-
利用 Metal 为机器学习加速
了解如何在 macOS 上使用 Metal 加快您的 PyTorch 模型训练。我们将介绍 TensorFlow 训练支持的更新,探索 MPS Graph 的最新功能和操作,并分享最佳实践以帮助您提升性能,满足您对机器学习的需求。要进一步了解如何搭配使用 Metal 和机器学习,请观看 WWDC21 的“使用 Metal Performance Shaders Graph 加快机器学习速度”。
资源
相关视频
WWDC23
WWDC22
WWDC21
-
搜索此视频…
♪ ♪
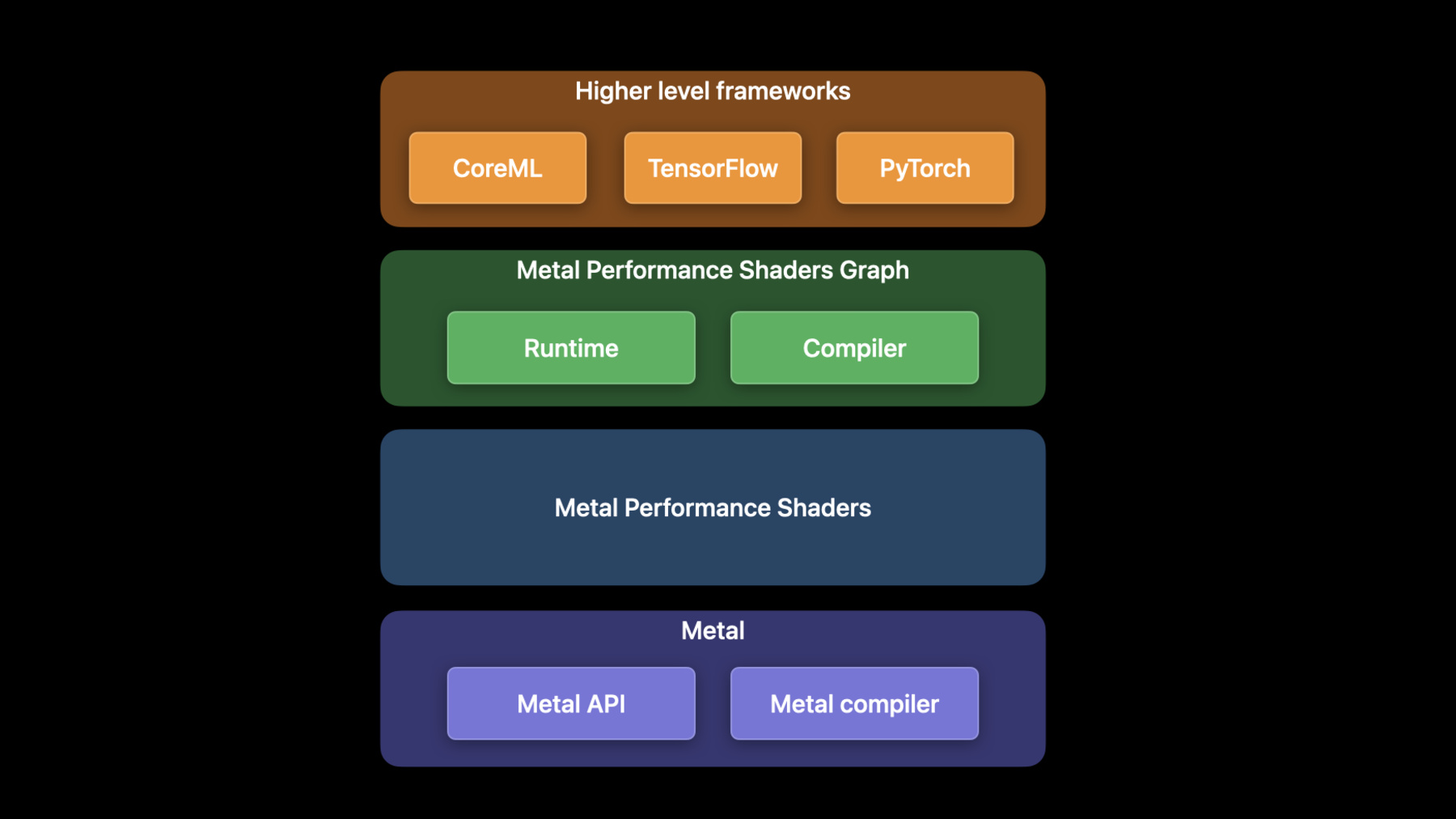
Dhruva: 欢迎来到 WWDC 2022 我叫 Dhruva 是一名 GPU 软件工程师 今天 Matteo 和我将探索 今年在 Metal 中 为机器学习引入的 所有新功能和增强功能 机器学习训练是 ML 管线中 计算最密集的过程 由于其并行性 GPU 在 ML 工作负载方面表现出色 Metal 机器学习 API 是通过一个 叫做 Metal Performance Shaders 或者简写为 MPS 的框架公开的 MPS 是一个高性能 GPU 元操作的集合 用于图像处理 线性代数 光线跟踪 和机器学习等各个领域 这些 Metal 内核经过优化 可在我们的所有平台上 提供最佳性能 例如 MPSImageCanny 过滤器 返回输入图像的边缘图 这是图像分割 App 中的常见操作 今年 Canny 滤波器处理 4K 高分辨率图像的速度提高了八倍 MPS Graph 是 GPU 的通用计算图 基于 MPS 框架构建 并扩展了对多维张量的支持 我建议您观看上一个讲座 以获得更多 关于如何使用 MPS Graph 的详细信息 像 CoreML 和 Tensorflow 这样的 高层 ML 框架 基于 MPS Graph 来实现 您可以使用 TensorFlow Metal 插件 在 GPU 上加速 TensorFlow 网络 有关如何充分利用 TensorFlow 的更多信息 请查看去年的讲座 Matteo 和我将在这个讲座里 讨论三个主题 首先 我将介绍 Apple GPU 支持的 最新 ML 框架 PyTorch 接下来 我将深入讨论 今年对 TensorFlow 所做的增强 最后 Matteo 将介绍 MPS Graph 框架中的新功能
我们非常高兴您现在能够 在 Mac GPUs 上 加速 PyTorch 网络 PyTorch 是一个流行的 开源机器学习框架 PyTorch 社区中呼声最高的功能 是支持 Apple 芯片上的 GPU 加速 我们通过向 PyTorch 生态系统 引入新的 MPS 后端 将 Metal 的能力带入 PyTorch 这个后端将成为 PyTorch 1.12 官方版本的一部分 MPS 后端实现了 PyTorch 操作内核 以及运行时框架 操作调用 MPS Graph 和 MPS 运行时组件使用 Metal 这使得 PyTorch 能够使用 MPS 的高效内核 以及 Metal 的指令队列 指令缓冲区和同步原语
操作内核和 PyTorch MPS 运行时组件 是开源代码的一部分 合并到了官方的 PyTorch GitHub repo 中 使用 MPS PyTorch 后端 是一个简单的三步过程 首先 从 PyTorch 1.12 开始 您可以使用 pip install torch 安装基础包 这个包可以在官方 python 包存储库中找到 有关环境设置和安装的更多详细信息 请参阅 Metal Developer Resources 网页 然后导入 PyTorch 并创建 MPS 设备 如果 MPS 设备后端可用 此代码段将使用该后端 否则将返回到 CPU 最后一步是转换您的模型和输入 以使用 MPS 设备 为了演示如何做到这一点 我将使用一个示例 该示例在来自 torchvision 预训练的 ResNet50 模型上运行推理 默认情况下 该模型将在 CPU 上运行 您可以使用 to 方法 将模型转换为使用 MPS 设备 这确保了模型内部的中间张量 也将使用加速的 MPS 后端 最后 您可以运行模型了 本示例将随机输入张量 传递给 MPS 模型 默认情况下 所有张量都分配在 CPU 上 为了使用 MPS 后端 您还需要在此处提供 MPS 设备 对这个张量的所有后续操作 都将在 GPU 上加速 最后 将样本输入 传递给 MPS_model 以获得预测 现在您已经知道了 如何使用 MPS 设备 我将向您展示 PyTorch 的一个实例 我一直想成为一名著名的艺术家 所以我决定使用机器学习 和我的 GPU 来帮助我使用 StyleTransfer 网络 创作艺术品 这个网络允许您将不同的艺术风格 应用于一幅图像 在本实例中 我们的目标是学习如何 将梵高在星夜中的风格 应用于这张猫的照片 借助新的 MPS 设备 您将能够使用 GPU 更快地训练 PyTorch 网络 为了演示这一点 我将在一台 M1 Max 上同时 在 CPU 和 GPU 上训练这个网络 学习这种风格需要数千次迭代 但 GPU 能够在更短的时间内 收敛到一个合理的模型
除了 StyleTransfer 我们还在所有 PyTorch 基准测试中 看到了惊人的加速 在 M1 Ultra 上 我们看到速度提高了 20 倍 平均速度提高了 8.3 倍 PyTorch 使机器学习模型的开发 变得很容易 通过使用 Apple GPU 对其进行训练 您将节省大量时间 接下来 我将深入讨论我们今年 对 TensorFlow 所做的所有增强 从 Tensorflow 2.5 版开始 Tensorflow Metal 加速就可以通过 Tensorflow Metal 插件来使用了 从那时起 又增加了一些附加功能和改进 其中对训练的增强包括包括更大批量 新的操作和定制操作支持 RNN 改进和分布式训练 TensorFlow Metal 插件版本 与 TensorFlow 主要版本保持一致 因此请确保更新 您的 TensorFlow 软件包 以获得最新的功能和改进 我们从更大批量开始 今年 TensorFlow-Metal 的软件改进 让您能够利用 Apple 芯片架构的独特优势 此图显示了使用不同批量大小 训练 ResNet50 模型的 加速效果 数据显示 批量越大 性能越好 因为每次梯度更新都更接近真实梯度 Apple 芯片的统一内存架构 允许您运行更大的网络或更大的批量 现在您可以在单个 Mac Studio 上运行您的工作负载 而不是将其拆分为一个云集群 这真的很棒 Apple 芯片架构还具有高效能功耗比 这意味着您的网络运行 比以往任何时候都更高效 接下来我将谈谈新操作和自定义操作 Tensorflow Metal 插件现在为各种新操作 提供了 GPU 加速 包括 argMin all pack 以及 adadelta 等等 但是如果您想要为 tensorflow API 当前不支持的操作 提供 GPU 加速该怎么办呢 为此 您需要创建一个自定义操作 下面是一个简单的卷积网络 运行两次迭代的示例 时间线分别表示 GPU 和 CPU 上 完成的工作 网络先进行卷积 之后进行 maxpool-ing 运算 然后进行 softmax 交叉熵损失运算 所有这些操作都是通过 MPS Graph 在 TensorFlow Metal 插件中 由 GPU 加速的 但您可能希望使用自定义损失函数 如果没有 MPS GPU 加速 来实现这一自定义损失 则需要在 CPU 时间线上 执行这项工作 这将引入同步开销并导致 GPU 饥饿状态 通过在 GPU 上进行这种自定义损失 您可以获得更好的性能 为了实现自定义操作 您需要了解 TensorFlow MetalStream 协议 这是用于编码 GPU 操作的协议 MetalStream 会保留 对用于编码 GPU 内核的 MTLCommandBuffer 的引用 它还暴露出 dispatch_queue 以便在编码时用于 CPU 端同步 因为可能有多个线程提交工作 使用 commit 或 commitAndWait 方法 将工作提交给 GPU CommitAndWait 是一个调试工具 它会一直等待当前命令缓冲区完成 这样您就可以观察序列化提交 现在让我们看看如何使用 这些概念来实现自定义 op 编写自定义操作有三个步骤 首先是注册操作 接下来 使用 MetalStream 实现该操作 最后将操作导入训练脚本并开始使用 我将从注册操作开始 使用 TensorFlow 核心 公开的 REGISTER_OP 宏 来指定 op 的语义 以及如何在 TensorFlow Metal 插件中定义它 接下来使用 TensorFlow_MetalStream 实现 op 首先定义 compute 函数 现在 在这个函数中 获取输入的 TensorFlow_Tensor 对象 并定义输出 这可能需要分配 然后使用 MetalStream 的命令缓冲区 创建一个编码器 接下来 定义自定义 GPU 内核 您的操作应该在 MetalStream 提供的 dispatch_queue 中进行编码 这确保了来自多个线程的提交 被序列化
然后使用 TensorFlow_MetalStream 协议中 提供的方法提交内核
最后 删除对分配张量的引用
最终 将操作导入到您的训练脚本中 开始使用它 在这一步中 构建定制 op 的 共享动态库文件 zero_out.so 有关如何构建和导入 .so 文件的信息 请参阅 Metal Developer Resources 此示例通过使用 TensorFlow load_op_library 将操作导入到训练脚本中 这是一个可选步骤 现在 这就像一个 python 包装器 我们的自定义 op 可以在训练脚本中调用 接下来 我想给您看一个 有趣的应用例子 叫做神经辐射场 或 NeRF 我们编写了一个自定义操作 通过启用 GPU 加速 实现更好的算法 从而提高了网络的性能
NeRF 是一种用于合成 模型 3D 视图的网络 为了训练 NeRF 从不同角度 获取一个物体的图像作为输入 NeRF 网络由两个堆叠的 多层感知器组成 输出模型的体积化表示 实时训练的关键性能优化 使用哈希表来实现 更新的网络允许更小的多层感知器 TensorFlow 本身不支持哈希表 所以我们使用自定义 op 功能 在 Metal 插件中实现它们 哈希表的 GPU 加速 可以更快地训练 NeRF 我将从这台 MacBook 开始 运行原始的多层感知器实现过程
为了呈现出合理的内容 我们至少需要 20 个 epoch 但每个 epoch 大约需要 100 秒 这意味着大约需要30分钟 才能看到一些东西 因此 现在我将从预先训练的 检查点文件中重新开始训练 该文件需要提前 30 分钟进行训练 这要从 epoch 20 开始 即使经过 30 分钟的训练 3D 模型也是模糊不清的 网络需要更长的训练时间 来学习更清晰的模型 原有的两层堆叠多层感知器方法 没有自定义哈希表 速度太慢 现在 在这台 MacBook 上 我将推出使用自定义哈希表的 优化版本 这种实现过程已经能够 呈现更清晰的模型 并且每个 epoch 仅需要 10 秒来学习 有关该项目的更多信息 请查看我们上传到 Metal Developer Resources 的示例代码
NeRF 只是众多网络中的一个 它展示了如何为您自己的 定制操作实现 GPU 加速 从而使您的网络运行得非常快 我期待着进一步了解 您所做的所有创造性定制 现在我想向您展示如何使用 Apple GPU 来分布 ML 工作负载的训练 为了分布工作负载的训练 您可以在单独的流程中 运行训练脚本的多个实例 其中每个进程评估模型的单个迭代
每个进程将从中央数据存储中 读取数据 之后 它将运行模型并计算模型梯度 接下来 该进程将计算梯度的平均值 并相互通信 以便在下一次迭代之前 每个进程都具有相同的梯度 最后 模型被更新 您可以重复这个过程 直到所有的迭代都结束 为了在 TensorFlow 上演示这一点 我将使用一个分布式训练的例子 我将使用一个流行的开源框架 Horovod 来进行分布式训练
Horovod 使用环形全归约算法 在该算法中 N 个节点中的每个节点 与其两个对等节点 进行多次通信 使用这种通信方式 工作进程在每次迭代之前 同步梯度 我将使用四个通过 Thunderbolt 电缆相互连接的 Mac Studio 来展示这一点 在这个示例中 我将训练 ResNet 这是一个图像分类器 每个 Mac Studio 旁边的柱状图 显示了训练此网络时 GPU 的利用率 对于单个 Mac Studio 性能约为每秒 200 张图像 当我添加另一个通过 Thunderbolt 连接的 Mac Studio 时 性能几乎翻了一番 达到每秒 400 张图像 因为两个 GPU 都得到了充分利用 最后 当我连接 两个以上的 Mac Studio 时 性能提升到每秒 800 张图像 受限于计算的训练工作负载 几乎是以线性扩展
现在我们来看一下 TensorFlow 的分布式训练性能 这个图表显示了一个 两个和四个 Mac Studio 的相对加速 它们以环形拓扑连接 并使用最新的 TensorFlow Metal 插件 和 Horovod 运行计算 绑定 TensorFlow 网络 如 resNet 和 DistilBERT 基础是单个 Mac Studio 上的性能 该图显示 随着每个 GPU 的增加 网络性能会随之扩展 因此您现在可以 在多个设备上使用 GPU 以加快您的训练时间 并充分利用所有 Apple 设备
今年针对 TensorFlow 的所有改进 和功能最终都体现在这张图表中 该图表显示了 相对于 CPU 实现的性能 未来还会有更多改进 现在 Matteo 将分享 MPS Graph 框架中的新内容 Matteo: 谢谢您 Dhruva 大家好 我叫 Matteo 是一名 GPU 软件工程师 PyTorch 和 TensorFlow 位于 MPS 图形框架之上 反过来 MPS Graph 使用 MPS 框架 提供的并行原语 来加速 GPU 上的工作 今天我将讨论使用 MPS Graph 进一步加速计算工作负载的两个功能 首先 我将展示新的共享事件 API 它允许您在两个Graph 之间同步工作 接着 我将介绍新的操作 您可以使用 MPS Graph 做更多的事情 我将从共享事件 API 开始 在同一个命令队列上运行应用 可以确保工作负载之间的同步 在本例中 保证计算工作负载 总是在调度其他工作负载之前终止 如后期处理和显示 在这种情况下 您将在每个调用中 利用 GPU 并行性 然而 一些 App 可能会受益于 更多的并行性 其中 GPU 的第一部分用于计算 第二部分用于后处理和显示 这可以通过在多个命令队列上 向 GPU 提交工作来实现 不幸的是 在这种情况下 可能会在 计算产生结果之前调度后处理管道 从而引入数据竞争 Shared Event API 可以用来解决这个问题 并引入跨命令队列的同步 以确保满足工作流依赖性 在代码中使用共享事件非常简单 我们假设您正在处理两个 Graph 第一个负责计算工作负载 第二个负责后处理工作量 我们还要假设计算图的结果被用作 后处理图的输入 并且它们运行在不同的命令队列上 Metal System Trace 中的 新 MPS Graph 轨迹 表明命令队列相互重叠 这会产生数据竞争 您可以使用共享事件来解决这个问题 首先 使用 Metal 设备创建事件 接下来 调用执行描述符中的 信号方法 提供事件 动作和值 然后您所要做的就是 在第二个描述符上 调用 wait 方法 提供事件变量和值
现在 Metal System Trace 表明 两个命令队列是 按顺序运行的 并且计算和后处理图之间的 依赖关系已经解决 这就是如何使用共享事件 来解决 App 中的 同步问题 接着 我来说说 MPS Graph 支持的新操作 这些操作允许您 使用框架做更多的事情 我将从 RNNs 开始 介绍这些新操作的一些细节
MPS Graph 现在公开了 递归神经网络 App 中 常用的三种操作 就是 RNN LSTM 和 GRU 层 这些操作都是相似的 所以我今天只关注 LSTM LSTM 运算通常用于自然语言处理 和其他 App 下图显示了 LSTM 操作的工作原理 想了解更多信息 请查看我们之前的 WWDC 讲座 您可以自己完成 LSTM 单元 但要做到这一点 您必须构建这个相当复杂的自定义子图 相反 您可以使用新的 LSTM 操作 它可以有效地对重复单元所需的 所有 GPU 工作进行编码 这种新操作大大加快了 基于 LSTM 的 CoreML 推理模型的速度
要使用新的 LSTM 操作 首先创建一个 MPS GraphLSTMDescriptor 您可以根据需要修改描述符属性 例如选择激活函数 接下来 将 LSTM 单元添加到图中 提供输入张量 您还可以提供一个偏差向量 以及操作的初始状态和单元格 最后 提供描述符 这就是设置 LSTM 所需要做的全部工作 RNN 的其他操作也类似 我鼓励您尝试这些操作 看看您的 App 可以获得什么样的加速 接下来 我将向您展示 对 Max Pooling 的改进支持 Max Pooling 操作采用 输入张量和窗口大小 为窗口的每个应用 计算窗口内输入的最大值 它通常用于计算机视觉中 以降低图像的维度 该 API 已被扩展为 返回池化操作符提取的 最大值位置的索引 您可以在梯度通道中使用索引 其中梯度必须传播到 已提取出最大值的位置 新的 API 也适用于训练 对于 PyTorch 和 TensorFlow 在训练期间重复使用索引的速度 可以提高六倍
要在代码中对此进行设置 首先需要创建 GraphPooling 描述符 您可以指定 returnIndicesMode 例如 globalFlatten4D 然后您可以使用 Return Indices API 来调用图上的池操作 操作的结果是双重的 第一个是 poolingTensor 第二个是 indicesTensor 您可以缓存索引张量以备后用 例如在训练管道上使用
MPS Graph 现在公开了 一个新的并行随机数生成器 举个例子 它可以用来 初始化训练图的权重 新的随机操作使用 Philox 算法 并为给定的种子返回 与 TensorFlow 相同的结果 新的运算以一个状态张量作为输入 它返回一个随机张量作为输出 而且该随机张量可以用作 新的状态张量 举个例子 可以将其用作第二个随机操作的输入 要使用新的随机运算 请调用 randomPhiloxStateTensor 方法 这个方法用给定的种子 初始化一个输入状态张量 然后声明 RandomOp 描述符 它将分布和数据类型作为输入 在示例中 描述符指定了 32 位浮点值的截断正态分布 您也可以使用正态分布和均匀分布
通过指定平均值 标准差 最小值和最大值 您可以进一步定义分布特征 最后 您可以创建随机操作 提供刚刚创建的 形状张量 描述符和状态张量
除了 Random 之外 MPS Graph 现在还支持 一种新的 GPU 加速操作 来计算两个位向量之间的汉明距离 汉明距离被定义为 两个长度相同的输入之间不同的位数 是两个序列之间编辑距离的度量 它被用于从生物信息学 到密码学的若干应用 要使用汉明距离 请在图形上调用 API 提供 primaryTensor secondaryTensor 和结果数据类型 请注意 新内核支持在 GPU 上 通过批处理维度 进行广播 现在 我将向您展示新的张量操作 这些操作非常容易使用 您现在可以扩展张量的维度 例如 从二维扩展到三维 然后您可以把维度压缩回去
您也可以平均分割一个张量 提供多个切片和一个轴 或者沿着给定的轴堆叠张量
您还可以为给定的输入形状生成 沿张量维度的 坐标值 例如 您可以用 0 轴上的坐标 填充形状为 2 乘 4 的张量 这也可用于实现 range1D 操作 例如 假设您想要生成 3 到 27 之间的数字范围 增量为 4 要做到这一点 您可以先 在维度 0 上的坐标创建 形状为 6 的张量 然后您所要做的就是乘以增量 再加上偏移量 这些都是今年新增的操作 有了这些新的操作 您将能够使用 MPS Graph 在整个 Apple 生态系统中 做更多的事情并获得更高的性能 现在 我将向大家展示 Apple 芯片 在 MPS 图表之外的性能提升 Blackmagic 刚刚发布了 DaVinci Resolve 版本 18 该版本使用 MPS Graph 来加速机器学习工作负载 Magic Mask 是 Resolve 的一项功能 它使用机器学习 来识别屏幕上的移动对象 并选择性地在对象上应用滤镜 首先 我将演示这在以前版本的 Resolve 中是如何工作的 然后将它与当前版本进行比较 要创建遮罩 您只需选择目标对象 您可以通过切换覆盖来查看遮罩 遮罩由红色区域标识 该区域正确标记了主体的形状 现在 如果我播放视频 当物体 在屏幕上移动时 遮罩会跟踪它 这看起来很棒 但它在以相当低的帧速率运行 因为机器学习管道在引擎盖下运行 现在我将切换到最新版本的 Resolve 它使用 MPS Graph 来加速 Magic Mask 网络 再次运行相同的时间线 帧速率比以前快了很多 这在 Apple 芯片上 带来了更好的编辑体验
这些是您仅仅通过 采用 MPS Graph 就能得到的加速 我鼓励您去探索它能给您的 App 带来什么样的性能 总而言之 您现在能够 使用 PyTorch 的 GPU 加速 该项目现在是开源的 您将发现用 TensorFlow Metal 插件 加速训练工作量的新方法 例如 使用自定义操作和分布式训练 最后 您还能够利用 MPS Graph 框架 优化最苛刻的机器学习任务 利用共享事件和新操作 充分使用 Apple 芯片 Dhruva 和我迫不及待地想知道 您将如何在您的 App 中 使用这些新功能 感谢您观看本期讲座 祝您的 WWDC 之旅一切顺利
-
-
3:44 - Install PyTorch using pip
python -m pip install torch -
3:59 - Create the MPS device
import torch mpsDevice = torch.device("mps" if torch.backends.mps.is_available() else “cpu”) -
4:15 - Convert the model to use the MPS device
import torchvision model = torchvision.models.resnet50() model_mps = model.to(device=mpsDevice) -
4:46 - Run the model
sample_input = torch.randn((32, 3, 254, 254), device=mpsDevice) prediction = model_mps(sample_input) -
9:27 - TensorFlow MetalStream protocol
@protocol TF_MetalStream - (id <MTLCommandBuffer>)currentCommandBuffer; - (dispatch_queue_t)queue; - (void)commit; - (void)commitAndWait; @end -
10:25 - Register a custom operation
// Register the operation REGISTER_OP("ZeroOut") .Input("to_zero: int32") .Output("zeroed: int32") .SetShapeFn([](::tensorflow::shape_inference::InferenceContext* c) { c —> set_output(0, c —> input(0)); return Status::OK(); }); -
10:41 - Implement a custom operation
// Define Compute function void MetalZeroOut::Compute(TF_OpKernelContext *ctx) { // Get input and allocate outputs TF_Tensor* input = nullptr; TF_GetInput(ctx, 0, &input, status); TF_Tensor* output; OP_REQUIRES_OK(ctx, ctx->allocate_output(0, input.shape(), &output)); // Use TF_MetalStream to encode the custom op id<TF_MetalStream> metalStream = (id<TF_MetalStream>)(TF_GetStream(ctx, status)); dispatch_sync(metalStream.queue, ^() { id<MTLCommandBuffer> commandBuffer = metalStream.currentCommandBuffer; // Create encoder and encode GPU kernel [metalStream commit]; } // Delete the TF_Tensors TF_DeleteTensor(input); TF_DeleteTensor(output); } -
11:30 - Import a custom operation
# Import operation in python script for training import tensorflow as tf zero_out_module = tf.load_op_library('./zero_out.so') print(zero_out_module.zero_out([[1, 2], [3, 4]]).numpy()) -
19:29 - Using shared events
// Using shared events let executionDescriptor = MPSGraphExecutionDescriptor() let event = MTLCreateSystemDefaultDevice()!.makeSharedEvent()! executionDescriptor.signal(event, atExecutionEvent: .completed, value: 1) let fetch = computeGraph.runAsync(with: commandQueue1, feeds: [input0Tensor: input0), input1Tensor: input1], targetTensors: [finalTensor], targetOperations: nil, executionDescriptor: executionDescriptor) let executionDescriptor2 = MPSGraphExecutionDescriptor() executionDescriptor2.wait(for: event, value: 1) let fetch2 = postProcessGraph.runAsync(with: commandQueue2, feeds: [input0Tensor: fetch[finalTensor]!, input1Tensor: input1], targetTensors: [finalTensor], targetOperations: nil, executionDescriptor: executionDescriptor2) -
22:03 - Adding an LSTM unit to the graph
let descriptor = MPSGraphLSTMDescriptor() descriptor.inputGateActivation = .sigmoid descriptor.forgetGateActivation = .sigmoid descriptor.cellGateActivation = .tanh descriptor.outputGateActivation = .sigmoid descriptor.activation = .tanh descriptor.bidirectional = false descriptor.training = true let lstm = graph.LSTM(inputTensor, recurrentWeight: recurrentWeightsTensor, inputWeight: weightsTensor, bias: nil, initState: nil, initCell: nil, descriptor: descriptor, name: nil) -
23:35 - Using MaxPooling with return indices API
// Forward pass let descriptor = MPSGraphPooling4DOpDescriptor(kernelSizes: @[1,1,3,3], paddingStyle: .TF_SAME) descriptor.returnIndicesMode = .globalFlatten4D let [poolingTensor, indicesTensor] = graph.maxPooling4DReturnIndices(sourceTensor, descriptor: descriptor, name: nil) // Backward pass let outputShape = graph.shapeOf(destination, name: nil) let gradientTensor = graph.maxPooling4DGradient(gradient: gradientTensor, indices: indicesTensor, outputShape: outputShape, descriptor: descriptor, name: nil) -
24:42 - Use Random Operation
// Declare Philox state tensor let stateTensor = graph.randomPhiloxStateTensor(seed: 2022, name: nil) // Declare RandomOp descriptor let descriptor = MPSGraphRandomOpDescriptor(distribution: .truncatedNormal, dataType: .float32) descriptor.mean = -1.0f descriptor.standardDeviation = 2.5f descriptor.min = descriptor.mean - 2 * descriptor.standardDeviation descriptor.max = descriptor.mean + 2 * descriptor.standardDeviation let [randomTensor, stateTensor] = graph.randomTensor(shapeTensor: shapeTensor descriptor: descriptor, stateTensor: stateTensor, name: nil) -
25:59 - Use the Hamming Distance API
// Code example remember 2D input tensor let primaryTensor = graph.placeholder(shape: @[3,4], dataType: .uint32, name: nil) let secondaryTensor = graph.placeholder(shape: @[1,4], dataType: .uint32, name: nil) // The hamming distance shape will be 3x1 let distance = graph.HammingDistance(primary: primaryTensor, secondary: secondaryTensor, resultDataType: .uint16 name: nil) -
26:21 - Use the expandDims API
// Expand the input tensor dimensions, 4x2 -> 4x1x2 let expandedTensor = graph.expandDims(inputTensor, axis: 1, name: nil) -
26:30 - Use the squeeze API
// Squeeze the input tensor dimensions, 4x1x2 -> 4x2 let squeezedTensor = graph.squeeze(expandedTensor, axis: 1, name: nil) -
26:35 - Use the Split API
// Split the tensor in two, 4x2 -> (4x1, 4x1) let [split1, split2] = graph.split(squeezedTensor, numSplits: 2, axis: 0, name: nil) -
26:39 - Use the Stack API
// Stack the tensor back together, (4x1, 4x1) -> 2x4x1 let stackedTensor = graph.stack([split1, split2], axis: 0, name: nil) -
26:46 - Use the CoordinateAlongAxis API
// Get coordinates along 0-axis, 2x4 let coord = graph.coordinateAlongAxis(axis: 0, shape: @[2, 4], name: nil) -
27:04 - Create a Range1D operation
// 1. Set coordTensor = [0,1,2,3,4,5] along 0 axis let coordTensor = graph.coordinate(alongAxis: 0, withShape: @[6], name: nil) // 2. Multiply by a stride 4 and add an offset 3 let strideTensor = graph.constant(4.0, dataType: .int32) let offsetTensor = graph.constant(3.0, dataType: .int32) let stridedTensor = graph.multiplication(strideTensor, coordTensor, name: nil) let rangeTensor = graph.addition(offsetTensor, stridedTensor, name: nil) // 3. Compute the result = [3, 7, 11, 15, 19, 23] let fetch = graph.runAsync(feeds: [:], targetTensors: [rangeTensor], targetOperations: nil)
-