-
기계 학습 모델 압축에 Core ML Tools 활용하기
Core ML Tools를 활용해 앱의 기계 학습 모델 풋프린트를 줄이는 방법을 알아봅니다. 팔레트화와 가지치기, 양자화를 비롯한 기술을 사용해 모델의 크기를 현저하게 줄이면서도 높은 수준의 정확도를 달성하는 방법을 살펴보겠습니다. 훈련 도중 모델을 압축하는 경우와 완전히 훈련된 모델을 압축하는 경우를 비교하고, 앱이 Apple Neural Engine을 최대한 활용해 압축 모델을 훨씬 더 빠르게 실행하는 방법을 소개합니다. Core ML 최적화에 대해 더 자세히 알고 싶다면 WWDC23의 세션인 '비동기 예측으로 Core ML 통합 개선하기'를 참조하세요.
리소스
관련 비디오
WWDC20
-
비디오 검색…
♪ ♪
안녕하세요, 풀킷입니다 Core ML 팀 엔지니어예요 Core ML Tools 업데이트 세션을 맡게 돼 정말 기쁩니다 기계 학습 모델의 크기와 성능을 최적화하는 데 오늘 소개할 업데이트 사항들이 유용할 겁니다 모델 기능이 크게 향상되면서 점점 더 많은 기능을 기계 학습이 구동하고 있습니다 결과적으로 단일 앱으로 배포되는 모델 수가 증가하게 됐고 앱의 각 모델도 점점 커지면서 앱 크기에 대한 압박이 가중됐죠 따라서 모델 크기를 확인하는 것이 중요합니다 모델 크기를 줄이면 몇 가지 이점이 있는데요 각 모델이 더 작아질 경우 동일한 메모리 예산으로 더 많은 모델을 출시할 수 있습니다 더 크고 성능이 뛰어난 모델을 출시할 수도 있고요 모델의 실행 속도를 높일 수도 있겠죠 모델이 작을수록 메모리와 프로세서 간에 이동할 데이터가 적기 때문입니다 따라서 모델의 크기를 줄이는 게 좋겠죠 모델은 어째서 커지는 걸까요? 이해를 돕고자 예시를 들어 설명해 볼게요 ResNet50는 널리 사용되는 이미지 분류 모델입니다 첫 번째 레이어는 매개변수가 대략 9천 개 있는 콘볼루션 레이어입니다 콘볼루션 레이어는 총 53개이고 크기가 다양하죠 마지막에는 매개변수 210만여 개를 가진 선형 계층이 있습니다 다 합하면 매개변수는 2,500만여 개가 됩니다 float16 정밀도를 사용해 모델을 저장한다면 가중치당 2바이트를 사용하니 50MB짜리 모델을 얻겠죠 50MB 모델도 크지만 안정적 확산 모델 같은 최신 모델을 사용하면 더 큰 모델을 갖게 됩니다 더 작은 모델을 얻는 경로를 알아보도록 하죠 더 적은 가중치로 우수한 성능을 달성할 수 있는 효율적인 모델 아키텍처를 디자인하는 방법이 있습니다 기존 모델의 가중치를 압축하는 방법도 있죠 오늘은 이런 모델 압축 경로에 중점을 두고자 합니다 모델 압축에 유용한 기술 세 가지를 먼저 살펴본 뒤 이런 모델 압축 기술을 통합하는 두 가지 워크플로를 보여 드릴게요 그런 다음 이런 기술과 워크플로를 모델에 적용하는 데 최신 Core ML Tools가 어떻게 도움이 되는지 알아보죠 마지막으로 스리잔과 함께 모델 압축이 런타임 성능에 어떤 영향을 미치는지 확인해 보도록 합시다 그럼 압축 기술부터 살펴보죠 모델 가중치를 압축하는 방법은 여러 가지가 있는데요 첫 번째 방법은 희소 행렬 표현을 사용해 더 효율적으로 패킹하는 겁니다 가지치기 기술을 사용하면 됩니다 가중치 저장에 사용하는 정밀도를 줄이는 방법도 있습니다 양자화나 팔레트화로 이를 수행할 수 있죠 두 전략 모두 손실이 생기고 보통 압축 모델은 압축되지 않은 모델에 비해 정확도가 약간 떨어집니다
기술을 하나씩 자세히 살펴볼게요
가중치 가지치기는 희소 표현을 사용해 모델 가중치를 효율적으로 패킹하도록 돕습니다 가중치 행렬을 희소화 또는 가지치기한다는 건 일부 가중치값을 0으로 설정한다는 의미예요 가중치 행렬로 시작하겠습니다 가지치기를 위해 최소 크기 가중치를 0으로 할게요
이제 0이 아닌 값만 저장하면 됩니다 0이 도입될 때마다 스토리지를 2바이트 정도 절약하게 됐습니다 나중에 밀집 행렬을 재구성하려면 0의 위치를 저장해야겠죠 모델 크기는 도입된 희소성 수준에 따라 선형으로 감소합니다 50% 희소 모델은 가중치의 50%가 0이라는 뜻입니다 ResNet50 모델의 경우 크기가 약 28MB인데 float16의 절반 정도죠
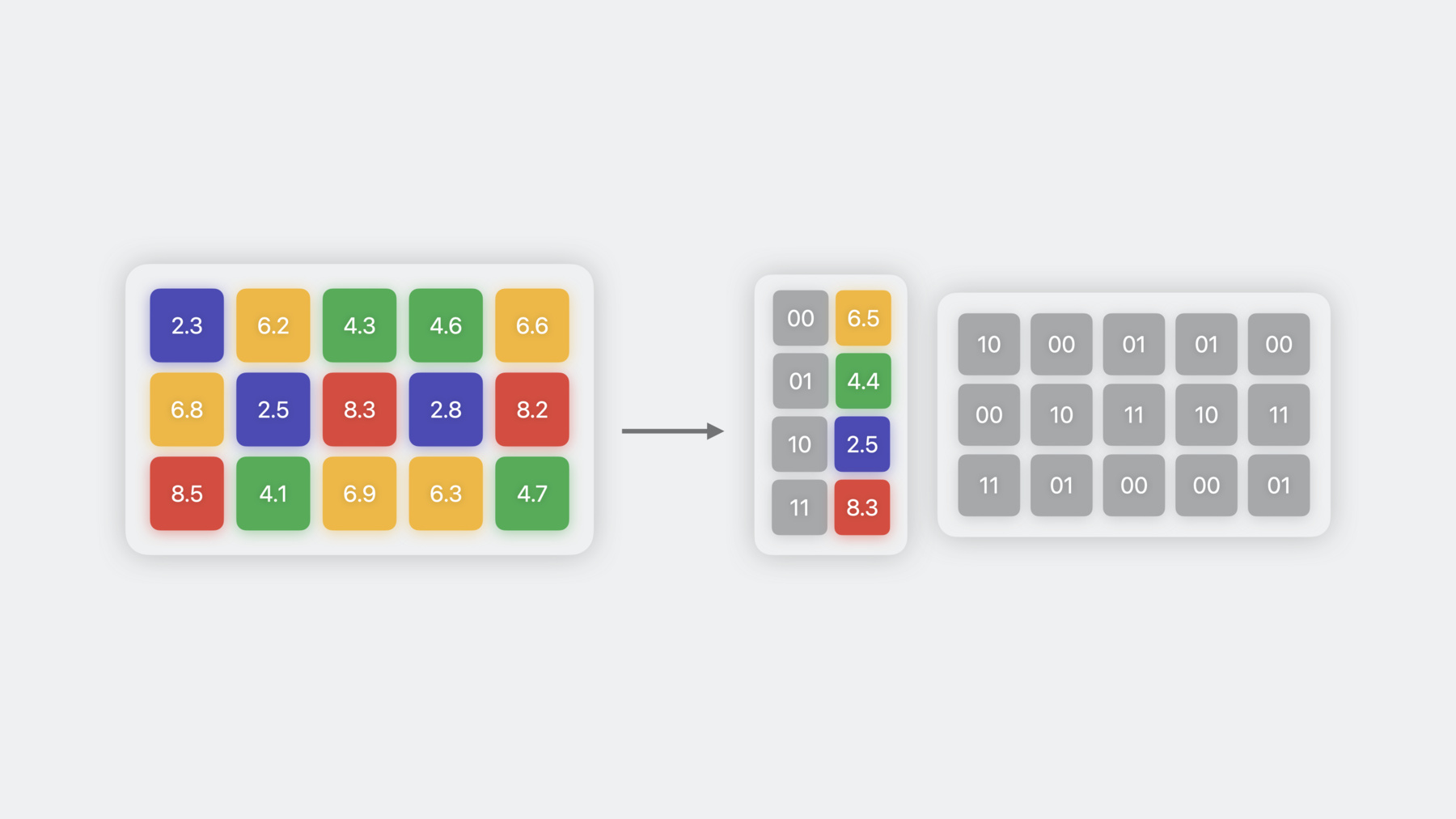
두 번째 가중치 압축 기술은 8비트 정밀도를 사용해 가중치를 저장하는 양자화입니다 양자화를 수행하려면 가중치값을 가져와서 int8 범위에 있도록 크기를 조정하고 이동하며 반올림합니다 이 예시에서 스케일은 2.35이고 가장 작은 값을 -127에 매핑하며 편향은 0입니다 모델에 따라 0이 아닌 편향도 사용할 수 있어서 양자화 오류를 줄이는 데 도움이 되기도 하죠 스케일과 편향은 가중치를 원래 범위로 되돌리고자 역양자화하는 데 재차 사용될 수 있습니다 가중치 정밀도를 8비트 미만으로 줄이려면 가중치 클러스터링 또는 팔레트화 기술을 사용하면 돼요 비슷한 값을 가진 가중치를 함께 그룹화하고 이들이 속한 클러스터 중심의 값을 사용해 표현하는 기술입니다 이런 중심은 룩업 테이블에 저장됩니다 그러면 원래 가중치 행렬이 인덱스 테이블로 변환되고 여기서 각 요소는 해당 클러스터의 중심을 가리킵니다 이 예시에서는 클러스터가 네 개이므로 2비트를 사용해 각 가중치를 표현하며 float16보다 여덟 배 더 압축할 수 있죠 가중치 표현에 사용할 수 있는 고유한 클러스터 중심의 수는 2의 n승과 같습니다 여기서 n은 팔레트화에 사용되는 정밀도예요 따라서 4비트 팔레트화는 클러스터 16개를 가질 수 있다는 의미죠 양자화는 모델 크기를 절반으로 줄이는 반면 팔레트화는 최대 여덟 배까지 줄일 수 있습니다
요약하자면 가중치 압축 기술은 세 가지입니다 각기 다른 방법을 사용해 가중치를 표현하고 다양한 수준의 압축을 제공하며 가지치기를 위한 희소성 양이나 팔레트화를 위한 비트 수 등 저마다의 매개변수로 제어해요 이제 이런 기술을 모델 개발 워크플로에 통합해 봐야겠죠 Core ML 모델 변환 워크플로부터 시작해 봅시다 원하는 파이썬 훈련 프레임워크로 모델을 훈련한 뒤 Core ML Tools를 사용해 해당 모델을 Core ML로 변환할 수 있습니다 워크플로를 한 단계 더 확장해 훈련 후 압축 워크플로로 만들 수 있어요 그러려면 전체 크기가 줄어들도록 이미 훈련되고 변환된 모델 가중치에 작동하는 압축 단계를 추가합니다 이 워크플로는 언제든지 시작할 수 있습니다 예를 들어 훈련 데이터가 필요 없는 사전 훈련 된 모델이나 이미 변환된 Core ML 모델로 시작할 수 있어요
이 워크플로를 적용할 때 압축할 양을 선택할 수 있습니다 압축을 더 많이 적용할수록 결과 모델은 더 작아지지만 트레이드오프가 생기기 마련이죠 특히나 특정 정확도를 달성하는 압축되지 않은 모델로 시작하게 될 테니까요 압축을 적용하면 모델 크기가 줄어들지만 정확도에도 영향을 미칠 수 있습니다 압축을 많이 적용할수록 이런 영향이 더욱 두드러지고 허용하기 힘들 정도로 정확도가 손실될 수 있어요
이런 추세와 허용 가능한 정도는 사용 예마다 다르며 모델과 데이터 집합에 따라서도 상이합니다 트레이드오프를 실제로 확인해 보죠 이미지 내 객체를 분할하는 모델을 살펴보도록 합시다 제가 불러온 이미지에서 소파에 속하는 픽셀마다 확률을 반환하는 모델입니다 기본 float16 모델은 객체를 아주 잘 분할합니다 가지치기가 10% 된 모델의 출력은 기본 모델과 매우 유사하네요 30% 희소성부터 아티팩트가 나타나기 시작하고 레벨이 높아질수록 증가합니다 40% 가지치기에 도달하면 모델이 완전히 어그러지고 확률 맵은 인식할 수 없게 됩니다 마찬가지로 8비트 양자화와 6비트 팔레트화는 기본 모델의 출력을 유지합니다 4비트 팔레트화에서는 아티팩트가 보이기 시작하고 2비트 팔레트화에서는 객체를 아예 분할하지 못하죠 압축률이 더 높아질 때 모델 성능 저하를 극복하려면 다른 워크플로를 사용하면 됩니다 '훈련 시간 압축'이라는 워크플로인데요 여기에서는 가중치를 압축하면서 일부 데이터에 대해 모델을 미세 조정 합니다 압축이 점진적이고 미분 가능한 방식으로 도입되어 새로 부과된 제약 조건에 맞게 가중치를 재조정할 수 있어요 모델이 정확도를 만족스러울 정도로 달성하면 압축된 Core ML 모델로 변환할 수 있습니다 기존 모델 훈련 워크플로에 훈련 시간 압축을 통합해도 좋고 사전 훈련된 모델로 시작해도 됩니다 훈련 시간 압축은 모델 정확도와 압축량 사이의 트레이드오프를 개선해 높은 압축률에서도 모델 성능을 동일하게 유지하도록 합니다 같은 이미지 세그멘테이션 모델을 다시 살펴봅시다 훈련 시간 가지치기의 경우 모델 출력은 최대 40% 희소성까지 바뀌지 않습니다 앞서 훈련 후 정확도가 무너졌던 지점이죠 이제 희소성이 50%, 75%가 되어도 기본 모델과 유사한 확률 맵을 달성하는군요 90% 희소성부터 모델 정확도가 크게 저하되기 시작하네요 마찬가지로 훈련 시간 양자화와 팔레트화는 기본 모델의 출력을 보존합니다 이 경우 2비트 압축까지도 출력이 보존되는군요 간단히 정리하자면 모델 변환 또는 훈련 도중에 가중치 압축을 적용할 수 있습니다 모델 훈련 중에 적용하면 훈련 시간이 길어지지만 정확도는 더 높습니다 두 번째 워크플로는 훈련 중에 압축을 적용하므로 미분 가능한 작업을 사용하여 압축 알고리즘을 구현해야 합니다 이제 이런 압축 워크플로를 Core ML Tools로 실행하는 방법을 살펴보겠습니다 Core ML Tools 6에서 압축 유틸리티 하위 모듈하에 가지치기나 팔레트화, 양자화를 위해 훈련 후 모델 압축 API를 사용할 수 있지만 훈련 시간 압축 API는 없었습니다 Core ML Tools 7에는 새로운 API가 추가되어 훈련 시간 압축 기능도 제공합니다 또한 coremltools.optimize라는 단일 모듈로 이전 API와 새 API를 통합했습니다 훈련 후 압축 API는 coremltools.optimize.coreml로 이동했습니다 새로운 훈련 시간 압축 API는 coremltools.optimize.torch에서 사용 가능하고 파이토치 모델과 함께 작동합니다 먼저 훈련 후 압축 API를 자세히 알아봅시다 훈련 후 압축 워크플로에서 입력은 Core ML 모델입니다 optimize.coreml 모듈에서 사용할 수 있는 세 가지 메서드로 업데이트할 수 있으며 앞서 봤던 압축 기술 세 가지를 각각 적용합니다 이런 메서드를 사용하려면 OptimizationConfig 객체를 먼저 생성하고 모델 압축 방법을 설명합니다 저는 75% 목표 희소성으로 크기 가지치기를 적용했어요 구성이 정의되면 prune_weights 메서드로 모델을 가지치기할 수 있습니다 압축된 모델을 얻는 간단한 단일 프로세스입니다 해당 기술에 특정한 구성으로 가중치를 팔레트화하고 양자화하는 데 유사한 API를 사용할 수 있습니다 이제 훈련 시간 압축 워크플로를 살펴보도록 하죠 여기서는 앞서 설명했듯이 훈련 가능한 모델과 데이터가 필요합니다 좀 더 구체적으로 말하자면 Core ML Tools로 모델을 압축하려면 사전 훈련 된 가중치가 있는 파이토치 모델로 시작합니다 그런 다음 optimize.torch 모듈에서 사용 가능한 API로 업데이트하고 압축 레이어가 삽입된 새 파이토치 모델을 가져온 뒤 미세 조정 합니다 원본 파이토치 훈련 코드와 데이터를 사용해서요 압축을 허용하도록 가중치를 조정하는 단계입니다 MPS 파이토치 백엔드를 사용해 MacBook에서 로컬로 수행할 수 있어요 정확도를 되찾도록 모델이 훈련되면 변환해서 Core ML 모델을 얻습니다 코드 예제를 통해 자세히 살펴봅시다 압축할 모델을 미세 조정 하는 데 필요한 파이토치 코드부터 시작하겠습니다 코드 몇 줄만 추가하면 Core ML Tools를 쉽게 활용해 훈련 시간 가지치기를 추가할 수 있어요 MagnitudePrunerConfig 객체를 먼저 생성하고 모델을 어떤 방식으로 가지치기하고 싶은지 설명합니다 목표 희소성은 75%로 설정하겠습니다 YAML 파일에 구성을 작성하고 from_yaml 메서드를 사용해 로딩할 수도 있어요 그런 다음 압축할 모델과 방금 만든 구성을 사용해 pruner 객체를 생성합니다 이어서 prepare를 호출해 가지치기 레이어를 모델에 삽입할게요 모델을 미세 조정 하는 동안 단계 API를 호출합니다 pruner의 내부 상태를 업데이트하도록요 훈련이 끝나면 finalize를 호출해서 가지치기 마스크를 가중치로 폴딩합니다 이제 변환 API를 사용하여 Core ML로 모델을 변환할 수 있습니다 양자화와 팔레트화에도 같은 워크플로를 사용할 수 있죠 이어서 스리잔이 Core ML Tools API를 사용해 객체 감지 모델을 팔레트화하는 방법을 시연해 줄 거예요 고마워요, 풀킷 저는 스리잔입니다 Core ML Tools 최적화 API를 시연하고자 합니다 ResNet18 백본이 있는 SSD 모델을 사용해 이미지에서 사람을 감지해 볼 거예요 우선 기본 모델과 훈련 유틸리티를 가져올게요 방금 얘기했던 SSD ResNet18 모델의 인스턴스부터 가져와야겠죠 작업이 단순해지도록 미리 작성해 둔 get_ssd_model 유틸리티를 호출하겠습니다 모델이 로딩됐으니 몇 에포크 동안 훈련해 보죠 객체 감지 모델이므로 모델 훈련 목표는 감지 작업의 SSD 손실을 줄이는 것입니다 간결하게 train_epoch 유틸리티는 서로 다른 배치를 통해 forward를 호출하거나 손실을 계산하며 경사 하강법을 수행하는 등 한 에포크 동안 훈련하는 데 필요한 코드를 캡슐화합니다 SSD 손실이 훈련하는 동안 점점 줄어드는 것 같네요 이제 Core ML 모델로 변환하겠습니다 그러려면 우선 모델을 추적한 뒤 coremltools.convert API를 호출해야겠죠 가져온 유틸리티를 호출해 모델 크기를 확인해 봅시다
모델의 크기는 23.6MB입니다 이제 Core ML 모델에서 예측을 실행하겠습니다 런던 여행에서 제가 찍었던 사진과 감지 테스트용 이미지를 선택했어요 객체를 탐지하기 위한 모델의 confidence 임곗값은 30%로 설정돼 있으므로 객체가 존재할 거라고 30% 이상 신뢰할 수 있는 상자만 표시할 겁니다
감지가 제대로 된 듯하네요 모델의 크기를 줄일 수 있을지 궁금해지는데요 훈련 후 팔레트화부터 시도해 볼게요 coremltools.optimize.coreml에서 구성 클래스와 메서드를 가져오겠습니다
이제 모델의 가중치를 6비트로 팔레트화할게요 OpPalettizerConfig 객체를 생성해 모드는 kmeans로 nbits는 6으로 지정합니다 이렇게 하면 매개변수가 작업 수준에서 지정되며 각 작업을 다르게 팔레트화할 수 있습니다 하지만 지금은 모든 작업에 6비트 모드를 적용할 거예요 OptimizationConfig를 정의하고 이 op_config를 전역 매개변수로 전달하겠습니다
최적화 구성은 변환된 모델과 함께 palettize_weights로 전달되고 팔레트화된 모델을 얻습니다 이제 크기가 얼마나 줄어들었는지 봅시다
모델의 크기는 9MB 정도로 줄었네요 혹시 테스트 이미지 성능에 영향을 미친 건 아닐까요? 확인해 봅시다 좋습니다 감지는 여전히 잘되네요 그럼 기쁜 마음으로 이 기세를 몰아 2비트 훈련 후 팔레트화를 곧바로 시도해 볼게요 방법은 아주 간단합니다 OpPalettizerConfig에서 nbits 값을 6에서 2로 바꾸고 palettize_weights API를 다시 실행하면 끝이죠
유틸리티를 사용해 Core ML 모델의 크기와 성능을 살펴보겠습니다
예상했던 대로 모델의 크기가 줄어들어 약 3MB가 됐네요 그런데 성능은 최적이 아닙니다 두 이미지 모두 사람을 감지하지 못했으니까요 모델이 예측한 상자 중 confidence 임곗값이 30%를 넘는 경우가 없어서 예측에 표시된 상자가 없는 거죠 2비트 훈련 시간 팔레트화를 시도해서 성능이 더 나은지 확인해 봅시다
우선 DKMPalettizerConfig와 DKMPalettizer를 coremltools.optimize.torch에서 가져올게요 DKM은 어텐션 기반으로 미분 가능한 K-평균 연산을 수행해 가중치 클러스터를 학습하는 알고리즘입니다 이제 팔레트 구성을 정의할 차례입니다 global_config에서 n_bits를 2로 지정하기만 하면 지원되는 모듈이 전부 2비트로 팔레트화됩니다 여기서는 모델과 구성에서 palettizer 객체를 생성할게요 이제 준비 API를 호출하면 팔레트화에 적합한 모듈을 모델에 삽입할 수 있습니다 몇 에포크 동안 모델을 미세 조정 할 차례네요 모델이 미세 조정 됐으므로 최종 API를 호출할게요 팔레트화된 가중치를 모델의 가중치로 복원하여 프로세스를 완료합니다 다음 단계는 모델의 크기를 확인하는 겁니다 토치 모델을 Core ML 모델로 변환하겠습니다 torch.jit.trace를 사용해 모델을 추적해 봅시다 변환 API를 호출하고 이번에는 PassPipeline이라는 추가 플래그를 사용해 DEFAULT_PALETTIZATION으로 값을 설정하겠습니다 이렇게 하면 변환된 가중치에 팔레트화된 표현을 사용하도록 컨버터에 지시할 거예요
모델의 크기와 테스트 이미지에서의 성능을 확인해 봅시다 훈련 시간 팔레트화 모델도 여덟 배 정도 압축되어 크기가 3MB쯤 되지만 훈련 후 팔레트화 모델과 달리 테스트 이미지를 올바르게 감지하고 있습니다 이건 데모였기 때문에 샘플 이미지 두 개로 모델 성능을 테스트해 봤어요 실제 시나리오에서는 평균 정밀도 같은 메트릭을 사용해 검증 데이터 집합에서 평가하겠죠
간단히 정리해 봅시다 훈련된 모델로 시작했고 float16 가중치가 있는 23.6MB 모델을 얻도록 변환했습니다 그런 다음 palettize_weights API를 사용해 6비트 가중치가 있는 더 작은 모델을 신속하게 얻었는데 데이터에서 잘 작동했죠 하지만 2비트로 바꿨더니 성능이 확연히 떨어졌습니다 이후 optimize.torch API로 토치 모델을 업데이트하고 미분 가능한 K-평균 알고리즘을 사용해 몇 에포크 동안 미세 조정 했죠 이렇게 했더니 2비트 압축 옵션에서도 정확도가 훌륭했습니다 데모에서는 특정 모델과 최적화 알고리즘을 조합해 사용했지만 이 워크플로는 사용 예에 일반화되고 모델 재훈련에 필요한 시간 및 데이터와 원하는 압축량 사이에서 트레이드오프를 파악하는 데 도움이 됩니다 이제 마지막 주제인 성능을 살펴보겠습니다 이러한 모델을 앱에 배포할 때 효율성을 더 높일 수 있도록 Core ML 런타임에 적용한 개선 사항을 간략히 알아볼게요 iOS 16과 iOS 17의 런타임이 어떻게 다른지 주요 차이점을 확인해 보죠 iOS 16에서는 가중치 전용 압축 모델을 지원했지만 iOS 17에서는 8비트 활성화 양자화 모델도 실행할 수 있습니다 iOS 16에서 가중치 압축 모델은 부동 가중치가 있는 해당 모델과 동일한 속도로 실행되는 반면 iOS 17에서는 Core ML 런타임이 업데이트되면서 이제 압축 모델이 특정 시나리오에서 더 빠르게 실행됩니다 macOS와 tvOS, watchOS의 최신 버전에서 유사한 런타임 개선 사항을 사용할 수 있습니다 이런 개선은 어떻게 이뤄질까요? 가중치만 압축되는 모델에서는 활성화가 부동 소수점 정밀도에 남아 있기 때문에 콘볼루션이나 행렬 곱셈 같은 연산이 발생하기 전에 다른 입력의 정밀도와 일치하도록 가중치값을 압축 해제 해야 합니다 이 압축 해제 단계는 iOS 16 런타임에서 미리 수행됩니다 따라서 이런 경우 모델이 실행되기 전에 메모리에서 완전 부동 정밀도 모델로 변환되고 추론 지연 시간에 변화를 관찰할 수 없겠죠 하지만 iOS 17에서는 특정 시나리오에서 작업이 실행되기 직전에 가중치가 때맞춰 압축이 해제됩니다 덕분에 모든 추론 호출에서 압축 해제를 수행하는 대신 메모리에서 더 작은 비트 가중치를 로딩한다는 이점이 있죠 Neural Engine 같은 컴퓨팅 유닛과 메모리에 바인딩된 모델의 경우 추론이 향상될 수 있습니다 이런 런타임의 이점을 설명하려고 몇 가지 모델을 선택해 프로파일링하고 float16 변형과 비교해서 추론 속도가 빨라지는 상대적인 양을 그래프로 표시해 봤어요 예상대로 속도의 향상 정도는 모델과 하드웨어에 따라 다릅니다 iPhone 14 Pro Max에서 4비트 팔레트화 모델의 속도 향상 범위인데요 향상 정도는 5-30% 사이로 다양합니다 희소 모델도 유형에 따라 향상 정도가 다양한데 float16 변형보다 75% 빠르게 실행되는 모델도 더러 있습니다 그렇다면 어떻게 해야 최고의 지연 성능을 얻을 수 있을까요? 부동 모델로 시작해서 optimize.coreml API를 사용해 모델의 다양한 표현을 탐색하면 됩니다 작업 속도가 빠르겠죠 모델을 재훈련할 필요가 없으니까요 이후 관심 있는 기기에 프로파일링하세요 Xcode의 Core ML 성능 보고서를 활용하면 작업 실행 위치를 비롯해 추론에 대한 통찰력을 얻을 수 있습니다 이후 어떤 구성이 가장 유용한지 최종 목록을 작성하세요 이제 정확도를 평가하고 개선하는 데 집중할 수 있습니다 이때 필요하다면 모델을 마무리하기 전에 토치와 Core ML Tools로 훈련 시간 압축을 적용해 볼 수 있겠죠
배운 내용을 정리해 봅시다 새 Core ML Tools API를 사용하면 모델의 크기를 줄이는 중요한 작업을 아주 손쉽게 수행해서 메모리 풋프린트를 줄이고 추론 속도를 높일 수 있습니다 더 많은 옵션과 벤치마킹 데이터를 확인해 보고 싶다면 Apple 문서를 참고하세요 추천할 만한 세션으로는 '비동기 예측으로 Core ML 통합 개선하기'가 있어요 오늘 슬라이드에서 다루지 않았던 Core ML 프레임워크의 개선 사항을 소개하는 세션입니다 감사합니다 즐겁게 압축해 보세요
-