-
创建由 Apple Silicon 提供支持的图像处理 app
了解如何针对 Apple Silicon 芯片优化图像处理 app。探索如何利用 Metal 渲染命令编码器、分块着色、统一内存架构和无内存附件。我们将展示如何利用 Apple 独特的分块式延迟渲染架构来创建低内存占用的节能 app,并带您了解将基于计算的 app 从独立 GPU 迁移到 Apple Silicon 芯片的最佳实践。
资源
- Debugging the shaders within a draw command or compute dispatch
- Metal Feature Set Tables
- Metal
- Metal Shading Language Specification
相关视频
WWDC20
-
搜索此视频…
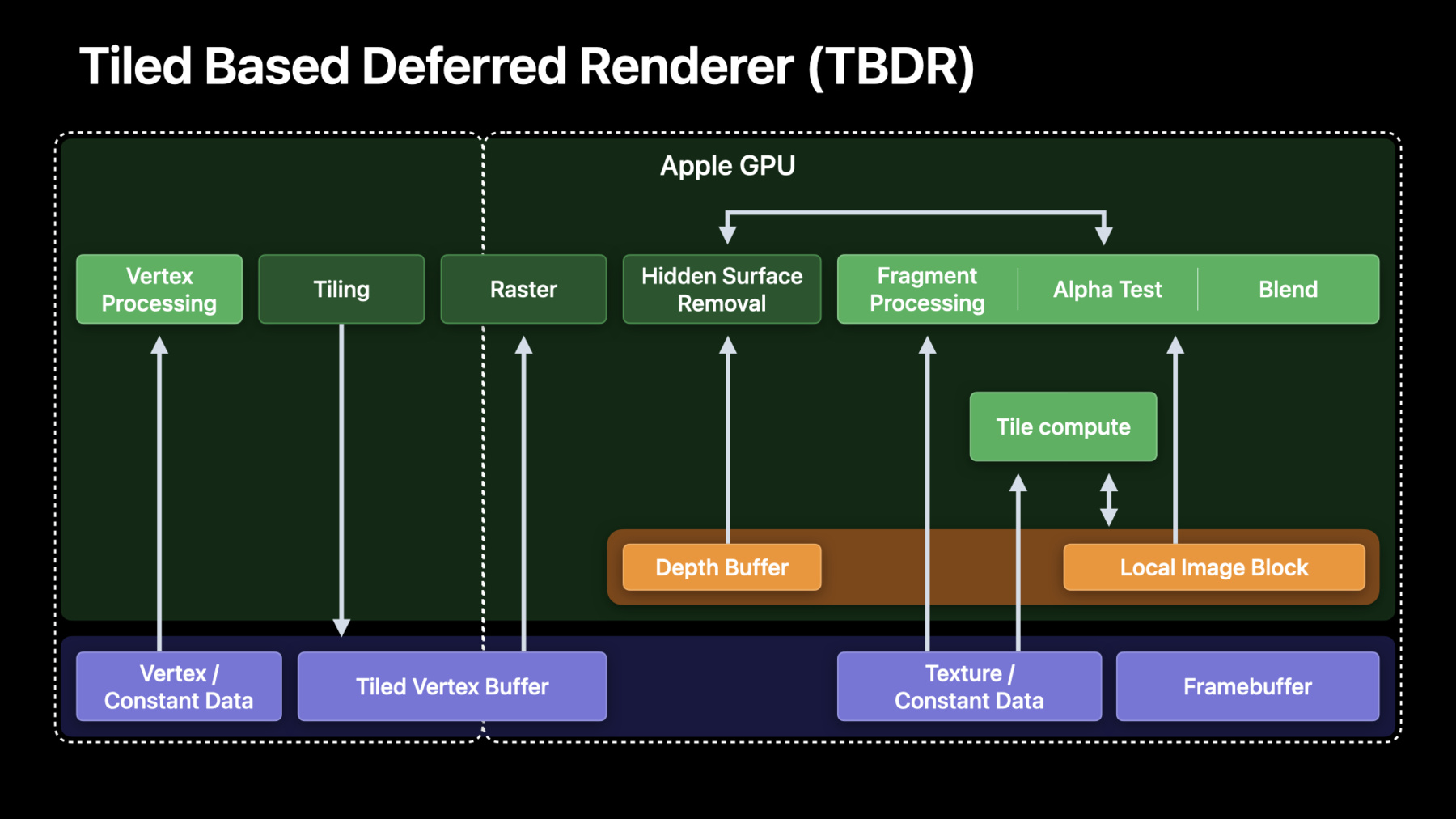
♪ (创建Apple Silicon 驱动的图像处理应用程序) 大家好 欢迎来到WWDC 我叫尤金·日德科夫 来自GPU软件部门 我将同Mac系统架构部门的 哈什·帕提尔一起 向大家介绍如何基于在 Apple silicon上 运行的Metal 创建图形处理应用程序 首先 我会重点介绍 最佳实践和所得经验 这些归功于开发者在过去一年中 参与优化在M1上运行的 图像处理应用 然后哈什会逐步指导 对Apple silicon 如何重新设计图像处理管道 从而获得最佳效果 让我们开始吧 首先 简单看一下 Apple系统芯片架构 及其优点 很多图像处理和视频编辑应用程序 是基于独立GPU设计的 因此必须考虑到独立GPU 和Apple GPU的区别 首先 所有Apple芯片使用的是 统一内存架构 所有组件 例如CPU GPU 神经和媒体引擎 都使用统一的内存接口 访问同一个系统内存 其次 我们的GPU使用 区块延迟渲染器 也就是TBDR TBDR有两个主要阶段 在区块阶段 将渲染面分成块状 然后独立处理几何图形 渲染阶段 全部像素由各区块处理 为使Apple silicon 架构达到最高效率 图像处理应用程序 应当使用统一内存 避免管道存在任何副本 并且利用区块内存和本地图像块 搭建TBDR架构 想了解关于Apple TBDR 如何低耗能工作 以及如何定位着色器核心的更多信息 请观看去年的课程 现在来看下 如何针对 Apple silicon 优化图像处理计算负载 去年 我们与很多优秀开发者密切合作 研究图像管道过渡 我们选择了六个 最有价值的技巧来分享 首先要讨论的是如何避免 不必要的内存副本或位块传输 鉴于目前处理的画面分辨率高达8K 这一点非常重要 然后 我们要着重介绍 使用渲染管道和纹理 代替缓冲区计算的优点 以及如何应用于 您自己的图像处理管道 当渲染和纹理通道 开启运行后 我们将展示合理装载/存储 和无内存附件的重要性 这将有助于最大限度地利用区块内存 然后 我们将介绍 对Uber-shaders 使用动态控制流的最佳方法 以及如何利用较小数据类型 例如短整型和半整型 从而提高性能和效率 最后是 关于最佳通量纹理格式的重要建议 好了 先从最有价值的技巧开始 避免Apple silicon 出现不必要位块传输 绝大多数图像处理应用程序 是基于独立GPU设计的 通过独立GPU 可以获取独立的系统内存和视频内存 为了使帧图像可见或常驻GPU 需要显式复制 而且需要复制两次 从而上传数据 供GPU处理并传回 假设我们解码一个8K视频 对其进行处理 并保存到硬盘 这种情况下是CPU线程进行解码 需要将解码后的框架 复制到GPU VRAM上 这里是GPU时间线 使用了所有的效果和过滤器 让我们进行下一步 然后再回来看 我们要把结果存储在硬盘上 对吗? 因此必须将处理过的框架 传回系统内存 和实际解码框架 这些被称为复制 或位块传输空白 而先进的图像处理应用 需要深度管道化和其他技术 来填充 好消息是利用Apple GPU 不再需要 进行这部分工作 因为内存是共享的 CPU和GPU均可直接访问 添加一行简单的代码 来检测是否在统一内存系统上运行 避免产生不必要的副本 从而节省您的内存和 时间 这是首要进行的一步 现在我们的统一内存架构中 位块传输已经被移除了 移除后 完全避免了复制空白 因此可以立即开始进程 这也给CPU和GPU管道化 减少了麻烦 请确保实现统一的内存路径 没有产生额外副本 如果在独立GPU上 保留位块传输副本 会损耗系统内存带宽 降低GPU实际运行效率 增加潜在调度消耗 而且 我们不需要再进行 独立的VRAM图像分配了 GPU帧捕获可以找出大的位块传输 请认真检查 确保只复制了必需的内容 下面介绍 如何利用Apple GPU TBDR架构 处理图像 大多数图像处理应用程序 通过调度一系列计算内核 对图像缓冲区进行操作 当在默认的串行模式下 调度一个计算内核 Metal可以确保所有后续调用 都能访问全部内存写入 可以使所有着色器内核 保持内存一致性 所以下一次调用开始时 每个内存写入都对其他内核可见 这也意味着内存流量可能会很高 整个图像都必须被读取写入 通过M1芯片 Apple GPU 可在MacOS上调用区块 与常规计算不同的是 仅利用区块同步点 进行区块存储 一些过滤器 比如卷积 不能被映射到区块模式 但很多其他的过滤器可以 推迟系统内存刷新直到编码器结束点 能提高效率 可以使GPU执行更多工作 不受系统内存带宽限制 进一步来说 很多独立像素的操作 不需要访问相邻像素 因此也不需要区块同步点 可以很好映射到片段函数 运行片段函数 不需要区块同步 除非编码器边界要求同步 或者区块内核在片段内核之后 要求串行调度 我们现在了解了Apple GPU 可启用片段功能 和区块内核 从而实现 更有效的图像处理 再来看看如何使用它 把调用缓冲区常规计算 转换为纹理渲染命令编码器 下面就靠经验法则了 没有像素依赖性的独立像素 应该使用片段函数来实现 任何有线程组范围操作的过滤器 都应该用区块着色实现 因为需要在一个区块内访问相邻像素 分散-聚集 和卷积过滤器 不能被映射到区块模式 因为需要随机访问 因此应该包含在计算调度中 渲染命令编码器 具备独特的AppleGPU功能 对纹理和渲染目标进行无损带宽压缩 能非常显著地节省带宽 尤其是对于图像处理管道 那么 来看看如何使用它 提到无损压缩 说明不应该做什么 更容易一些 首先 已经压缩的纹理格式 不利于无损压缩 其次 有三个特殊的纹理标志 不能用于压缩 所以要确保您没有无意中设置 上述纹理标志 第三 线性纹理 或MTLBuffer支持的纹理 也不允许出现 对于非私有纹理 还需要进行一些特殊操作 确保GPU访问内容的优化 从而保持最快路径 GPU帧捕获摘要窗格 出现了无损压缩警告 并说明了程序退出原因 在本例中 设置了像素格式视图标记 在很多情况下 开发者可能会无意中设置标记 如果需要swizzle组件或 sRGB转换 不要设置像素格式视图 好了 现在渲染和纹理路径 开始运行了 现在 我们来确认一下 是否正确使用了区块存储 TBDR的区块存储理念 比如加载/存储和无存储附件 对桌面环境来说是全新的理念 所以需要确保使用正确 现在开始加载/存储 我们已经知道 整个渲染目标被分割成区块 对每个单元批量进行加载/存储 保证在内存层次结构中 选择了最优路径 在渲染通道起始处执行 设置GPU初始化区块内存的模式 并在通道末尾 返回并写入GPU所需附件 这里的关键问题是 要避免载入不需要的信息 如果要覆盖整个图像 或者资源是临时资源 将加载动作设置为Load ActionDontCare 利用渲染解码器 不再需要清除输出或临时数据 不再像以前一样 需要专门计算通道 或调用fillBuffer 设置 LoadActionClear 可以有效地设置清除值 对于存储也是如此 请确保只存储以后需要的数据 例如主要附件 不要储存任何临时数据 除了明确的加载和存储 AppleGPU还通过无记忆附件 节省了内存占用 通过无记忆储存模式 我们就可以明确地定义一个附件 仅区块内存分配的功能 意味着将只在编码器运行周期内 为每一个区块持续储存数据 这可以大大减少内存占用率 尤其是对于6K/8K图像 其中每一帧都需要数百兆 让我们看看这一切如何 在编码器中完成 首先创建纹理描述符 然后创建输出纹理 再创建一个临时纹理 请注意我已经把它标记为无记忆 因为我们不希望这里有任何存储 然后我们创建渲染通道 首先描述附件 然后设定负载/存储 我们并不关心加载的输出 因为它被完全覆盖了 我们需要存储它 我们不加载临时纹理 而是需要将其清除 也不需要将其存储 最后用描述符创建渲染通道 完成了 我们正在使用统一内存 将图像处理管道 转到渲染命令编码器 并合理利用了区块存储 现在来讲一下uber着色器 uber着色器 或uber核心 应用非常广泛 可以让开发者的工作更轻松 主机代码设置控制结构 着色器只是循环 一系列if/else语句 比如启用色调映射时 或者输入HDR或SDR格式时 这种方法被称为uber着色器 可以很好地 减少管道状态对象总数 然而也有不足之处 主要是增加了寄存器压力 从而适应更复杂的控制流 使用更多的寄存器 能限制着色器运行的最大占用率 我们考虑将控制结构传入简单内核 可以使用结构中的标志来控制 这里有两个特性 假如输入HDR格式并启用色调映射 看上去不错 对吗 那么GPU上发生了什么呢 由于不能在编译时推断出任何事情 我们必须假设有两个通道 HDR和非HDR 在标记处结合 色调映射也是如此 对其进行评估 然后根据输入标记 选择输入或输出 这里的难点是寄存器 每个控制流路径都需要寄存器 这是uber着色器表现不佳的地方 正如您所知道的 内核使用的寄存器 决定着色器可以运行的最大占用率 这是因为寄存器文件 被着色器核心上所有模拟路径共享 如果只运行需要的程序 将提高模拟组并发性 和GPU利用率 我们来看下如何解决这个问题 Metal API提供了正确方法 即 function_constants 将两个控制参数设为 function_constants 然后对代码进行相应的修改 这是修改后的内核代码 主机端也必须更新 以便在管道创建时提供函数常量值 另一个好方法是 通过在着色器中使用16位类型 从而减少寄存器压力 AppleGPU有原生16位支持 因此当使用较小数据类型时 着色器所需寄存器更少 利用率更高 半整型和短整型所需能耗更少 可达到更高的峰值速率 因此尽可能使用半整型和短整型 代替浮点型和整数型 数据类型通常可自由转换 在这个例子中 考虑到内核使用的是 线程组中的thread_position 进行计算 我们使用的是无符号整数型 但Metal所支持的最大线程组 可以轻松适用无符号短整型 然而 threadgroup_position_in_grid 可能需要更大的数据类型 但对于图像处理中使用的网格大小 高达8K或16K 无符号短整型也足够了 如果使用16位类型代替 所产生的代码使用较少的寄存器 有可能增加占用率 现在 我来演示一下 如何查看寄存器的所有细节 Xcode13的GPU框架调试器 将高级管道状态对象 视图用于渲染 区块并计算PSO 可通过寄存器来检查 详细的管道统计数据 并对所有着色器进行微调 介绍完寄存器 下面介绍纹理格式 首先要注意 不同的像素格式 可能有不同的采样率 由于硬件生成和通道数量的不同 更宽的浮点类型 可能会降低点采样率 特别是浮点格式 例如RGBA32F 在对过滤值进行采样时 将比FP16变量慢 较小数据类型减少内存存储 带宽 以及缓存占用空间 因此我们还是建议 尽可能使用最小数据类型 但在这个例子中 还要考虑纹理存储 图像处理中的3D LUTs 实际很常见 我们所使用的大多数应用程序 都使用浮点RGBA 针对启用 双线性滤波的3D LUT应用阶段 请考虑您的应用程序能否改用半整型 并且有足够精确度 如果是这种情况 立即切换到FP16 以获得峰值采样率 如果整型数精确度不够 定点无符号短码 提供了良好的统一取值范围 因此用单位比例编码LUT 并向着色器提供LUT范围 可以很好地获得峰值采样率 并保证足够的数值精确度 好 我们刚刚讲完了 应该如何利用AppleGPU架构 使图像处理管道尽可能高效地运行 想要立刻开始实践 有请哈什 谢谢 尤金 现在 让我们根据迄今为止 学到的所有最佳实践 重新设计一个 基于Apple silicon 架构的图像处理管道 具体来说 我们将为AppleGPU 定制视频处理管道的图像处理阶段 实时图像处理 对GPU计算和内存带宽要求非常高 我们首先来了解 通常如何设计 对Apple silicon 如何进行优化 我们不打算在本节中讨论 视频编辑工作流程的细节 这部分请参考两年前的会议课程 我们只讨论将图像处理的计算部分 过渡到渲染路径 在开始之前 先快速看一下图像处理阶段 在典型视频处理管道中的位置 以ProRes编码的输入文件为例 首先从磁盘或外部存储器中 读取ProRes编码帧 然后在CPU上对该帧进行解码 图像处理阶段 在GPU上执行这个解码帧 并渲染出最终的输出帧 最后显示这个输出帧 此外还可以对最终渲染帧进行编码 用于传输 接下来 让我们来看看 图像处理管道的组成 图像处理开始时 首先将源图像RGB和alpha的不同通道 解包到独立的缓冲区 我们将在图像处理管道中 处理每一个通道 可同时处理 也可单独处理 接下来 可能需要转换色彩空间 以便在所需的色彩管理环境中操作 然后用3D LUT进行色彩校正 然后应用空间-时间降噪 卷积 模糊和其他效果 最后 将单独处理的通道打包在一起 用于最终输出 选择的这些步骤有什么共同点呢 它们都是点式过滤器 只在单个像素上操作 没有像素间的依赖性 这些都能很好地映射到碎片着色器 空间和卷积式操作 需要访问大半径像素 而我们也有分散的 读写访问模式 都很适合计算内核 我们稍后会用到这些知识 现在 来看看这些操作是如何执行的 应用程序将应用于图像的效果链 表示为一个过滤器图 每个过滤器都是它自己的内核 处理前一阶段的输入 并为下一阶段产生输出 这里的每个箭头都表示 一个缓冲区被写入/被一个阶段输出 并作为下一个阶段的输入被读取 由于内存是有限的 应用程序通常需要一个拓扑排序 来线性化图形 这是为了使中间资源总数尽可能少 同时也避免了竞争条件 该例子中的这个过滤器简易图 需要两个中间缓冲器 才能在没有竞争条件的情况下运行 并产生最终输出 这里的线性化图形 也大致代表GPU命令缓冲区的编码 让我们深入了解一下 为什么这个过滤图 占用这么多设备内存带宽 每个过滤操作都必须将整个图像 从设备内存加载到寄存器中 并将结果写回设备内存 而这是相当大的内存流量 让我们根据例子中的图像处理图 估算一下4K帧图像处理的 内存占用情况 一个4K解码帧本身 对于浮点16精确度来说 需要67兆的内存 对于浮点32精确度来说 需要135兆的内存 而专业工作流 绝对需要浮点32精确度 通过这个图像处理图 以浮点32精确度处理一个4K帧 我们谈论的是设备内存 超过两千兆的读写流量 另外 写入持有中间输出的缓冲区 也会冲击缓冲区的层次结构 并对芯片上的其他区块产生影响 常规的计算内核 不会从芯片上的隐含区块内存受益 内核可以明确分配线程组范围的内存 这些由芯片区块内存支持 然而 该区块内存 在计算编码器内的调用是不持续的 相比之下 区块内存 在一个渲染命令编码器内的 不同绘制通道中是持续的 让我们看看如何重新设计 这个有代表性的图像处理管道 从而更有效地利用区块内存 通过以下三个步骤来解决这个问题 首先将计算通道 改为渲染通道 所有中间输出缓冲区改为纹理 然后 将没有像素间依赖的 每个像素操作编码 为渲染命令编码器中的 片段着色器调用 确保考虑到所有的中间结果 并设置适当的加载/存储动作 最后讨论比点式过滤器 更复杂的情况下 该如何操作 第一步是使用 单独的MTLR渲染命令编码器 来编码合格的着色器 在这个滤镜图中 解包 色彩空间转换 LUT 和色彩校正过滤器 都是每个像素的点过滤器 可以将其转换为片段着色器 并使用渲染命令编码器对其进行编码 同样地 混合器和打包着色器 在这个图像处理管道的末端 也可以转换为 片段着色器 并使用另一个MTL 渲染命令编码器进行编码 然后可以在各自的渲染通道中 调用这些着色器 当创建渲染通道时 色彩附件上的所有资源 在该渲染通道中都可隐性区块化 一个片段着色器只能更新 与区块中片段位置相关的图像块数据 同一渲染通道中的下一个着色器 可以直接从区块内存中 获取前一个着色器的输出 在下一节 我们将展示 如何构建映射到这些过滤器的 片段着色器 我们还将介绍 需要定义和使用哪些结构 以便从这些片段着色器中 访问底层区块内存 最后 介绍一个片段着色器 在区块存储器中产生的输出 如何能被同一渲染命令编码器中 下一个片段着色器 直接从区块存储器中消耗 这是编码过程中必须做的事情 在这里 我将输出图像作为纹理 附在渲染通道描述符的色彩附件0上 并把持有中间结果的纹理 附在渲染通道描述符的色彩附件1中 它们都会被区块化 请按照之前我们讲过的 设置适当的加载/存储属性 现在 在片段着色器中 建立一个结构来访问这些纹理 在接下来的例子中 将展示如何在片段着色器中 使用这个结构 只需使用之前定义的结构 即可在片段着色器中 访问输出和中间纹理 这些纹理 是在与该片段相对应的 适当的区块内存位置进行的 由解包着色器产生的输出 被色彩空间转换着色器消耗作为输入 使用的是我们之前定义的相同结构 这个片段着色器可以自行处理 更新输出和中间纹理 这将再次 更新相应的区块内存位置 要在同一个渲染编码器通道中 对所有其他的片段着色器 需要按照同样的步骤操作 接下来 让我们设想一下 经过这些更改 这个操作序列的样式 正如您所看到的 现在经过解压 色彩空间转换 3D LUT应用 和色彩校正等步骤 都在区块内存上执行 使用一个渲染通道 中间没有设备内存通道 在渲染过程结束时 非无记忆的渲染目标 会存入设备内存 然后就可以运行下一类过滤器了 让我们再来谈谈 具有散点收集访问模式的过滤器 代表这种过滤器的内核 可以直接操作设备内存中的数据 卷积滤波器非常适合 用于操作计算内核中的区块 在这里 可通过标明 一个线程组范围的内存 来表示使用区块内存的意图 现在把像素块 和所有必要的光晕像素 存入区块存储器 这取决于过滤器的半径 并直接在区块内存上 执行卷积操作 请记住 计算编码器内的计算调用中 区块内存是不持续的 因此在执行Filter1之后 必须将区块内存中的内容 转入设备内存 这样Filter2就可以 消耗Filter1的输出 那么做出所有这些更改后 结局如何呢 通过例子中重组的图像处理图 以浮点32精确度处理一个4K帧 情况如下 带宽从2.16千兆 降到仅值810兆的加载和存储 这就使设备内存的流量 减少了62% 不需要两个中间设备缓冲区 每帧就可节省270兆的内存 最终 减少了高速缓存的占用 这是因为该渲染通道中 所有片段着色器 都是直接在区块内存上操作的 Apple silicon的 一个重要特性 就是它的统一内存架构 下面一个例子介绍如何利用 这个统一内存架构 在Apple silicon上的 不同块之间进行互动 我们将以GPU渲染的 最终视频帧的HEVC编码 作为一个案例研究 这种编码是使用 Apple silicon上的 专用硬件媒体引擎完成的 由GPU渲染的最终输出帧 可以直接被媒体引擎消耗 不产生额外的内存复制 下面的章节里 我们将通过一个例子说明 如何以最有效的方式 为GPU产生的最终输出帧 建立HEVC编码管道 为此 首先将利用 CoreVideo API 来创建一个由IOSurfaces 支持的像素缓冲池 然后利用Metal API 在刚才创建的缓冲池中 将最终帧渲染成 IOSurfaces支持的 Metal纹理 最后 将这些像素缓冲区 直接分配给媒体引擎进行编码 而不需要对GPU产生的输出帧 进行任何额外的复制 从而充分利用统一内存架构 我将分步展示如何做到这一点 并涵盖需要的所有结构 来实现这个工作流 首先 创建一个 由IOSurface支持的 CV像素缓冲池 以所支持的像素格式 这里 将使用双平面 色度超采样像素格式 进行HEVC编码 现在从CV像素缓冲池得到一个缓冲 将其传递给具有正确平面索引的 Metal纹理缓存 得到CVMetal纹理索引 由于使用的是双平面像素格式 需要对双平面像素缓冲器的两个平面 都执行这一步骤 从CVMetal纹理索引对象 得到底层Metal纹理 对亮度和色度平面 都执行这一步骤 请记住 这些Metal纹理 是由同样的 IOSurfaces支持的 也会支持 CVPixelBuffer平面 使用Metal API渲染成 与亮度和色度平面 相对应的纹理 这也将更新 支持这些Metal纹理的 IOSurface 我们强烈建议在GPU上 对色度平面进行色度子采样 作为图像处理管道中的着色器通道 需要注意的是 CVPixelBuffer 和刚刚渲染的Metal纹理 都是由系统内存中 相同的底层IOSurface 副本支持的 现在可以将这个 CVPixelBuffer 直接发送到媒体引擎进行编码 可以看到 由于统一内存架构 可以在GPU和媒体引擎块之间 无缝移动数据 没有内存拷贝 最后记得在每一帧之后 释放CVPixelBuffer和 CVMetalTexture参考 释放CVPixelBuffer 可使这个缓冲区在未来帧中循环使用 总结一下 我们建议 再次进行以下操作 利用统一内存架构 在适当情况下 使用MTL渲染命令解码器 而不是计算 在单个渲染命令编码器中 合并所有合格的渲染通道 设置适当的加载/存储动作 对瞬时资源使用无记忆附件 适当使用区块着色 对其他API使用缓冲池实现零拷贝 感谢您参加今天的课程 请继续观看接下来的 2021年度WWDC课程视频
♪
-
-
10:53 - Memoryless attachments
let textureDescriptor = MTLTextureDescriptor.texture2DDescriptor(…) let outputTexture = device.makeTexture(descriptor: textureDescriptor) textureDescriptor.storageMode = .memoryless let tempTexture = device.makeTexture(descriptor: textureDescriptor) let renderPassDesc = MTLRenderPassDescriptor() renderPassDesc.colorAttachments[0].texture = outputTexture renderPassDesc.colorAttachments[0].loadAction = .dontCare renderPassDesc.colorAttachments[0].storeAction = .store renderPassDesc.colorAttachments[1].texture = tempTexture renderPassDesc.colorAttachments[1].loadAction = .clear renderPassDesc.colorAttachments[1].storeAction = .dontCare let renderPass = commandBuffer.makeRenderCommandEncoder(descriptor: renderPassDesc) -
12:25 - Uber-shaders impact on registers
fragment float4 processPixel(const constant ParamsStr* cs [[ buffer(0) ]]) { if (cs->inputIsHDR) { // do HDR stuff } else { // do non-HDR stuff } if (cs->tonemapEnabled) { // tone map } } -
13:32 - Function constants for Uber-shaders
constant bool featureAEnabled[[function_constant(0)]]; constant bool featureBEnabled[[function_constant(1)]]; fragment float4 processPixel(...) { if (featureAEnabled) { // do A stuff } else { // do not-A stuff } if (featureBEnabled) { // do B stuff } } -
23:02 - Image processing filter graph
typedef struct { float4 OPTexture [[ color(0) ]]; float4 IntermediateTex [[ color(1) ]]; } FragmentIO; fragment FragmentIO Unpack(RasterizerData in [[ stage_in ]], texture2d<float, access::sample> srcImageTexture [[texture(0)]]) { FragmentIO out; //... // Run necessary per-pixel operations out.OPTexture = // assign computed value; out.IntermediateTex = // assign computed value; return out; } fragment FragmentIO CSC(RasterizerData in [[ stage_in ]], FragmentIO Input) { FragmentIO out; //... out.IntermediateTex = // assign computed value; return out; }
-