-
음성 처리의 새로운 기능
Apple 음성 처리 API를 사용하여 VoIP(Voice over Internet Protocol) 앱에서 최상의 오디오 경험을 확보하는 방법을 알아보세요. 음소거 상태에서 이야기하는 사람을 감지하고 다른 오디오의 더킹을 조절하는 방법 등을 알려드립니다.
챕터
- 0:00 - Introduction
- 3:19 - Other audio ducking
- 7:55 - Muted talker detection
- 11:37 - Muted talker detection for macOS
리소스
관련 비디오
WWDC23
-
비디오 검색…
♪ ♪
'음성 처리의 새 기능' 세션에 오신 걸 환영합니다 저는 Core Audio 팀의 줄리언입니다 VoIP(Voice over IP) 응용 프로그램은 어느 때보다 중요해졌습니다 동료, 가족, 친구와 관계를 유지할 수 있게 도와주니까요 음성 채팅의 오디오 음질은 뛰어난 사용자 경험을 제공하는 데 중요한 역할을 합니다 어떤 상황에서든 좋은 음질을 유지하도록 오디오를 처리하는것은 중요하고도 어렵습니다 그래서 Apple은 음성 처리 API를 제공하여 모든 사람이 앱에서 채팅할 때 항상 최상의 오디오 경험을 누릴 수 있게 합니다 어떤 종류의 음향 환경이든 어떤 Apple 제품을 사용하든 어떤 오디오 액세서리가 연결되든지요 Apple의 음성 처리 API는 많은 앱이 널리 사용하고 있죠 저희의 FaceTime과 Phone 앱을 포함해서요 동급 최고의 오디오 신호 처리를 제공합니다 특히 에코 캔슬링, 노이즈 억제 자동 이득 제어 등으로 음성 채팅 오디오를 향상합니다 각 Apple 제품의 음향 엔지니어들이 오디오 기기 유형에 따라 최고의 성능을 내도록 조정한 것입니다 각각의 고유한 음향 특성에 맞게요 또한 Apple의 음성 처리 API를 채택하면 사용자가 앱의 마이크 모드 설정을 완전히 제어할 수 있습니다 마이크 모드에는 표준, 음성 분리 와이드 스펙트럼이 있죠 Apple의 음성 처리 API를 사용하기 좋은 곳은 VoIP 응용 프로그램입니다 Apple의 음성 처리 API에는 두 가지가 있습니다 하나는 AUVoiceIO라고 하는 I/O 오디오 유닛입니다 AUVoiceProcessingIO라고도 하죠 I/O 오디오 유닛과 직접 상호작용하고 싶을 때 씁니다
다른 하나는 AVAudioEngine이죠 좀 더 정확하게는 AVAudioEngine의 '음성 처리' 모드를 활성화하는 겁니다
AVAudioEngine은 상위 레벨 API로서 일반적으로 사용하기 더 쉽고 오디오 작업을 할 때 짜야 하는 코드의 양을 줄여 줍니다 두 API 모두 동일한 음성 처리 기능을 제공합니다 이제 새로운 기능입니다 음성 처리 API를 tvOS에서도 처음으로 쓸 수 있게 됐습니다 이에 대해 더 자세한 사항을 알고 싶다면 'tVOS의 연속성 카메라 알아보기' 세션을 보시면 됩니다 또한 새 API 두 개를 AUVoiceIO와 AVAudioEngine에 추가하여 음성 처리를 더 잘 제어할 수 있게 하고 새로운 기능 구현이 가능하도록 했습니다
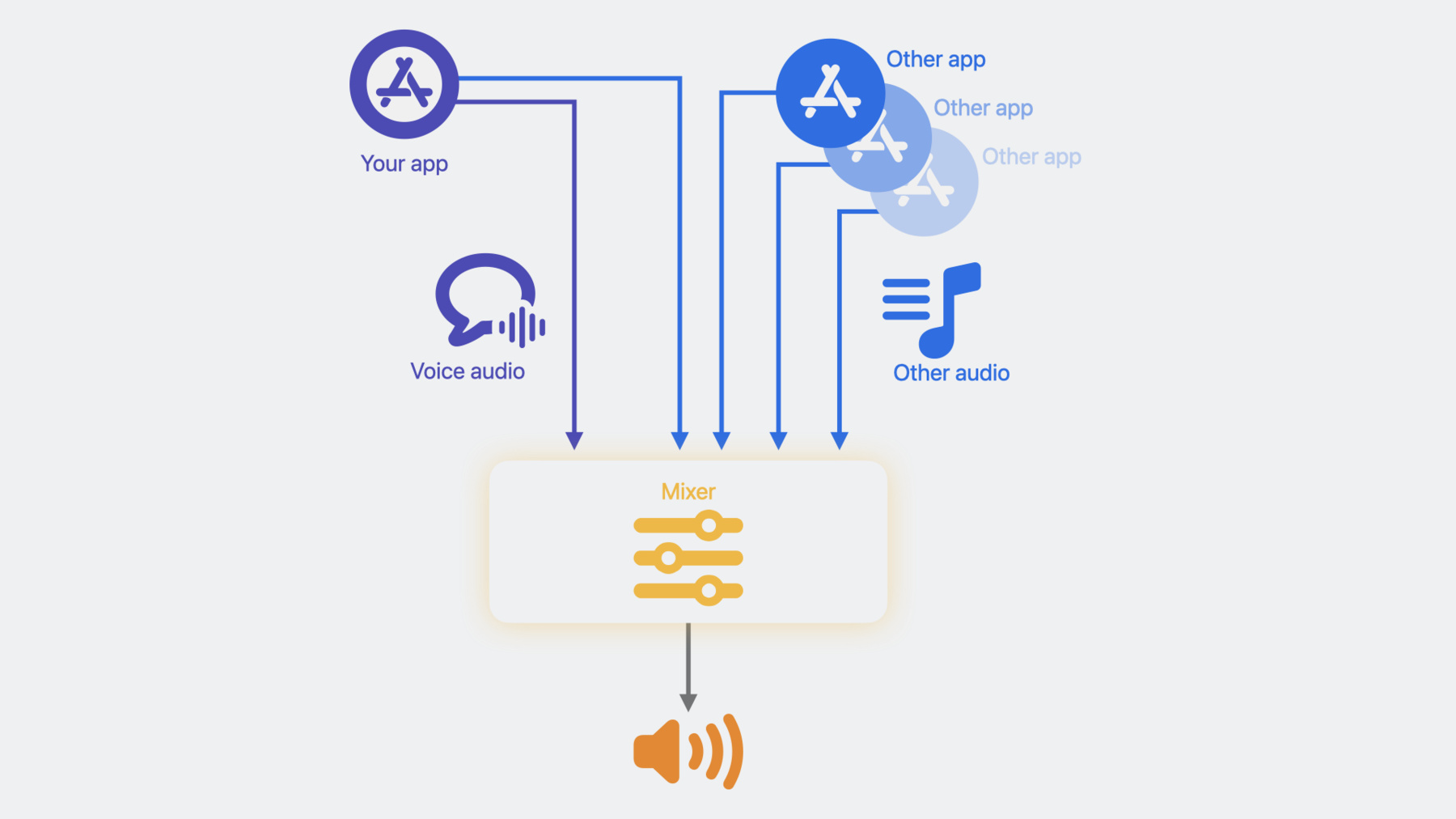
첫 번째 API는 다른 오디오의 더킹 동작을 돕습니다 이게 무슨 의미인지는 잠시 후에 설명하겠습니다 두 번째 API는 앱이 음소거된 화자 감지 기능을 구현할 수 있게 합니다 이 세션에서는 이 새 API들을 중점적으로 알아볼 것입니다 첫 번째 API는 바로 '다른 오디오 더킹'입니다 이 API를 알아보기 전에 먼저 '다른 오디오'란 무엇이며 왜 더킹이 중요한지 설명해 드리죠 Apple의 음성 처리 API를 사용한다면 오디오 재생을 할 때 어떻게 되는지 보겠습니다 여러분의 앱은 Apple의 음성 처리를 거친 음성 채팅 오디오 스트림을 제공하고 출력 기기로 재생합니다 하지만 다른 오디오 스트림도 동시에 재생될 수 있죠 예를 들어, 여러분 앱이 음성 처리 API를 거치지 않은 또 다른 오디오 스트림을 재생할 수 있습니다
여러분 앱과 동시에 오디오를 재생하는 다른 앱도 있을 수 있죠 여러분 앱의 음성 오디오 스트림 외에 다른 모든 오디오 스트림이 Apple의 음성 처리에서는 '다른 오디오'로 간주됩니다 여러분의 음성 오디오가 다른 오디오와 섞여 있는 거죠 출력 기기로 재생되기 전에는요 음성 채팅 앱이 일반적으로 오디오 재생에서 제일 중점을 두는 것은 음성 채팅 오디오입니다 그래서 다른 오디오의 볼륨 레벨을 더킹해서 음성 오디오의 명료도를 향상하는 거죠 예전에는 다른 오디오를 더킹하는 양을 동일하게 적용했죠 대부분의 앱에서 잘 작동하기 때문에 현재의 더킹으로도 여러분의 앱에 문제가 없다면 그냥 그대로 두시면 됩니다 하지만 어떤 앱은 더킹 동작을 더 제어하는 것이 필요한 경우도 있는데요 이 API는 바로 그런 것을 도와줄 것입니다
먼저 AUVoiceIO에 적용하는 것을 보여드리고 나서 AVAudioEngine으로 넘어가겠습니다 AUVoiceIO에서는 이것이 다른 오디오 더킹 구성의 구조체죠 이것은 더킹의 두 가지 독립적인 측면을 제어합니다 더킹의 스타일, 즉 mEnableAdvancedDucking과 더킹의 양, 즉 mDuckingLevel이 바로 그것입니다 mEnableAdvancedDucking은 기본적으로 비활성화돼 있습니다 활성화되면 더킹 레벨을 동적으로 조절합니다 채팅 참여자 양쪽의 음성 활동 유무에 따라서요 그러니까 양쪽 사용자가 말할 때는 더킹이 더 많이 적용되는 거죠 어느 쪽도 말하지 않을 때는 더킹을 줄이고요 FaceTime SharePlay에서 더킹되는 것과 매우 유사합니다 FaceTime에서 누구도 말을 안 하면 미디어 재생 볼륨이 높아지죠 하지만 누구든 말을 시작하면 미디어 재생 볼륨이 줄어듭니다
다음은 mDuckingLevel입니다 여기엔 네 가지 컨트롤 레벨이 있죠 기본(Default), 최소(Min) 중간(Mid), 최대(Max)입니다 기본(Default) 더킹 레벨에서는 기존처럼 같은 양의 더킹이 적용되죠 이것은 계속 기본 설정으로 유지됩니다 최소(Min) 더킹 레벨은 적용하는 더킹의 양을 최소화하죠 다시 말해 이 설정은 다른 오디오의 볼륨을 최대한 키우고 싶을 때 씁니다 마찬가지로 최대(Max) 더킹 레벨은 적용하는 더킹의 양을 최대화하죠 일반적으로 더 높은 더킹 레벨을 선택하면 음성 채팅의 명료도를 향상하는 데 도움을 줍니다
두 컨트롤은 독립적으로 사용할 수 있습니다 결합해서 사용하면 더킹 동작을 자유자재로 제어할 수 있을 것입니다
지금까지 더킹 구성을 살펴봤는데요 여러분의 앱에 적합한 더킹을 만들 수 있을 것입니다 예제를 하나 보겠습니다 고급 더킹을 설정해 보죠 더킹 레벨을 최소로 선택합니다
그런 다음 이 더킹 구성을 AUVoiceIO에 적용합니다 kAUVoiceIOProperty_OtherAudio DuckingConfiguration을 통해서요
AVAudioEngine을 쓸 때에도 API는 매우 비슷합니다 다른 오디오 더킹 구성의 구조체는 이렇게 정의합니다 더킹 레벨의 enum은 이렇게 정의합니다
이 API를 AVAudioEngine에 사용하려면 먼저 엔진의 입력 노드에서 음성 처리를 활성화합니다
그런 다음 더킹 구성을 설정합니다
마지막으로 입력 노드에서 구성을 설정합니다 다음으로 여러분의 앱에 매우 유용한 기능을 구현하게 해 줄 다른 API를 보죠 온라인 회의에서 이런 상황을 겪어 보셨을 겁니다 동료나 친구와 이야기한다고 생각했는데 알고 보니 음소거 상태였던 겁니다 아무도 여러분의 명석한 지적이나 웃긴 얘기를 못 들은 거죠 네, 난처합니다 음소거된 화자 감지 기능이 있으면 정말 좋겠죠 FaceTime에서 이렇게 하는 것처럼요
그래서 저희는 음소거된 화자가 있음을 감지하는 API를 제공합니다 이는 iOS 15에 맨 처음 도입되었고 이제는 macOS 14과 tvOS 17에서도 사용할 수 있죠 이 API를 어떻게 사용하는지 전체적인 개요를 말씀드리죠 먼저, 리스너 블록을 AUVoiceIO나 AVAudioEngine에 보내야 합니다 음소거된 화자가 감지됐다는 알림을 받으려면요 여러분이 보내는 리스너 블록은 음소거된 화자가 말을 시작하거나 멈출 때마다 호출됩니다 그다음 그런 알림을 처리할 코드를 구현합니다 예를 들어 사용자가 음소거 상태에서 말을 시작했다는 알림을 받았다면 사용자에게 음소거를 해제하라는 메시지를 표시하고 싶을 수도 있죠 마지막으로 중요한 것은 음소거를 구현하는 겁니다 AUVoiceIO나 AVAudioEngine의 음소거 API를 통해서요
AUVoiceIO를 쓰는 코드 예제를 단계별로 설명해 드리죠 AVAudioEngine 예제도 이어서 살펴볼 겁니다 먼저, 알림을 처리할 리스너 블록을 준비합니다
블록에는 AUVoiceIOSpeech ActivityEvent 유형의 매개변수가 있죠 다음 두 가지 값을 가질 수 있습니다 SpeechActivityHasStarted 아니면 SpeechActivityHasEnded죠
리스너 블록이 호출되는 때는 음소거 중 음성 활동 이벤트에 변동이 생겼을 때입니다
블록 안의 이 부분이 이 이벤트를 처리하는 방법을 구현한 것입니다 예를 들어 SpeechActivityHasStarted라면 사용자에게 음소거를 해제하라는 메시지를 띄울 수 있겠죠 리스너 블록이 준비되면 AUVoiceIO에 등록해야 합니다 kAUVoiceIOProperty_MutedSpeech ActivityEventListener를 통해서요
사용자가 음소거하면 음소거의 구현은 음소거 API인 kAUVoiceIO Property_MuteOutput으로 합니다
여러분의 리스너 블록은 A, 사용자가 음소거 상태이고 B, 음성 활동 상태가 바뀔 때만 호출됩니다
음성 활동이 지속적으로 이뤄지거나 이뤄지지 않을 때는 불필요한 알림이 발생하지 않죠
AVAudioEngine을 쓸 때도 구현은 아주 비슷합니다 엔진의 입력 노드에서 음성 처리를 활성화한 후 알림을 처리할 리스너 블록을 준비합니다
그런 다음 입력 노드로 리스너 블록을 등록합니다
사용자가 음소거하면 AVAudioEngine의 음성처리 음소거 API로 음소거하죠
이제 음소거된 화자 감지 기능을 구현해 보겠습니다 AUVoiceIO 및 AVAudioEngine에서요 아직 Apple의 음성 처리 API를 채택할 준비가 안 된 분들에게는 이 기능을 구현할 수 있는 대안도 준비돼 있습니다
이 대안은 macOS상에서만 가능합니다 Core Audio HAL API 즉, 하드웨어 추상화 계층 API를 통해서요 음성 활동 감지를 돕는 두 가지 새 HAL 프로퍼티가 있는데 함께 사용됩니다 먼저, 입력 기기에서 음성 활동 감지를 활성화합니다 kAudioDeviceProperty VoiceActivityDetectionEnable로요 그런 다음 HAL 프로퍼티 리스너를 kAudioDevicePropertyVoiceActivity DetectionState에 등록하죠 이 HAL 프로퍼티 리스너는 음성 활동 상태가 변경될 때마다 호출됩니다 프로퍼티 리스너가 여러분의 앱에 알려주면 프로퍼티에 질의해서 현재 값을 얻습니다
몇 가지 코드 예제로 차근차근 설명해 드리죠
입력 기기에서 음성 활동 감지를 활성화하기 위해서 먼저 HAL 프로퍼티 주소를 구성합니다
그리고 입력 기기에 대해 프로퍼티를 설정하여 활성화합니다
다음으로 리스너를 음성 활동 감지 상태 프로퍼티에 등록하기 위해 HAL 프로퍼티 주소를 구성합니다 그런 다음 여러분의 프로퍼티 리스너를 넣어주죠
여기서 'listener_callback'은 여러분의 리스너 함수 이름입니다
프로퍼티 리스너를 구현한 예를 보여드리겠습니다
리스너는 이런 함수 시그니처를 따릅니다
이 예제에서는 이 리스너가 하나의 HAL 프로퍼티에만 등록됩니다 이는 호출됐을 때 어떤 HAL 프로퍼티가 바뀌는지 모호하지 않다는 뜻입니다
같은 리스너를 하나 이상의 HAL 프로퍼티 알림에 등록하고 나면 먼저 inAddresses 배열을 확인해서 무엇이 변경됐는지 확인해야 합니다
이 알림을 처리하는 과정에서 VoiceActivityDetectionState 프로퍼티에 질의해 현재 값을 얻죠
그런 다음 그 값을 처리하는 여러분의 로직을 구현합니다
이런 음성 활동 감지 HAL API에는 몇 가지 중요한 세부 사항이 있죠 첫째, 음성 활동 감지는 에코 캔슬링 마이크 입력으로부터 합니다 그래서 음성 채팅 응용 프로그램에 쓰기 좋습니다
둘째, 감지는 프로세스 음소거 상태에 상관없이 작동합니다 음소거된 화자 감지 기능을 구현하기 위해서는 음성 활동 상태와 음소거 상태를 결합하는 추가 로직을 여러분의 앱이 구현할 수 있어야 합니다 HAL API를 써서 음소거를 구현하려면 HAL의 프로세스 음소거 API를 사용하시는 것이 좋습니다 메뉴 바에 녹화 표시등이 표시되지 않게 하여 음소거 상태에서 사용자의 사생활이 보호된다는 믿음을 주죠 이제까지 말씀드린 것을 정리해 보겠습니다 Apple의 음성 처리 API를 알아봤는데요 이것이 왜 VoIP 응용 프로그램에 쓰기 좋은지도 말씀드렸습니다 다른 오디오 더킹과 더킹 동작을 제어하는 API에 대해 알아봤고 AUVoiceIO와 AVAudioEngine에서 구현하는 코드 예제를 살펴봤죠 또한 음소거된 화자 감지를 구현하는 방법을 알아봤고 그것을 AUVoiceIO와 AVAudioEngine에서 구현해 봤죠 Apple의 음성 처리 API를 쓰지 않을 경우의 대안에 대해서도 설명했습니다 macOS에서 Core Audio HAL API를 사용하는 겁니다 Apple의 음성 처리 API를 사용한 여러분의 멋진 앱을 기대하겠습니다 시청해 주셔서 감사합니다 ♪ ♪
-
-
5:50 - Other audio ducking
// Insert code snipp297struct AUVoiceIOOtherAudioDuckingConfiguration { Boolean mEnableAdvancedDucking; AUVoiceIOOtherAudioDuckingLevel mDuckingLevel; };et. typedef CF_ENUM(UInt32, AUVoiceIOOtherAudioDuckingLevel) { kAUVoiceIOOtherAudioDuckingLevelDefault = 0, kAUVoiceIOOtherAudioDuckingLevelMin = 10, kAUVoiceIOOtherAudioDuckingLevelMid = 20, kAUVoiceIOOtherAudioDuckingLevelMax = 30 }; -
6:48 - Other audio ducking
const AUVoiceIOOtherAudioDuckingConfiguration duckingConfig = { .mEnableAdvancedDucking = true, .mDuckingLevel = AUVoiceIOOtherAudioDuckingLevel::kAUVoiceIOOtherAudioDuckingLevelMin }; // AUVoiceIO creation code omitted OSStatus err = AudioUnitSetProperty(auVoiceIO, kAUVoiceIOProperty_OtherAudioDuckingConfiguration, kAudioUnitScope_Global, 0, &duckingConfig, sizeof(duckingConfig)); -
6:50 - Other audio ducking
const AUVoiceIOOtherAudioDuckingConfiguration duckingConfig = { .mEnableAdvancedDucking = true, .mDuckingLevel = AUVoiceIOOtherAudioDuckingLevel::kAUVoiceIOOtherAudioDuckingLevelMin }; // AUVoiceIO creation code omitted OSStatus err = AudioUnitSetProperty(auVoiceIO, kAUVoiceIOProperty_OtherAudioDuckingConfiguration, kAudioUnitScope_Global, 0, &duckingConfig, sizeof(duckingConfig)); -
7:20 - Other audio ducking
public struct AVAudioVoiceProcessingOtherAudioDuckingConfiguration { public var enableAdvancedDucking: ObjCBool public var duckingLevel: AVAudioVoiceProcessingOtherAudioDuckingConfiguration.Level } extension AVAudioVoiceProcessingOtherAudioDuckingConfiguration { public enum Level : Int, @unchecked Sendable { case `default` = 0 case min = 10 case mid = 20 case max = 30 } } -
7:31 - Other audio ducking
let engine = AVAudioEngine() let inputNode = engine.inputNode do { try inputNode.setVoiceProcessingEnabled(true) } catch { print("Could not enable voice processing \(error)") } let duckingConfig = AVAudioVoiceProcessingOtherAudioDuckingConfiguration(mEnableAdvancedDucking: false, mDuckingLevel: .max) inputNode.voiceProcessingOtherAudioDuckingConfiguration = duckingConfig -
7:32 - Muted talker detection AUVoiceIO
AUVoiceIOMutedSpeechActivityEventListener listener = ^(AUVoiceIOMutedSpeechActivityEvent event) { if (event == kAUVoiceIOSpeechActivityHasStarted) { // User has started talking while muted. Prompt the user to un-mute } else if (event == kAUVoiceIOSpeechActivityHasEnded) { // User has stopped talking while muted } }; OSStatus err = AudioUnitSetProperty(auVoiceIO, kAUVoiceIOProperty_MutedSpeechActivityEventListener, kAudioUnitScope_Global, 0, &listener, sizeof(AUVoiceIOMutedSpeechActivityEventListener)); // When user mutes UInt32 muteUplinkOutput = 1; result = AudioUnitSetProperty(auVoiceIO, kAUVoiceIOProperty_MuteOutput, kAudioUnitScope_Global, 0, &muteUplinkOutput, sizeof(muteUplinkOutput)); -
11:08 - Muted talker detection AVAudioEngine
let listener = { (event : AVAudioVoiceProcessingSpeechActivityEvent) in if (event == AVAudioVoiceProcessingSpeechActivityEvent.started) { // User has started talking while muted. Prompt the user to un-mute } else if (event == AVAudioVoiceProcessingSpeechActivityEvent.ended) { // User has stopped talking while muted } } inputNode.setMutedSpeechActivityEventListener(listener) // When user mutes inputNode.isVoiceProcessingInputMuted = true -
12:31 - Voice activity detection - implementation with HAL APIs
// Enable Voice Activity Detection on the input device const AudioObjectPropertyAddress kVoiceActivityDetectionEnable{ kAudioDevicePropertyVoiceActivityDetectionEnable, kAudioDevicePropertyScopeInput, kAudioObjectPropertyElementMain }; OSStatus status = kAudioHardwareNoError; UInt32 shouldEnable = 1; status = AudioObjectSetPropertyData(deviceID, &kVoiceActivityDetectionEnable, 0, NULL, sizeof(UInt32), &shouldEnable); // Register a listener on the Voice Activity Detection State property const AudioObjectPropertyAddress kVoiceActivityDetectionState{ kAudioDevicePropertyVoiceActivityDetectionState, kAudioDevicePropertyScopeInput, kAudioObjectPropertyElementMain }; status = AudioObjectAddPropertyListener(deviceID, &kVoiceActivityDetectionState, (AudioObjectPropertyListenerProc)listener_callback, NULL); // “listener_callback” is the name of your listener function -
13:13 - Voice activity detection - listener_callback implementation
OSStatus listener_callback( AudioObjectID inObjectID, UInt32 inNumberAddresses, const AudioObjectPropertyAddress* __nullable inAddresses, void* __nullable inClientData) { // Assuming this is the only property we are listening for, therefore no need to go through inAddresses UInt32 voiceDetected = 0; UInt32 propertySize = sizeof(UInt32); OSStatus status = AudioObjectGetPropertyData(inObjectID, &kVoiceActivityState, 0, NULL, &propertySize, &voiceDetected); if (kAudioHardwareNoError == status) { if (voiceDetected == 1) { // voice activity detected } else if (voiceDetected == 0) { // voice activity not detected } } return status; };
-