-
Accelerate machine learning with Metal Performance Shaders Graph
Metal Performance Shaders Graph is a compute engine that helps you build, compile, and execute customized multidimensional graphs for linear algebra, machine learning, computer vision, and image processing. Discover how MPSGraph can accelerate the popular TensorFlow platform through a Metal backend for Apple products. Learn how to add control flow to your graphs, manage the graph compilation for optimal performance, and use the MPSGraph operations to accelerate the hardest compute applications with only a few lines of code.
Resources
- Training a Neural Network with Metal Performance Shaders
- Metal Performance Shaders
- Metal
- Metal Shading Language Specification
Related Videos
WWDC22
WWDC20
-
Search this video…
Hi. I'm Saharsh Oza. I'm with the GPU Software Engineering team at Apple. Today my colleague, Yuliya Pylypiv, and I will talk about what's new in Metal Performance Shaders Graph. Let us begin. MPS is a library of metal-based, high-performance, GPU-accelerated primitives for varied fields like image processing, linear algebra, ray tracing, and machine learning. MPS team optimizes Metal kernels to give the best performance on each hardware across Apple's various platforms. Last year, we introduced the MPSGraph framework, a general purpose compute graph for the GPU. It is supported on macOS, iOS, iPadOS and tvOS, same as the MPS framework. Please watch our last year's session to get more introductory details on the MPSGraph. Let's take a look at the agenda. We have a lot to cover. We will discuss ML inference and training acceleration through MPSGraph. We will introduce some exciting new MPSGraph operations. We will introduce new ways for you to control compilation in MPSGraph. And finally, we will look at the all new control-flow capabilities of MPSGraph. I'd like to introduce my colleague, Yuliya, who will share some exciting updates for inference and training acceleration. Thanks, Saharsh. Hi. I'm Yuliya Pylypiv. I am a part of GPU Software team at Apple. Today, I want to share the improvements we've made to boost training and inference performance on GPU. Let's get right into it. The MPSGraph framework has been adopted by higher level machine learning frameworks like Core ML and TensorFlow for GPU acceleration. This year, we have optimized MPSGraph even further with a combination of kernel improvements and stitching adoption. This has translated to large performance gains to the machine learning frameworks that use MPS. Let's take a closer look at the new Metal Plugin for TensorFlow. TensorFlow is a popular machine learning training platform, and GPUs are the predominant accelerator device. This year, we have developed a new Metal Plugin using TensorFlow PluggableDevice Interface released in TensorFlow 2.5. This brings the power of Metal to TensorFlow using MPS and MPSGraph. This allows us to train any machine learning model on Mac platform GPUs without modifications. Now, let's see one of these in action. For this demo, I am going to use a Jupyter environment. On my M1 system, I have the latest available TensorFlow installed. When we list physical devices, you can see there is only a CPU device registered.
Here I am defining a popular machine learning model, ResNet50, which is widely used for image classification, transfer learning, and more.
Current model uses a standard ImageNet dataset with 224 by 224 image sizes.
As you can see, the current ETA for the first epoch running on CPU is around 20 minutes. Let me install the TensorFlow Metal Plugin which we introduced earlier and see if we can add some speedup to the current network. To do so, I'm gonna use pip install tensorflow-metal...
going back to the same ResNet50 model we used before.
Only this time, you can see there is a new GPU device registered. This is the GPU device we introduced as a part of the TensorFlow platform using Metal Plugin.
All callbacks and network definition remain unchanged. Kicking off the network again so we can compare ETAs. You can see that the GPU version of the same network is training around four times faster using TensorFlow Metal Plugin.
Now let's take a closer look at the other networks. Here we show the performance on key machine learning training benchmarks relative to the CPU. As you can see, we have a good speedup across all benchmarks, going up to eight times faster on the M1 MacBook Pro.
Installing the new Metal Plugin for TensorFlow is easy. After installing the base TensorFlow using pip install tensorflow-macos, you can install Metal Plugin using pip install tensorflow-metal. The Metal Plugin will be available on the official Python package repo, pypi.org. For details on environment setup and installation, please refer to Metal Developer Resource. That's it for TensorFlow. Next, let's talk about Inference acceleration in Core ML.
Core ML is Apple's machine learning inference framework. We also saw significant performance improvements on Core ML with MPSGraph. We show here inference speedup of key classes of machine learning networks on M1. We get a 2x speedup on BERT, which is a canonical transformer network used for NLP applications. ResNet50, which is central to computer vision applications, has been tuned for texture paths in previous releases. This is an additional performance improvement of 16% with our new buffer backend through MPSGraph. These performance improvements in Core ML and TensorFlow are due to performance improvements in MPS primitives like Convolution2D. Here, we show the speedup of Convolution2D on NHWC and NCHW data layouts which are used for training and inference respectively. That's it for the improvements in inference and training. Next, let's go back to Saharsh to learn more about the new operations in MPSGraph. Thanks, Yuliya. Now we will take a look at the new set of operations supported by MPSGraph.
We support a plethora of operations on the MPSGraph, from multiple variants of convolutions and reductions to all the basic math ops you may need in your compute graphs. This year, we added special operations to enable you to do even more with MPSGraph. We will introduce three new primitives: control dependency, stencil operator, and gather operator. First, we'll look at control dependency. Control dependency is needed to explicitly order operations in the graph. To understand this, let's formally define a graph operation. Operations in the graph connect with each other via three kinds of edges: input tensors, which represent which tensors act as data inputs to the op, output tensors, which are created by the op itself, and finally, a special kind of edge called control dependency. They must execute before the current operation, even if the current operation itself does not depend on it. This API also offers a convenient way to prevent operations from being optimized away by MPSGraph. This is needed to implement machine learning layers like batch normalization. Let's see this in practice. Batch normalization is a standard layer used in ML training to make the network more stable and converge faster. Here we see the computational graph for batch normalization that is used for training. The first step is to compute the mean and variance. These are, in turn, used to update the running mean and running variance which are needed for inference. However, the training graph result does not require these variables, so the MPSGraph might optimize them away. We can solve this by explicitly ordering them before the final normalization operator using control dependencies. Let's look at a simple example with some code that shows how you can use this API.
This graph shows an exponent and assign operator. The assign operator is not used by anything else in the graph. So it may be optimized away. One way to solve this is to explicitly set the assign as a targetOperation. However, this requires the developer to track dependencies globally across the graph. Instead, with the new control dependency API, you can make the exponent operation depend on the assignment. This removes the need to have a targetOperation and also ensures that the graph does not optimize it away. Next, we will see this in code.
We first define the operator that the exponent is dependent on. Next, we create a dependentBlock which defines the exponent operator. Finally, we call the run API on this graph. Note that no targetOperations need to be tracked globally. That's it for control dependency. Now let's talk about stencil operators.
A stencil operation is a generalization of sliding window operators like image convolution. These operators are essential in finite element methods, machine learning, and image processing applications. Here, we see a five-point 2D stencil commonly used to implement Laplacian operations. The stencil operator shown here can be applied to higher dimensions too, as shown with this seven-point 3D stencil diagram. Let's take a closer look at the operator. For each output value, it computes a weighted reduction over the stencil window on the input tensor, as shown. The operator supports various reduction modes including argmin/argmax, and various padding modes, including reflection and clampToZero. MPSGraph enables stitching across MPS kernels for optimal performance. With stitching support, the stencil operator allows you to express complex mathematical operations in a single kernel launch. Let us see one such example in action. Local response normalization is a pytorch op used for normalizing in the channel dimension. It's very straightforward to implement this with the new stencil operation. Here, we see the graph for this normalization technique. We see that it's just element wise ops around the stencil operation. Without the new operation, multiple dispatches will be needed. Now, since the stencil op supports stitching, this entire graph can be launched in a single dispatch. So that's it for the stencil operator. Next, let's take a look at improvements in gather operations.
This year, new gather operations have been added to MPSGraph. These allow for efficient copying of arbitrary sized slices in noncontiguous memory locations. Conceptually, we are gathering the values from locations marked in blue from a chunk of memory. These gather layers allow for efficient implementation of embedding lookup and dynamic matrix copy. GatherND is a powerful extension of the gather operation. While the normal gather supports linear indexing, the gatherND operation enables N-dimensional indexing. This allows for seamless copying of data from anywhere in an N-dimensional input. The input to this operation is a vector of coordinates, and each coordinate can be up to the rank of the input tensor. Any dimensions not specified in the coordinates result in slice copies. We can step through an example of a gather of row slices from a 3D tensor. In this example, the indices specify two coordinates corresponding to the matrix and row coordinates. With no third coordinate to column index, this gatherND will copy entire rows. The result tensor is a 2D matrix of the rows gathered from the input matrix. GatherND can represent nearly any form of gather operation and give great performance. For example, let's see how we can implement embedding lookup using gather operations.
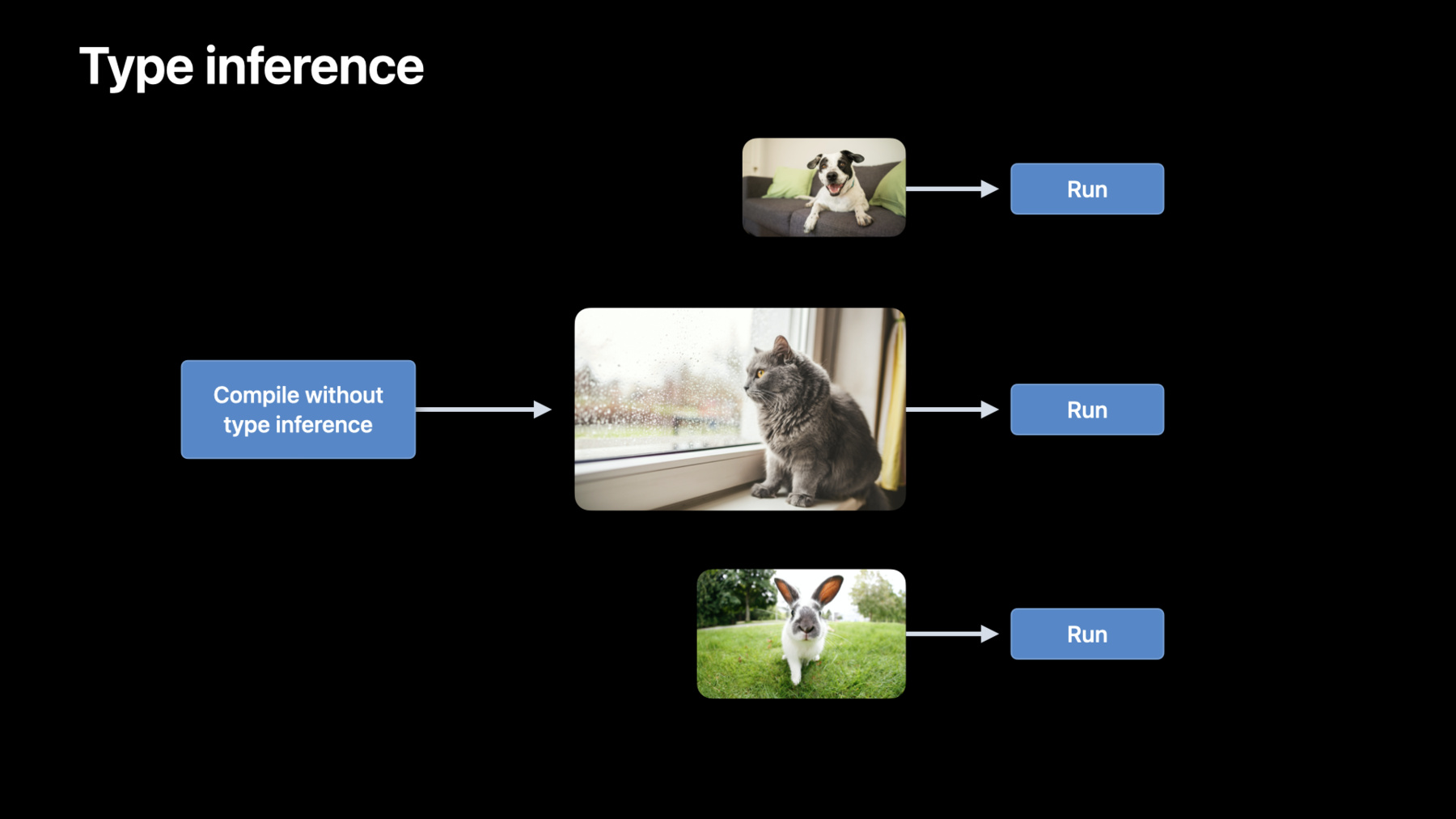
Embedding lookup is a common operation used to find embedding vectors for a provided set of input objects. Commonly, this layer is used in language processing networks, where an embedding matrix is generated associating each word in the vocabulary to an embedding vector. The ID of the words in the vocabulary can be used as the indices to a gather operation, and the embedding matrix is our input tensor. We would like to get the corresponding rows for each word ID, which we can do easily using a gather layer. We only specify one coordinate, so the entire row will be copied for each input word. The resulting tensor is a 2D matrix of each input word's embedding vector along the rows. That's it for the new MPSGraph operations we have introduced this year. Now let's talk about the compilation APIs. This year, we are introducing the new MPSGraphExecutable API. This compilation API improves performance in two ways. First, it gives the developer control on when to compile the graph. Second, it allows you to reduce the number of compilation calls through deferred type inference. Now let's take a closer look at each. Last year, we provided a really convenient API to define and execute an MPSGraph. Under the hood, the first time an evaluation was requested, MPSGraph invoked compilation for the input types and internally created an executable. For any subsequent executions, MPSGraph seamlessly cached this executable to ensure compilation cost is not paid again. Users now have the ability to invoke compilation ahead of time so you can choose the timeline for compilation. With the compiled executable, you can call run directly on the MPSGraphExecutable. This gives the user control on when the graph is compiled and also the ability to cache the compiled executable so you can gain even more performance. Let's see this in code. Here, we have a simple graph to add two tensors. Now to compile, we provide the types for the feeds and target tensors along with the operations. What we get is a compiled graph and an executable. And the evaluation method is just as simple. We provide a Metal command queue and our input tensor data. So those are the basics of compiling an MPS graph. Next, let's talk about how we reduce the number of compilation calls through deferred type inference. Type inference is a compilation pass where MPSGraph must determine tensor shapes where they are not specified by the user. In this graph, we are performing a matrix multiplication of two 2D tensors. The shapes of the input tensors are shown. However, the output tensor is of an unknown shape.
Once the type inference pass is complete, the output tensor shape is determined based on the inputs and operation type. In standard neural networks, the inputs to the network are not always the same size. For natural language processing, the sentences or sequences can be of different lengths. For CNNs, we see different-sized images coming in to be evaluated. Before the compilation upgrades of this year, for every new sized image, a compilation would be invoked to do type inference for the whole graph. Now with control over compilation, you, the developer, can invoke compilation with type inference pass turned off. This can save tens or hundreds of many seconds of compilation time on each iteration and get the best performance.
MPSGraph runtime will infer types just in time during encoding and seamlessly make things work. It is a tradeoff between saving compilation time versus getting the most optimal graph. Let's see how this can be used in the code example shared before.
Disabling the type inference pass can be achieved by setting the compilation descriptor as shown. That's it for compilation APIs. Finally, let's talk about the new control flow APIs of MPSGraph. These APIs let you dynamically dispatch operations based on tensors previously evaluated by the graph. This is common in applications like batch normalization and recurrent neural networks. Let's take a look at how a “while loop” can be implemented with MPSGraph today without the new API.
First, we create a graph that computes the predicate. Next, the predicate is evaluated on the CPU through an explicit memory synchronization. If the predicate is true, the previously created graph is re-executed with the new inputs. Otherwise, if the predicate is false, the loop ends and a second MPSGraph is created and executed to consume the result. With the new control flow API, all these steps can be launched as part of a single MPSGraph execution.
This is more convenient to implement because you don't have to introduce explicit memory synchronization primitives. Now let's take a look at how this can be potentially more efficient. Here we see the control flow timeline without the new API. We encode the first kernel on the CPU. Once the kernel is complete, we have to synchronize memory to read the result. This is potentially inefficient, as the CPU has to wait for the GPU to finish executing. Similarly, the GPU also has to wait for the CPU synchronization and subsequent encoding to complete. This happens in each iteration. Now let's see the benefits of using the new MPSGraph API. We have to perform only one CPU encode call. Since the predicate is evaluated on the GPU timeline, no synchronization overhead is incurred, and the kernels can be launched without any bubbles.
Now let's see what the new APIs are.
We added three new control flow APIs: if/else, for loops, and while loops. Let's start with the if/else primitive. We are all familiar with this. Based on a predicate, different code paths are executed. We are provided a Boolean predicate along with a code block for the “if” and “else” conditions. If this predicate is true, we execute the then block of code. Otherwise, if it's false, the else branch is executed. Having the if/else operation is very useful in neural networks. One canonical usage is in batchNormalization operation, which has different behavior in training and inference. With the isTraining Boolean, we can have a single graph to represent both variants of the normalizer. Let's look at how to set up an if/else branch in code.
Let's take a very simple example of two input scalar tensors. If the first tensor is smaller than the second, we return the sum of the operations. Else, we return the difference. First, we compute the predicate and pass that to the API. Next, when the predicate is true, we compute the then block and add the tensors. Finally, when the predicate is false, we compute the else block and subtract the tensors. Next, let's see how to implement a for loop.
The for loop primitive loops over a set of operations a fixed number of times. This is common in recurrent neural networks where we have to loop over sequences of different lengths during training. We need to provide the numberOfIterations of the for loop. The index is initialized to 0 and compared against the numberOfIterations each loop iteration. If it's less than the numberOfIterations, we execute the body of the for loop and increment the index by 1.
When the index is equal to or greater than the numberOfIterations, we end the loop. Let's see how to implement this in code.
Let's say we wanted to implement a really simple example. We'll initialize the result variable to some input value. Then we loop four times, multiplying the result by another input value each time. First, we create two graph tensors. The output tensor will be initialized to input0. In each iteration, this tensor will be multiplied by input1. Next, we set the numberOfIterations to 4 so that we can execute the loop four times, from index 0 to index 3. Next, we create the body of the for loop. This is done by creating a closure which represents a single iteration. Each iteration is passed the index of the current iteration, as well as the output of the previous iteration. Then, we'll update the result and return it, to be passed to the next iteration. Finally, we pass all these arguments to the for loop API in the graph. Note that the iterationArguments of the body are initialized to input0 tensor. That's it for the for loop. Now let's look at the while loop API.
This primitive executes a set of operations while a condition is met. We need to provide two blocks of code to use this API. In the first block, the condition is checked with a predicate. When the predicate is true, the body of the while loop in the after block is executed. This recomputes the predicate. MPSGraph then uses this predicate in the next iteration of the before block. If the condition evaluated is false, it exits the loop. The API also allows for implementing the do-while loop by swapping the body and condition evaluation code blocks. Let's say we wanted to implement a really simple example. We'll initialize the result variable to some input value. Then we'll multiply the result by a multiplier each time in a loop till we exceed a threshold. First, we define a block of code that will evaluate the predicate using the result of the previous iteration. It also stores the results of the previous iteration in a returnTensors NSArray. This array will be used as the input to the next iteration when the predicate is true and used as the final result if the predicate is false. Next, we define the body of the while loop where the tensors are multiplied. The product is returned for the condition block to read.
Finally, we'll pass all these arguments to the while loop API as shown. Note the initialInputs argument is used in the first iteration of the before block.
That's it for while loops. Next, we'll see how this can be used in a real application. Image composition is a common image editing utility. Here, an object is implanted into a target image. We start with a source image and a background image, as shown. Next, we create a mask on the source image. Let's place this mask of the source image directly against the background. That does not look great, as we can clearly see the edges of the source image. Through image composition, we want to smoothen these edges. Pairing a Laplacian edge filter with an iterative linear solver is a common way to achieve this. Now let's look at the details. Here, we see the pipeline needed to perform image composition with MPSGraph. We start with our input tensors, the background image, source image, and a mask of the object. Next we use an iterative linear solver coupled with a Laplacian edge detector. The output of this set of operations is a composite image with smooth edges. Let's take a look at the Laplacian edge filter. Implementing the Laplacian edge filter involves a windowed reduction over the source image with a set of weights. The stencil operator is used to implement this as shown. Using this operator, we are able to see the edges of the source object. The edges computed here will be used as the input to the linear solver. Next, let's take a look at the linear solver.
We start with the background image and feed it into the linear solver. The solver updates this image, and the result is subsequently read back in. As we can see, this is an iterative process. As the iterations progress, the solution image improves till we arrive at the perfect blend at the edges. The loop terminates when the error is below a user defined tolerance. This requires a while loop. You can now use the MPSGraph Control Flow API to implement this. Now, let's look at the demo. We have implemented an image composition utility using the MPSGraph as an iPad Pro application.
We start with a source image on the top and a target image below. We will be cloning objects from the source to the target. The first thing we need to do is to draw a mask around the cow that we want to move.
Let's see how this looks with a naive clone.
That does not look very good, as we can see the rough edges. Now let's try the image composition technique we just described. We will start by setting the initial solution to the background image. Let's run this for about 50 iterations.
Clearly, the solution image has not yet converged. Let's run it for about 50 more iterations.
This looks way more natural as the edges smoothen out. The ease of programming with MPSGraph makes experimenting with different techniques straightforward. Initializing the solver with the cloned image instead of the background image can result in faster convergence. We can enable this initialization mode by toggling this switch. Let's see this in action by setting the iteration count to 50 again and resetting to the naive clone.
Now let's rerun the solver. We can see the solution image after 50 iterations looks pretty good. Since we already start with the source object, we also observe less bleeding at the edges. This is great. But what we really want is to automate convergence based on an error tolerance. This will require a while loop which we will enable by using this switch. We have implemented this with the new MPSGraph API. The error tolerance can be controlled with this slider. We have set it to 0.1, as shown. Let's reset this back to the naive clone.
Now we start the solver. With this while loop, we converge to the solution image in about 80 iterations without me having to specify any iteration count. Now let's have some fun by cloning other animals onto this background. Let's try this cute puppy.
All right, done tracing. I think it would look great at the bottom right of this image.
Maybe we can try a bird next.
This would look good on the top right of the background. The new background with all these images looks pretty neat. That's it for the demo.
In summary, we showed how adopting MPSGraph led to amazing performance improvements for CoreML and TensorFlow. Inference is now up to twice as fast. We introduced useful new compute primitives, including the stencil operator that is going to enable a wide range of applications.
We showed new compilation flexibility that MPSGraph offers. This is going to shave off latency from inference networks.
And finally, we showed all new control flow capabilities of MPSGraph. This API is key to expressing several linear algebra applications in addition to machine learning networks.
We are excited to see how you will take advantage of these features. Thank you, and have a great WWDC 2021. [upbeat music]
-
-
8:35 - Control dependencies 1
// Execute the graph let results = graph.run(feeds: [inputTensor: inputs], targetTensors: [exp], targetOperations: [assign]) -
9:01 - Control dependencies 2
// Create control dependency let exp = graph.controlDependency(with: [assign], dependentBlock: { return [graph.exponent(with: input, name: nil)] }, name: nil) // Execute the graph let results = graph.run(feeds: [inputTensor: inputs], targetTensors: [exp], targetOperations: nil) -
14:42 - Evaluation method
// Create the graph let placeholder0 = graph.placeholder(shape: [1, 3], dataType: .float32, name: nil) let placeholder1 = graph.placeholder(shape: [2, 1], dataType: .float32, name: nil) let addTensor = graph.addition(placeholder0, placeholder1, name: nil) // Compile the graph into an executable let executable = graph.compile(with: nil, feeds: [placeholder0: MPSGraphShapedType(shape: [1, 3], dataType: .float32), placeholder1: MPSGraphShapedType(shape: [2, 1], dataType: .float32)], targetTensors: [addTensor], targetOperations: nil, compilationDescriptor: nil) // Execute the graph into an executable let fetch = executable.run(with: commandQueue, inputs: [MPSGraphTensorData(input0), MPSGraphTensorData(input1)], results: nil, executionDescriptor: nil) -
16:38 - Disabling the type inference pass
// Create the graph compilation descriptor let descriptor = MPSGraphCompilationDescriptor() // Disable type inference descriptor.disableTypeInference() // Compile the graph into an executable let executable = graph.compile(with: nil, feeds: /* feeds */, targetTensors: /* target tensors */, targetOperations: nil, compilationDescriptor: descriptor) // execute the graph -
19:22 - If/else in batch normalization
// Different behavior during inference and training let results = graph.if(isTraining, then: { ... }, // compute mean and variance else: { ... }, // use running_mean and running_variance name: nil) -
19:46 - If/else
let predicate = graph.lessThan(a, b, name: nil) let results = graph.if(predicate, then: {[ graph.addition(a, b, name: nil) ]}, else: {[ graph.subtraction(a, b, name: nil) ]}, name: nil) -
20:58 - For loop 1
var result = input0 for i in 0..<4 { result *= input1 } -
21:12 - For Loop 2
// Initialize inputs let input0 = graph.placeholder(shape: [], dataType: .int32, name: nil) let input1 = graph.placeholder(shape: [], dataType: .int32, name: nil) let numberOfIterations = graph.constant(4, shape: [], dataType: .int32) -
21:33 - For Loop 3
// Define Body let body = { (index: MPSGraphTensor, iterationArguments: [MPSGraphTensor]) -> [MPSGraphTensor] in let iterationResult = graph.multiplication(iterationArguments[0], input1, name: nil) return [iterationResult] } -
21:52 - For Loop 4
// Create for loop operation let result = graph.for(numberOfIterations: numberOfIterations, initialIterationArguments: [input0], body: body) -
22:51 - While loop 1
var result = initialValue while result < threshold { result *= multiplier } -
23:01 - While loop 2
// Evaluate condition let condition = { (inputs: [MPSGraphTensor], returnTensors: NSMutableArray) -> MPSGraphTensor in let predicate = graph.lessThan(inputs[0], threshold, name: nil) returnTensors.add(inputs[0]) return predicate } -
23:22 - While loop 3
// Define body let body = { (inputs: [MPSGraphTensor]) -> [MPSGraphTensor] in let iterationResult = graph.multiplication(inputs[0], multiplier, name: nil) return [iterationResult] } -
23:33 - While loop 4
// Create while loop operation let results = graph.while(initialInputs: [initialValue], before: condition, after: body, name: nil) -
25:00 - Edge filter
// Apply the laplacian edge filter on the source image let edges = graph.stencil(with: source, weights: laplacianWeights, descriptor: desc, name: nil)
-