-
Direct Access to Video Encoding and Decoding
Discover how to use AV Foundation and Video Toolbox to access hardware accelerated encoding and decoding services. Gain best practices for when it is appropriate to use a high-level or low-level API for encoding or decoding. Learn about multi-pass export for improved H.264 encoding and see how to use it in your app.
资源
-
搜索此视频…
Hi everyone. Thanks for coming today. My name is David Eldred. This is session 513 and we're going to talk about Video Encoders and Decoders today. All right. We want to make sure that no matter what you're doing with the video in your application, you have access to hardware encoders and decoders.
This will help users. This will improve user experience in a number of ways.
Obviously, they'll get better performance and they will be far more efficient, but most importantly, this will extend battery life. Users will really appreciate it if their OS X, their portables, as well as their iOS devices have improved battery life. And as an added bonus, people with portables will love it if their fans don't kick in every time they're doing video processing.
So today, we're going to break this -- first, we're going to break this down into a few case studies. We're going to look at some common user scenarios. The first scenario we're going to talk about is the case where you have a stream of H.264 data coming in over the network and you want to display that inside of a layer in your application. The next one we're going to talk about is the case where you have a stream of H.264 data coming in over the network, but you don't just want to display that in your application, but you want to actually get access to those decoded CV pixel buffers.
Next, we'll be talking about when the case where you have a sequence of images coming in from the camera or someplace else and you'd like to compress those directly into a movie file.
And accompanying that, there's the case where you have a stream of images coming in from the camera or someplace else and you'd like to compress those but get direct access to those compressed sample buffers so that you can send them out over the network or do whatever you like with them.
And then finally, we're going to give you an intro to our new multi-pass APIs that we're introducing in iOS8 and Yosemite. All right, let's do a quick overview of our media interface stack. You've seen stuff like this earlier this week, but we'll do it once more, and there's a little focus on video in my view of this, because we're talking about video.
So at the top we have AVKit. AVKit provides very easy-to-use high level - ah, view level interfaces for dealing with media.
Below that, we have AVFoundation. AVFoundation provides an easy-to-use Objective-C interface for a wide range of media tasks.
And below that, we have Video Toolbox. Video Toolbox has been there on OS X for a while, but now it's finally populated with headers on iOS. This provides direct access to encoders and decoders.
And below that we have Core Media and Core Video. These frameworks provide many of the necessary types that you'll see throughout the -- in the interfaces in the rest of the stack.
So today, we're going to focus on AVFoundation and the Video Toolbox. In AVFoundation, we'll be looking at some interfaces that allow you to decode video directly into a layer in your application or compress frames directly into a file. And the Video Toolbox -- we'll be looking at these interfaces to give you more direct access to encoders and decoders so you can decompress directly to CV pixel buffers or compress directly to CM sample buffers.
So a quick note on using these frameworks. A lot of people think they have to dive down to the lowest level and use the Video Toolbox in order to get hardware acceleration, but that's really not true.
On iOS, AVKit, AVFoundation and Video Toolbox will all use hardware codecs.
On OS X, AVKit and AVFoundation will use hardware codecs when they're available on the system and when you -- when it's appropriate.
And Video Toolbox will use hardware codecs when it's available on system and when you request it.
All right.
So before we dive into more stuff, we're going -- I'm going to do a quick look at this cast of characters. These are some of the common types that you'll encounter in these interfaces.
First off, there's CVPixelBuffer. CVPixelBuffer contains a block of image data and wrapping that buffer of data is the CVPixelBuffer wrapping. And the CVPixelBuffer wrapping tells you how to access that data. It's got the dimensions, the width and the height. It's got the pixel format, everything you need in order to correctly interpret the pixel data. Next, we've got the CVPixelBufferPool. The CVPixelBufferPool allows you to efficiently recycle CVPixelBuffer back ends. Those data buffers can be very expensive to constantly allocate and de-allocate, so PixelBufferPool allows you to recycle them. The way a PixelBufferPool works is you allocate a CVPixelBuffer from the pool and the CVPixelBuffer is a ref counted object. When everyone releases that CVPixelBuffer, the data back end goes back into the pool and it's available for reuse next time you allocate a pixel buffer from that pool.
Next thing is pixelBufferAttributes. This isn't actually a type, like the rest of the things in this list, but it's a common object you'll see listed in our interfaces. You'll see requests for pixelBufferAttributes dictionaries. pixelBufferAttributes are a CF dictionary containing a set of requirements for either a CVPixelBuffer or a PixelBufferPool.
This includes the, you can -- this can include several things. This can include dimensions that you're requesting, the width and height. This can include a specific pixel format or a list of pixel formats that you'd like to receive.
And you can include specific compatibility flags requesting compatibility with specific display technologies such as OpenGL, OpenGL ES or Core Animation.
All right. Next, we've got CMTime. CMTime is the basic description of time that you'll see in your interfaces. This is a rational representation of a time value. It contains a 64-bit time value that's the numerator, and a 32-bit time scale, which is the denominator. We use this sort of rational representation so that these time values can be passed throughout your media pipeline and you won't have to do any sort of rounding on them. All right. Next, CMVideoFormatDescription. You'll see this in a bunch of our interfaces, and a CMVideoFormatDescription is basically a description of video data. This contains the dimensions. This includes the pixel format and there's a set of extensions that go along with the CMVideoFormatDescription. These extensions can include information to -- information used for displaying that video data, such as pixel aspect ratio, and it can include color space information. And in the case of H.264 data, the parameter sets are included in these extensions and we'll talk about that more a little bit later.
All right, next is CMBlockBuffer. CMBlockBuffer is the basic way that we wrap arbitrary blocks of data in Core Media.
In general, when you encounter video data, compressed video data in our pipeline, it will be wrapped in a CMBlockBuffer. All right, now we have CMSampleBuffer. You'll see CMSampleBuffer show up a lot in our interfaces. These wrap samples of data. In the case of video, CMSampleBuffers can wrap either compressed video frames or uncompressed video frames and CMSampleBuffers build on several of the types that we've talked about here.
They contain a CMTime. This is the presentation time for the sample. They contain a CMVideoFormatDescription. This describes the data inside of the CMSampleBuffer.
And finally, in the case of compressed video, they contain a CMBlockBuffer and the CMBlockBuffer has the compressed video data.
And if it's an uncompressed image in the CMSampleBuffer, the uncompressed image may be in a CVPixelBuffer or it may be in a CMBlockBuffer. All right. Next, we've got CMClock.
CMClock is the Core Media wrapper around a source of time and, like the clock on a wall -- there's no clocks on the wall here, but -- like a clock on the wall, time is always moving and it's always increasing on a CMClock.
One of the common clocks that you'll see used is the HostTimeClock. So CMClockgetHostTimeClock will return a clock which is based on mach-absolute-time.
So CMClocks are hard to control. You can't really control them. As I mentioned, they're always moving and always at a constant rate. So CMTimebase provides a more controlled view onto a CMClock.
So if we go ahead and create a CMClock based -- CMTimebase based on the hostTime clock, we could then set the time to time zero on our timebase.
Now, time zero on our timebase maps to the current time on the CMClock, and you can control the rate of your timebase. So if you were then to go and set your timebase rate to one, time will begin advancing on your timebase at the same rate at which the clock is advancing. And CMTimebases can be created based on CMClocks or they can be created based on other CMTimebases.
All right.
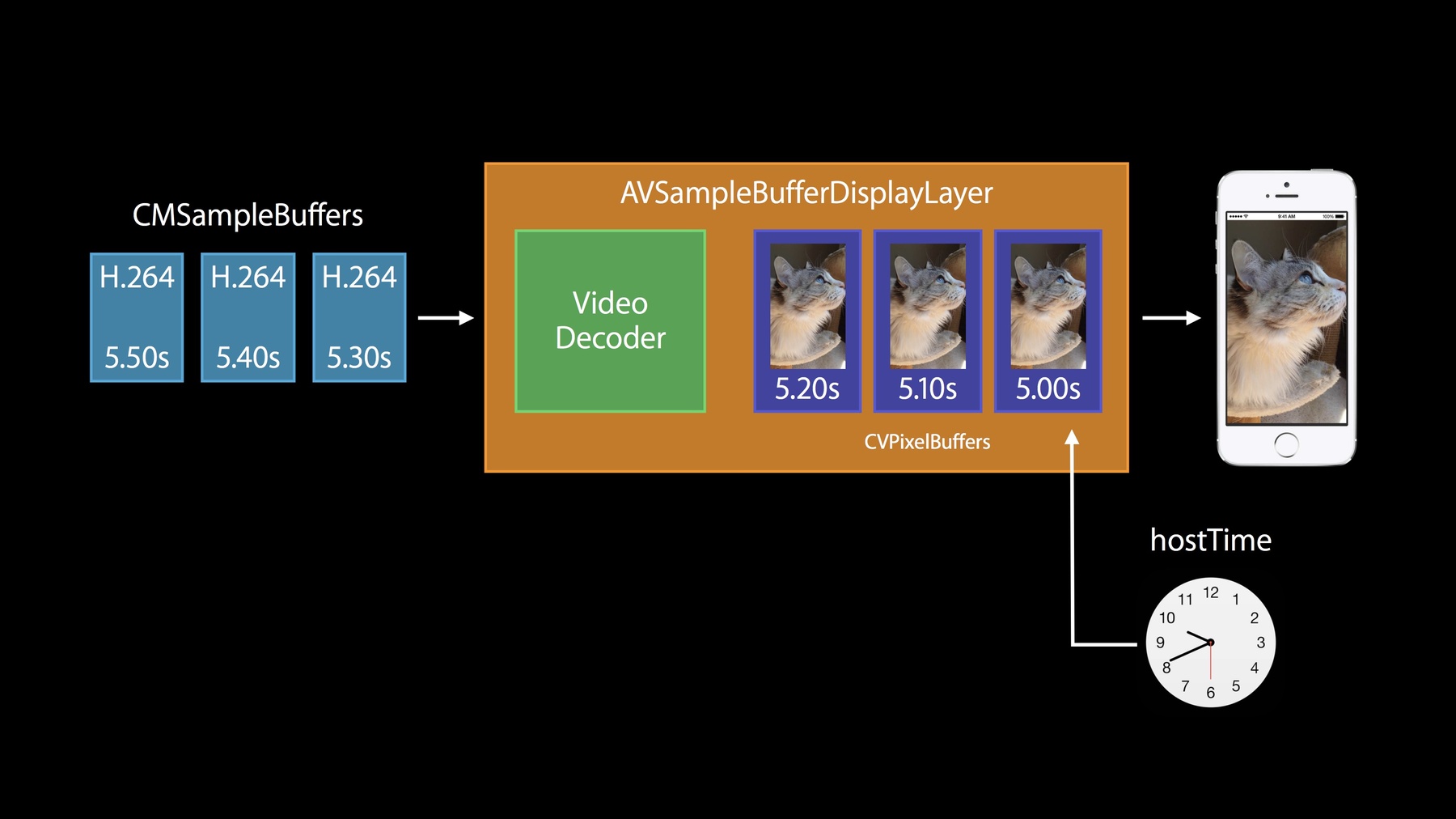
Let's hop into our first use case. This is the case where you have a stream of data coming in over the network and since its video data coming over the network, we can safely assume it's a cat video and so we've got AVSampleBufferDisplayLayer, which takes -- which can take a sequence of compressed frames and display it in a layer inside of your application.
AVSampleBufferDisplayLayer shipped in Mavericks, and it's new in iOS8.
So let's take a look inside AVSampleBufferDisplayLayer.
As I mentioned, it takes a -- a CM sample -- a sequence of compressed frames as input and these need to be in CMSampleBuffers.
Internally, it's going to have a video decoder and it will decode the frames into CVPixelBuffers and it will have a sequence of CVPixelBuffers queued up, ready to display in your application at the appropriate time. But, I mentioned we were getting our data off of the network. A lot of times, when you're getting a stream of compressed video off the network, it's going to be in the form of an elementary stream.
And I mentioned that CMSample -- uh, AVSampleBufferDisplayLayer wants CMSampleBuffers as its input.
Well, there's a little bit of work that has to happen here to convert your elementary stream data into CMSampleBuffers. So let's talk about this. H.264 defines a couple of ways of packaging -- the H.264 spec defines a couple of ways of packaging H.264 data. The first one I'm going to refer to as Elementary Stream packaging. This is used in elementary streams, transport streams, a lot of things with streams in their name. Next, is MPEG-4 packaging. This is used in movie files and MP4 files.
And in our interfaces that deal with CMSampleBuffers, Core Media and AVFoundation exclusively want the data packaged in MPEG-4 packaging.
So let's look closer at an H.264 stream. An H.264 stream consists of a sequence of blocks of data packaged in NAL Units. These NAL Units can contain several -- so this is the network abstraction layer, and these are Network Abstraction Layer units.
These can contain a few different things. First off, they can contain sample data.
So you could have -- a single frame of video could be packaged in one NAL Unit, or a frame of video could be spread across several NAL Units.
The other thing that NAL Units can contain is parameter sets. The parameter sets, the Sequence Parameter Set and Picture Parameter Set, are chunks of data which the decoder holds on to and these apply to all subsequent frames; well, until a new parameter set arrives.
So let's look at Elementary Stream packaging. Elementary Stream packaging, in Elementary Stream packaging, the parameter sets are included in NAL Units right inside the stream. This is great if you're doing sequential playback. You read in your parameter sets and they apply to all subsequent frames until a new frame or sets arrive.
MPEG-4 packaging has the NAL Units pulled out and it's in a separate block of data, and this block of data is stored in the CMVideoFormatDescription. So as I mentioned, each CMSampleBuffer references this CMVideoFormatDescription. That means each frame of data has access to the parameter sets.
This sort of packaging is superior for random access in a file. It allows you to jump anywhere and begin decoding at an I frame.
So what do you have to do if you have an Elementary Stream coming in? Well, we've got -- you've got a couple -- you've got your parameter sets and NAL Units and you're going to have to package those in a CMVideoFormatDescription.
Well, we provide a handy utility that does this for you; CMVideoFormatDescription CreatefromH264ParameterSets. All right, so the next difference that we're going to talk about between an Elementary Stream and MPEG-4 packaging is in NAL Unit headers. So each NAL Unit in an the stream -- Elementary Stream will have a three or four bytes start code as the header and in MPEG-4 packaging, we have a length code. So for each NAL Unit in your stream, they're going -- you have to strip off that start code and replace it with the length code. That's the length of the NAL Unit.
It's not that hard.
So let's talk about building a CMSampleBuffer from your Elementary Stream. First thing you're going to have to do is take your NAL Unit, or NAL Units, and replace the start code with a length code.
And you'll wrap that NAL Unit in a CMBlockBuffer. One note here, for simplicity, I'm showing a single NAL Unit but if you have a frame that consists of several NAL Units, you need to include all of the NAL Units in your CMSampleBuffer.
So you have a CMBlockBuffer. You have your CMVideoFormatDescription that you created from your initial -- from your parameter sets, and throw in a CMTime value, that's the presentation time of your frame, and you have everything you need in order to create a CMSampleBuffer using CMSampleBufferCreate.
All right, let's talk about AVSampleBufferDisplayLayer and Time. So as we saw, all CMSampleBuffers have an associated presentation time stamp, and our video decoder's going to be spitting out CVPixelBuffers each with an associated presentation time stamp.
Well, how does it know when to display these frames? By default, it will be driven off of the hostTime clock.
Well, that can be a little bit hard to manage; the hostTime clock isn't really under your control.
So we allow you to replace the hostTime clock with your own timebase.
To do this you set the time - y'know, in the example here, we're creating a timebase based on the hostTime clock and we're setting that as the control timebase on our AVSampleBufferDisplayLayer.
Here, we're setting the timebase time to five, which would mean our frame whose time stamp is five will be displayed in our layer, and then we go ahead and set the timebase rate to one, and now our timebase begins moving at the same rate as the hostTime clock, and subsequent frames will be displayed at the appropriate time.
All right.
So providing the CMSampleBuffers, the SampleBufferDisplayLayer, there's really two major scenarios that can describe this. First off, there's the periodic source. This is the case where you're getting frames in at basically the same rate at which they're being displayed in the AVSampleBufferDisplayLayer. This would be the case for a live streaming app or live streaming app with low latency or video conferencing scenario.
The next case is the unconstrained source. This is the case where you have a large set of CMSampleBuffers at your disposal ready to feed into the AVSampleBufferDisplayLayer at one time.
This would be the case if you have a large cache of buffered network data or if you're reading the CMSampleBuffers from a file.
All right, let's talk about the first case.
This is really simple. Frames are coming in at the same rate at which they're being displayed. You can go ahead and just enqueue the sample buffers with your AVSampleBufferDisplayLayer as they arrive.
You use the enqueueSampleBuffer column. All right. The unconstrained source is a little bit more complicated. You don't want to just shove all of those CMSampleBuffers into the AVSampleBufferDisplayLayer at once. No one will be happy with that. What you want to do, the AVSampleBufferDisplayLayer can tell you when it's buffers - it's internal buffers are low and it needs more data and you can ask it when it has enough data.
The way you do this is using the requestMediaData WhenReadyOnQueue.
You provide a block in this interface and AVSampleBufferDisplayLayer will call your block every time its internal queues are low and it needs more data.
Inside of that block, you can go ahead and loop while you're asking whether it has enough data. You use isReadyForMoreMediaData column. If it returns true, that means it wants more SampleBuffers, so you keep on feeding SampleBuffers in. As soon as it returns false, that means it has enough and you can stop.
So it's a pretty simple loop to write.
All right.
Let's do a quick summary of what we talked about with AVSampleBufferDisplayLayer. At this point, you should be able to create an AVSampleBufferDisplayLayer.
You've learned how to convert your Elementary Stream H.264 data into CMSampleBuffers that will happily be decompressed by your AVSampleBufferDisplayLayer.
We've talked about a couple of scenarios about how you would provide these CMSampleBuffers to your layer, AVSampleBufferDisplayLayer. And finally, we talked about using a custom CMTimebase with the AVSampleBufferDisplayLayer. All right.
So let's dive into our second case. This is the case where you have a stream of H.264 data coming in over the network, but you don't want to just display it in your application; you want to actually decode those frames and get the decompressed pixel buffers.
So what we had in AVSampleBufferDisplayLayer contains a lot of the pieces we need.
But instead of accessing the video decoder through the AVSampleBufferDisplayLayer, we'll access it through the VTDecompressionSession. Like the AVSampleBufferDisplayLayer, VTDecompressionSession wants CMSampleBuffers as its input.
And it will decode the CMSampleBuffers to CVPixelBuffers and receive those in the OutputCallback that you implement.
So in order to create a VTDecompressionSession, you'll need a few things.
First, you need to provide a description of the source buffers that you'll be decompressing.
This is a CMVideoFormatDescription. If you're decompressing from an Elementary Stream, you've created this from your parameter sets, if you just have a CMSampleBuffer that you want to decompress you can pull it straight off the CMSampleBuffer.
Next, you need to describe your requirements for your output pixelBuffers. You use a pixelBufferAttributes dictionary for this.
And finally, you need to implement a VTDecompressionOutputCallback.
All right. Let's talk about describing your requirements for the output pixelBuffers. Here, you need to create a PixelBufferAttributes dictionary. So let's look at a scenario where we want to use the Output CVPixelBuffers in an open GLS ES render pipeline.
Really, the only requirement here that we have for our Output PixelBuffers is that they be OpenGL ES compatible. So we can go ahead and just create a CFDictionary or NSDictionary specifying the kCVPixelBufferOpen GLESCompatibilityKey and set it to true.
So it can be very tempting to, when you're creating these PixelBufferAttributes dictionaries, to be very specific. That way, there's no surprises about what you get out of the VTDecompressionSession, but there's some pitfalls here. So let's look at this case where we had kCVPixelBufferOpen GLESCompatibilityKey set to true.
Here, our decompression session -- the decoder inside of our decompression session is going to be decoding the frames and outputting YUV CVPixelBuffers.
In the VTDecompressionSession we'll then ask, is this -- well, it'll ask itself, "is this PixelBuffer compatible with those requested attributes?" And the answer is yes. That YUV frame is OpenGL ES compatible so it can return that directly to your callback.
But let's say you were possessed to add BGRA request to your PixelBufferAttributes.
So just like before, the decoder inside of our VTDecompressionSession will decode to a YUV format and will ask whether this CVPixelBuffer is compatible with the requested output requirements.
And it is OpenGL ES compatible, but it's certainly not BGRA.
So it will need to do an extra buffer copy to convert that YUV data to BGRA data.
So extra buffer copies are bad. They decrease efficiency and they can lead to decreased battery life. So the moral story here is -- be, uh -- don't over specify.
All right, let's talk about your Output Callback.
So the Output Callback is where you'll receive the decoded CVPixelBuffers and CVPixelBuffers don't have a built in time stamp, so you'll receive the presentation time stamp for that PixelBuffer here.
And if there are errors or the frame is dropped for any reason, you'll receive that information in the Output Callback. And it's important to note that the Output Callback will be called for every single frame that you push into the VTDecompressionSession even if there's an error, even if it's dropped.
All right, let's talk about providing frames to your VTDecompressionSession. To do that, you call VTDecompression SessionDecodeFrame.
Just like AVSampleBufferDisplayLayer, you need to provide these as CMSampleBuffers, and you need to provide these frames in decode order.
And by default, VTDecompressionSession DecodeFrame will operate synchronously. This means that your OutputCallback will be called before VTDecompression SessionDecodeFrame returns.
If you want asynchronous operation, you can pass in the flag requesting EnableAsynchronous Decompression. All right, let's talk about asynchronous decompression then. With ASynchronousDecompression, the call to VTDecompressionSession DecodeFrame returns as soon as it hands the frame off to the decoder. But decoders often have limited pipelines for decoding frames. So when the decoder's internal pipeline is full, the call to VTDecompression SessionDecodeFrame will block until space opens up in the decoders pipeline.
We call this decoder back pressure.
So what this means is that even though you're calling VTDecompressionSession DecodeFrame and requesting Asynchronous Decompression, we will be doing the decompression asynchronously but the call can still block (in some cases). So be aware of that. You're doing AsynchronousDecompression but the call can block, so don't perform UI tasks on that thread.
All right, if you find yourself in a situation where you want to ensure that all asynchronous frames have been cleared out of the decoder, you can call VTDecompressionSession and WaitForAsynchronousFrames. This call will not return until all frames have been omitted from the decompression session.
So, sometimes, while decoding a sequence of video frames there will be a change in the CMVideoFormatDescription. So let's look at the case where we had a sequence of an Elementary Stream and we created the first format description out of the first parameter sets that we encountered. So now we have format description one with our first SPS and PPS. We can go ahead and create our VTDecompressionSession with that format description and decode all the subsequent frames with that format description attached to the CMSampleBuffer until we encounter a new SPS and PPS in the stream.
Then, we need to create a new format description with that new -- the new SPS and PPS and we have to make sure that the decompression session can switch between these format descriptions.
So to do that, you call VTDecompressionSession CanAcceptFormatDescription. This will ensure -- ask the decoder whether it's able to transition from FormatDescription one to FormatDescription two. If the answer is true (yes, it can handle the new accepted FormatDescription) that means you can pass subsequent samples with that new FormatDescription attached to them into the Decompression Session and everything will work fine. If it returns false, that means the decompressor cannot transition from that first format description to the second format description, and you'll need to create a new VTDecompressionSession and be sure to -- and pass the new frames into that one. And be sure to release that old VTDecompressionSession when you're no longer using it. All right. Quick summary of what we talked about with VTDecompressionSession.
We talked about creating the VTDecompressionSession and how to make optimal decisions when creating your PixelBuffer-- ah, your PixelBufferAttributes dictionary for specifying your output requirements. We talked about running your decompression session both synchronously and asynchronously and we talked about handing changes in CMVideo FormatDescription.
So. With that, let's hop into case three. This is the case where you have a stream of CVPixelBuffers or frames coming in from a camera or another source, and you want to compress those directly into a movie file.
Well, for this -- you may be familiar with this already -- we have AVAssetWriter.
AVAssetWriter has an encoder internally, and it's going to be encoding those frames into CMSampleBuffers and it's got some file writing smarts, so it can write these optimally into a movie file.
We're not actually going to talk more, at this point, about AVAssetWriter, but it's an important concept and an important thing to bring up in the context of this talk, so if you want more information on the AVAssetWriter, you can go back to WWDC 2013 and the talk "Moving to AVKit and AVFoundation" or 2011, "Working with Media and AVFoundation." All right. Let's just hop straight into case four. This is the case where you have that stream of data coming in from your camera and you want to compress it, but you don't want to write into a movie file. You want direct access to those compressed SampleBuffers.
So we want to approach our video encoder through a VTCompressionSession rather than through the AVAssetWriter.
So just like the AVAssetWriter, VTCompressionSession takes CVPixelBuffers as its input, and it's going to compress those and return CMSampleBuffers, and we can go ahead and send that compressed data out over the network.
So to create a VTCompressionSession, you'll need a few things, and this is really simple. You just need to specify the dimensions you want for your compressed output.
You need to tell us what format you want to compress to, such as kCMVideoCodec Type-H.264, and you can optionally provide a set of PixelBufferAttributes describing your source CVPixelBuffers that you'll be sending to the VTCompressionSession. And finally, you need to implement a VTCompression OutputCallback.
So you've created a VTCompressionSession. Now you want to configure it.
You configure a VTCompressionSession using VTSessionSetProperty. In fact, you can have a whole sequence of VTSessionSetProperty calls. So I'm going to go through a few common properties here and, but, this is not an exhaustive list. The first one I'm going to mention is AllowFrameReordering. By default, H.264 encoder will allow frames to be reordered. That means the presentation time stamp that you pass them in will not necessarily equal the decode order in which they're emitted.
If you want to disable this behavior, you can pass false to allow frame reordering.
Next one: AverageBitRate. This is how you set a target bit rate for the compressor.
H264EntropyMode -- using this, you can specify CAVLC compression or kVTH compression for your H.264 encoder.
All right, and then there's the RealTime property. The RealTime property allows you to tell the encoder that this is a real-time encoding operation (such as in a live streaming case, conferencing case) as opposed to more of a background activity (like a transcode operation).
And the final one I'm going to mention here is the ProfileLevel key. This allows you to specify specific profiles and levels or specific profiles and allow us to choose the correct level. And this is definitely not an exhaustive list. There's a lot of these options available, so go ahead and look in VTCompressionProperties.H and see what we have for you. All right, let's talk about providing CVPixelBuffers to your VTCompressionSession.
Use VTCompressionSession EncodeFrame to do this, and you'll need to provide CVPixelBuffers and, CV -- as I've mentioned, CVPixelBuffers don't have a presentation time stamp built into them, so as a separate parameter, you'll provide the presentation time stamp.
You need to feed the frames in in presentation order.
And it's -- one more note about the presentation order: they -- the presentation time stamps must be increasing. No duplicate presentation time stamps, no time stamps that go backwards.
And so compression sessions -- compression operations usually require a window of frames that they'll operate on, so your output may be delayed. So you may not receive a compressed frame in your output callback until a certain number of frames have been pushed into the encoder. All right. And finally, if you've reached the end of the frames that you're passing to the compression session and you want to have it emit all of the frames that it's received so far, you can use VTCompressionSession CompleteFrames. All pending frames will be omitted.
All right. Let's talk about your output callback.
So your OutputCallback is where you'll receive your output CMSampleBuffers. These contain the compressed frames.
If there were any errors or dropped frames, you'll receive that information here.
And final thing, frames will be emitted in decode order. So you provided frames to the VTCompressionSession in presentation order and they'll be emitted in decode order. All right. Well, so you've compressed a bunch of frames. They're now compressed in CMSampleBuffers, which means that they're using MPEG-4 packaging. And you want to send that out over the network, which means you may need to switch these over to Elementary Stream packaging.
Well, once again, you're going to have to do a little bit of work.
So we talked about the parameter sets before.
So the parameters sets will -- in your MPEG-4 package, H.264 will be in the CMVideoFormatDescription. So the first thing you're going to have to do is extract those parameter sets and package them as NAL Units to send out over the network.
Well, we provide a handy utility for that too. CMVideoFormatDescription GetH.264ParameterSetAtIndex.
All right, and the next thing you need to do is the opposite of what we did with AVSampleBufferDisplayLayer.
Our NAL Units are all going to have length headers and you're going to need to convert those length headers into start codes.
So as you extract each NAL Unit from the compressed data inside the CMSampleBuffer, convert those headers on the NAL Units.
All right. Quick summary of what we talked about with the VTCompressionSession.
We talked about creating the VTCompressionSession.
We've talked about how to configure it using the VTSessionSetProperty column.
And we talked about how you would provide CVPixelBuffers to the compression session.
And finally, we talked about converting those CMSampleBuffers into an H.264 Elementary Stream packaging.
All right. And with that, I'd like to hand things off to Eric so he can talk about Multi-Pass. Good morning everyone. My name is Eric Turnquist. I'm the Core Media Engineer, and today, I want to talk to you about Multi-Pass Encoding.
So as a media engineer, we often deal with two opposing forces; quality versus bit rate. So quality is how pristine the image is, and we all know when we've seen great quality video and we really don't like seeing bad quality video.
Bit rate is how much data per time is in the output media file. So let's say we're preparing some content.
If you're like me, you go for high quality first. So great, we have high quality.
Now in this case, what happens with the bit rate? Well unfortunately, if you have high quality, you also tend to have a high bit rate. Now that's okay, but not what we want if we're streaming this content or storing it on a server.
So in that case we want to a low bit rate but the quality isn't going to stay this high. Unfortunately, that's also going to go down as well.
So we've all seen this as blocky encoder artifacts or an output image that doesn't really even look like the source. We don't want this either. Ideally, we want something like this; high quality and low bit rate. In order to achieve that goal, we've added Multi-Pass Encoding to AVFoundation and Video Toolbox. Yeah. So first off, what is Multi-Pass Encoding? Well, let's do a review of what Single-Pass Encoding is first. So this is what David covered in his portion of the talk.
With Single-Pass Encoding, you have frames coming in, going into the encoder and being emitted. In this case, we're going to a movie file.
Then once you're done appending all the samples, we're finished, and we're left with our output movie file. Simple enough.
Let's see how multi-pass differs. So you have uncompressed frames coming in going, into the compression session, being emitted as compressed samples. Now we're going to change things up a little bit. So we're going to have our Frame Database. This will store the compressed samples and allow us random access and replacement, which is important for multi-pass. And we're going to have our Encoder Database; this will store frame analysis.
So we're done appending for one pass, and the encoder will decide I think, "I can actually do better in another pass, so I can tweak the parameters a little bit to get better quality." It will request some samples and you'll go through and send those samples again to the encoder, and then it may decide I'm done or I'm actually -- or, I want more passes. In this case, let's assume that we're finished.
So we no longer need the encoder database or the compression session, but we're left with this Frame Database and we want a movie file, so we need one more step.
There's a final copy from the Frame Database to the output movie file and that's it. We have a multi-pass encoded video track on a movie file.
Cool. Let's go over some encoder features.
So my first point is -- I want to make a note of -- is David said that Single-Pass is hardware accelerated and multi-pass is also hardware accelerated, so you're not losing any hardware acceleration there.
Second point is that multi-pass has knowledge of the future. No, it's not some crazy, time-traveling video encoder. (Bonus points: whoever files that enhancement request!) It allows, or -- is able to see your entire content. So in Single-Pass, as frames come in, the encoder has to make assumptions about what might come next. In multi-pass, it's already seen all your content so it can make much better decisions there.
Third, it can change decisions that it's made. So in Single-Pass, as soon as the frame is emitted, that's it. It can't -- it can no longer change, uh -- Yeah, it can no longer change its mind about what it's emitted.
In multi-pass, because the frame database supports replacement, each pass you can go through and change its mind about how to achieve optimal quality. And as a result of this, you really get optimal quality per bit, so it's sort of like having a very awesome custom encoder for your content.
So that's how multi-pass works and some new features. Let's talk about new APIs.
So first off, let's talk about AVFoundation. In AVFoundation, we have a new AVAssetExportSession property. We have new pass descriptions for AVAssetWriterInput and we have reuse on AVAssetReaderOutput.
So first, let's go over an overview of AVAssetExportSession.
In AVAssetExportSession, you're going from a source file, decoding them, then performing some operation on those uncompressed buffers -- something like scaling or color conversion, and you're encoding them and writing them to a movie file. So in this case, what does AVAssetExportSession provide? Well, it does all this for you. It's the easiest way to transcode media on iOS and OS X. So let's see what we've added here.
So in AVAssetExportSession multiple passes are taken care of for you automatically. There's no work that you have to do to send the samples between passes. And also, it falls back to Single-Pass if multi-pass isn't supported. So if you choose a preset that uses a codec where multi-pass isn't supported, don't worry, it'll use Single-Pass.
And we have one new property; set this to yes and you're automatically opted into multi-pass, and that's it. So for a large majority of you, this is all you need.
Next, let's talk about AVAssetWriter.
So AVAssetWriter, you're coming from uncompressed samples. You want to compress them and write them to a movie file.
You might be coming from an OpenGL or OpenGL ES context. In this case, what does AVAssetWriter provide? Well, it wraps this portion, going from the encoder to the output movie file.
Another use case, it's similar to AVAssetExportSession where you're going from a source movie file to a destination output movie file and modifying the buffers in some way.
Well in this case, you're going to use an AVAssetReaderOutput and an AVAssetWriterInput. You're responsible for sending samples from one to the other. Let's go over our new AVAssetWriterInput APIs. So like AVAssetExportSession, you need to enable multi-pass, so set this to yes and you're automatically opted in. Then after you're done appending samples, you need to mark the current pass as finished. So what does this do? Well, this triggers the encoder analysis. The encoder needs to decide if I need to perform multiple passes and if so, what time ranges. So the encoder might say, "I want to see the entire sequence again," or "I want to see subsets of the sequence." So how does the encoder talk about what time ranges it wants for the next pass? Well, that's through an AVAssetWriter InputPassDescription. So in this case, we have time from 0 to 3, but not the sample at time 3, and samples from 5 to 7, but not the sample at time 7. So a pass description is the encoder's request for media in the next pass, and it may contain the entire sequence or subsets of the sequence. On a pass description, you can query the time ranges that the encoder has requested by calling sourceTimeRanges.
All right, let's talk about how AVAssetWriterInput uses pass descriptions.
So when you trigger the encoder analysis, the encoder needs to reply with what decisions it's made. So you provide a block on this method to allow the encoder to give you that answer. So this block is called when the encoder makes a decision about the next pass. In that block, you can get the new pass description, the encoder's decision about what content it wants for the next pass. Let's see how that works all in a sample. So here's our sample. We have our block callback that your provide.
Inside that callback you call currentPassDescription. This asks the encoder what time ranges it wants for the next pass. If the pass is non-nil (meaning the encoder wants data for another pass) you reconfigure your source. So this is where the source will send samples to the AVAssetWriterInput, and then you prepare the AVAssetWriterInput for the next pass. You're already familiar with requestMediaData WhenReadyOnQueue. If the pass is nil, that means the encoder has finished passes. Then you're done. You can mark your input as finished. All right, let's say you're going from a source media file. That was in our second example. So we have new APIs for AVAssetReaderOutput. You can prepare your source for multi-pass by saying supportsRandomAccess equals yes. Then when the encoder wants new time ranges, you need to reconfigure your AVAssetReaderOutput to deliver those time ranges. So that's resetForReadingTimeRanges with an NSArray of time ranges.
Finally, when all passes have completed you callMarkConfigurationAsFinal. This allows the AVAssetReaderOutput to transition to its completed state so it can start tearing itself down. Right. Now there's a couple short cuts you can use if you're using AVAssetReader and AVAssetWriter in combination together.
So you can enable an AVAssetReaderOutput if the AVAssetWriterInput supports multi-pass. So if the encoder supports multi-pass, we need to support random access on the source. Then you can reconfigure your source to deliver samples for the AVAssetWriterInput. So with your readerOutput call resetForReadingTimeRanges with the pass description's time ranges. Let's go over that in the sample.
So instead of delivering for an arbitrary source, we now want to deliver for our AVAssetReaderOuput. So we call resetForReadingTimeRanges with the pass description sourceTimeRanges.
Great. So that's the new API and AVFoundation for multi-pass. Let's talk next about Video Toolbox.
So in Video Toolbox, our encoder frame analysis database, we like to call this our VTMultiPassStorage.
We also have additions to VTCompressionSession, which David introduced in his portion of the talk, and decompressed frame database, or as we call it, the VTFrameSilo. So let's go over the architecture, but this time replacing the frame database and the encoder database with the objects that we actually use. So in this case, we have our VTFrameSilo and our VTMultiPassStorage.
We're done with this pass. The encoder wants to see samples again.
We're sending in those samples that it requests.
Then we're finished and we can tear down the VTMultiPassStorage and the compression session and we're left with our FrameSilo. So this is where we need to perform the copy from the FrameSilo to the output movie file. Great, we have our output movie file.
So first off, let's go over what the VTMultiPassStorage is. So this is the encoder analysis. This is a pretty simple API. First you create the storage and then you close the file once you're finished. So that's all the API that you need to use. The data that's stored in this is private to the encoder and you don't have to worry about it.
Next, let's talk about additions to VTCompressionSession.
So first, you need to tell the VTCompressionSession and the encoder about your VTMultiPassStorage. So you can do that by setting a property. This will tell the encoder to use MultiPass and use this VTMultiPassStorage for its frame analysis. Next, we've added a couple functions for multi-pass. So you call beginPass before you've appended any frames then after you're done appending frames for that pass, you call endPass. EndPass also asks the encoder if another pass can be performed.
So if another -- if the encoder wants another pass to be performed then you need to ask it what time ranges of samples it wants for the next pass. That's called VTCompressionSession GetTimeRangesFor NextPass and you're given a count and a C array of time ranges. Now let's talk about the VTFrameSilo. So this is the compressed frame store.
So like the other objects you created, and then you want to add samples to this VTFrameSilo.
So frames will automatically be replaced if they have the same presentation time stamp and how this data is stored is abstracted away from you and you don't need to worry about it. It's a convenient database for you to use. Then you can prepare the VTFrameSilo for the next pass. This optimizes the storage for the next pass.
Finally, let's talk about the copy from the VTFrameSilo to the output movie file.
So you can retrieve samples for a given time range. This allows you to get a sample in a block callback that you provide and add it to your output movie file. All right, that's the new Video Toolbox APIs. So I want to close with a couple considerations.
So we've talked about how multi-pass works and what APIs you can use in AVFoundation and Video Toolbox, but we need to talk about your use cases and your priority in your app. So if you're performing real time encoding, you should be using single-pass. Real time encoding has very specific deadlines of how much compression can take and multi-pass will perform more passes over the time range, so use Single-Pass in these cases.
If you're concerned about using the minimum amount of power during encoding, use single-pass. Multiple passes will take more power and, as will the encoder analysis.
If you're concerned with using the minimum amount of temporary storage during the encode or transcode operation, use single-pass. The encoder analysis storage and the frame database will use more storage than the output media file.
However, if you're concerned about having the best quality for your content, multi-pass is a great option. If you want to be as close to the target bit rate you set on the VTCompressionSession or AssetWriter as possible, use multi-pass. Multi-pass can see all of the portions of your source media and so it can allocate bits only where it needs to. It's very smart in this sense.
If it's okay to take longer in your app (so if it's okay for the encoder transfer operation to take longer for better quality) multi-pass is a good option. But the biggest takeaway is that in your app, you need to experiment. So you need to think about your use cases and your users and if they're willing to wait longer for better quality. Next, let's talk about content.
So if you, if your app has low quality -- or, low complexity content, think of this like a title sequence or a static image sequence.
Both single-pass and multi-pass are going to both give you great quality here, but multi-pass won't give you much better quality than single-pass. These are both pretty easy to encode.
Next, let's talk about high complexity content. So think of this as classic encoder stress tests; water, fire, explosions. We all love to do this, but single-pass and multi-pass are both going to do well, but multi-pass probably won't do much better than single-pass. These are -- this kind of content is hard for encoders to encode.
Where is multi-pass a better decision? Well, that's in varying complexity, so think of this as a feature-length movie or a documentary in Final Cut Pro or an iMovie trailer. They might have low complexity regions, a title sequence, high complexity transitions. Because there's a lot of different kinds of content, multi-pass is able to analyze those sections and really give you the best quality per bit. But again, the message is: with your content, you need to experiment. So you know your content and you should know if multi-pass will give you a good benefit in these cases. So let's go over what we've talked about today. AVFoundation provides powerful APIs to operate on media, and for most of you, these are the APIs you will be using. And when you need the extra power, Video Toolbox APIs provide you direct media access. If you fall into one of the use cases that David talked about, this is a good way to use Video Toolbox.
Finally, multi-pass can provide substantial quality improvements, but you need to think about your app, your use cases and your users before you enable it.
So for more information, here's our Evangelism email. You have AVFoundation Documentation and a programming guide. We can answer your questions on the developer forums. For those of you that are watching online, a lot of these talks have already happened. If you're here live, so these are the talks you might be interested in. Thanks everyone and have a good rest of your day. [ Applause ]
-