-
Core ML을 사용하여 머신 러닝 및 AI 모델을 온디바이스로 배포하기
Core ML로 머신 러닝 및 AI 모델을 변환하고 실행할 때 속도와 메모리 성능을 최적화하는 방법을 알아보세요. 모델 표현, 성능 관련 인사이트, 실행, 모델 스티칭 등을 위한 새로운 옵션을 소개합니다. 매력적인 비공개 온디바이스 경험을 만들 때 이러한 옵션들을 함께 사용해 보세요.
챕터
- 0:00 - Introduction
- 1:07 - Integration
- 3:29 - MLTensor
- 8:30 - Models with state
- 12:33 - Multifunction models
- 15:27 - Performance tools
리소스
관련 비디오
WWDC23
-
비디오 검색…
안녕하세요, Core ML 팀 엔지니어 Joshua Newnham입니다 오늘은 Core ML의 새로운 기능을 소개하고 기기에서 머신 러닝과 AI 모델을 효율적으로 배포 및 실행하는 방법을 설명하겠습니다
AI 모델을 온디바이스로 실행하면 여러 흥미로운 가능성을 확인할 수 있습니다 새로운 형태의 상호작용이나 강력한 전문 도구를 제작하고 건강 및 피트니스 데이터에서 통찰력 있는 분석을 얻으면서 동시에 개인정보 데이터는 안전하게 보호할 수 있습니다
수많은 앱이 Core ML을 사용하여 온디바이스 머신 러닝 기반의 멋진 경험을 제작했습니다 여러분도 가능합니다!
이 비디오에서는 먼저 모델 배포 작업 흐름에서 Core ML의 역할을 검토해 보겠습니다 그런 다음 몇 가지 기능 중 먼저 모델 통합을 단순화하는 새로운 유형인 MLTensor에 대해 알아보겠습니다 상태를 사용하여 모델 추론 효율을 향상하는 방법도 알아보려 합니다 그 다음에는 배포 효율성을 높이는 다중 함수 모델을 소개하겠습니다 마지막으로 Core ML 성능 도구의 업데이트를 살펴봄으로써 모델 프로파일링과 디버깅에 도움을 드리겠습니다 시작하겠습니다
머신 러닝 작업 흐름은 3단계로 구성됩니다 즉, 모델 학습, 모델 준비 모델 통합입니다 이 비디오에서는 온디바이스로 머신 러닝 및 AI 모델을 통합하고 실행하는 과정에 집중하겠습니다 모델 학습에 대해 알아보려면 올해 WWDC 비디오 중에서 ‘Apple GPU에서 머신 러닝 및 AI 모델 학습시키기’를 시청하세요 또한 모델을 변환하고 최적화하는 방법을 알아보려면 올해의 비디오 ‘머신 러닝 및 AI 모델을 Apple Silicon으로 가져오기’를 시청하세요
모델 통합은 ML 패키지에서 시작됩니다 사전 준비 단계에서 생성되는 아티팩트입니다 여기에서 Core ML을 사용하면 앱에 이 모델을 손쉽게 통합하고 사용할 수 있습니다
Xcode와 긴밀하게 통합되어 있으며 다양한 머신 러닝 및 AI 모델 유형에서 온디바이스 추론을 수행할 수 있는 통합 API를 제공합니다
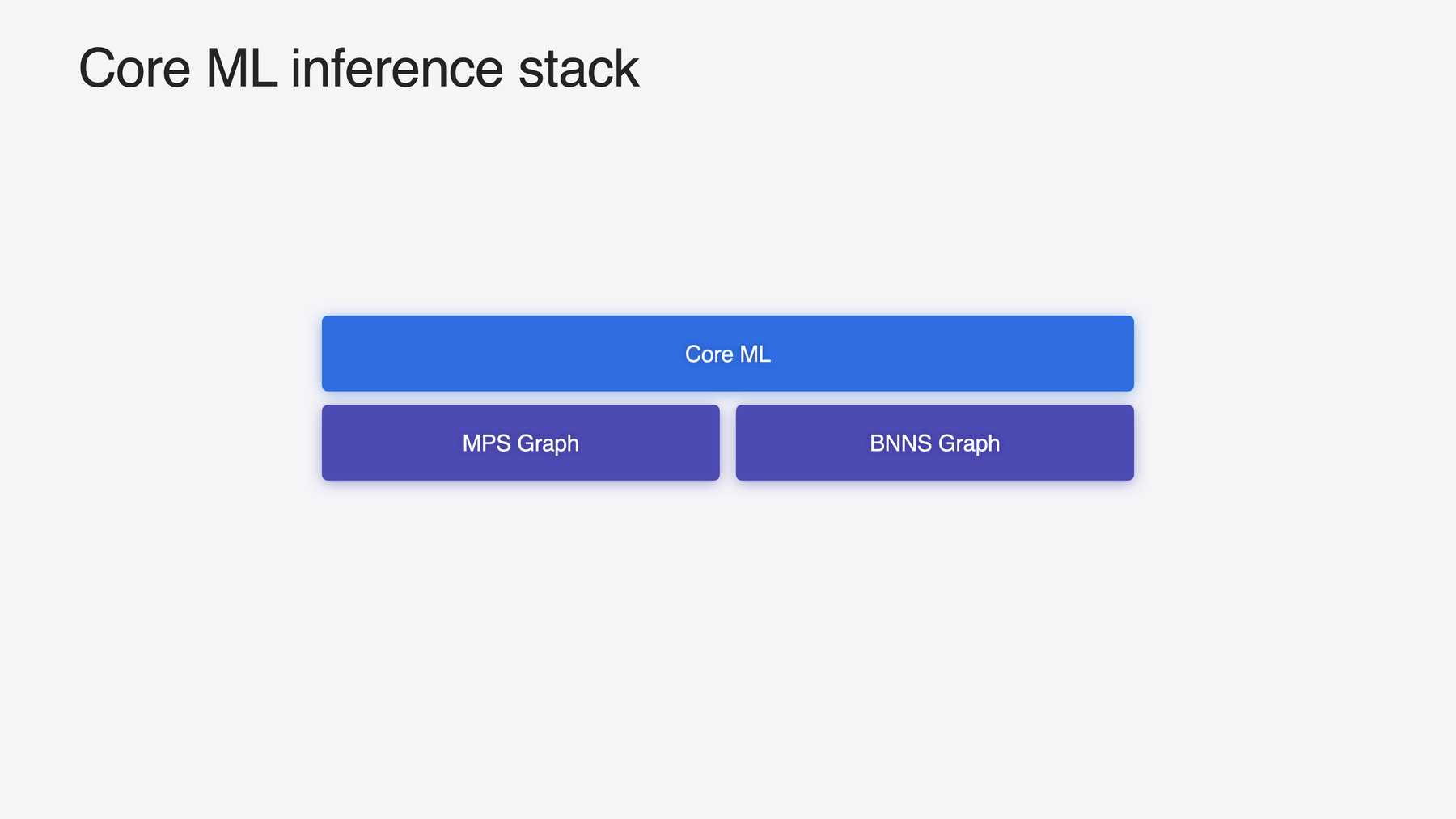
모델은 Apple Silicon의 강력한 컴퓨팅 기능을 활용하고 CPU, GPU, Neural Engine에 작업을 배정하며 실행됩니다 이 과정에서 MPS Graph와 BNNS Graph를 활용합니다 두 요소 또한 머신 러닝 프레임워크이며 Core ML 모델을 사용할 수 있습니다 Metal과 긴밀하게 통합해야 하거나 CPU에서 실시간 추론을 수행해야 할 때 가장 적합하죠 자세히 알아보려면 관련 비디오를 살펴보세요 추론 스택이 많이 개선되어 Core ML은 올해 성능이 더욱 향상되었습니다
예를 들어 iOS 17과 18의 상대적인 예측 시간을 비교해 보면 많은 모델이 iOS 18에서 더 빠르게 실행되는 모습을 볼 것입니다 이는 OS에 의한 속도 향상으로 모델을 다시 컴파일하거나 코드를 수정하지 않아도 됩니다 다른 기기에서도 마찬가지입니다만 모델과 하드웨어에 따라 속도 향상 수준은 다를 수 있습니다
모델 변환을 완료했으니 효율적으로 통합하고 실행하는 방법을 살펴볼 차례입니다
앱에 모델을 통합하려면 단순하게 필요한 값을 입력받고 반환되는 출력값을 읽으면 됩니다
하지만 고급 사용 사례일수록 복잡성은 빠르게 커집니다 예를 들어 생성형 AI는 반복 작업이 많고 여러 모델을 활용하기도 합니다
이러한 사용 사례에서는 모델 외부에서의 계산 과정이 종단간 파이프라인을 잇는 중간 접착제의 역할을 합니다 이러한 계산 과정은 연산을 처음부터 구현하거나 다양한 하위 수준 API를 사용하며 두 방법 모두 코드가 길고 복잡해집니다 지금까지는 말이죠
Core ML의 새로운 유형인 MLTensor를 소개합니다 이러한 계산 과정을 편리하고 효율적으로 처리할 수 있는 유형입니다
MLTensor는 머신 러닝 프레임워크에서 흔히 사용되는 수학 연산과 변환 연산을 지원합니다
이러한 연산은 Apple Silicon의 강력한 컴퓨팅 기능을 활용하므로 높은 성능을 보장하며
널리 사용되는 Python의 숫자 라이브러리와 유사하므로 사용하기 쉽고 직관적으로 이해할 수 있습니다 물론 이미 머신 러닝에 익숙해야 하지만 말이죠 몇 가지 예시를 통해 API를 자세히 살펴보겠습니다
먼저 텐서를 몇 개 생성합니다 텐서는 다양한 방법으로 생성할 수 있는데 두 가지 방법을 보여 드리겠습니다
MLShapedArray를 사용하는 방법과 중첩된 스칼라 컬렉션을 사용하는 방법입니다 MLShapedArray처럼 MLTensor는 다차원 배열이며 형상과 스칼라 유형으로 정의됩니다 형상은 각 축의 길이이며 스칼라 유형은 저장되는 요소의 유형입니다 텐서 생성 방법을 알았으니 텐서를 조작하는 방법을 몇 가지 살펴보겠습니다 기초 수학 연산부터 보겠습니다 텐서는 다양한 연산을 지원합니다 이 예에서는 요소별 덧셈과 곱셈을 수행한 다음 결과의 평균을 구합니다 텐서는 리터럴과 원활하게 작동하며 프레임워크가 호환되는 형상으로 자동으로 브로드캐스팅합니다 결과와 평균을 비교하여 불리언 표식을 할당하고 결과에 마스크를 곱해 값을 필터링합니다 마스크가 0인 값은 모두 0이 됩니다 이번에는 텐서를 인덱싱하고 형상을 변환하는 방법입니다 Python 숫자 라이브러리와 유사하게 텐서의 각 차원을 인덱싱하여 텐서를 슬라이싱할 수 있습니다 이 예에서는 행렬의 첫 번째 행만 가져온 다음 reshape 메서드를 사용해 다시 확장했습니다 모든 텐서 연산은 비동기적으로 배정됩니다 따라서 텐서는 MLShapedArray로 명시적으로 구체화해야만 저장된 데이터에 액세스할 수 있습니다 이렇게 해야 모든 업스트림 연산이 완료된 후 데이터를 사용할 수 있습니다
텐서를 생성하고 조작하는 방법을 살펴봤으니 더 흥미로운 작업을 해 보겠습니다 MLTensor가 어떻게 대형 언어 모델 통합을 단순화하는지 알아보겠습니다
먼저 예시 모델과 무엇이 출력되는지 보겠습니다 이 모델은 자기 회귀 언어 모델이며 선행 단어들의 맥락을 바탕으로 다음 단어 또는 토큰을 예측하도록 학습된 모델입니다
모델은 문장을 생성하기 위해 예측한 단어를 입력에 추가하며 시퀀스 종료 토큰을 감지하거나 일정 길이에 도달할 때까지 이 과정을 반복합니다 하지만 언어 모델은 단어 하나만 출력하는 게 아니라 어휘 내 모든 단어에 점수를 매겨 출력합니다 각 점수는 모델이 다음 단어로 예측한 확률을 나타냅니다
디코더는 이 점수를 사용해 다양한 전략을 바탕으로 다음 단어를 선택합니다 예를 들어 가장 점수가 높은 단어를 선택할 수도 있고 조정된 확률 분포에서 무작위로 샘플링할 수도 있습니다 디코딩 메서드는 따로 수정할 수 있어 모델과 별개로 이 과정이 처리되므로 이상적인 MLTensor용 모델입니다 몇 가지 디코딩 메서드를 구현한 것을 비교하여 MLTensor 도입 전후의 차이를 살펴보겠습니다
이 데모에서는 수정된 버전의 HuggingFace Swift Transformer 패키지와 Chat 앱을 사용하고 준비 비디오에서 변환하고 최적화한 Mistral7B 모델을 사용하겠습니다 디코더 구현을 비교하기 전에 모델이 작동하는 모습을 보겠습니다 슈퍼히어로 코기견에 관한 아동용 소설의 제목을 생성해 보겠습니다
나쁘지 않은 결과지만 더 창의적이면 좋겠네요 이 애플리케이션은 기본적으로 확률이 가장 높은 단어를 선택합니다 그리디 디코딩이라는 방법이죠
다른 디코딩 방법을 살펴보겠습니다
상위 K개 샘플링을 선택하면 애플리케이션이 확률이 가장 높은 K개 단어 중에서 무작위로 샘플링합니다 확률이 가장 높은 단어를 항상 선택하는 대신에 말이죠
가장 확률이 높은 단어들 중에서 무작위로 샘플링할 뿐 아니라 확률 분포에 변화를 주기 위해 온도를 조정할 수 있습니다 온도가 높을수록 고른 분포를 보이므로 더 창의적인 응답을 얻을 수 있고 반대로 온도가 낮을수록 출력을 예측하기 쉬워집니다
모델을 다시 실행해 보겠습니다 상위 K개 샘플링을 사용하며 온도를 1.8로 설정하겠습니다
좀 더 흥미로운 결과네요 두 가지 디코딩 메서드의 작동 결과를 봤으니 MLTensor 사용 유무에 따른 구현의 차이를 비교해 보겠습니다 구현한 코드를 비교해 보면 가장 놀라운 차이점은 같은 기능을 구현하는 것임에도 MLTensor를 사용하면 코드가 훨씬 짧아진다는 겁니다 MLTensor를 사용하지 않은 버전이 잘못되었다거나 하위 수준 API가 불필요하다는 건 아닙니다 오히려 이 코드는 제대로 작성된 성능이 뛰어난 코드이며 하위 수준 API가 필요한 경우도 많습니다 하지만 보통은 대부분의 머신 러닝 작업에서 MLTensor는 간결한 대안을 제공하며 하위 수준 디테일에 덜 신경 쓰면서 멋진 경험을 제작하는 데 집중할 수 있습니다 이전 섹션에서는 MLTensor가 어떻게 언어 모델의 출력 디코딩을 단순화하는지 살펴봤습니다 이번 섹션에서는 상태에 대해 알아보고 어떻게 활용하면 언어 모델에서 각 단어를 생성하는 데 걸리는 시간을 줄일 수 있는지 알아보겠습니다 먼저 상태가 무엇을 의미하는지부터 알아보겠습니다 지금까지는 대체로 상태 비저장 모델을 다루어 보셨을 겁니다 즉 각 입력을 독립적으로 처리하고 기록을 저장하지 않는 모델입니다 예를 들어 컨볼루션 신경망을 사용하는 이미지 분류기는 각 입력이 이전 입력과 독립적으로 처리되므로 상태 비저장입니다
스테이트풀 모델은 이와 다릅니다 짐작하셨겠지만 이전 입력의 기록을 유지합니다 시퀀스 데이터에 사용되는 순환 신경망 같은 아키텍처가 스테이트풀 모델의 예시입니다
지금까지의 스테이트풀 모델은 상태를 수동으로 관리하여 상태를 입력에 전달해야 했습니다 그런 다음 출력에서 업데이트된 상태를 다시 다음 예측에 사용하는 방식입니다 그러나 상태에 사용되는 데이터를 매번 로드하고 언로드하려면 오버헤드가 발생합니다 상태의 크기가 커지면 오버헤드도 눈에 띄게 커지죠
올해 Core ML은 스테이트풀 모델 지원이 강화되었습니다 상태를 수동으로 관리하는 대신 Core ML이 대신 처리하며 앞서 설명한 오버헤드를 줄여 줍니다 이제 상태를 사용하는 것이 이로운 모델 유형을 하나 살펴보겠습니다 이전 섹션에서 언어 모델이 어휘 내 모든 단어에 대해 점수를 매겨 출력한다고 말씀해 드렸습니다 여기서 점수는 모델이 해당 단어가 다음에 나올 것이라 생각하는 확률을 할당한 거죠 점수 외에도 모델은 해당 단어에 대한 키와 값 벡터도 출력합니다 벡터는 각 단어에 대해 계산되며 네트워크에 내장된 어텐션 메커니즘이 이를 활용하여 모델이 더욱 자연스럽고 맥락에 따른 연관성 있는 출력을 생성하는 데 사용됩니다 매번 이전 단계의 단어 벡터를 다시 계산할 필요가 없도록 저장되고 재사용되며 이를 키-값 캐시 또는 KV 캐시라고 합니다 이 캐시에 최신 기능을 사용해 보면 아주 좋겠네요, 한 번 보겠습니다
모델의 입력과 출력을 사용하여 KV 캐시를 처리하는 대신 이제 Core ML 상태를 활용하여 관리할 수 있습니다 이렇게 하면 오버헤드가 줄고 추론 효율성이 향상되므로 예측 시간이 단축됩니다
상태를 지원하려면 준비 단계에서 모델에 명시적으로 추가해야 한다는 점을 기억하세요 ‘머신 러닝 및 AI 모델을 Apple Silicon으로 가져오기’에서 어떻게 하는지 알아보세요
모델이 상태를 지원하는지 Xcode에서 간단하게 확인할 수 있습니다
상태를 지원한다면 모델 미리보기의 예측 탭에서 모델 입력 바로 위에 표시됩니다
이제 다음 단어 예측에 사용되는 코드를 수정하여 상태를 지원해 보겠습니다 먼저 상태 비저장 버전의 코드를 검토하며 수정이 필요한 곳을 찾아보죠 관련된 부분에만 집중해 보겠습니다 먼저 키와 값 벡터를 저장할 빈 캐시를 생성합니다
캐시는 모델에 입력으로 전달되고 모델에서 반환하는 값으로 캐시 값을 업데이트합니다 이제 상태를 지원하려면 필요한 변경 사항을 살펴보겠습니다
코드가 살짝 수정되었을 뿐 대부분은 그대로입니다
상태를 수동으로 사전에 할당하는 대신 모델 인스턴스로 상태를 생성합니다 이 예시에서는 Core ML이 버퍼를 사전에 할당하여 키와 값 벡터를 저장하고 상태의 핸들을 반환합니다 이 핸들을 사용하여 버퍼에 액세스하고 상태의 수명을 제어할 수 있습니다
각 캐시를 입력으로 전달하는 대신 이제 모델 인스턴스로 생성한 상태를 전달하기만 하면 됩니다 또한 그 안에서 알아서 업데이트되므로 캐시를 업데이트하는 마지막 단계를 생략할 수 있습니다 끝났습니다 상태를 지원하도록 코드를 수정하고 다음 단어를 예측하는 데 필요한 속도를 단축했습니다
KV 캐시 구현 방법 간 결과 차이를 보겠습니다 M3 Max 탑재 MacBook Pro에서 실행되는 Mistral7B 모델입니다 왼쪽은 상태를 사용하지 않고 구현한 KV 캐시이며 오른쪽은 상태를 사용합니다 오른쪽은 완료되는 데 5초 정도 걸린 반면 왼쪽은 대략 8초가 소요되었습니다 상태를 사용해 속도를 1.6배 향상했습니다 물론 성능은 모델과 하드웨어에 따라 달라집니다 하지만 이를 통해 상태를 사용하면 어떤 이점이 있는지 짐작할 수 있습니다
다음 섹션에서는 Core ML의 새로운 기능 중 여러 함수를 가진 모델을 유연하고 효율적으로 배포하는 방법을 살펴보겠습니다 머신 러닝 모델이라고 하면 일반적으로 무언가를 입력받아 무언가를 출력하는 함수처럼 작동하는 모습을 떠올리죠
실제로 Core ML에서 신경망은 함수로 표현됩니다 일반적으로 연산 블록이 담긴 하나의 함수로 구성됩니다 자연스럽게 여러 함수를 처리하도록 확장하는 걸 생각하게 되죠 이제 Core ML에서 지원하는 기능입니다 구체적인 예시를 통해 이 기능을 사용하여 여러 어댑터가 있는 모델을 효율적으로 배포해 보겠습니다
어댑터에 대해 설명하자면 기존 네트워크에 내장되며 다른 작업을 위한 지식이 학습되는 작은 모듈입니다 어댑터를 사용하면 대형 사전 학습 모델의 가중치를 조정하지 않고도 효율적으로 기능을 확장할 수 있습니다 이렇게 하면 기본 모델 하나를 여러 어댑터에서 공유할 수 있습니다 이 예시에서는 어댑터를 사용하여 잠재 확산 모델이 생성하는 이미지의 스타일에 영향을 주겠습니다
둘 이상의 스타일을 배포하고 싶다면 어떻게 할까요?
지금까지는 특수화된 모델을 어댑터당 하나씩 둘 이상 배포하거나 어댑터 가중치를 입력으로 전달해야 했습니다 둘 다 이상적인 방법은 아니죠
이제 다중 함수를 지원하므로 더 효율적인 방법이 있습니다
하나의 기본 모델을 공유하는 여러 어댑터를 병합하며 각 어댑터에 대한 함수를 노출할 수 있습니다
모델에서 여러 함수를 내보내는 방법을 알아보려면 ‘머신 러닝 및 AI 모델을 Apple Silicon으로 가져오기’를 시청하세요 모델에 특정 함수를 로드하는 코드를 살펴보겠습니다
다중 함수 모델을 로드하려면 함수 이름을 명시하기만 하면 됩니다
로드된 후에는 모델에서 예측을 호출하면 해당 함수를 호출하고 함수를 지정하지 않으면 기본 함수가 호출됩니다 어떻게 작동하는지 살펴보겠습니다
이 데모에서는 오픈 소스 Stable Diffusion XL 모델과 HuggingFace의 앱 Diffusers의 수정된 버전으로 텍스트에서 이미지를 생성하겠습니다 파이프라인은 여러 모델로 구성되며 MLTensor를 통해 매끄럽게 연결되어 있습니다 여기에는 서로 다른 어댑터를 사용하는 두 가지 함수를 가진 U-Net 모델이 포함되어 생성할 이미지의 스타일에 영향을 줄 수 있습니다 모델에서 사용할 수 있는 함수를 미리 살펴보려면 Xcode에서 열어 보면 됩니다
이 모델에는 두 함수 ‘sticker’ 및 ‘storybook’이 있네요 사용되는 입력과 출력이 동일하므로 두 함수에서 같은 파이프라인을 사용할 수 있습니다 반드시 그래야 하는 것은 아니고 각 함수에 사용되는 입력과 출력이 다를 수도 있습니다 앱으로 돌아와 슈퍼히어로 코기견의 스티커를 생성해 보겠습니다
훌륭하네요! 다른 함수로 바꿔 다른 스타일의 슈퍼히어로를 생성해 보겠습니다
멋지네요! 이 데모에서는 여러 어댑터를 가진 하나의 모델을 배포하여 각 함수를 통해 액세스하는 방법을 알아봤습니다 다양한 시나리오에서 사용할 수 있는 다재다능한 기능입니다 어떻게 활용하실지 기대되네요 이 마지막 섹션에서는 모델 프로파일링과 디버깅을 지원하는 몇 가지 개선 사항과 새로운 도구를 살펴보겠습니다 먼저 Core ML 성능 보고서가 개선되었습니다 성능 보고서는 모든 연결된 기기에서 코드를 작성하지 않아도 생성할 수 있습니다 Xcode에서 모델을 열고 성능 탭에서
더하기 버튼을 클릭하여
프로파일링할 기기와
컴퓨팅 기기를 선택하고 ‘Run Test’ 버튼을 클릭합니다
생성이 완료되면 보고서에서 로드 및 예측 시간의 요약과 함께 컴퓨팅 기기 사용량의 분석이 표시됩니다 올해부터 성능 보고서에서 더욱 많은 정보를 제공합니다 특히 추정 시간 그리고 각 연산에 대한 컴퓨팅 기기 지원 정보입니다 추정 시간은 각 연산에 걸린 시간을 보여 줍니다 예측 시간 중앙값에 각 연산에 대한 추정 상대 비용을 곱해 계산됩니다
네트워크의 병목 지점을 파악하는 데 도움이 됩니다 추정 시간을 바탕으로 연산을 정렬하면 파악할 수 있죠
또한 이제 지원되지 않은 연산 위에 마우스를 올려 특정 컴퓨팅 기기에서 실행되지 못한 이유에 대한 힌트를 얻을 수 있습니다
이 예시에서는 데이터 유형이 지원되지 않는다고 알려 주네요 이 정보를 바탕으로 준비 단계로 돌아가 필요한 부분을 변경하여 모델이 모든 컴퓨팅 기기와 호환되도록 수정할 수 있습니다
이 모델의 경우 단순히 정확도를 Float16으로 변경하면 되네요 더 많은 정보를 제공할 뿐 아니라 이제 성과 보고서를 내보내 다른 실행 결과와 비교할 수 있습니다 실행 결과를 비교하면 애플리케이션에 코드를 추가하지 않고도 모델 변경 사항의 영향을 파악할 수 있습니다 코드에 대해 더 이야기하자면 어떤 경우에는 그냥 코드를 추가하는 게 편할 때도 있습니다 MLComputePlan API가 도입되면서 이제 간단하게 할 수 있습니다 MLComputePlan은 성능 보고서처럼 Core ML에서 모델의 디버깅과 프로파일링 정보를 제공합니다 이 API는 각 연산에 대한 모델의 구조 및 런타임 정보를 표시합니다 지원 및 선호되는 컴퓨팅 기기 연산 지원 상태 앞서 설명한 추정 상대 비용 등의 정보입니다 이제 이 비디오를 마무리하며 내용을 요약해 보겠습니다 Core ML의 새로운 기능을 통해 머신 러닝 및 AI 모델을 온디바이스로 효율적으로 배포하고 실행할 수 있습니다 이제 MLTensor를 도입하여 모델 통합을 단순화하고 상태를 활용하여 추론 효율성을 향상하고 다중 함수 모델을 통해 여러 기능을 가진 모델을 효율적으로 배포할 수 있습니다 또한 성능 도구에서 제공하는 새로운 정보를 바탕으로 모델을 프로파일링하고 디버깅할 수 있습니다 강력한 온디바이스 머신 러닝 기능을 활용하여 여러분이 제작할 새로운 경험이 매우 기대가 됩니다
-