-
빠르게 링크: 빌드 및 실행 시간 개선
앱의 빌드 및 런타임 링크 연결 성능을 향상하는 방법을 확인하세요. 링크 연결, 옵션, 그리고 앱의 링크 성능을 향상하는 최신 업데이트에 대해 자세히 알아볼 수 있는 뒷이야기를 소개합니다.
리소스
관련 비디오
WWDC23
WWDC22
-
비디오 검색…
♪ ♪
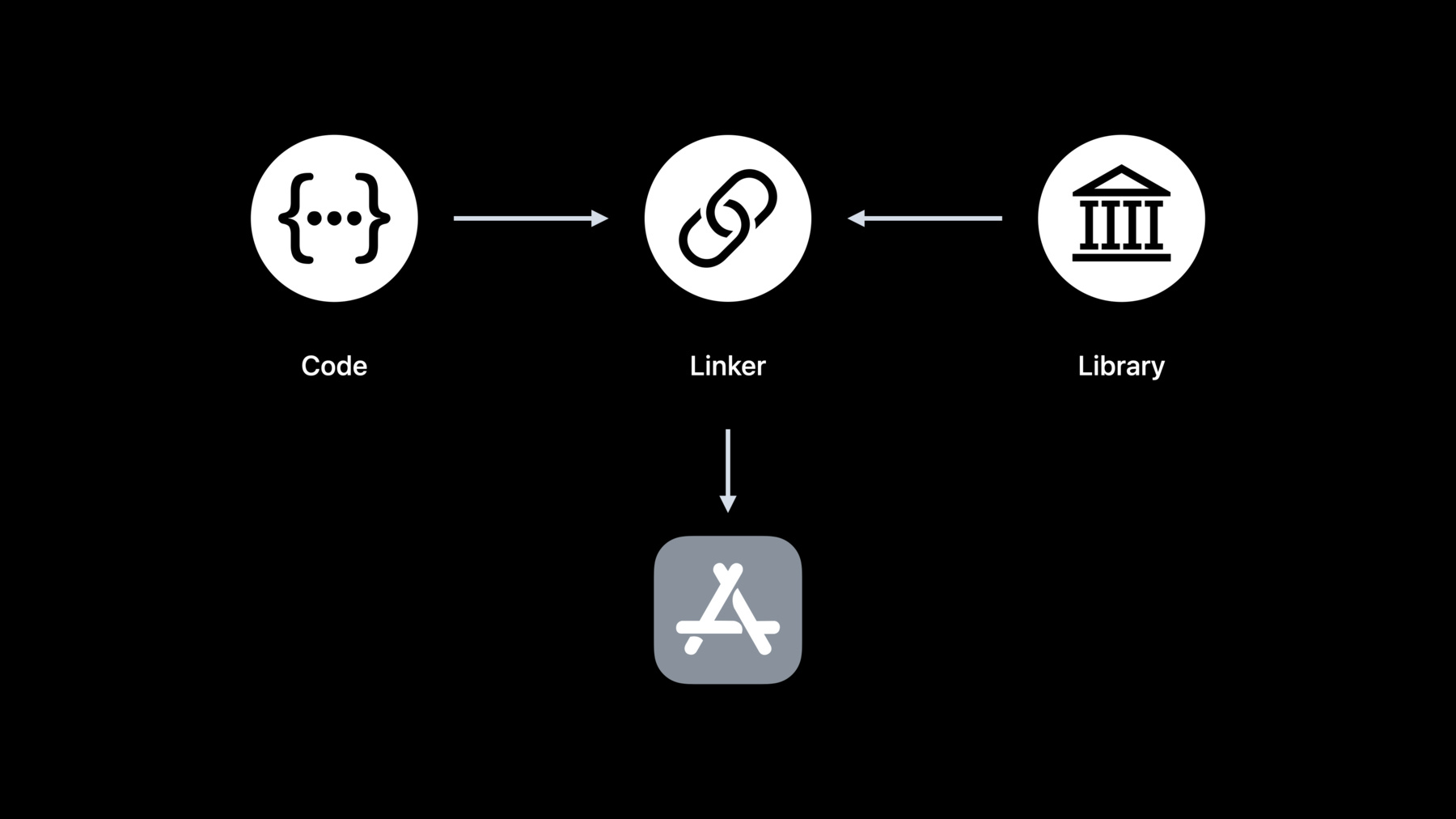
안녕하세요, Apple의 Linker 팀 수석 엔지니어 Nick Kledzik입니다 오늘은 빠르게 링크하는 법에 대해 말씀드리겠습니다 Apple이 링크 개선을 위해 무엇을 했는지 링크 과정에 어떤 일이 발생하는지 이해하는 데에 도움을 드리고 앱의 링크 성능을 향상으로 이어지도록 해보겠습니다 그렇다면 링킹이란 무엇일까요 여러분이 코드를 작성했는데 다른 사람의 코드도 사용했습니다 라이브러리나 프레임워크 형태로요 여러분의 코드가 이런 라이브러리 를 사용하려면 링커가 필요합니다 링킹에는 두가지 유형이 있습니다 앱을 빌드하는데 발생하는 '정적 링킹'이 있습니다 정적 링킹은 앱을 빌드하는 데 걸리는 시간과 앱의 최종 크기에 영향을 줄 수 있습니다 그리고 '동적 링킹'이 있습니다 앱이 실행될 때 발생하죠 앱이 작동할 때까지 고객의 대기 시간에 영향을 줄 수 있습니다 이번 세션에서는 정적 및 동적 링킹 모두 다루겠습니다 먼저 몇 가지 예와 함께 정적 링킹이 무엇인지 정의하고 어디서 왔는지 말씀드리겠습니다 그 다음 Apple의 정적 링커인 Id64의 신기능을 공개하겠습니다 정적 링킹에 대한 배경지식과 함께 그 모범 사례에 대해 자세히 설명드리겠습니다 강연의 후반부에서는 동적 링킹에 다룰 겁니다 동적 링킹이 무엇인지 그리고 어디서 왔는지 동적 링킹 과정에서 어떤 일이 발생하는지 보여드리겠습니다 그 다음 올해 dyld의 새로운 기능을 공개하겠습니다 동적 링크 시간 성능 개선을 위해 무엇을 할 수 있는지도 이야기하겠습니다 마지막으로 이면을 엿볼 수 있는 두 가지 새로운 도구를 이야기하며 마무리하겠습니다 바이너리에 무엇이 있고 동적 링킹 과정에 어떤 일이 일어나는지 볼 수 있습니다 정적 링킹 이해를 위해 모든 것의 시초로 돌아가봅시다 초기에는 프로그램들이 간단했고 소스 파일도 하나뿐이었습니다 빌드도 쉬웠죠 단 하나의 소스 파일에서 컴파일러를 실행하면 실행 가능한 프로그램을 생성합니다 하지만 모든 소스 코드가 있는 하나의 파일은 확장되지 않습니다 여러 소스 파일을 가지면 어떻게 빌드할까요 하나의 거대 텍스트 파일을 편집 하기 싫어서 그러는 건 아닙니다 정말 절약이 되는 것은 빌드 할 때마다 모든 함수를 다시 컴파일하지 않아도 되는 것이죠 그래서 한 일이 컴퍼일러를 두 부분으로 나누는 것이었습니다 첫 번째 부분은 소스 코드를 새로운 중간 파일 '재배치 가능한 객체 파일'로 컴파일하고 두 번째 부분은 재배치 가능한 .o 파일을 읽고 실행 가능한 프로그램을 생성합니다 그리고 이 두 번째 부분 정적 링커를 'ld'라고 부릅니다 이제 정적 링킹이 어디에서 비롯하였는지 알겠죠 소프트웨어가 발전하면서 사람들은 곧 .o 파일들을 주고받게 됩니다 번거로워졌죠 누군가는 .o 파일들을 하나의 라이브러리로 묶으면 좋지 않을까 생각하게 됩니다 당시에 파일들을 묶는 표준 방법은 아카이브 도구 'ar'을 사용하는 것이었습니다 백업 및 배포에 사용되었죠 따라서 워크플로우가 다음과 같아졌습니다 여러개의 .o 파일을 하나의 아카이브로 'ar'화 하고 아카이브 파일에서 직접적으로 .o 파일들을 읽도록 링커가 향상되었습니다 이것은 공통 코드를 공유하는데 아주 큰 개선 사항이었죠 당시에는 단지 라이브러리 또는 아카이브라고 불렸습니다 오늘날에는 정적 라이브러리라고 부르죠 하지만 최종 프로그램은 무거워졌습니다 라이브러리의 수천 개의 함수가 프로그램에 복사되었기 때문이죠 단지 몇 개의 함수만 사용된다고 하더라도요 그래서 영리한 최적화가 추가됐죠 링커가 정적 라이브러리의 모든 .o 파일을 사용하는 대신 정의되지 않은 심볼 문제가 해결되는 경우의 .o파일만 정적 라이브러리에서 가져옵니다 이것은 누군가가 모든 C 표준 라이브러리 함수를 포함하는 거대한 하나의 libc.a 정적 라이브러리를 구축할 수 있음을 의미했죠 모든 프로그램이 하나의 libc.a에 연결할 수 있지만 각 프로그램은 실제로 필요로 하는 libc의 일부만 가져옵니다 오늘날에도 이 모델은 존재합니다 그러나 이런 정적 라이브러리의 선택적 로딩은 분명하지 않고 많은 프로그래머들을 곤경에 빠뜨립니다 정적 라이브러리의 선택적 로딩을 좀 더 명확히 하기 위한 간단한 시나리오를 설명드리죠 main.c에는 'foo' 함수를 호출하는 'main' 함수가 있습니다 foo.c에는 bar를 호출하는 foo가 있습니다 그리고 bar.c에는 bar가 구현되어 있고 unused라는 또 다른 함수도 구현되어 있습니다 마지막으로 baz.c엔 undef 함수를 호출하는 baz 함수가 있습니다 이제 이들 각각을 자체 .o 파일로 컴파일합니다 보시다시피 foo, bar, undef에는 회색 박스가 없습니다 정의되지 않았기 때문이죠 심볼의 사용이지 정의가 아닙니다 bar.o와 baz.o를 정적 라이브러리 하나로 합친다고 해봅시다 그 다음 두개의 .o 파일과 이 정적 라이브러리를 링크합니다 실제로 일어나는 일을 단계 별로 살펴보죠 먼저 링커는 명령어 라인 순서대로 파일을 읽어나갑니다 가장 먼저 찾은 것은 main.o이죠 main.o를 로드하고 'main'에 대한 정의를 찾습니다 심볼 테이블에 보이는 main을요 그렇지만 main 안에 정의되지 않은 'foo'가 있다는 것도 찾습니다 그 다음 링커는 명령어 라인의 다음 파일 foo.o를 파싱합니다 이 파일은 'foo'에 대한 정의를 추가합니다 즉, 더 이상 정의되지 않은 foo가 아닌 것이죠 하지만 foo.o의 로드는 정의되지 않은 새 심볼 'bar' 또한 추가합니다 명령어 라인의 모든 .o 파일이 로드되었으므로 링커는 정의되지 않은 심볼이 남아 있는지 확인합니다 이 경우 아직 'bar'이 정의되지 않았기 때문에 링커는 명령어 라인의 라이브러리들을 살펴보면서 정의되지 않은 'bar' 심볼을 충족하는 라이브러리를 찾습니다 링커가 정적 라이브러리 bar.o에서 'bar' 심볼이 정의되는 것을 찾죠 따라서 링커는 아카이브로부터 bar.o를 로드합니다 이 시점에서는 더 이상 정의되지 않은 심볼이 없습니다 따라서 라이브러리 수색을 중단합니다 링커는 다음 단계로 이동해 프로그램에 포함 될 모든 함수와 데이터에 주소를 할당합니다 그런 다음 모든 함수와 데이터를 출력 파일에 복사합니다 그럼 출력 프로그램이 완성되죠 baz.o는 정적 라이브러리에 있지만 프로그램에 로드되지 않았습니다 링커가 정적 라이브러리에서 선택적으로 로드한 방식 때문에 로드되지 않았죠 이 방식은 분명하진 않지만 정적 라이브러리의 핵심적 측면입니다 여러분은 이제 정적 링킹 및 정적 라이브러리의 기본을 이해했습니다 그럼 Apple의 정적 링커에 대한 최신 개선 사항인 ld64에 대해서 알아보겠습니다 대중적 요구에 맞춰 올해는 ld64의 최적화에 시간을 들였습니다 그래서 올해의 링커는… 많은 프로젝트에서 두 배 빠릅니다 이것을 어떻게 해냈을까요 개발 시스템에서 코어를 더 잘 활용했습니다 링커 작업을 병렬로 수행하도록 여러개의 코어를 사용할 수 있는 여러 영역을 찾았습니다 여기에는 입력 파일의 내용을 출력 파일로 복사하고 LINKEDIT의 부분들을 병렬로 구축하고 UUID 계산을 변경하고 코드 서명 해시를 병렬로 수행하는 것이 포함됩니다 다음으로 여러 알고리즘을 개선했습니다 각 심볼의 문자열 슬라이스를 나타내는데 C++의 string_view 객체를 사용하게 되면 exports-trie builder가 굉장히 잘 작동하는 것을 볼 수 있습니다 또한 바이너리의 UUID를 계산할 때 최신 암호화 라이브러리를 사용해 하드웨어의 가속을 활용했습니다 다른 알고리즘 개선도 있었죠
링커의 성능 개선 작업 동안 일부 앱에서는 링크 시간에 영향을 미치는 구성 문제를 발견했습니다 다음으로는 여러분의 프로젝트에서 여러분들이 링크 시간 개선을 위해 할 수 있는 것들을 이야기하겠습니다 다섯 가지 주제를 다룰 건데요 첫째는 정적 라이브러리 사용 여부입니다 다음은 잘 알려지지 않은 링크 시간에 큰 영향을 주는 세 가지 옵션과 마지막으로 놀랄 수 있는 몇 가지 정적 링크의 속성을 다루겠습니다 첫 번째 주제는 정적 라이브러리에 빌드되는 소스 파일에 열심히 작업해서 빌드 시간이 느려지는 경우입니다 파일이 컴파일 되고 나면 목차를 포함한 정적 라이브러리 전체를 다시 빌드해야 하기 때문에 그렇습니다 단지 추가적인 I/O가 많은 겁니다 안정적인 코드에는 정적 라이브러리가 가장 적합합니다 코드가 활발히 변경되지 않는 경우에요 빌드 시간을 줄이기 위해서는 현재 개발 중인 코드를 정적 라이브러리 밖으로 이동하는 것을 고려해야 합니다 조금 전에 우리는 아카이브에서 선택적 로딩을 봤습니다 그러나 선택적 로딩의 단점은 링커가 느려진다는 겁니다 그 이유는 빌드를 재현 가능하도록 하면서 전통적인 정적 라이브러리의 의미를 따르기 위해서는 링커가 라이브러리를 고정된 직렬 순서로 처리해야 하기 때문입니다 그 말은 ld64의 병렬화 이점을 정적 라이브러리와 함께 사용할 수 없다는 것이죠 그렇지만 이런 기록 동작이 별로 필요하지 않은 경우라면 링커 옵션을 사용해 빌드 속도를 높일 수 있습니다 해당 링커 옵션을 'all load'라고 합니다 모든 정적 라이브러리의 모든 .o 파일을 로드하도록 링커에 지시하죠 이는 앱이 선택적 로딩을 하지만 결국 모든 정적 라이브러리로부터 대부분의 콘텐츠를 로드하는 경우라면 유용할 수 있습니다 -all_load의 사용은 링커가 모든 정적 라이브러리와 해당 콘텐츠를 병렬로 파싱할 수 있도록 합니다 하지만 앱이 영리한 트릭을 사용해 동일한 심볼을 구현하는 여러 정적 라이브러리가 있어서 명령어 라인의 정적 라이브러리 순서에 의존해 어떤 구현을 사용할지 정하는 방식이라면 이 옵션은 적합하지 않습니다 왜냐하면 링커는 모든 구현을 로드하기 때문에 일반 정적 링킹 모드에서 찾을 수 있는 심볼의 의미를 가져오리란 법이 없기 때문입니다 -all_load의 또 다른 단점은 프로그램이 무거워 질 수 있다는 겁니다 'unused' 코드가 계속 추가되기 때문이죠 이를 보완하기 위해 -dead_strip 링커 옵션을 사용할 수 있습니다 이 옵션으로 연결 불가한 코드와 데이터를 링커가 제거합니다 데드 스트리핑 알고리즘은 빠르고 출력 파일의 사이즈를 줄임으로써 자체적으로 크기 절약을 하지만 -all_load와 -dead_strip 모두를 사용하려 한다면 이들 옵션의 유무에 따른 링커 시간을 측정해서 여러분의 경우에 유리한 선택인지 확인해야 합니다 다음 링커 옵션은 -no_exported_symbols입니다 약간의 배경 설명을 드리면 링커가 생성하는 LINKEDIT 세그먼트의 한부분은 하나의 exports-trie로 접두사 트리이며 내보낸 모든 심볼 이름, 주소 및 플래그를 인코딩합니다 모든 dylib에는 내보낸 심볼이 있어야 하는 반면 메인 앱 바이너리는 일반적으로 내보낸 심볼이 필요하지 않습니다 즉, 일반적으로 메인 실행 파일에서는 심볼을 조회하지 않습니다 그런 경우 -no_exported_symbols를 사용하여 앱 대상에 대해 LINKEDIT에서 trie 데이터 구조 생성을 건너뛰도록 할 수 있습니다 그럼 링크 시간이 향상되죠 그러나 앱이 메인 실행 파일로 다시 연결되는 플러그인을 로드하거나 xctest 번들 실행을 위해 호스트 환경으로 앱과 xctest를 사용하면 앱에 모든 내보내기가 있어야 합니다 즉, 해당 구성에서는 -no_exported_symbols를 사용할 수 없다는 것이죠 사이즈가 큰 경우엔 exports trie의 억제가 합리적입니다 화면에 표시된 dyld_info 명령을 실행하여 내보낸 심볼의 수를 계산할 수 있습니다 우리가 본 한 대형 앱에는 약 백만 개의 심볼이 내보내졌습니다 그리고 링커가 해당 심볼 수에 대한 exports trie를 빌드하는데 2~3초가 걸렸습니다 -no_exported_symbols를 추가하여 해당 앱의 링크 시간이 2~3초 단축됐습니다 dyld_info 도구에 대해서는 강연 뒷 부분에 자세히 설명하겠습니다 다음 옵션은 -no_deduplicate입니다 몇 년 전 우리는 링커에 새로운 패스를 추가했습니다 명령은 같지만 이름이 다른 함수를 병합하기 위해서요 C++의 템플릿 확장으로 그런 함수들을 많이 얻게 됐습니다 그러나 이 알고리즘은 비쌉니다 링커는 모든 함수의 명령을 반복적으로 해시해야 하죠 중복을 찾도록요 이런 비용 문제 때문에 링커가 약한-정의 심볼만 살펴보도록 알고리즘을 제한시켰습니다 템플릿 확장으로 C++ 컴파일러가 내보내는 인라인 되지 않은 것들이 제한됐죠 de-dup 중복 제거는 사이즈 최적화이며 디버그 빌드는 사이즈가 아닌 속도 빠른 빌드에 관한 겁니다 기본적으로 Xcode는 디버그 구성을 위해 링커에 -no_deduplicate를 전달해 de-dup 최적화를 비활성화합니다 clang 또한 no-dedup 옵션을 링커에 전달합니다 clang 링크 라인을 -O0으로 실행한다면요 요약하자면 C++를 사용하고 사용자 정의 빌드가 있는 경우 즉, Xcode에서 비표준 구성을 사용하거나 다른 빌드 시스템을 사용하는 경우 링크 시간 개선을 위해서 여러분의 디버그 빌드가 -no_deduplicate을 추가하도록 해야합니다 제가 말씀드린 옵션들은 ld에 대한 실제 명령어 라인 인자들입니다 Xcode를 사용할 때 제품의 빌드 설정을 변경해야 합니다 빌드 설정에서 '기타 링커 플래그'를 찾습니다
다음은 -all_load에 대한 설정입니다 'Dead Code Stripping' 옵션도 여기에 있죠 -no_exported_symbols도 있고 -no_deduplicate도 있습니다
이제 정적 라이브러리를 사용할 때 경험할 수 있는 몇 가지 놀라운 내용들에 관해 이야기해보겠습니다 첫째, 정적 라이브러리에 소스 코드가 빌드되고 앱이 이 라이브러리에 연결되지만 해당 코드는 최종 앱에 포함되지 않습니다 예를 들어 어떤 함수에 'attribute used'를 추가했다거나 Objective-C 카테고리가 있는 경우 링커가 선택적 로딩을 수행하기 때문에 정적 라이브러리에 있는 해당 객체 파일이 링크 과정 중에 필요한 일부 심볼 또한 정의하지 않는다면 해당 객체 파일은 링커가 로드하지 않게 됩니다 정적 라이브러리와 데드 스트리핑 간의 상호작용도 흥미롭습니다 데드 스트리핑은 많은 정적 라이브러리 문제를 숨길 수 있죠 일반적으로 심볼의 누락이나 중복되는 심볼은 링커의 오류를 유발합니다 하지만 데드 스트리핑은 링커가 메인에서 시작해서 모든 코드와 데이터에 걸쳐 도달 가능성 패스를 실행하도록 하여 심볼의 누락이 연결할 수 없는 코드에서 온 것으로 판명되면 링커가 심볼 누락 오류를 억제하도록 만듭니다 유사하게 정적 라이브러리에 중복되는 심볼이 있는 경우 링커는 첫번째 것을 선택하고 오류를 내뱉지 않습니다 정적 라이브러리를 사용할 때 마지막으로 아주 놀라운 점은 하나의 정적 라이브러리가 여러 프레임워크에 통합되는 경우입니다 각각의 프레임워크는 개별적으로는 잘 실행됩니다만 어느 시점에서 일부 앱은 두 가지 프레임워크를 모두 사용하게 되고 이는 이상한 런타임 문제를 발생시킵니다 바로 여러 개의 정의로 인해서요 가장 흔한 경우는 Objective-C 런타임 경고로 동일한 클래스 명의 여러 인스턴스에 대한 경고입니다 종합적으로 정적 라이브러리는 강력합니다 그렇지만 함정을 피하기 위해서는 이해가 필요하죠 이것으로 정적 링킹을 마무리하겠습니다 이제 동적 링킹으로 넘어가죠 정적 라이브러리와 정적 링킹에 대한 다이어그램을 살펴봅시다 시간이 지나면서 이 다이어그램이 확장될 것을 생각해보세요 점점 더 많은 소스 코드가 생기겠죠 사용할 수 있는 라이브러리가 점점 더 많아질 수록 최종 프로그램의 크기가 커지는 것은 당연합니다 시간에 따라 해당 프로그램 빌드에 드는 정적 링크 시간도 증가하죠
이런 라이브러리가 만들어지는 과정을 보겠습니다 이 순서를 바꾼다면 어떨까요 'ar'을 'ld'로 바꾸고 출력 라이브러리는 이제 실행 가능한 바이너리가 되는 것이죠 이것이 90년대 동적 라이브러리의 시작이었습니다 약칭으로 동적 라이브러리를 'dylibs'라고 합니다 다른 플랫폼에서는 DSO 또는 DLL이라고도 하죠 여기에서 정확히 어떤 일이 일어나는 걸까요 그리고 그것이 확장성에 어떤 도움이 될까요
핵심은 정적 링커가 동적 라이브러리와의 링킹을 다르게 취급한다는 점입니다 라이브러리에서 최종 프로그램으로 코드를 복사하는 것 대신 링커가 일종의 약속을 기록합니다 동적 라이브러리에서 사용되는 심볼 및 런타임 시 라이브러리의 경로를 기록하는 것이죠 이것이 어떻게 장점일 수 있을까요 프로그램 파일 사이즈가 여러분의 통제 하에 있게 됩니다 단지 여러분의 코드와 런타임에 필요한 동적 라이브러리 목록만 포함되죠 라이브러리 코드의 복사본을 더 이상 프로그램에 받지 않게 됩니다 프로그램의 정적 링크 시간은 이제 코드 크기에 비례하고 링크하는 dylib 수와는 무관합니다 또한 가상 메모리 시스템이 이제 빛날 수 있습니다 여러 프로세스에서 동일한 동적 라이브러리가 사용되는 경우 가상 메모리 시스템은 그 dylib를 사용하는 모든 프로세스에서 해당 dylib에 대해 동일한 물리적 RAM 페이지를 재사용합니다 동적 라이브러리의 시초와 이것이 해결한 문제를 보여드렸습니다 그렇다면 이 '이점'에 대한 '비용'은 무엇일까요 첫 번째, 동적 라이브러리 사용의 이점은 빌드 시간 단축이었습니다 그렇지만 그 비용은 앱 시작 속도의 둔화입니다 앱 시작 시 프로그램 파일 하나만 로드하는 것이 아니기 때문이죠 이제 모든 dylib들이 로드되고 함께 연결돼야 합니다 빌드 시간에서 시작 시간으로 링킹 비용의 일부를 연기시킨 것이나 다름 없죠 두 번째로 동적 라이브러리 기반 프로그램은 더티 페이지가 더 많습니다 정적 라이브러리의 경우 모든 정적 라이브러리의 모든 전역들을 링커가 메인 실행 파일의 동일한 DATA 페이지에 다 같이 배치시킵니다 그러나 dylib를 사용하면 DATA 페이지가 각 라이브러리에 있죠 마지막으로 동적 링킹의 또 다른 비용은 새로운 것이 필요하다는 겁니다 바로 동적 링커요 빌드 시에 실행 파일에 기록된다던 약속을 기억하시나요 이제 라이브러리를 로드하기 위해 이 약속을 이행할 무언가가 런타임에 필요합니다 이것이 바로 dyld 동적 링커의 용도이죠 동적 링킹이 런타임에서 어떻게 작동하는지 살펴봅시다 실행 가능한 바이너리는 세그먼트로 분할됩니다 일반적으로 최소한 TEXT, DATA 및 LINKEDIT으로 분할되죠 세그먼트는 항상 OS 페이지 사이즈의 배수입니다 각 세그먼트는 다른 권한을 가지죠 예를 들어 TEXT 세그먼트는 '실행' 권한을 가집니다 CPU가 페이지의 바이트를 기계 명령어로 처리 가능함을 의미하죠 런타임 시 dyld는 여기 보이는 것 처럼 각 세그먼트의 권한을 받아 실행 파일들을 메모리에 mmap() 해야 합니다 세그먼트들은 페이지 사이즈이고 페이지 정렬되기 때문에 가상 메모리 시스템이 프로그램이나 dylib 파일을 VM 범위의 백업 저장소로 설정하는 것이 간단합니다 즉, 해당 페이지에 메모리 액세스가 있을 때까지 RAM에 아무것도 로드되지 않으며 이로 인해 페이지 폴트가 발생하고 이는 VM 시스템이 파일의 적절한 하위 범위를 읽고 그 콘텐츠로 필요한 RAM 페이지를 채우도록 만듭니다 하지만 매핑만으로는 충분하지 않습니다 어떻게든 프로그램은 '연결'되거나 dylib에 바인딩되어야 합니다 이를 위한 '수정'라는 개념이 있죠
다이어그램에서 프로그램에 포인터들이 설정된 것을 볼 수 있는데요 프로그램이 사용하는 dylib 부분들을 향하고 있습니다 수정 사항들이 무엇인지 알아보죠 여기 우리의 친구 mach-o 파일이 있습니다 TEXT는 불변입니다 또한 코드 서명을 기반으로 하는 시스템 안에 있어야 하죠 malloc()을 호출하는 함수가 하나 있다면 어떻게 될까요 어떻게 작동할 수 있을까요 _malloc의 상대주소는 프로그램이 빌드될 때 알 수 없습니다 일어나는 일은 malloc이 dylib에 있는 것을 보고 정적 링커가 호출 사이트를 변환하는 것이죠 호출 사이트는 스텁에 대한 호출이 됩니다 동일한 TEXT 세그먼트의 링커에 의해서요 따라서 빌드 시에 상대 주소가 알려지고 이는 BL 명령어가 올바르게 형성될 수 있음을 의미합니다 이것이 도움이 되는 점은 스텁이 DATA로부터 포인터를 로드하고 해당 위치로 점프한다는 점입니다 런타임에서는 TEXT에 대한 변경이 필요 없습니다 dyld에 의해 DATA만 변경되죠 사실 dyld를 이해하는데 중요한 것은 dyld에 의한 모든 수정이 단지 DATA에 대한 dyld의 포인터 설정 뿐이라는 겁니다
그럼 dyld가 수행하는 수정 사항에 대해 더 자세히 알아보죠 LINKEDIT 어딘가에 dyld가 수정 작업에 써야하는 정보가 있습니다 수정에는 두 가지 유형이 있습니다 첫 번째 유형은 리베이스라고 하며 dylib 또는 app 자체 내에서 가리키는 포인터를 갖는 경우이죠 ASLR이라는 보안기능이 있는데요 dyld가 임의의 주소에서 dylib를 로드하도록 만듭니다 따라서 내부 포인터는 빌드 시에 설정할 수 없습니다 이런 포인터들은 시작 시에 dyld가 조정하거나 '리베이스'해야 하죠 디스크에서 이런 포인터들은 대상 주소를 포함합니다 dylib가 주소 0에서 로드되는 경우에요 그럼 LINKEDIT가 기록해야 하는 건 각 리베이스의 위치가 전부입니다 그러면 dyld는 dylib의 실제 로드 주소를 각 리베이스 위치에 추가해 올바르게 수정할 수 있습니다
두 번째 수정 유형은 바인드입니다 바인드는 상징에 대한 참조로 대상이 숫자가 아닌 상징 명입니다 'malloc' 함수에 대한 포인터를 예로 들 수 있는데요 문자열 '_malloc'은 실제로 LINKEDIT에 저장되며 dyld는 해당 문자열을 사용해 libSystem.dylib의 exports trie에서 malloc의 실제 주소를 조회합니다 그 다음 dyld는 해당 값을 바인드가 지정한 위치에 저장합니다 올해는 수정을 인코딩하는 새로운 방법 'chained fixups' 연결 수정을 발표합니다
첫 번째 장점은 LINKEDIT이 더 작아진다는 겁니다 LINKEDIT이 작아질 수 있는 이유는 모든 수정 위치를 저장하는 대신 새 형식은 각 DATA 페이지의 첫 번째 수정 위치와 가져온 심볼 목록만을 저장하기 때문입니다 그리고 나머지 정보는 DATA 세그먼트 자체에 인코딩됩니다 최종적으로 수정이 고정될 위치에요 이 새로운 형식이 '연결 수정'이란 이름을 얻게 된 것은 수정 위치가 서로 연결되어 있다는 점 때문입니다 LINKEDIT는 첫 번째 수정이 있었던 위치만 알려주고 DATA의 64비트 포인터 위치에 있는 일부 비트들은 다음 수정 위치에 대한 오프셋을 포함합니다 그 안에 수정이 바인드인지 리베이스인지 알려주는 비트도 들어있죠 바인드인 경우 나머지 비트는 심볼의 인덱스가 됩니다 리베이스인 경우 나머지 비트는 이미지 내 대상에 대한 오프셋이 됩니다 연결 수정에 대한 런타임 지원은 iOS 13.4 이상부터 존재합니다 배포 대상이 iOS 13.4 이상이라면 이 새로운 형식을 오늘 바로 사용할 수 있다는 것이죠 연결 수정 형식은 올해 발표하는 새로운 OS 기능을 가능하게 합니다 하지만 이를 이해하려면 dyld가 작동하는 방식에 대해 알아야하죠
dyld는 메인 실행 파일에서 시작합니다. 앱이라고 해보죠 mach-o를 파싱하여 종속 dylib들을 찾습니다 필요한 동적 라이브러리를 찾는 것이죠 해당 dylib들을 찾아 mmap()을 수행합니다 그 다음 이들 각각에 대해 재귀적으로 mach-o 구조를 파싱합니다 필요에 따라 추가적으로 dylib를 로드하면서요 모든 것이 로딩되면 dyld는 필요한 모든 바인드 심볼을 조회하고 수정을 수행할 때 해당 주소를 사용합니다 마지막으로 모든 수정이 완료되면 dyld는 이니셜라이저를 상향식으로 실행합니다 저희는 5년 전에 새로운 dyld 기술을 발표했습니다 앱이 실행될 때마다 녹색 단계들이 매번 동일하다는 것을 깨달았죠 따라서 프로그램과 dylib들이 변경되지 않는 한 모든 녹색 단계는 첫 번째 실행에서 캐시되고 후속 실행에서는 재사용 될 수 있습니다 올해 우리는 추가 dyld 성능 개선 사항을 발표합니다 새로운 dyld 속성 'page-in linking' 페이지-인 링킹입니다 dyld가 모든 수정 사항을 실행 시에 모든 dylib에 적용하는 대신 커널이 수정 사항을 DATA 페이지에 게으르게 적용할 수 있죠 페이지-인에서요 mmap 처리된 영역의 일부 페이지에서 일부 주소를 처음 사용하면 커널이 해당 페이지를 읽도록 유발하는 경우가 항상 있었습니다 그러나 이제 DATA 페이지의 경우 커널은 해당 페이지에 필요한 수정도 적용합니다 10년이 넘도록 dyld 공유 캐시에 있는 OS dylib에 대한 페이지-인 링킹 특수 케이스가 있었습니다 올해는 이를 일반화하여 모든 사람이 사용 가능하도록 만들었습니다 이 매커니즘은 더티 메모리와 실행 시간을 줄이죠 그렇다는 것은 DATA_CONST 페이지가 깨끗하다는 의미이고 TEXT 페이지처럼 축출과 재생성이 가능해서 메모리 압력이 줄어듭니다 이런 페이지-인 링킹 속성은 차기 iOS, macOS 및 watchOS 릴리즈에 포함될 예정입니다 페이지-인 링킹은 연결 수정으로 빌드된 바이너리에만 작동합니다 그 이유는 연결 수정을 사용하면 대부분의 수정 정보가 디스크의 DATA 세그먼트에 인코딩되고 페이지-인 중에 커널에서 사용할 수 있기 때문이죠 주의할 것은 dyld가 이 매커니즘을 시작 중에만 사용한다는 겁니다 나중에 dlopen()된 dylib들은 페이지-인 링킹되지 못하죠 그 경우 dyld는 전통적인 경로를 사용하고 수정 사항을 dlopen 호출 중에 적용합니다 이를 염두에두고 dyld 워크플로우 다이어그램으로 돌아가보죠 지금까지 5년간 dyld는 위의 녹색 단계를 최적화 해왔습니다 첫 실행에서 작업을 캐싱하고 나중의 실행에서 이를 재사용함으로써요 이제 dyld는 '수정 적용' 단계를 최적화 할 수 있습니다 수정을 직접 수행하지 않고 게으르게 페이지-인에서 커널이 하도록 만들어서요 이제 dyld의 새 기능을 확인했으니 동적 링킹의 모범 사례에 대해 이야기해 보겠습니다 동적 링크 성능 개선을 위해 가능한 것에는 무엇이 있을까요 방금 보여드렸지만 dyld는 이미 동적 링킹의 대부분의 단계를 가속화했습니다 우리가 제어할 수 있는 한가지는 dylib의 수 입니다 더 많은 dylib가 있을수록 dyld가 더 많은 로드 작업을 해야 하죠 반대로 dylib가 적을수록 dyld가 수행해야 하는 작업이 줄어듭니다 다음으로 살펴볼 수 있는 부분은 정적 이니셜라이저입니다 항상 메인 이전에 실행되는 코드죠 정적 이니셜라이저에서는 I/O 또는 네트워킹을 수행하지 마세요 몇 밀리초 이상 소요될 수 있는 작업은 이니셜라이저에서 수행되어서는 안됩니다 세상은 점점 더 복잡해지고 사용자는 더 많은 기능을 원합니다 따라서 라이브러리를 사용해 그 모든 기능을 관리하는게 합리적이죠 목표는 동적 및 정적 라이브러리 사이의 최적의 지점을 찾는 겁니다 너무 많은 정적 라이브러리와 반복적인 빌드/디버그 사이클은 늦어집니다 반면에 너무 많은 동적 라이브러리와 느린 시작 시간은 고객이 알아차리죠 그러나 올해는 ld64의 속도를 높였기 때문에 최적의 지점이 변경되었을 수 있습니다 이제 더 많은 정적 라이브러리 또는 더 많은 소스 파일을 앱에서 직접 사용하면서 여전히 동일한 시간에 빌드할 수 있습니다 마지막으로 설치 기반에서 작동하는 경우 새로운 배포 대상으로 업데이트하게 되면 도구들이 연결 수정을 생성하여 바이너리를 더 작게 만들고 실행 시간을 단축할 수 있죠 마지막으로 여러분 모두가 알고 있길 바라는 점은 링킹 과정을 들여다보는 데 도움이 될 새로운 도구 두 가지입니다 첫 번째 도구는 dyld_usage입니다 이것을 사용해 dyld가 하는 일을 추적할 수 있습니다 이 도구는 macOS에만 있지만 시뮬레이터에서 앱 실행을 추적하거나 앱이 Mac Catalyst 용으로 빌드된 경우에 사용할 수 있죠 다음은 macOS에서 TextEdit에 대해 실행한 예입니다
맨 위의 몇 줄에서 알 수 있듯이 실행하는데 총 15ms나 걸렸지만 페이지-인 링킹 덕에 수정에는 1ms 밖에 걸리지 않았습니다 이제 대부분의 시간은 정적 이니셜라이저에서 소요됩니다
두 번째 도구는 dyld_info입니다 이를 사용해 디스크와 현재 dyld 캐시 모두에서 바이너리를 검사할 수 있습니다 이 도구에는 많은 옵션이 있지만 내보내기 및 수정을 보는 방법을 보여드리겠습니다 여기 -fixup 옵션은 dyld가 처리할 모든 수정 위치와 그 대상을 표시합니다 파일이 이전 스타일의 수정이든 새로운 연결 수정이든 관계없이 출력은 동일하죠 이 -exports 옵션은 dylib에 있는 모든 내보내기된 심볼 및 dylib의 시작 부분의 각 심볼에 대한 오프셋을 표시합니다 이 경우 dyld 캐시에 있는 dylib인 Foundation.framework에 대한 정보를 보여주고 있죠 디스크에 파일이 없지만 dyld_info 도구는 dyld와 동일한 코드를 사용하므로 찾을 수 있습니다
이제 정적 라이브러리와 동적 라이브러리의 역사와 절충을 이해했으니 여러분의 앱이 수행하는 작업을 검토해보고 그 최적의 지점을 찾았는지 판단해봐야 할 때입니다 만약 앱이 대형인데 빌드가 링크하는데 시간이 꽤 소요된다면 새로운 빠른 링커가 있는 Xcode 14를 사용해보세요 여전히 정적 링크의 속도도 높이고 싶다면 제가 자세히 설명해 드린 세가지 링커 옵션을 살펴보시고 여러분 빌드에서 유의미한지 링크 시간 개선이 있는지 확인해보세요 마지막으로 iOS 13.4 이상에서는 연결 수정을 활성화하여 앱 및 임베디드 프레임워크를 빌드 해 볼 수 있습니다 그 다음 앱이 iOS 16에서 더 작고 더 빠르게 실행되는지 확인하세요 시청해 주셔서 감사합니다 멋진 WWDC 보내시길 바랍니다
-