계산 단위에 언제 계산 요청을 전송하는지를 보여줍니다 그 단위의 예는 Neural Engine이나 GPU입니다 여러분은 Ungrouped 뷰를 선택할 수도 있습니다 거기엔 이벤트 타입마다 개별 레인이 있습니다 하단엔 Model Activity Aggregation 뷰가 있습니다 이 뷰는 흔적이 표시된 모든 이벤트의 집계 통계를 제공합니다 예를 들어 이 흔적에선 모델 로딩에 평균 17.17ms가 걸렸고 예측에는 평균 7.2ms가 걸렸습니다 그게 이벤트를 지속 시간에 따라 정렬할 수 있다는 데 주의하세요 여기에서 목록으로 알 수 있는 건 모델로 예측하는 것보다 그걸 로딩하는 데 시간이 더 많이 걸린다는 겁니다 로딩에 걸린 총 6.41초를 예측의 단 2.69초와 비교해서요 이건 낮은 프레임률과 관련이 있을 수 있습니다 이 많은 로딩이 어디에서 오는지 알아보죠
제가 발견 중인 건 각각의 예측을 호출하기 전에 Core ML model을 다시 로딩하고 있다는 겁니다 이건 일반적으로 좋은 관례가 아닙니다 모델을 한 번 로딩해서 메모리에 넣어둘 수 있거든요 제 코드로 되돌아가서 이걸 고쳐보겠습니다
제가 모델을 로딩하는 코드 영역을 발견했습니다 여기에서 문제는 이게 계산된 속성이란 겁니다 그건 제가 styleTransferModel 변수를 참고할 때마다 그게 그 속성을 다시 계산한다는 뜻이죠 이 경우에 그건 모델을 다시 로딩한다는 뜻입니다 저는 이걸 빨리 수정할 수 있습니다 이게 게으른 변수가 되도록 바꾸는 방식으로요
이제 앱을 다시 프로파일링해서 이게 반복되는 로딩 문제를 고쳤는지 확인해보겠습니다
저는 다시 한 번 Core ML 템플릿을 선택해서 흔적을 캡처합니다 이건 제 예상에 훨씬 더 가깝네요 카운트 열로 알 수 있는 건 총 5개의 로딩 이벤트가 있다는 건데 그건 제가 앱에서 썼던 스타일의 수와 일치하고 로딩의 총 지속 시간이 예측의 총 지속 시간보다 훨씬 짧습니다 또한 제가 스크롤할 때… 그건 반복된 예측 이벤트를 제대로 보여줍니다 각각의 이벤트 사이에 로딩 없이 말이죠
또 하나 주목할 점은 지금까지 제가 모든 Core ML 활동을 보여주는 뷰만 봤다는 겁니다 이 앱에는 스타일별로 Core ML 모델 하나가 있어서 저는 모델별로 Core ML 활동을 분류하고 싶을 수 있습니다 Instrument는 그 일을 쉽게 만들어줍니다 메인 그래프에서 좌측 상단의 화살표를 클릭할 수 있습니다 그럼 그건 흔적에서 사용되는 모델별로 하나의 서브트랙을 만들어줍니다 여기에서 그건 사용된 다양한 스타일 전송 모델을 모두 표시해줍니다 Aggregation 뷰도 유사한 기능을 제공해줍니다 모델별로 통계치를 분류할 수 있게 해줘서요
다음으로 저는 제 모델 중 하나의 예측으로 가보고 싶습니다 그게 돌아가고 있는 방식을 더 잘 알기 위해서요 Watercolor 모델을 좀 더 깊이 살펴보겠습니다
이 예측에서 Compute 레인으로 알 수 있는 건 제 모델이 Neural Engine과 GPU의 조합에서 작동됐다는 겁니다 Core ML은 이 계산 요청을 비동기식으로 전송해서 이 계산 단위들이 언제 활동하며 모델을 돌리는지 아는 데 제가 관심이 있다면 저는 Core ML Instrument를 GPU Instrument 및 새 Neural Engine Instrument와 조합할 수 있습니다 이렇게 하기 위해 저는 세 개의 Instrument를 여기 고정시켰습니다
Core ML Instrument는 모델이 돌아갔던 모든 지역을 저에게 보여줍니다
그리고 이 지역 내에서 Neural Engine Instrument는 계산이 먼저 Neural Engine에서 돌아가는 걸 보여주고 GPU Instrument는 모델이 Neural Engine에서 전달되어 GPU에서 돌아가는 걸 마친 걸 보여줍니다 이건 제 모델이 하드웨어에서 실제로 실행되는 방식을 더 잘 알게 해줍니다 정리하자면 저는 Xcode 14에서 Core ML Instrument를 사용해서 제 모델이 앱에서 실시간으로 돌아갈 때 그것의 성능을 알게 됐습니다 그런 다음 문제를 파악했습니다 제 모델을 너무 자주 다시 로딩하는 문제였습니다 그 문제를 제 코드에서 고쳤고 애플리케이션을 재프로파일링했고 문제가 고쳐졌다는 걸 입증했습니다 저는 Core ML과 GPU와 새 Neural Engine Instrument를 조합해서 제 모델이 다양한 계산 단위에서 실제로 돌아갔던 방식에 관한 자세한 내용을 알 수 있었습니다 여기까지가 여러분이 성능을 이해하도록 돕는 새로운 툴에 대한 개요였습니다 다음으로는 그 성능을 최적화하게 해줄 수 있는 향상된 API들을 알아보겠습니다 먼저 Core ML이 모델 입력과 출력을 처리하는 방식을 알아보겠습니다 여러분이 Core ML 모델을 만들 때 그 모델에는 입력 및 출력 기능들의 집합이 있습니다 각각에 타입과 크기가 있죠 런타임에서 여러분은 Core ML API를 써서 모델의 인터페이스를 따르는 입력을 제공하고 추론을 돌린 후에 출력을 얻습니다 이미지와 MultiArray에 좀 더 상세하게 초점을 맞춰보겠습니다 이미지의 경우 Core ML은 8비트 그레이 스케일과 구성 요소당 8비트가 있는 32비트 컬러 이미지를 지원합니다 그리고 다차원 배열의 경우 Core ML은 Int32 Double, Float32를 스칼라 타입으로 지원합니다 여러분의 앱이 이 타입들로 이미 작동되고 있다면 그것들을 모델에 연결시키는 일만 중요합니다 하지만 때론 여러분의 타입이 다를 수도 있습니다 예를 하나 보여드리죠 저는 제 이미지 처리와 스타일 앱에 새 필터를 추가하고 싶습니다 이 필터는 이미지를 강렬하게 해줍니다 단일 채널 이미지 위에 작동하는 방식으로요 제 앱에는 GPU에 사전 및 사후 처리 연산 기능이 있고 그건 이 단일 채널을 Float16 정확도로 나타냅니다 이를 위해 저는 coremltools를 써서 이미지 강화 토치 모델을 여기에 보이듯 Core ML 형식으로 전환했습니다 그 모델은 Float16 정확도 계산을 사용하도록 구성됐습니다 또한 그건 이미지 입력을 갖고 이미지 출력을 생성합니다 제가 받은 모델은 이런 모습입니다 주의할 점은 Core ML에서 8비트인 그레이 스케일 이미지가 필요하단 겁니다 이걸 돌아가게 하기 위해 저는 코드를 작성해서 제 입력을 OneComponent16Half에서 OneComponent8으로 다운캐스트한 다음 그 출력을 OneComponent8에서 OneComponent 16Half로 업캐스트해야 했습니다 그런데 이게 다가 아닙니다 모델이 Float16 정확도에서 계산을 수행하도록 구성되었기에 어느 시점에 Core ML은 이 8비트 입력을 Float16으로 전환해야 합니다 그건 전환을 효율적으로 하지만 앱이 돌아가는 상태에서 Instruments 흔적을 살펴보면 이게 보입니다 Core ML이 수행하고 있는 데이터 단계들에 주목하세요 Neural Engine 계산 이전과 이후에요 Data 레인을 확대해보면 그건 Core ML이 데이터를 복사해서 Neural Engine에서의 계산을 준비시키고 있는 게 보입니다 이 경우에 그건 Float16으로의 전환을 뜻합니다 이건 안타깝게 느껴집니다 원본 데이터가 이미 Float16이었으니까요 이상적으로 이 데이터 변환은 앱 내와 Core ML 내에서 피할 수 있습니다 모델이 Float16 입력 및 출력과 직접 작동할 수 있게 해서요 iOS 16과 macOS Ventura부터 Core ML에는 하나의 OneComponent16Half 그레이 스케일 이미지와 Float16 MultiArray에 대한 네이티브 지원이 있습니다 여러분은 Float16 입력 및 출력을 수용하는 모델을 만들 수 있습니다 이미지의 새 색상 레이아웃이나 MultiArray의 새 데이터 타입을 명시하는 식으로요 그와 동시에 coremltools의 전환 기법을 적용하면서요 이 경우에 저는 제 모델의 입력 및 출력이 그레이 스케일 Float16 이미지가 되도록 명시합니다 Float16 지원은 iOS 16과 macOS Ventura에서부터 이용이 가능하므로 이 기능들은 최소 배치 목표가 iOS 16으로 명시됐을 때만 이용 가능합니다 모델의 재전환된 버전은 이런 모습입니다 입력 및 출력이 Grayscale16Half로 표시됐다는 점에 주의하세요 이 Float16 지원으로 제 앱은 Float16 이미지를 Core ML로 직접 넣어줄 수 있는데 이는 앱의 입력을 다운캐스팅할 필요와 출력을 업캐스팅할 필요를 없애줍니다 그건 코드에서 이런 모습입니다 제 입력 데이터가 OneComponent16Half CVPixelBuffer 형식이므로 저는 픽셀 버퍼를 Core ML로 직접 보낼 수 있습니다 이는 어떤 데이터 복사나 변환도 발생시키지 않습니다 그런 다음 OneComponent16Half CVPixelBuffer 출력으로 얻습니다 그것의 결과는 더 단순한 코드와 데이터 변환이 필요하지 않은 겁니다 여러분이 할 수 있는 또 하나의 멋진 일이 있는데 Core ML에 출력에 대한 사전 할당 버퍼를 채워달라고 하는 겁니다, Core ML이 예측별로 새 버퍼를 할당하게 하는 대신에 말이죠 그렇게 하는 방법은 출력 지원 버퍼를 할당하고 그걸 예측 옵션들 위에 정하는 겁니다 제 앱의 경우 outputBacking Buffer란 함수를 제가 작성했는데 그건 OneComponent16Half CVPixelBuffer를 돌려줍니다 그런 다음 전 이걸 예측 옵션들 위에서 정하고 마지막으로 그 예측 옵션들과 함께 제 모델에 예측 기법을 호출하는 겁니다 출력 지원을 명시해서 여러분은 모델 출력의 버퍼 관리에 대한 통제력을 늘릴 수 있습니다 그 변화가 이루어졌으니 정리하자면 이건 Instruments 흔적에서 나타난 겁니다 8비트 입력 및 출력이 있던 모델의 원래 버전을 썼을 때요 그리고 이건 Instruments 흔적의 최종 모습입니다 IOSurface의 지원을 받는 Float16 버퍼를 모델의 새로운 Float16 버전에 제공하기 위해 코드를 수정한 후죠 이전에 Data 레인에서 나타났던 데이터 변환은 이제 사라졌습니다 Core ML이 그걸 더 이상 수행할 필요가 없으니까요 요약하자면 Core ML에는 이제 Float16 데이터에 대한 양끝 네이티브 지원이 있습니다 이는 여러분이 Float16 입력을 Core ML에 제공하고 Core ML에서 Float16 출력을 돌려받을 수 있다는 뜻이죠 새로운 출력 지원 API를 써서 Core ML이 여러분의 사전 할당 출력 버퍼를 채우게 할 수 있어요 새로운 걸 만드는 대신에요 그리고 마지막으로, 가능할 때마다 IOSurface의 지원을 받는 버퍼 사용을 추천합니다 그건 Core ML이 데이터 사본 없이 데이터를 다양한 계산 단위 사이에서 이동시킬 수 있게 해줍니다 통합 메모리를 활용하는 방식으로요 다음으로는 Core ML에 추가되는 몇 가지 기능을 빠르게 설명하겠습니다 첫째는 가중치 압축입니다 모델의 가중치 압축은 여러분이 더 작은 모델을 갖고 있을 때도 유사한 정확도에 도달하게 해줄 수 있습니다 iOS 12에선 Core ML에 훈련 후 가중치 압축이 도입됐는데 그건 Core ML 신경망 모델의 크기를 줄일 수 있게 해줍니다 우린 이제 16비트와 8비트 지원을 ML Program 모델 타입으로 확대하고 있고, 덧붙여서 희박한 표현에서 가중치를 저장하는 새로운 옵션도 도입합니다 coremltools 유틸리티로 여러분은 이제 ML Program 모델에 대한 가중치를 양자화하고 팔레트화하고 희박하게 할 수 있습니다 다음은 새 계산 단위 옵션입니다 Core ML은 주어진 계산 단위 선호에 대한 추론 지연 시간을 늘 최소화하는 걸 목표로 합니다 앱은 이 선호를 명시할 수 있는데 방법은 MLModelConfiguration computeUnits 속성을 정하는 거죠 세 개의 기존 계산 단위 옵션 외에도 이제 cpuAndNeuralEngine이란 새 옵션이 생겼습니다 이는 Core ML에 GPU로 계산을 보내지 말라고 하는데 이게 도움이 되는 때는 앱이 GPU를 이용해서 다른 계산을 할 때와 그에 따라 Core ML이 그 초점을 CPU와 Neural Engine으로 제한하는 걸 선호할 때입니다 다음으로 우린 Core ML 모델 인스턴스를 초기화하는 새 방법을 추가합니다 그건 모델 직렬화의 측면에서 유연성을 더해줍니다 그건 여러분이 맞춤형 암호화 계획으로 모델 데이터를 암호화할 수 있게 해주고 로딩 직전에 암호 해독을 하게 해줍니다 이 새 API들로 여러분은 메모리 내 Core ML 모델 사양을 컴파일하고 로딩할 수 있습니다 컴파일된 모델이 디스크에 있어야 할 필요 없이요 마지막 업데이트는 Swift 패키지와 그것들이 Core ML과 작동하는 방식과 관련이 있습니다 패키지는 재사용 가능한 코드를 묶고 분배하기에 참 좋은 방법입니다 Xcode 14로 여러분은 Swift 패키지에 Core ML 모델을 포함시킬 수 있고 누군가 여러분의 패키지를 불러오면 여러분의 모델이 작동합니다 Xcode는 Core ML 모델을 자동으로 컴파일하고 묶고 여러분이 익숙하게 작업해온 것과 동일한 코드 생성 인터페이스를 만들어줍니다 우린 이 변화에 대한 기대가 큽니다 그건 Swift 환경에서 여러분의 모델을 분배하는 걸 훨씬 쉽게 해줄 테니까요 이번 세션은 끝났습니다 Xcode 14의 Core ML 성능 보고서와 Instrument는 여러분의 앱에서 ML로 작동하는 기능들의 성능을 분석하고 최적화하는 걸 돕습니다 새로운 Float16 지원과 출력 지원 API들은 데이터가 Core ML에 들어가고 거기에서 나오는 흐름을 더 잘 통제하게 해줍니다 가중치 압축에 대한 확대 지원은 여러분 모델의 크기를 최소화하는 걸 도울 수 있습니다 그리고 메모리 내 모델과 Swift 패키지 지원으로 여러분은 Core ML 모델을 나타내고 합치고 나누는 것과 관련해서 훨씬 더 많은 옵션을 갖게 됩니다 저는 Core ML 팀의 Ben이었고 WWDC의 남은 시간도 즐기세요 ♪
-