-
개인 맞춤형 목소리로 음성 합성 확장하기
최신 음성 합성 기술을 앱에 적용해 봅니다. 사용자 맞춤형 음성 합성기와 음성을 iOS 및 macOS에 통합하는 방법을 알아보세요. SSML이 표현형 음성 합성을 생성하는 데 어떻게 사용되는지 보여 드리겠습니다. 또한 보완, 대체 의사소통 앱이 사람을 대신하여 사람과 똑같은 방식으로 말할 수 있도록 Personal Voice가 작동하는 모습을 살펴보세요.
챕터
- 0:00 - Welcome
- 1:25 - Explore SSML
- 2:37 - Implement a synthesis provider
- 10:01 - Use Personal Voice
리소스
- Audio Unit
- Creating an audio unit extension
- Speech Synthesis Markup Language (SSML)
- Speech synthesis
관련 비디오
WWDC20
-
비디오 검색…
♪ ♪
안녕하세요, 그랜트입니다 접근성 팀 엔지니어죠 많은 이들이 Apple 플랫폼에서 음성 합성을 사용하고 음성 합성기 목소리에 의지하는 분도 있는데요 이런 목소리는 기기를 들여다보는 창구가 됩니다 어떤 목소리를 선택할지는 순전히 개인 취향에 달린 문제죠 iOS 음성 합성에서는 이미 다양한 목소리를 지원하지만 더 많은 목소리를 제공할 방법을 다루려고 합니다 우선 음성 합성 마크업 언어가 무엇인지 살펴보고 어떻게 맞춤형 음성에 몰입형 음성 출력을 제공하는지 왜 음성 공급자가 해당 언어를 채택해야 하는지 알아보도록 합시다 그런 다음 음성 합성 공급자를 구현해서 기기에 전반에 걸쳐 합성기와 음성 경험을 제공하는 방법을 배우고 마지막으로 Personal Voice를 살펴보겠습니다 새로 도입된 기능인데요 사람이 녹음한 목소리를 바탕으로 합성 음성을 생성할 수 있죠 사용자 본인의 목소리로 음성을 합성할 수 있는 겁니다 그럼 SSML을 알아봅시다 SSML은 음성 텍스트를 표현하는 W3C 표준입니다 SSML 음성은 다양한 태그와 속성을 가진 XML 형식을 사용해 선언적으로 표현됩니다 이런 태그를 사용해 속도나 높낮이 같은 음성 속성을 제어할 수 있죠 Apple 자사 합성기에 SSML이 사용되는데요 WebKit의 WebSpeech가 포함되죠 음성 합성기의 표준 입력이기도 하죠 SSML의 사용법을 알아보도록 합시다 중간에 잠시 멈추는 어구를 예시로 들어 볼게요 이런 휴지를 SSML로 표현할 수 있습니다 '안녕' 문자열로 시작하고 SSML break 태그로 1초 휴지를 추가한 뒤 '만나서 반가워'는 속도를 높여 끝내는 거죠 SSML prosody 태그를 추가하고 속도 속성을 200%로 설정합니다 이제 이 SSML을 사용하여 대화할 AVSpeechUtterance를 생성할 수 있습니다 그럼 이제 본인의 음성 합성기 목소리를 어떻게 구현하는지 살펴보죠
음성 합성기는 뭘까요? 음성 합성기는 텍스트와 원하는 음성 속성에 대한 정보를 SSML 형태로 받고 해당 텍스트의 오디오 표현을 제공합니다 훌륭한 새 음성을 포함하는 합성기가 있고 iOS와 macOS, iPadOS로 이를 가져오려고 합니다 음성 합성 공급자를 사용하면 음성 합성기와 목소리를 플랫폼에 구현해 시스템 음성보다 훨씬 개인화된 음성을 사용자에게 제공할 수 있습니다
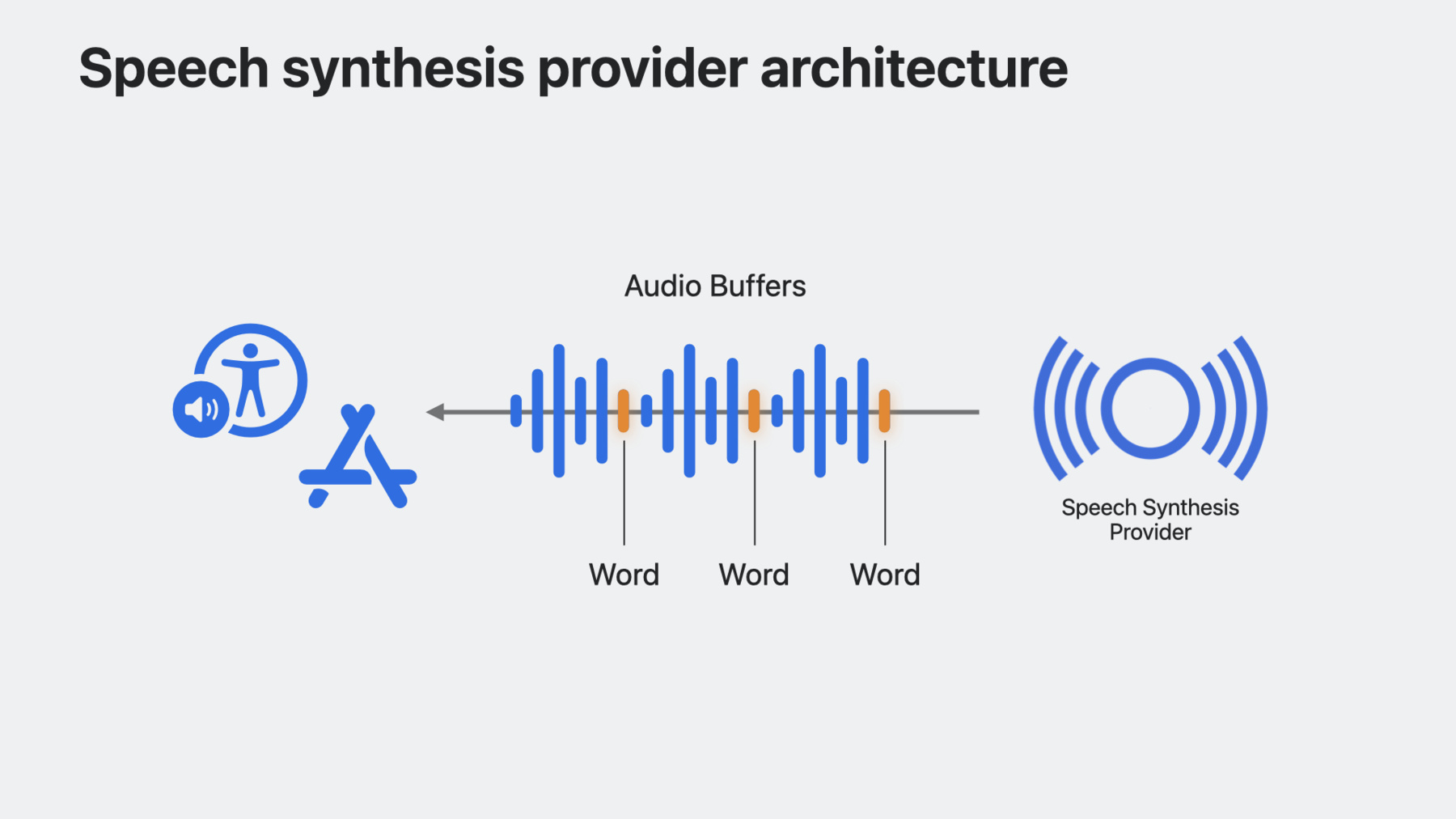
작동 방식을 알아보죠 음성 합성 공급자 Audio Unit 확장 프로그램이 호스트 앱에 내재해 있고 SSML 형태로 음성 요청을 받습니다 확장 프로그램은 SSML 입력에 대한 오디오 렌더링을 담당하고 단어 발생 위치를 나타내는 마커를 오디오 버퍼 내에서 선택적으로 반환합니다 이후 해당 음성 요청 재생을 시스템에서 모두 관리하죠 오디오 세션 관리를 처리할 필요가 없습니다 음성 합성 제공자 프레임워크가 내부적으로 관리하죠 합성기가 뭔지 파악했으니 음성 합성기 확장 프로그램을 빌드해 볼 수 있겠네요 새로운 Audio Unit 확장 앱 프로젝트를 Xcode에서 생성한 다음 Audio Unit 유형은 '음성 합성기'를 선택하고 네 글자로 된 합성기 하위 유형 식별자와 본인을 제조자로 설정하는 네 글자 식별자를 제공합니다 Audio Unit 확장 프로그램은 핵심 아키텍처로 음성 합성기 확장 프로그램이 빌드된 곳입니다 호스트 앱 프로세스 대신에 확장 프로세스에서 합성기를 실행하도록 해 주죠
확장 프로그램이 합성할 음성을 구입하고 선택할 수 있는 간단한 인터페이스를 앱에서 제공할 겁니다 구입 가능한 음성을 보여 주는 목록 뷰 먼저 생성해 보죠 음성 이름과 구입 버튼이 각 목소리 셀에 표시되겠죠
그런 다음 목록에 음성을 채워 볼게요 WWDCVoice는 간단한 구조체로 음성 이름과 식별자를 갖습니다
구입한 음성을 추적하려면 상태 변수도 필요하고 이를 표시할 섹션도 새로 필요하죠 이어서 음성 구입을 위한 함수를 생성해 봅시다 여기서 새로 구입한 음성을 목록에 추가할 수 있고 그에 따라 UI를 업데이트할 수도 있습니다 AVSpeechSynthesis ProviderVoice 메서드 updateSpeechVoices를 기록합니다 이렇게 하면 합성기에 사용 가능한 음성 세트가 변경됐으며 시스템 음성 목록을 다시 빌드해야 한다고 앱에서 신호를 보낼 수 있습니다 이번 예제에서는 앱 내 음성 구입을 완료한 뒤 이를 호출할 수 있겠죠 음성 합성기 확장 프로그램에서 어떤 음성을 사용할 수 있는지 확인할 방법도 필요합니다 앱 그룹을 통해 공유할 UserDefaults의 인스턴스를 생성하면 됩니다 앱 그룹을 통해 호스트 앱과 확장 프로그램 간에 음성 목록을 공유할 수 있죠 앱 그룹을 생성할 때 받았던 스위트 이름을 명시적으로 지정하고 있습니다 호스트 앱과 확장 프로그램이 같은 도메인에서 읽을 수 있도록요 purchase 함수로 되돌아가 살펴보면 새로운 음성을 구입할 때 사용자 기본을 업데이트하는 메서드를 구현해 두었고요 또한 AVSpeechSynthesizer는 사용 가능한 시스템 음성의 변경을 수신하는 새로운 API가 있습니다 사용자가 음성을 삭제하거나 새 음성을 다운로드할 때 시스템 음성 집합이 바뀔 수 있죠 availableVoices DidChangeNotification을 구독해 이런 변경 내용을 기반으로 음성 목록을 업데이트할 수 있어요 호스트 앱은 준비됐으니 키 컴포넌트 네 개로 구성되는 Audio Unit을 채워 봅시다
합성기에서 제공할 음성을 시스템에 알리는 방법부터 먼저 추가하겠습니다 음성 목록을 제공하도록 speechVoices getter를 재정의하고 앞서 지정했던 앱 그룹인 UserDefaults 도메인에서 읽으면 됩니다 음성 목록 내 항목별로 미국식 영어 AVSpeechSynthesisProviderVoice를 구성할 겁니다 그런 다음 시스템이 어떤 텍스트를 합성할지 합성기에 말해 줄 방법을 마련해야겠죠 synthesizeSpeechRequest 메서드는 시스템이 확장 프로그램에 텍스트 합성을 시작하라고 신호를 줄 때 호출됩니다 이 메서드의 인수는 SSML과 대화할 음성을 포함하는 AVSpeechSynthesis ProviderRequest의 인스턴스가 되겠죠 이어서 음성 엔진 구현에 생성해 둔 helper 메서드를 호출하겠습니다 이번 예제에서는 getAudioBuffer 메서드가 오디오 데이터를 생성할 겁니다 요청과 SSML 입력에서 명시된 음성을 기반으로 해서요 인스턴스 변수 framePosition은 0으로 설정해서 렌더링 블록을 호출할 때 렌더링한 프레임 수를 추적하고 버퍼에서 프레임을 복사합니다 합성기가 오디오 합성을 멈추고 현재 음성 요청을 버리도록 신호를 보내는 방법도 필요하죠 cancelSpeechRequest를 사용하면 됩니다 현재 버퍼를 간단히 버리는 곳이죠 마지막으로 렌더링 블록을 구현해야겠죠 렌더링 블록은 원하는 frameCount를 사용해 시스템에서 호출합니다 이후 Audio Unit은 프레임을 요청받은 수만큼 outputAudioBuffer로 채워야 합니다 그런 다음 타깃 버퍼에 대한 참조와 synthesizeSpeechRequest 호출 중 생성하고 저장한 버퍼를 설정한 뒤 타깃 버퍼로 프레임을 복사합니다 마지막으로 Audio Unit이 현재 음성 요청에 대한 버퍼를 모두 소진하면 actionFlags 인수를 offlineUnitRenderAction _Complete로 설정해 렌더링이 완료됐으며 더 렌더링할 오디오 버퍼가 없다고 시스템에 신호를 보냅니다 그럼 작동해 봅시다 이건 제 음성 합성기 앱인데요 음성을 구입한 뒤 새 음성 엔진을 사용해서 음성을 합성하는 뷰로 이동할게요 우선 합성기에 '안녕'을 입력하겠습니다
안녕 이번엔 '잘 가'를 입력해 보죠
잘 가 이렇게 합성 공급자를 구현하고 시스템 전반에서 사용 가능한 음성을 제공하는 호스트 앱을 생성해 봤습니다 VoiceOver부터 여러분의 앱까지 어디서든 가능하죠 이런 API를 사용해 새로운 목소리를 구현하고 텍스트를 음성으로 전환해 보시길 바라요 다음으로는 새로운 기능인 Personal Voice를 살펴봅시다 이제 기기의 성능을 활용해 iOS와 macOS에서 목소리를 녹음하고 재생성할 수 있습니다 Personal Voice는 서버가 아니라 기기에 생성됩니다 나머지 시스템 음성과 함께 표시되며 Live Speech라는 새 기능과 함께 사용할 수 있습니다 Live Speech는 텍스트를 읽어 주는 기능으로 iOS와 iPadOS, macOS watchOS에서 지원합니다 즉석에서 자신의 목소리로 음성을 합성할 수 있죠 Personal Voice에 대한 새로운 요청 승인 API를 사용해 이런 목소리와 음성을 합성하도록 액세스를 요청할 수 있습니다 Personal Voice는 사용이 민감하므로 보완, 대체 의사소통 앱에 주로 사용한다는 점을 꼭 기억해 두세요 Personal Voice용으로 만들어 둔 AAC 앱을 확인해 보죠 앱에 보이는 버튼 중 두 개는 제가 WWDC 세션에서 사용하는 일반적인 어구를 말해 주고 나머지 하나는 Personal Voice 액세스를 요청하는 버튼입니다 승인은 AVSpeechSynthesizer에서 새 API로 요청할 수 있죠 바로 requestPersonalVoice Authorization입니다 승인이 나면 AVSpeechSynthesisVoice API의 speechVoices에서 Personal Voice의 음성이 시스템 음성과 함께 나타나고 isPersonalVoice라는 새 voiceTrait가 표시될 겁니다
이제 Personal Voice에 액세스할 수 있으므로 대화할 때 사용할 수 있겠죠
Personal Voice 작동을 시연해 보겠습니다 'Personal Voice 사용하기'를 눌러 승인을 요청해 볼게요 요청이 수락되면 심볼을 탭해서 제 목소리를 들을 수 있습니다 안녕하세요, 그랜트입니다 WWDC23에 잘 오셨어요 정말 대단하지 않나요? 이제 여러분도 앱에서 이런 음성을 사용할 수 있습니다
앞서 살펴본 SSML은 앱에서 음성 입력을 표준화하고 풍부한 음성 경험을 빌드할 때 사용할 수 있습니다 음성 합성기를 Apple 플랫폼에서 구현하는 방법도 살펴봤으니 이제 여러분도 훌륭한 새 음성을 시스템 전역에서 사용하도록 제공할 수 있을 겁니다 마지막으로 Personal Voice를 이용해 앱에서 음성을 합성할 때 개성을 더 반영할 수 있겠죠 목소리를 잃어 가는 사용자에게 특히 도움이 될 겁니다 이 API들을 사용해서 색다른 경험을 생성해 보세요 감사합니다
-
-
2:10 - SSML phrase
<speak> Hello <break time="1s"/> <prosody rate="200%">nice to meet you!</prosody> </speak> -
2:29 - SSML utterance
let ssml = """ <speak> Hello <break time="1s" /> <prosody rate="200%">nice to meet you!</prosody> </speak> """ guard let ssmlUtterance = AVSpeechUtterance(ssmlRepresentation: ssml) else { return } self.synthesizer.speak(ssmlUtterance) -
4:33 - Create a host app
struct ContentView: View { var body: some View { List { Section("My Awesome Voices") { ForEach(availableVoices) { voice in HStack { Text(voice.name) Spacer() Button("Buy") { // Buy this voice... } } } } } } var availableVoices: [WWDCVoice] { return [ WWDCVoice(name: "Screen Reader Voice", id: "com.example.screen-reader-voice"), WWDCVoice(name: "Reading Voice", id: "com.example.reading-voice") ] } } -
5:04 - Keep track of purchased voices
struct ContentView: View { @State var purchasedVoices: [WWDCVoice] = [] var body: some View { NavigationStack { List { MyAwesomeVoicesSection Section("Purchased Voices") { ForEach(purchasedVoices) { voice in NavigationLink { // Destination View } label: { Text(voice.name) } } } } } } } -
5:13 - Inform the system when available voices change
struct ContentView: View { @State var purchasedVoices: [WWDCVoice] = [] var body: some View { List { MyAwesomeVoicesSection PurchasedVoicesSection } } func purchase(voice: WWDCVoice) { // Append voice to list of purchased voices purchasedVoices.append(voice) // Inform system of change in voices AVSpeechSynthesisProviderVoice.updateSpeechVoices() } } -
5:39 - Update UI with purchased voices
struct ContentView: View { @State var purchasedVoices: [WWDCVoice] = [] var body: some View { List { Section("My Awesome Voices") { ForEach(availableVoices.filter { !purchasedVoices.contains($0) }) { voice in HStack { Text(voice.name) Spacer() Button("Buy") { purchase(voice: voice) } } } } PurchasedVoicesSection } } } -
5:46 - Save available voices into UserDefaults
struct ContentView: View { let groupDefaults = UserDefaults(suiteName: "group.com.example.SpeechSynthesizerApp")! @State var purchasedVoices: [WWDCVoice] = [] var body: some View { List { MyAwesomeVoicesSection PurchasedVoicesSection } } func purchase(voice: WWDCVoice) { // Append voice to list of purchased voices purchasedVoices.append(voice) // Write purchasedVoices to defaults updatePurchasedVoices() // Inform system of change in voices AVSpeechSynthesisProviderVoice.updateSpeechVoices() } } -
6:25 - Monitor for system voice changes
struct ContentView: View { @State var systemVoices: [AVSpeechSynthesisVoice] = AVSpeechSynthesisVoice.speechVoices() var body: some View { List { MyAwesomeVoicesSection PurchasedVoicesSection Section("System Voices") { ForEach(systemVoices.filter { $0.language == "en-US" }) { voice in Text(voice.name) } } } .onReceive(NotificationCenter.default .publisher(for: AVSpeechSynthesizer.availableVoicesDidChangeNotification)) { _ in systemVoices = AVSpeechSynthesisVoice.speechVoices() } } } -
6:53 - Override speechVoices getter
// Implement a synthesis provider public class WWDCSynthAudioUnit: AVSpeechSynthesisProviderAudioUnit { public override var speechVoices: [AVSpeechSynthesisProviderVoice] { get { } } } -
7:02 - Use UserDefaults to provide set of available voices
public class WWDCSynthAudioUnit: AVSpeechSynthesisProviderAudioUnit { public override var speechVoices: [AVSpeechSynthesisProviderVoice] { get { let voices: [String : String] = groupDefaults.value(forKey: "voices") as? [String : String] ?? [:] return voices.map { key, value in return AVSpeechSynthesisProviderVoice(name: value, identifier: key, primaryLanguages: ["en-US"], supportedLanguages: ["en-US"] ) } } } } -
7:22 - Use your synthesis engine on each synthesis request
public class WWDCSynthAudioUnit: AVSpeechSynthesisProviderAudioUnit { public override func synthesizeSpeechRequest(speechRequest: AVSpeechSynthesisProviderRequest) { currentBuffer = getAudioBuffer(for: speechRequest.voice, with: speechRequest.ssmlRepresentation) framePosition = 0 } } -
8:14 - Handle request cancellation
public class WWDCSynthAudioUnit: AVSpeechSynthesisProviderAudioUnit { public override func synthesizeSpeechRequest(speechRequest: AVSpeechSynthesisProviderRequest) { currentBuffer = getAudioBuffer(for: speechRequest.voice, with: speechRequest.ssmlRepresentation) framePosition = 0 } public override func cancelSpeechRequest() { currentBuffer = nil } } -
8:28 - Override internalRenderBlock
public class WWDCSynthAudioUnit: AVSpeechSynthesisProviderAudioUnit { public override var internalRenderBlock: AUInternalRenderBlock { return { [weak self] actionFlags, timestamp, frameCount, outputBusNumber, outputAudioBufferList, _, _ in guard let self else { return kAudio_ParamError } return noErr } } } -
8:42 - Implement the render block
public class WWDCSynthAudioUnit: AVSpeechSynthesisProviderAudioUnit { public override var internalRenderBlock: AUInternalRenderBlock { return { [weak self] actionFlags, timestamp, frameCount, outputBusNumber, outputAudioBufferList, _, _ in guard let self else { return kAudio_ParamError } // This is the audio buffer we are going to fill up var unsafeBuffer = UnsafeMutableAudioBufferListPointer(outputAudioBufferList)[0] let frames = unsafeBuffer.mData!.assumingMemoryBound(to: Float32.self) var sourceBuffer = UnsafeMutableAudioBufferListPointer(self.currentBuffer!.mutableAudioBufferList)[0] let sourceFrames = sourceBuffer.mData!.assumingMemoryBound(to: Float32.self) for frame in 0..<frameCount { if frames.count > frame && sourceFrames.count > self.framePosition { frames[Int(frame)] = sourceFrames[Int(self.framePosition)] self.framePosition += 1 if self.framePosition >= self.currentBuffer!.frameLength { break } } } return noErr } } } -
11:10 - Request authorization for Personal Voice
struct ContentView: View { @State private var personalVoices: [AVSpeechSynthesisVoice] = [] func fetchPersonalVoices() async { AVSpeechSynthesizer.requestPersonalVoiceAuthorization() { status in if status == .authorized { personalVoices = AVSpeechSynthesisVoice.speechVoices().filter { $0.voiceTraits.contains(.isPersonalVoice) } } } } } -
11:34 - Use Personal Voice
func speakUtterance(string: String) { let utterance = AVSpeechUtterance(string: string) if let voice = personalVoices.first { utterance.voice = voice syntheizer.speak(utterance) } }
-