-
自然语言框架改进
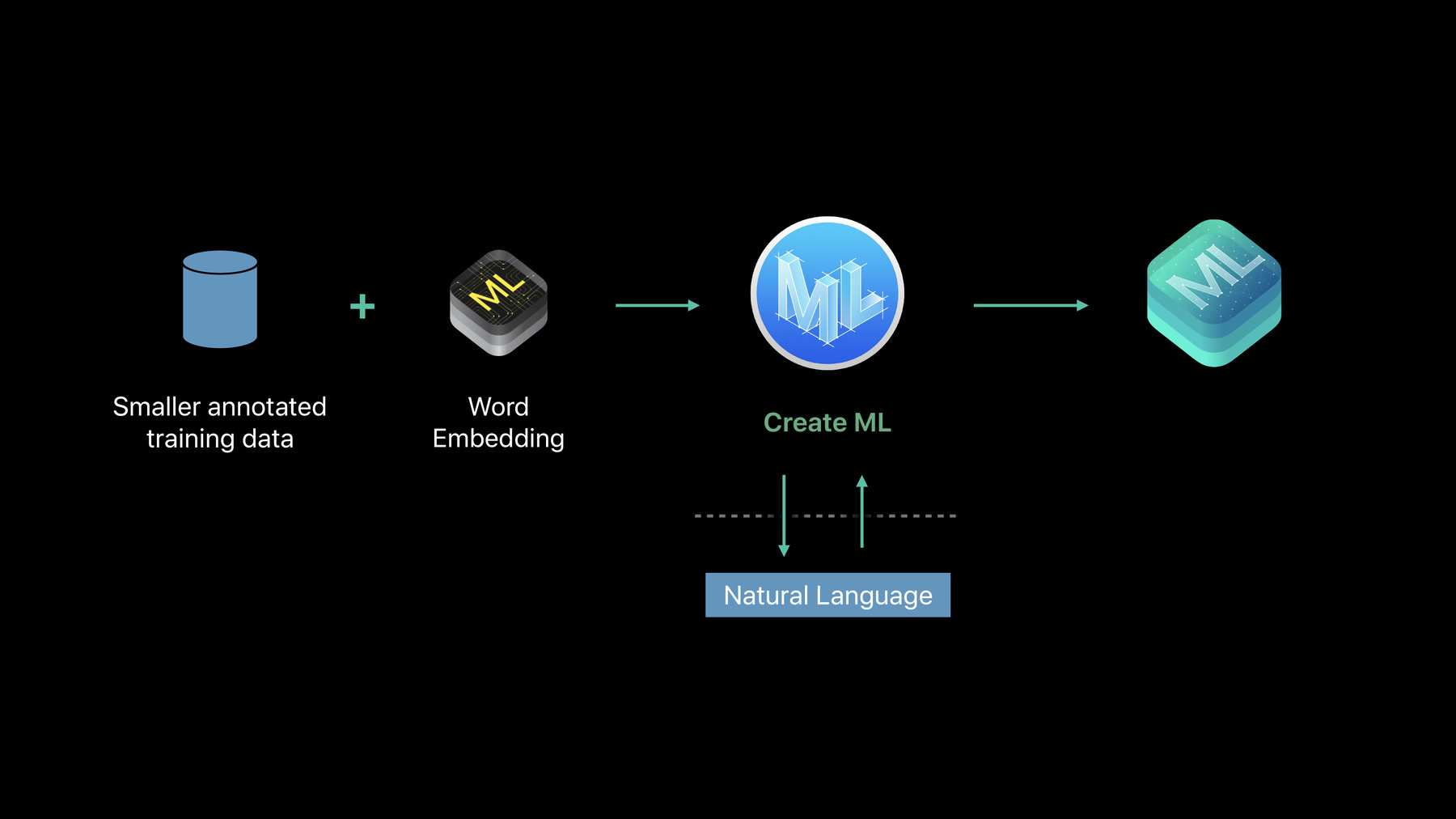
自然语言框架专为在所有 Apple 平台提供高性能的设备端自然语言处理 API 而设计。了解这个框架中新增的情感分析和文本目录支持。更深入地了解基于文本的模型的迁移学习,以及能够为您的 app 带来出色搜索体验的全新单词嵌入支持。
资源
相关视频
WWDC23
WWDC20
WWDC19
-
搜索此视频…
大家下午好 欢迎来到我们的讲演 自然语言处理 我叫 Vivek 我的同事 Doug Davidson 会和我一起 完成讲演 我们开始吧 如你所知 文本无处不在 随处可见 用户在 App 中 和文本交互的模式 主要有两个 一是通过自然语言输入 用户在 App 内写入文本 或生成文本 比如用户可能在 App 里 用键盘键入文本 这种 App 有很多 比如 《信息》 用户写入文本然后分享给其他人 还有《备忘录》 或者任何效率 App 部分功能需要你键入文本
另一种用户 和 App 内文本互动的方式 是通过自然语言输出 App 把文本内容 提供给用户 用户使用或者读取这个文本
这类 App 有 比如《新闻》 信息或者文本展示给用户 用户阅读这个信息 所以 不论是文本输入还是输出 为了从原始文本中 提取可操作的情报 自然语言处理 都是非常重要的 去年 我们介绍了 自然语言框架 自然语言框架 是 Apple 所有平台通用的 可处理所有东西的自然语言处理的主力 所以我们提供了几个 基础的 NLP 模块 比如语言识别 分词 词性标注等等 我们展示了这些基础功能 并跨语种提供这些功能 这是通过无缝融合 语言学和机器学习实现的 所以你可以只关注 通过使用这些 API 搭建你的 App 繁重的工作 我们在幕后处理 现在 如果你退一步 看看所有这些功能 实际上 如果你看看 大部分 NLP 功能 它们可以分为 两大类任务 第一类是文本分类 文本分类的目的是 给一个文本 这个文本可以是一个句子 可以是一个段落 或者一个文件 你想向这个文本 分配标签 这些标签可以是情感标签 可以是话题标签 任何你想分配的标签
另一类 NLP 任务被称为 单词标注 这里的任务 或这里的目的是 给一系列词 也被称为 token 我们想给这个序列里的 每个 token 分配一个标签 今年 在文本分类 和单词标记中 我们都有新的 API 首先 我们先从 情感分析开始 情感分析是一个文本分类 API 这是个新的 API 是这样运作的 你要做的是 把文本传输到这个 API API 分析文本 给你一个 情感分值 这个情感分值 捕捉文本里的 情感程度
情感分值 从负一到正一不等 表示情感的程度 比如 -1.0 表明是一个 非常强烈的消极情感 1.0 表明是 非常强烈的积极情感 所以基本上 我们提供一个分值 让你为 App 测定分值 举个例子 如果有一句话 比如 我们在夏威夷 和家人玩得很开心 API 可能会给出 0.8 分 表明这句话 是一句积极的句子
相反 如果这句话是 我们在夏威夷玩得不好 因为妈妈扭伤了她的脚踝 这不是一句积极的话 所以你得到 -0.8 分 然后你就可以判定 这是一个消极的情感
非常棒 你怎么用呢 用起来真的很简单 对于你们 习惯使用 NaturalLanguage 的人 这会非常简单 导入 NaturalLanguage 创建一个实例 NLTagger 现在你做的就是 指定一个新的标签方案 这个标签方案被称为情感分值 然后把想分析的字符串 附加到 tagger 然后你只需要 在句子层面 或者在段落层面请求情感分值
看一下实际运行情况
这儿有一个 假设 App 它是个奶酪 App 作为这个 App 的一部分 用户可以做很多事情 他们可以写关于奶酪的笔记 他们可以写评价 发表对不同奶酪的看法 尽管这个 App 是关于奶酪的 但它并不油腻 它处理的是精细的奶酪 我将要为大家展示的是 一个用户在写评价 在他写评价时 文本传送到 情感分类 API 我们得到一个分值 根据情感分值给文本上色 我们看 如果你键入类似 很好 非常美味的评语 你可以看到 这是一个积极的情感
相反 如果你键入 入口还不错 但是后味很糟糕 可以看到这是个消极情感 你可以看到 这些都是实时发生的 这是因为 API 性能非常出色 它实际使用神经网络模型 所有 Apple 平台上 都激活了硬件 所以基本上 你可以实时做这些
我们支持情感分析 API 用于七种不同的语言 英语 法语 意大利语 德语 西班牙语 葡萄牙语和简体中文 我觉得你们肯定会喜欢这个
当然 所有的这些 都全部发生在设备上 用户数据不需要离开设备 设备本身就能提供这项强大的功能 我想简短地讨论一下 语言素材 我刚才已经提及 NLP 功能是多种多样的 支持多种 不同的语言 现在 对于用户 我们确保他们能够拥有 自己感兴趣的 语言的素材 但是对于大家来说 出于开发的目的 可能对按需素材更感兴趣 实际上 这是大家的一个普遍请求 所以我们要介绍一个 新的便捷 API 叫做请求素材 你可以按照自己的需求 触发一个特定素材的下载 你只需指定 自己喜欢的 语言和标签方案 我们会在后台复刻一个下载 然后你就可以 及时在设备上获取素材 这会帮助你开发 App 并提高你 搭建 App 的效率
我刚才介绍的是文本分类 现在我们进入单词标记部分
回顾一下 单词标记是一个任务 给定一系列 token 我们想要给序列中每一个 token 分配标签 就像这个例子 我们可以给许多 token 分配不同的标签 Timothy 是一个人名 瑞士是一个地方 这句话里还有很多名词
很好 如果你只是想用我们的 API 做命名实体识别 或用 API 做词性标注也可以 但这里还有几个例子 你可以做更适合你任务的东西 你想知道的不仅是格吕耶尔 干酪 是两个名词 你还想知道 它是种瑞士奶酪 我们在搭建一个奶酪 App 你当然想得到这个信息 但是 默认 tagger 不包含任何关于奶酪的信息 那我们要如何 提供这个信息呢 所以自然语言框架里 有一个新功能 我们称之为文本目录
文本目录非常简单 你只需要提供 一个自定义列表 可能是一个非常大的实体列表 列表中的每一个实体 都有一个标签 实际情况下 这些列表可能是数百万 甚至是几亿 你需要做的是 把这种词库传送到 Create ML 创建一个 MLGazetteer 实例 Gazetteer 只是 文本目录的术语 两个名称可以混用 你得到的输出就是 文本目录 这是输入词库的 非常精简和有效的形式 非常简单 你要做的就是先提供这个词库 我们不能在这里 展现数百万的实例 我们只能用几个实例作例子 但是它可以是 一个非常非常大的词库
然后你就可以 创建 MLGazetteer 实例 传送词库 将它写到磁盘 这一切看起来都没有什么危险 你可能在想 我只是把词库写到磁盘 这是在做什么 如果你的调用正确 会发生一些神奇的事情 Create ML 在内部调用自然语言 自然语言会把这个 非常大的词库 压缩到一个 Bloom 过滤器 这是一种非常紧凑的形式 那么你得到的输出 就是文本目录 实际上 我们已经用了这个方法 并达到了效果 我们已经压缩了 维基百科几乎所有的 人名 机构名称 位置 差不多有 250 万个 压缩到 磁盘上的 2 兆 在某种程度上 你一直在使用这个模型 当你在 NaturalLanguage 里 结合统计模型 调用命名实例识别 API 时 你就在用这个 Bloom 过滤器 和 Gazetteer 现在我们把这个能力给了你 一旦你创建了 Gazetteer 或文本目录 用起来就会特别简单 通过指定文本目录的路径 刚才写到磁盘上的文本目录 你创建了一个 MLGazetteer 实例 你可以在这里用自己喜欢的标签方案 可以是词汇类 名称类型 任何标签方案都可以 只需要把 Gazetteer 附加到标签方案 然后 每当有一个文本 这个自定义的 Gazetteer 会覆盖 NaturalLanguage 提供的默认标签
这样 你就可以自定义你的 App
现在 返回奶酪 App 如果有一句话 比如 比卡芒贝尔奶酪 或牛乳奶酪更淡 你可以使用奶酪的文本目录 识别一个是法国奶酪 另一个是瑞士奶酪 你也许可以创建一个超链接 通过这种方式 制作一个更好的 App 这是一种在 NaturalLanguage 里 使用文字目录 标注单词的方法 我刚才介绍了文本分类 介绍了单词标注 但是近几年 NLP 领域 发生了巨大的变化 有两个催化剂 促成了这一变化 一是单词嵌入概念 单词嵌入只是单词的 向量表示 另一个是 NLP 里 神经网络的使用
我很高兴地宣布 今年你可以 通过 NaturalLanguage 使用这些功能搭建 App 我们先从单词嵌入开始 谢谢
在我们进入 单词嵌入部分之前 我想通过几张幻灯片 解释一下什么是嵌入 理论层面上 嵌入只不过是把离散对象集合 映射到持续向量表示 我们有这些离散对象 这个集合里的每个对象 可以用有限向量表示 在这个例子中 我们是用 3D 向量展示的 用 3D 是因为 设计和看起来比较容易 但是实际上 这些向量 可以是任意维度 可以是 100D 300D 甚至在某些情况下 是 1000D 向量
这些嵌入的特性是非常条理 当你要设计 这些嵌入时 语义相似的对象 会聚在一起
在这个例子中 油漆罐和油漆刷 聚在了一起
运动鞋 和高跟鞋聚在了一起 所以 嵌入的特性非常条理 嵌入的这个特性 不仅可以用于单词 实际上还可用于 不同的形式 可以是图片嵌入 当你有一张图片 通过 VGG 网络 或者任何卷积神经网络传输时 你得到的输出 就是这个特性图像嵌入 同样 你可以嵌入单词 短语 当你在做推荐系统时 里面有歌曲名 或者产品名 他们都是通过向量表示的 所以 它们只是嵌入 总的来说 嵌入只是将字符串 映射到持续的数字序列 或者数字向量 我们已经在 iOS 12 里 非常成功地使用了这些嵌入 我将向大家介绍 如何在照片中使用嵌入
在照片搜索中 当你输入一个想查找的词时 比如说 雷雨的照片 在屏幕下面 照片库里的所有照片 都通过卷积神经网络编了索引 卷积神经网络的输出 固定在一定数量的类上 可能是 1000 个类 也可能是 2000 个类 如果你的卷积神经网络 不知道雷雨是什么 那么你永远无法找到 雷雨的索引照片 因为不知道雷雨这个单词 但是因为有单词嵌入 我们知道雷雨和天空多云相关 这些标签 你的卷积神经网络是明白的 所以 在 iOS 12 中 你可以使用单词嵌入 在照片搜索中实现模糊搜索 所以 通过单词嵌入 你可以找到 自己想找的照片 实际上 它可以应用到 所有的搜索 App 如果你有一串字符 你想模糊搜索 你可以关联原单词 和与其相近的单词 说到这儿 你可以用嵌入 做些什么呢 你可以用单词嵌入 进行 4 项基本操作 一是 你可以得到 一个单词的向量
二是 如果有两个单词 你可以找到两个词的距离 因为你可以查看 每个单词的 对应向量 比如说 猫和狗 如果我想得到这两个词 之间的距离 那么这个距离 应该挺近的 但如果是 狗和靴子 那么在语义场内 它们距离应该挺远 那么你会得到更远一些的距离
三是 你可以得到 和某个单词最相近的词 这应该是到目前为止 对于单词嵌入 最流行的用法 我刚才展示的照片搜索 App 正是在做这个 寻找和某个单词最相近的单词 最后一点是 你可以得到一个向量的最近邻居 假设你有一个句子 句子里有好几个单词 句子里每一个单词 都可以得到一个单词嵌入 你可以把它们 总结起来 这样你会得到一个新的向量 有了这个向量 你就可以得到 所有和这个向量相近的单词 这也是一种应用单词嵌入的方法 单词嵌入内容很多 但是最重要的是 我们为你提供了这个功能 你可以在 OS 上 便捷地使用它 很高兴告诉大家 这些单词嵌入 支持 7 种语言 我刚才提到的所有功能 都只需要一两行代码 就可以实现 单词嵌入支持 7 种语言 英语 西班牙语 法语 意大利语 德语 葡萄牙语和简体中文
非常棒 OS 嵌入通常是在 通用语料库上构建的 文本数量庞大 有数亿单词 所以他们对于 某个词和其他词的关系 有一个大致概念 但是很多时候 你想做一些更自定义的事
也许你活跃在 不同的领域 医药领域 法律领域 或金融领域 如果你的领域各不相同 那么你想在 App 中 使用的词汇 会非常不同 也许你只是想 让一个 OS 不支持的语言 实现单词嵌入 你应该怎么做呢 我们对此也有准备 你可以使用自定义单词嵌入 对于熟悉单词嵌入 见证这个领域发展的人 有许多第三方工具 可以训练自定义嵌入 比如 word2vec GloVe fasttext 所以 你可以用自己的文本 也可以用自己在 Keras TensorFlow 或 PyTorch 训练的自定义神经网络 你可以通过原始文本 创建自己的嵌入 你也可以从任一网站 下载它们训练好的 单词嵌入 问题是 你要下载的这些嵌入 体积非常非常大 1GB 或 2GB 那么大 但是你想非常精简有效地 在你的 App 中使用它们 我们实现了这一点 这些来自第三方 App 的嵌入 体积非常大 我们自动将它们 压缩成非常紧凑的格式 有了这个格式 你就可以像用 OS 嵌入一样 使用它们了 接下来将由 Doug 为大家介绍 如何使用 OS 嵌入 和自定义嵌入 他会给大家做个示范 后半段的讲演交给他了 轮到你了 Doug
好的 我将通过一个演示 App 向大家展示运行起来 是什么样的 首先 我写了个 非常小的演示 App 帮助大家理解 单词嵌入 在这儿键入一个单词 它会显示最近的邻居 嵌入空间内 离那个单词最近的邻居 我们先从英语开始 使用内置 OS 单词嵌入 我键入一个单词 比如椅子 可以看到 它的邻居都是 意思和它相近的单词 椅子 沙发 长榻 等等 我也可以键入自行车 最近的邻居是 自行车 摩托车 等等 这些单词意思 和自行车相近 我也可以键入 书 就能得到和书意思相近的词 从这里 我们可以看出 内置 OS 单词嵌入 显示原本的 词义和语言 并识别出该语言在 通用文本里相近的意思
当然 这里我最感兴趣的是 这些嵌入 和奶酪有什么关系 毕竟我们做的是 奶酪 App 所以 我们键入一个 奶酪 单词
看一下这里 你立刻就能看到 内置嵌入知道奶酪是什么 但是我很失望 这些嵌入只知道奶酪 但不了解任何细节
否则 他们就不会把这些特殊的奶酪 和奶酪相关的东西 放在一起 它们不应该放在一起 我想要的效果是 它能明白 奶酪之间的关系 所以 我就趁机训练 我自己的自定义奶酪嵌入 它会基于相似性 把奶酪放在一起 切换到自定义嵌入
这些是自定义奶酪嵌入里的 切德干酪的邻居 这样就好多了 可以看到 它把 和切德干酪 口感相似的奶酪 放在了一起 比如 兰开夏奶酪 格洛斯特硬干酪和柴郡白干酪 这是我们可以用在 App 里的东西 现在 我们再来看一下 奶酪 App 是什么样的
我在这个奶酪 App 上 尝试了一些想法 看一下现在它的样子 当用户键入时 首先我会得到 一个情感分值 看一下这是否是一句 积极情感的话 如果是的话 我会用我的标注 检查一下这句话 当然 也会用我们的 自定义奶酪 Gazetteer 查看这句话里有没有提到什么奶酪 我在找有没有提及奶酪 如果用户真的提及了 我就会把这个名字 传送到自定义奶酪嵌入 查找相关奶酪
听起来挺好的吧 我们试一下 调出我们的奶酪 App 去年我去荷兰旅游 然后我爱上了 荷兰奶酪 我将把这个告诉我的 App 这肯定是一句 情感积极的话 而且确实提及了 一种特定的奶酪 然后我的 App 就可以为我推荐 和我刚才提到的奶酪 相似的奶酪
这展示了单词嵌入的功能 不仅如此 它还展示了自然的 多变的 NaturalLanguage API 是如何和 App 功能 结合到一起的
现在我们退回幻灯片 我想要简单的回顾一下 在 API 中 这个是什么样子的 如果你想要用 内置的 OS 单词嵌入 非常简单 你要做的就是请求 请求某个特定语言的 单词嵌入 我们就会给你 一旦你有了这些 NLEmbedding 对象的其中一个 你就可以用它做很多事情 当然 你可以得到组件 向量组件 和任何特定目录相对应
你可以得到在嵌入空间中 两个单词之间的距离 是近还是远 正如在奶酪 App 里所见 你可以浏览 找到在这个嵌入空间内 任何特定名称 最近的邻居 如果你想用自定义单词嵌入 要创建它 你可以用 Create ML 当然你需要 所有表示嵌入的向量 我不能在这里 通过幻灯片 向大家展示所有的向量 因为他们有 50 或者 100 个组件那么长 但是这儿有一个例子 在实际操作中 你可能从一个文件中引入它们 使用各种 Create ML 工具 从文件中 加载数据 然后你就可以从中 创建一个单词嵌入对象 将它写到磁盘上 这么做时 发生了什么呢 在实际操作中 这些嵌入一般会比较大 数百维 乘以数千个条目 体积会很大 会占用很多磁盘空间 搜索就会比较贵 当你把它们 编译进单词嵌入对象时 在内部 我们做的是 用产品量化技术 实现很高程度的压缩 然后添加索引 这样你就可以快速搜索 最近的邻居 就像我们的示范一样 来试一下 我们有一些 开源的 非常大的嵌入 这些是 GloVe 和 fasttext 嵌入 未压缩的格式 有 1GB 或 2GB 大 当我们把它压缩成 NL 压缩格式时 它们只有几十兆 只需要几毫秒 你就可以搜索到 离它们最近的邻居
有个 Apple 的例子 有个 Apple 的例子 Apple 做了许多播客 我们和播客团队 交流了一下 他们有一个 为播客制作的嵌入 表示各种播客之间的相似性 所以我们想试一下 看看把这个嵌入 做成 NL 嵌入格式 会发生什么 这个嵌入代表 66,000 个不同的播客 原格式有 167MB 但是我们压缩了它 现在只占 3MB NL 嵌入的功能就是 添加这些嵌入 在你的 App 里 设备上使用它们
好的 接下来我想换一个话题 介绍另一个 和单词嵌入相关的东西 那就是文本分类的迁移学习
我想先谈一下 我们是如何 训练文本分类的
在我们训练文本分类时 我们给他一系列 各种类的例子 把这些数据传送给 Create ML Create ML 会调用自然语言 训练分类器 生成一个 Core ML 模型 我们希望 这些例子会充分提供 关于各类的信息 这样模型就可以概括 分类它没有 见过的例子 当然 去年 这个功能已经上市了 我们有训练这些模型的算法 最出名的是 我们的标准算法 我们称之为 maxEnt 算法 它基于逻辑压缩 快速 强大 有效 但是有一个问题 除了你给的 训练资料外 它不知道其他的东西 这样你就要确保 你给他的训练材料 包括你希望 在实际操作中 能看到的所有东西 在某种意义上说 我们提供算法 比较简单 比较困难的部分留给了你们 那就是提供训练数据 但是如果我们用 已知的语言知识 结合我们提供的 体积小一点的训练材料 来训练模型 这样不是很好吗? 通过两者的结合 它会理解更多的实例 即便是训练材料 没有那么多
这就是迁移学习的目标 这是 NLP 重点研究领域 很高兴 我们已经 找到了一个解决办法 现在介绍给大家 自然语言训练模型 生成一个 Core ML 模型 但是我们怎么结合 已知的语言知识呢 我们从哪儿得到这个知识呢
单词嵌入提供了许多语言的知识 尤其是 它们知道 单词的许多意思 我们的方法是 有单词嵌入 和你提供的训练材料 把他们放入单词嵌入 在此之上 训练神经网络模型 这样我们就得到了 迁移学习文本分类模型
看起来比较复杂 但是如果你想用 你只需要请求
在训练迁移学习模型时 你只需要在算法规范里 改变一个参数 现在这里有几个选择 首先 显而易见 你可以用 表示单词原意的 内置 OS 单词嵌入 如果你有一个 自定义单词嵌入 也可以用 我们知道一个给定单词 可以有不同的意思 这个词的意思 取决于上下文 比如 Apple 在这两句话中 意思完全不同
我们希望 用在迁移学习上的嵌入 可以根据单词的 意思和上下文 给这些单词不同的值 当然 普通的单词嵌入 只是将单词映射到向量 不管单词是什么意思 它只能给出 同样的值
但我们做的是 训练一个特殊嵌入 让它根据单词的 意思和上下文 给出不同的值 大家可以感受到 这个领域发展的有多快 这只是一年前 我们在研究的东西 现在就可以公布出来 如果你想用 你只需要请求 指定一个动态嵌入 这个动态嵌入 会根据单词 所处的上下文 改变单词的值 这是做文本分类的迁移学习 非常强大的一个技术
看一下示范
好的 这里是一些 用 Create ML 训练文本分类 非常标准的代码 和我即将训练的东西 它基于一个数据集 从一个名为 DBpedia 的 开源百科全书中得到的 它包含许多话题的 简短词条 一些是关于人 艺术家 作家 植物 动物等等 这里的任务是 根据词条确定分类 是一个人 还是一个作家 或艺术家 等等 有 14 种不同的类 我想通过 200 个实例 尝试训练分类器 这是一个非常困难的任务 我们用现有的 maxEnt 模型 来尝试一下
快速写入发送 开始 结束了
非常快 非常简单 看一下测试集的表现情况 77% 的准确率
还可以 但是能更好吗 稍微改动一下 这里的代码 不再使用 maxEnt 模型 而是使用 带有动态嵌入的迁移学习 开始试一下
正如我刚才所说 这是在训练一个神经网络模型 所以时间会久一点 所以在它训练时 我们可以细看一下 正在训练的数据 实际上 在你训练神经网络模型时 你需要关注 训练使用的数据 这个数据是 跨多个类的随机实例 我整理了一下 所以每个类的 实例数大致相同 这是一个比较均衡的集
我们的训练集 另外我们还有一个 单独的验证集 也是跨类的随机实例 也许没有训练集 体积那么大 但也是均衡的 验证集在这种训练中 尤为重要 神经网络训练 容易过度拟合 会或多或少记住训练内容 但不会概括总结 验证集 会确保它 继续概括 当然我们还有一个 单独的测试集 实例也是随机但均衡的 当然 训练验证测试集之间 没有重叠部分 不然就是欺骗
我们需要测试集 查看我们在做什么 尤其是在这个例子中 有了测试集 我们就知道迁移学习模型 是不是比 maxEnt 模型好 好像是结束了 我们来看一下 在这里我们可以看到 迁移学习实现了 86.5% 的正确率 比 maxEnt 模型好很多 那么如何把这个应用到 我们的奶酪 App 呢 我已经有 奶酪口味的笔记
按它们提到的奶酪 给每一个都标上了标签 我将用这个 训练分类器模型 我的奶酪分类器模型 会拿到一个句子 尝试对他进行分类 找到它最接近的是哪种奶酪 把它放入我的奶酪 App 我将在这个奶酪 App 里做的是 如果用户 没有特别提到一种奶酪 那么我需要尝试找出 他们想要哪种奶酪 我要做的只是向模型请求 文本的标签非常简单 我们来试一下
在这里输入一句话
然后让奶酪器分类解析它 奶酪分类器判定 我想要的最接近 卡芒贝尔奶酪 然后我的奶酪嵌入 会推荐一些 其他相似的奶酪 布里奶酪等等
我也可以输入
质地结实的奶酪 它认定为是 切达奶酪 并推荐了一些相似的奶酪 这向我们展示了 文本分类结合其他 NaturalLanguage API 的 强大功能 最后我将说明一些 使用文本分类 必须要考虑的问题 首先我们要注意 哪些语言支持迁移学习 考虑上下文 不论是通过静态嵌入 还是通过 动态嵌入 然后我想再说一下 数据方面的问题
处理数据的 第一要求是 你必须要了解 自己的领域
在实际操作中 你将遇到什么样的文本 是句子片段 还是完整的句子 还是多个句子 确保你的训练数据 和在实际情况中 可能遇到 需要分类的数据 尽量的相似
并且尽量全面地包括 你在 App 中 可能遇到的 文本的变体
就像刚才在 DBpedia 例子中 看到的那样 你要确保实例 尽量是随机的 训练集 验证集 测试集 尽量不同 这是基本的数据要求 如何知道 哪个算法最适合你呢 普遍来讲 你需要尝试 但是也有一些参考 你可以先尝试 maxEnt 分类器 它速度很快 它会给你一个答案
但是 maxEnt 分类器能做什么呢 maxEnt 分类器 可以识别训练材料中 最常出现的词 比如说 你想训练识别积极和消极情感 它可能会注意到 爱和幸福是积极的 恨和不开心是消极的 如果实际使用中 遇到了这些单词 那么 maxEnt 分类器 就会做得很好 迁移学习做了什么呢 它注意的是不是单词的意思呢 如果在实际操作中 遇到了用不同的单词 表达相同意思的情况 这时迁移学习模型 就会大放异彩 它做的就会 比普通的 maxEnt 模型好 总的来说 我们有一些新的 API 可以用于情感分析 可以结合 MLGazetteer 用于文本目录 可以结合 NL 嵌入 用于单词嵌入 我们有一种新型的文本分类 因为可以用迁移学习 所以这个新类型特别强大
希望这些可以在你的 App 中 起到帮助作用 线上还有更多的信息 你也可以查看其他 相关的讲解
谢谢 [掌声]
-