-
기기 내 음성 인식을 사용자화하기
기본 모델에 어휘를 추가하는 사용자화로 앱의 기기 내 음성 인식을 개선하는 방법을 알아보세요. 기기 내에서 음성 인식이 작동하는 방식과 전사의 예측 가능도가 높아지게 특정 단어와 어구를 부스팅하는 방법, 템플릿 지원을 사용해 사용자 지정 어구의 전체 집합을 빠르게 생성하는 방법을 알려 드리겠습니다. 모두 런타임에서 이뤄지죠. Speech 프레임워크를 더 알아보려면 WWDC19의 '음성 인식 개선 사항' 세션을 확인하세요.
리소스
관련 비디오
WWDC19
-
비디오 검색…
♪ ♪
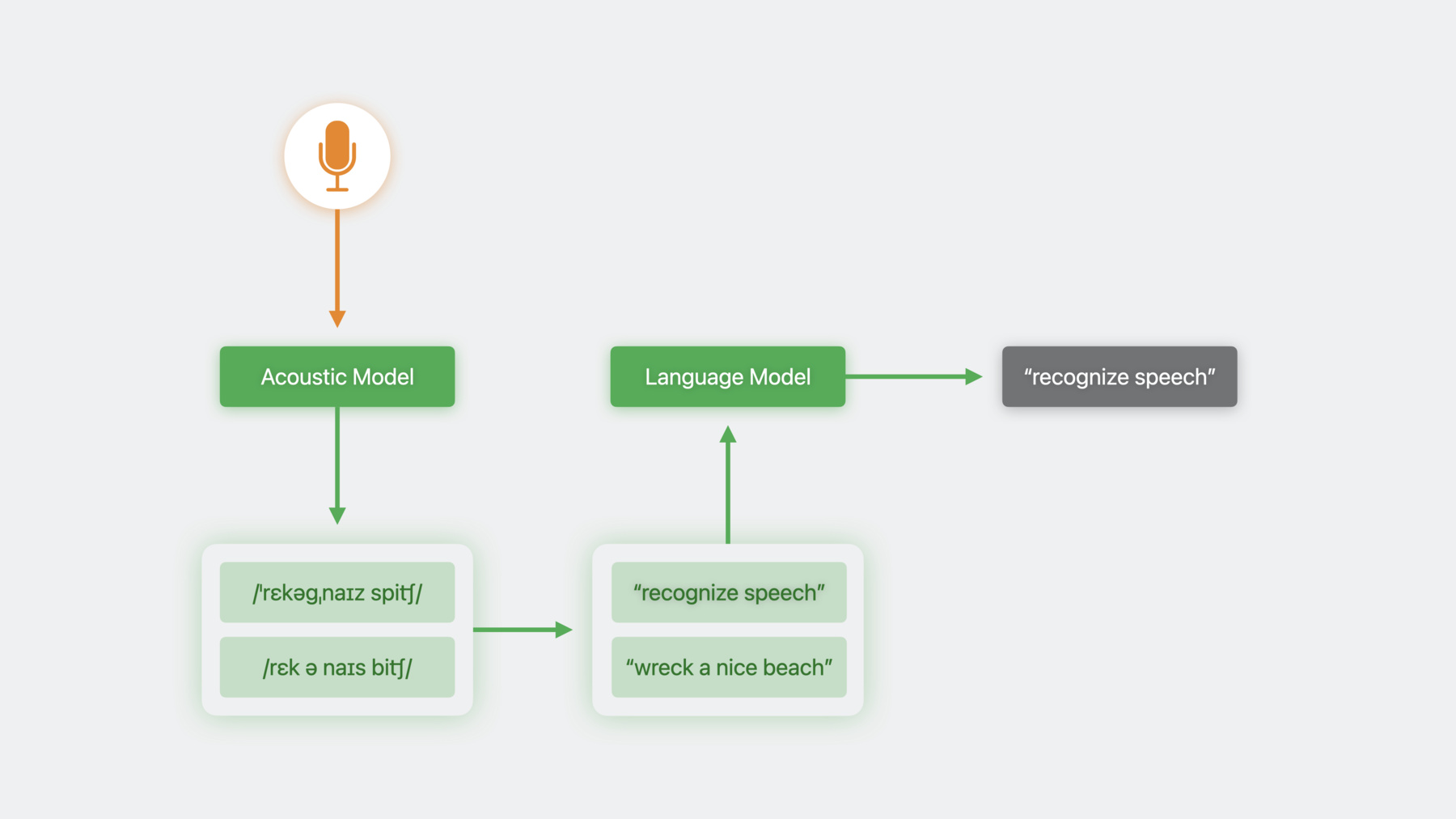
안녕하세요 저는 이선입니다 Siri Understanding 팀 소속이죠 이번 세션에서는 음성 인식의 흥미로운 개선 사항을 몇 가지 말씀드리겠습니다 iOS 10에서는 Speech 프레임워크를 도입했습니다 그래서 Siri와 키보드 받아쓰기를 구현한 기술을 동일하게 사용해서 음성 활성화 앱을 단순하고 직관적인 인터페이스로 만들 수 있었죠 하지만 음성 인식기 클래스는 모든 앱에서 바로 쓰기에 적합하지 않습니다 음성 인식의 작동 방식을 통해 이유를 알아봅시다 먼저 음성 인식 시스템에서 오디오 데이터를 음향 모델에 주면 발음 표기가 생성됩니다 이 발음 표기는 문자 형태인 전사문으로 변환되죠 오디오 데이터에 맞는 발음 표기가 복수인 경우도 있습니다 단일한 발음 표기가 여러 전사문에 대응할 수도 있고요 이런 케이스에서는 후보 전사문이 여러 개 나와서 명확화할 방법이 필요해집니다 이를 위해 저희는 언어 모델이라는 걸 사용합니다 언어 모델은 주어진 단어가 단어 시퀀스에서 다음에 올 가능도를 예측합니다 전체 문장에 적용하면 문장이 엉터리일지를 감지할 수 있습니다 언어 모델 덕분에 가능도가 낮은 후보는 거부됩니다 훈련 중 모델에 노출된 사용 패턴에 기반해서요 iOS 10 이후로 Speech 프레임워크는 사용이 간단한 인터페이스를 위해 이 과정 전체를 캡슐화했습니다 이게 최적이 아닐 수 있는 이유를 예시와 함께 살펴봅시다 저는 체스를 좋아해서 체스 앱을 작업했는데요 사용자가 개별 움직임은 물론이고 일반적인 오프닝과 디펜스 수도 지시하게 했습니다 여기서 상대는 퀸스 갬빗이라는 고전적인 수를 뒀습니다 저는 고민 끝에 E5로 응수하기로 합니다 앨빈 카운터 갬빗이죠
'앨빈 카운터 갬빗을 플레이해'
문제가 있군요 제가 체스에서 두려는 수를 인식기가 음악 재생 요청으로 이해했습니다 인식기가 사용하는 언어 모델은 훈련 과정에서 음악 재생 요청에 많이 노출되었기 때문에 앨범 이름이 따라오는 '앨범을 재생해' 같은 쿼리에는 준비가 되어 있습니다 반면 제가 선호하는 말의 전사문은 접한 적이 없나 봅니다 언어 모델의 동작을 추출하는 방식으로 Speech 프레임워크는 모든 앱에 같은 모델 사용을 강제합니다 도메인이 다르면 동작도 달라야 하는데도요 iOS 17부터는 SFSpeechRecognizer에서 언어 모델의 동작을 사용자화하고 응용 프로그램에 맞춰 정확도를 개선할 수 있습니다
언어 모델 사용자화를 시작하려면 훈련 데이터의 컬렉션을 먼저 만듭니다 이 작업은 개발 과정에서 할 수 있죠 다음으로는 앱에서 데이터를 준비하고 인식 요청을 설정한 다음 이를 실행합니다
훈련 데이터 컬렉션 빌드 과정을 이야기해 봅시다 고수준의 훈련 데이터는 텍스트 비트로 구성됩니다 앱 사용자들이 말할 법한 어구를 나타내는 비트죠 모델은 이런 어구를 예상하도록 학습하게 되니 이 어구가 올바르게 인식될 가능도가 높아집니다 종종 실험해 보세요 인식기의 뛰어난 기능과 갈수록 발전하는 모습이 아주 놀랍답니다 Speech 프레임워크는 훈련 데이터의 컨테이너가 될 새로운 클래스를 도입합니다 결과 빌더 DSL로 빌드된 클래스죠 정확한 어구나 어구의 일부를 PhraseCount 객체로 제공합니다 PhraseCount는 최종 데이터 집합에 샘플이 몇 번이나 보여야 하는지도 설명합니다 이걸 사용해서 특정 어구에 가중치를 더 실을 수 있죠 시스템이 받을 수 있는 데이터의 양은 한정적이니 전체 훈련 데이터 예산에 맞게 어구 부스팅의 필요를 조절하세요 템플릿으로 정규 패턴에 맞는 샘플을 다수 생성할 수도 있습니다 여기서는 합치면 체스 수가 되는 단어 세 클래스를 정의했습니다 움직일 piece는 타깃팅할 파일 역할을 겸하고 royal piece는 플레이할 편을 정의합니다 rank는 움직일 지점이죠 이걸 패턴으로 합치면 가능한 수를 모두 나타내는 샘플 데이터가 쉽게 생성됩니다 여기서는 count가 템플릿 전체에 적용되니 체스 수를 나타내는 샘플을 1만 개 얻게 됩니다 모든 샘플 결과 데이터에 고루 배분된 상태로요 데이터 객체를 다 빌드하면 이걸 파일로 내보낸 다음 다른 에셋과 마찬가지로 앱에 배포합니다
앱에서 전문 용어가 쓰일 수도 있을 텐데요 가령 의약품 명칭이 들어가는 의료 앱이라면 그런 용어의 철자와 발음을 모두 정의하고 용법을 보여 주는 어구 count를 제공할 수 있습니다 발음은 X-SAMPA 문자열 형태로 수신됩니다 각 로케일은 발음 기호의 고유한 부분집합을 지원하죠 전체 로케일과 지원되는 기호에 대해서는 문서를 참고하세요 제 앱에서 인식기에 이해시키고 싶은 것은 프렌치 디펜스의 흔한 변형인 위나워 베리에이션인데요 이 로케일에서 지원되는 X-SAMPA 기호의 부분집합으로 발음을 나타냅니다 앱이 런타임 중 접근하는 데이터도 같은 API로 훈련할 수 있습니다 이걸로 사용자 특유의 사용 패턴을 지원해서 사용자가 배우고자 하는 체스 오프닝과 디펜스에 초점을 맞출 수도 있겠네요 명명된 엔티티를 훈련하려 할 수도 있겠죠 사용자의 연락처에 대해 네트워크 플레이를 지원하거나요 늘 그랬듯 사용자의 프라이버시는 최우선 고려 대상입니다 커뮤니케이션 앱을 예로 들면 커맨드를 부스팅해서 통화 기록에 나오는 빈도를 근거로 연락처를 호출하려 할 수 있는데요 이런 유형의 정보는 기기에 항상 남아 있어야 합니다 데이터 객체를 생성하려면 앱에서 같은 메서드를 호출해서 이를 파일로 작성하고 앞서 보신 대로 수집하면 됩니다
생성된 훈련 데이터는 단일 로케일에 묶이는데요 단일 스크립트에 다중 로케일을 지원하려면 표준 현지화 기능을 사용하면 됩니다 NSLocalizedString 등이 있죠 이제 모델을 앱에 배포하는 이야기를 해 봅시다 prepareCustomLanguageModel이라는 새로운 메서드를 우선 호출합니다 앞 단계에서 생성한 파일을 받아서 나중에 사용할 새로운 파일 두 개를 만들어 주죠 이 메서드 호출에서는 연동 지연이 다량 발생할 수 있으니 메인 스레드 밖에서 호출하는 것이 좋습니다 로딩 스크린 같은 UI 뒤에 지연을 숨기고요 데이터가 생성된 기기에 데이터를 보관해야만 사용자 프라이버시를 존중할 수 있는 경우도 있습니다 언어 모델 사용자화는 이를 지원하고자 사용자화 데이터를 절대 네트워크에 보내지 않습니다 사용자화된 요청은 오직 기기에서만 서비스됩니다 앱이 음성 인식 요청을 구성하면 해당 인식이 기기에서 실행되도록 먼저 강제해야 합니다 이렇게 하지 못하면 요청은 사용자화 없이 서비스됩니다 이어서 요청 객체에 언어 모델을 붙입니다 이제 언어 모델 사용자화가 앱에서 켜졌습니다 '앨빈 카운터 갬빗을 플레이해' 제가 지정한 용어가 잘 작동하네요 '위나워 베리에이션을 플레이해'
언어 모델을 사용자화해서 제 응용 프로그램의 도메인에 인식기를 맞추고 동작 방식을 어느 정도 제어하게 되었습니다 무엇보다 중요한 건 앱의 음성 인식 정확도를 개선했다는 점이죠 더 많은 앱과 사용자에 맞춰 Speech 프레임워크가 조정되니 한층 강력해진 프레임워크로 더 멋진 경험을 만들 수 있습니다 언어 모델을 사용자화하면 음성 인식기가 강화되고 앱 사용자화가 가능해집니다 여러분이 이걸로 이뤄 낼 놀라운 결과물이 너무나 기대됩니다 감사합니다 핵심에 집중하는 걸 잊지 마세요 ♪ ♪
-