-
Advances in Natural Language Framework
Natural Language is a framework designed to provide high-performance, on-device APIs for natural language processing tasks across all Apple platforms. Learn about the addition of Sentiment Analysis and Text Catalog support in the framework. Gain a deeper understanding of transfer learning for text-based models and the new support for Word Embeddings which can power great search experiences in your app.
리소스
관련 비디오
WWDC23
WWDC20
WWDC19
-
비디오 검색…
Hello and good afternoon everyone. Welcome to our session on Natural Language Processing. I'm Vivek, and I'll be jointly presenting this session with my colleague, Doug Davidson.
Let's get started. As you know, text is ubiquitous.
You see it everywhere. If you think of how users interact with text in apps, there are two primary modes in which they interact. One, is through Natural Language input, wherein the user is writing text or generating text within the application.
For instance, the user may be typing text on the keyboard inside the app. Examples of apps are, for example, messages where you're writing text and sharing it with other people, notes, or any productivity app where you're writing text as part of the application.
The other sort of user interaction with text in apps is through Natural Language output wherein the app presents the text content to the user, and the user is consuming or reading this text.
If you think of an application, like Apple News, the information or text is presented to the user, and the user is reading this information.
So, both in cases of text input and text output, in order to extract actionable intelligence out of raw text, Natural Language processing is really important. And last year, we introduced the Natural Language Framework.
The Natural Language Framework is the NLP workhorse for all things across all Apple platforms. So, we provide several fundamental NLP building blocks such as language identification, tokenization, part of speech tagging, and so on, and we present these functionalities and provide this across several different languages. And we do this by seamlessly blending linguistics and machine learning so that you can just focus on building your apps by using these APIs, and we do all of the heavy lifting under the hood. Now, if you step back and look at all of these functionalities, actually if you look at most NLP functionalities, they can be broken down into two broad categories of tasks. One is text classification. And the objective in text classification is given a piece of text, and this text can either be a sentence, can be a paragraph, or a document, you would like to assign labels to this piece of text, and these labels can be sentiment labels, topic labels, or any labels that you want to assign.
The other category of tasks by NLP is called word tagging. And the task here or the objective here is given a sequence of words or what we call is tokens, we would like to assign a label to every token in this sequence. And this year, we have exciting new APIs in both text classification as well as word tagging. Let's start off with the first one, which is sentiment analysis.
Sentiment analysis is a text classification API, this is a new API, and it works this way. What you do is you bring your text, and you pass your text to this API, and the API analyzes the text and gives you out a sentiment score.
Now this sentiment score captures the degree of sentiment that is contained in your text.
You provide a sentiment score from -1 to +1, which indicates the degree of sentiment.
For instance, if you have -1, it indicates a very strong negative sentiment, and +1 indicates a very positive sentiment. So, essentially we provide the score and let you calibrate the score for your application. As an example, if you had a sentence such as we had a fun time in Hawaii with the family, the API might give you a score of 0.8, which shows that this sentence is a positive sentence.
In contrast, if you had a sentence such as we had a not so fun time in Hawaii because mom twisted her ankle, well that's not positive, so you get a score of minus 0.8, and you can calibrate that to be a negative sentiment.
This is great; how do you use it? It's really simple to use. So those of you who are used to using NaturalLanguage, this is extremely easy. You import NaturalLanguage. You create an instance of NLTagger and all that you do now is specify a new tag scheme. And the new tag scheme is called sentiment score.
Once you do this, you attach the string that you want to analyze to the tagger, and you simply ask for the sentiment score either at the sentence level or the paragraph level.
Now let's see this in action.
So what we have here is a hypothetical app. It's a cheese application. And as part of this application, users can do a bunch of things. They can write notes about cheese. They can write reviews, express their opinions about different kinds of cheese. So, even though this application is about cheese, there's nothing cheesy about it. It really deals with the finer points of cheese. And what I'm going to show you here is a user writing a review, and as the user is writing the review, the text gets passed to the sentiment classification API, we get a score, and we color the text based on the sentiment score. So, let's see, if you were to type something like fantastic taste, really delicious, you can see this is a positive sentiment.
In contrast, if you said great at first but a horrible aftertaste, you see that this is a negative sentiment, right. And what you also realize here is all of this can be happening in real time. That's because the API is extremely performing. It uses a Neural Network model underneath, and it's hardware activated across all Apple platforms, so essentially, you can do this in real time.
And we support the sentiment analysis API in seven different languages, English, French, Italian, German, Spanish, Portuguese, and simplified Chinese. I think you're really going to like this.
And, of course, all of this is happening completely on device, and the user data never has to leave the device. We bring all that power on device to you.
I like to just spend a brief moment on language assets. As I mentioned, the NLP functionalities are quite diverse, and we provide this in several different languages. Now, for users of our applications, we make sure that they always have the assets in the language they're interested in. But for you, for development purposes, you might be interested in getting assets on demand. This is in fact a very common request that we've heard from several of you, and we're introducing a new convenience API called Request Assets. So, you can trigger off a download for a particular asset on demand. You just specify the language and the tag scheme that you're interested in, and we'll fork off a download in the background, and the next opportune moment you're going to get the assets on your device. So, this is really going to help you with development and increase your productivity as you're building your apps.
So, we talked about text classification. Now let's shift our attention to Word Tagging.
To just refresh your memory, Word Tagging is a task where given a sequence of tokens we'd like to assign a label to every single token in the sequence. As an example here, we could assign a bunch of tokens different labels. Timothy is a person name. Switzerland is a location, and we have a bunch of nouns here in this sentence.
Now, this is great. If you're just looking to do named entity recognition using our APIs or part of speech tagging using our APIs, this is fine, but there are several instances where you want to do something that's more customized to your task.
You don't want to know just Gruyere cheese are two nouns, but what you want to do is you want to know that it's Swiss cheese. Of course, we are building a cheese application, you want to get this information out.
But, the default tagger doesn't have any information about cheese, so how are we going to provide this information? So, we have a new functionality in Natural Language Framework that we call a Text Catalog.
A Text Catalog is very simple. What you do is you provide your custom list, and this can be a very large list of entities. For each of the entities in your list, you have a label.
In practice, these lists can be millions or even like, you know, a couple of hundred millions.
What you do is you pass this sort of a dictionary into Create ML, create an instance of MLGazetteer, and Gazetteer is just a terminology that we use interchangeably with Text Catalog, and what you get as an output is a Text Catalog. Now, this is an extremely compressed and efficient form of the input dictionary that you provided. It's very simple to use. What you do is you provide this dictionary. As I mentioned, we can't show your million entries here. We're just showing as an example a few entries, but this can be an extremely large dictionary.
Once you do that, you can create an instance of MLGazetteer, pass the dictionary, and you write it out to disc. It looks really innocuous. You might be thinking, I'm just writing a dictionary to disc. What are you doing here? Something magical happens when you make the right call. Create ML calls Natural Language under the hood, and Natural Language takes this very large dictionary and compresses it into a bloom filter, which is an extremely compact representation, and what you get as an output is a Text Catalog.
In fact, we've used this to create effect internally. We've been able to compress almost all the person, organization, and location names in Wikipedia, which is almost two and a half million names, into two megabytes on disc. Sort of implicitly you've been using this model. When you call the named entity recognition API in NaturalLanguage, in conjunction with the statistical model, you're using this bloom filter and Gazetteer and now we are bringing that power to you. Once you create a Gazetteer or a Text Catalog, using it is extremely easy.
You create an instance of MLGazetteer by specifying the path to the Text Catalog that you just wrote out to disc. You can work with your favorite tag scheme here. It can be lexical class. It can be name type, any tag scheme, and you can simply attach your Gazetteer to this tag scheme.
Once you do this, every time you have a piece of text, this customized Gazetteer is going to override the default tags that NaturalLanguage provides.
Consequently, you can customize your application.
Now, if you go back to the cheese application, and if you have a sentence such as lighter than Camembert or Vacherin, you can use your Text Catalog for cheese and identify that one is a French cheese, and the other is a Swiss cheese, and you can perhaps hyperlink it and create a much more cooler application out of this. So that's one way to use Text Catalog in a word tagger in NaturalLanguage for this release. So we've talked about text classification. We've talked about word tagging.
But the field of NLP has moved significantly in the past few years, and there have been the without catalysts for this change.
One is the notion of Word Embeddings, and Word Embeddings are nothing but vector representation of words. And the other one is the use of Neural Networks in NLP.
We are delighted to tell you that we are bringing both these things to your apps in NaturalLanguage this year. So, let's start off with Word Embeddings. Thank you.
Before we jump or dive into Word Embeddings, I'd like to spend a couple of slides talking about what an embedding is. At a conceptual level, embedding is nothing but a mapping from a discrete set of objects into a continuous vector representation. So, you have these bunch of discrete objects. Each object in this set can be represented by some sort of a finite vector. In this example, we're showing it with a 3-dimensional vector.
Three dimensions because it's easy to plot and visualize, but in reality, these vectors can be of arbitrary dimensions. You can have 100 dimensions, 300 dimensions, or in some cases even 1000 dimensional vector.
Now, the neat property about these embeddings is that when you plot these embeddings, objects that are similar semantically are clustered together.
So, in this example, if you had to look at the paint can and the paint roller, they are clustered together.
Or, if you had to look at the sneakers and the high heels, they are clustered together. So, this is a very neat property of embeddings. And this property of embeddings is not only proof of words but actually across several different modalities. You can think of image embeddings. When you take an image and pass it through a VGG network or any sort of a convolution Neural Network, the feature that you get as an output is nothing but an image embedding.
Similarly, you can have embeddings for words, for phrases, and when you work with recommendation systems where you're working with song titles or product names, they are represented by using a vector. So, they are nothing but just embeddings.
So, in summary, embedding is nothing but a mapping from a string into a continuous sequence of numbers or a vector of numbers. We've actually used these embeddings very successfully in iOS 12, and let me tell you how we use this in Photos.
In Photos search, when you type a particular term that you're looking for, maybe pictures of a thunderstorm, what we do underneath the hood is all the images in your photo library are indexed by using a convolution Neural Network. And the output of the convolution Neural Network is fixed to some certain number of classes, perhaps to 1000 classes or 2000 classes.
Now, if your convolution Neural Network doesn't know what thunderstorm is, you will never find the pictures that were indexed because they didn't have the term thunderstorm, but with the power of Word Embeddings, we know that thunderstorm is actually related to sky and cloudy, and those are labels that your convolution Neural Network understands. So, by doing this, in iOS 12, you're able to enable fuzzy search in Photos search by using Word Embeddings. So, as a consequence of this, you can find the images through the power of Word Embeddings. In fact, it can be applied to any search application. If you want to do fuzzy search and you have a string, you can use the Word Embedding to get neighbors related to that original word.
Having said that, what can you do with an embedding? There are four primary operations that you can do with Word Embeddings.
One is, given a word, you can obviously get the vector for that word.
Given two words, you can find the distance between two words because for each of those words, you can look at the corresponding vectors. So, if I say dog and cat and ask for the distance, I'm going to get a distance, and that distance is going to be pretty close to each other.
If I say dog and a boot, those are fairly distant in the semantic space, and you're going to get something that's much higher distance.
The third thing that you can do is get the nearest neighbors for a word, and this probably is by far the most popular way of using word embeddings, and the Photos search application that I just showed you was doing exactly that. Given a word, you're looking for nearest neighbors of a word. Last but not the least is you can also get the nearest neighbors for a vector, so let's assume that you have a sentence, and you have multiple words in the sentence, and for each of the words in the sentence, you can get the word embedding, you can sum it up. So what you get is a new vector, and given that vector, you can ask for all the words that are close to that vector. That's a neat way of using Word Embeddings too. So a lot of stuff about Word Embeddings, but the most important thing is we are providing this easy for you to use on the OS. So, we're delighted to tell you that these Word Embeddings come on the OS in seven different languages for you to use, and all of the functionalities I just mentioned, you can use it with one or two lines of code. So, we're supporting it in seven languages from English, Spanish, French, Italian, German, Portuguese, and simplified Chinese.
Now, this is great. The OS embeddings are generally framed on general corpora, large amounts of text, billions and billions of words. So, they have a general notion of what a relationship with a particular word is.
But many a time, you want to do something that's even more custom.
So, perhaps you're working with different sort of domains, something in the medical domain or the legal domain or the financial domain.
So, if your domain is very different, and the vocabulary of words that you want to use in your application is extremely different, or maybe you just want to train a word embedding for a language that's not supported on the OS, how do you do that? We have a provision for that too.
You can use and bring custom word embeddings.
So, those of you who are familiar with word embeddings and have seen this field evolve, there are many third-party tools to train your own embedding such as word2vec, GloVe, fasttext. So, you can bring your own text or you can even use a Custom Neural Network that you train in Keras TensorFlow or PyTorch. So, go from raw data, you can build your own embeddings, or you can go to any one of these websites and download their pretrained word embeddings.
Now, the challenge there is when you download any of these embeddings, they are very, very large. They're 1 gigabyte or 2 gigabytes in size. But you want to use it in your app in a very compact and efficient way, and we do just that. When you bring these embeddings from third-party applications and they're really large, we automatically compress them into a very compact format, and once you have this compact format, you can use it just like how you use the OS embeddings.
But to tell you how you use these embeddings, both the OS as well as the custom, I'm going to turn it over to Doug, who is going to do a demo and then walk you through the rest of the session. Over to you, Doug.
All right. So, let's go over to the demo machine here, and let's see some of this in action.
So, the first thing I've done here is to write a very tiny demo application that helps us explore Word Embeddings. So, I type a word in here, and it shows us the nearest neighbor, nearest neighbors of that word in embedding space. Let's start by using the built-in OS Word Embeddings for English. So, I type a word like chair, and we see the nearest neighbors of chair are words that are similar in meaning to chair, sofa, couch, and so forth, or I could type in something like bicycle.
And the nearest neighbors, bike and motorcycle and so forth, these are words that are close in meaning to bicycle or maybe book.
And we get words that are similar in meaning to book. So, what we can see from this, we can understand that the built-in OS Word Embeddings represent the ordinary meanings of words and the language and recognize the similarity of meanings as expressed in general text in that language.
But, of course, what I'm really interested in here is knowing what do these embeddings understand about cheese, because we're dealing with a cheese application here.
So, let me type in a cheese word.
And take a look here, and what I can see right away is that these built-in embeddings do know what cheese is, but I'm very disappointed. I can see these embeddings know nothing about the finer points of cheese.
Otherwise, they would never have put these particular cheeses and cheese-related things together. They don't go together at all.
What I really want here is something that understands the relationships of cheeses. So, I've taken the opportunity to train my own custom cheese embedding that puts cheeses together based on their similarity.
And let's switch over to it.
So, here are the neighbors of cheddar in my own custom cheese embedding. This is much better.
We can see that it puts near cheddar, it puts some fine cheeses that are similar to cheddar in texture like our Lancashires, Double Gloucester, and Cheshire.
So this is something that we can use in our cheese application. So, let's take a look at the cheese application now.
So, I've been trying out some ideas for our cheese application. Let's see how this looks. So, when the user types something in, the first thing I'm going to do is get a sentiment score on it to see and check does this represent a sentence with a positive sentiment, and if it does, then I'm going to go through it using my tagger using, of course, our custom cheese Gazetteer to see whether the user mentioned any cheeses in it.
And so I'll look for a cheese, and if the user did mention a cheese, then I'm going to pass it through my custom cheese embedding to find similar related cheeses.
Sounds plausible? Let's try it out. Let's bring up our cheese application, and so I visited the Netherlands last year, and I fell in love with Dutch cheeses, so I'm going to tell my app that. So, this is a certainly a sentence with a positive sentiment, and it does reference a particular cheese. So, I go through, and now my app can make recommendations of cheeses that are similar to the one that I mentioned here.
So, this shows of the power of Word Embeddings, but even more than that, it shows how the natural, various NaturalLanguage APIs can come together for application functionality.
So, now, let's go back to the slides, and I want to review briefly how this looks in API.
So, if you want to use a built-in OS Word Embedding, it's very simple. All you do is ask for it. Ask for the word embedding for a particular language, and we'll give it to you. Once you have one of these NL embedding objects, there are various things you can do with it. You can, of course, get the components, the vector components, corresponding to any particular entry.
You can find the distance between two words, be it short or far, in embedding space.
And as we saw in our cheese application, you can go through and find the nearest neighbors of any particular item in this embedding space. If you want to use a custom word embedding, then to create it, you go over to Create ML, and you need, of course, all of the vectors that represent your embedding. I can't really show them all to you right here in the slide because there are 50 or 100 components long, but here's an example of what they look like. In practice, you're probably going to be bringing them in from a file using the various Create ML facilities for loading data from files. And then you just create a word embedding object from it and write it out to disc. Now, what's going on when you do this? Well, in practice, these embeddings tend to be quite large, hundreds of dimensions times thousands of entries. It could be huge, and they could take a lot of space on disc, naively and be expensive to search. But when you compile them into our word embedding object, then under the hood what we do is we use a product quantization technique to achieve a high degree of compression, and we add indexes so you can do fast searching for nearest neighbors, as you saw in our examples.
Just try this out. We took some very large embeddings that are readily available as open source. This is some GloVe and fasttext embeddings. These are a gigabyte or 2 gigabytes in uncompressed form. When we put them into our NL embedding compressed format, they're only tens of megabytes, and you can search through them for nearest neighbors in just a couple of milliseconds.
Closer to home-- For an example, closer to home, Apple does a lot with podcasts, so our podcast group, we talked to them, and they, as it happens, have an embedding for podcasts that represents the similarity of various podcasts, one to another. So, we thought we'd try it out and see what would happen if we took this embedding and put it into our NL embedding format. So this embedding represents 66,000 different podcasts, and source form is 167 megabytes, but we compress it down to just 3 megabytes on disc. So what NL embedding does is it makes it practical to include these embeddings and use them on , on the device, in your application.
All right.
So, next I want to switch and talk about another thing that's related to Word Embeddings, and that is Transfer Learning for Text Classification.
So, I'd like to start by talking a little bit about what we do, what it is we do when we train a text classifier.
So, when we're training a text classifier, we give it a set of examples for various classes. You can pass that in to Create ML. Create ML will call on Natural Language. We will trained a classifier and out will come a Core ML model. And what we hope is that these examples will give sufficient information about the various classes that the model can generalize to classify examples that it hasn't seen. And, of course, we have already shipped this last year, and we have algorithms for training these models, most notably our standard algorithm is what we call the maxEnt algorithm, based on logistic compression. It's very fast, robust, and effective.
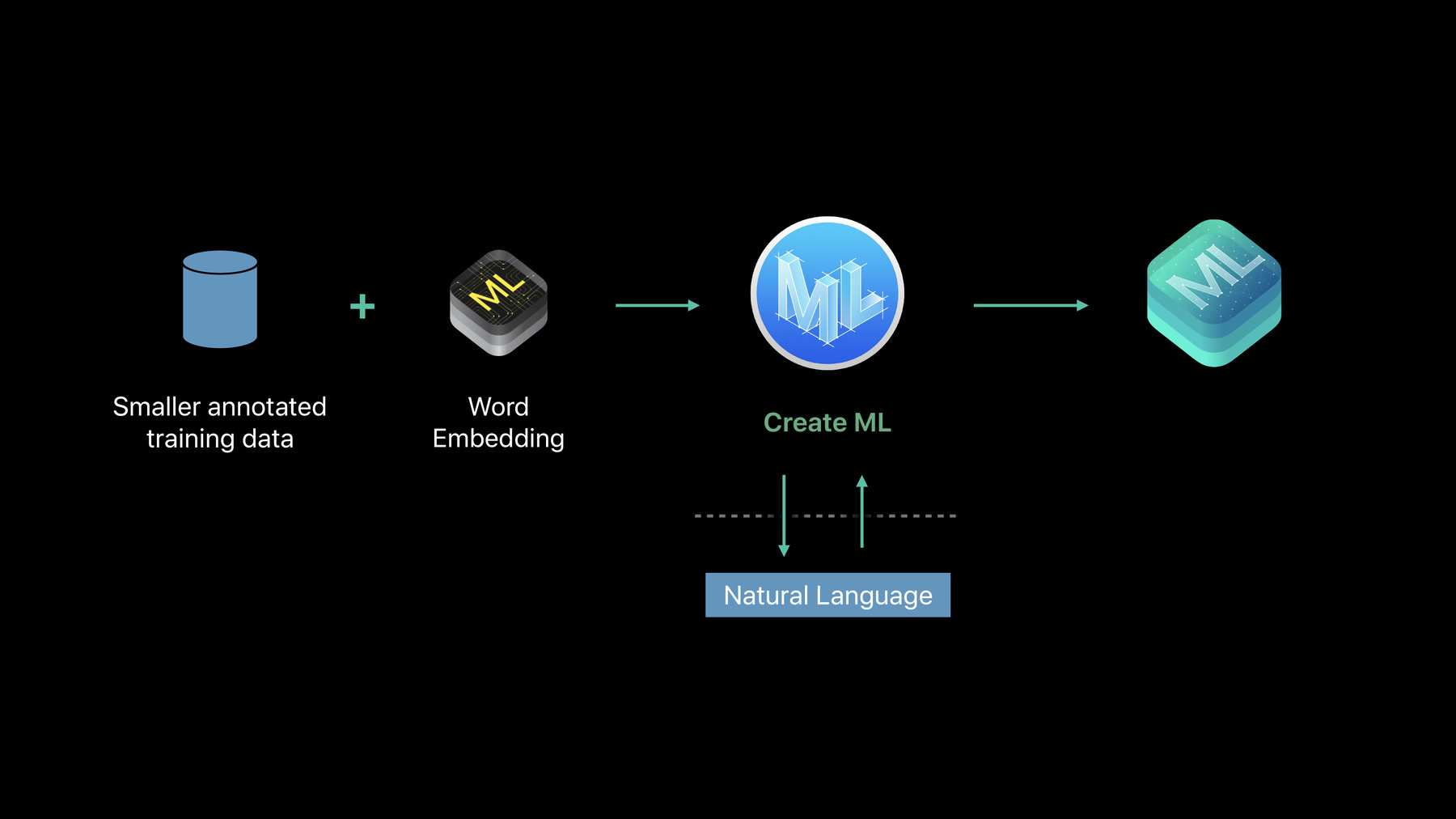
But one thing about it is it doesn't know anything except what it learns from the training data that you give it. So, you have to make sure that the training material you give it covers essentially all of the sort of things that you expect to see in examples in practice. So, in some sense, we've done the easy part of creating the algorithm and left you the hard part of producing the training data. But, wouldn't it be nice if we could take advantage of prior knowledge of the language and then maybe use that in conjunction with some smaller amount of training material that you have to provide in order to train a model that would combine these two and so hopefully understand more about the examples it's going to see with less in the way of training material.
And so this is the promise of Transfer Learning.
This is a highly active research area in NLP, and I'm happy to say we have a solution for this that we're delivering now.
Again, NaturalLanguage trains a model, and the outcome is a Core ML model. But how are we going to incorporate previous knowledge of the language? Where are we going to get it? Well, Word Embeddings provide a great deal of knowledge of the language. In particular, they know quite a bit about the meaning of words. So, our solution uses Word Embeddings, takes the training material you provide, puts them through the Word Embeddings, and then on top of that we train a Neural Network model, and that is what we provide as a Transfer Learning Text Classification model.
Now, there's a lot of work going on here, but if you want to use it, all you have to do is ask for it.
You just change one parameter in the specification of the algorithm that you want when training a Transfer Learning model. Now, there are a few different options here.
So, the first one, most obvious is, you can use the built-in OS Word Embeddings that represent the ordinary meaning of words, and if you have a custom Word Embeddings, you could also use that as well. We know that a given word can have very different meanings, depending on how it appears in the context of a sentence. So, for example, Apple in these two sentences has very different meanings.
So, what we'd like is to have an embedding for Transfer Learning purposes that gives different values for these words depending on their meaning and context. And, of course, an ordinary word embedding, it just maps words to vectors, and it will give the same value for the word no matter how it appears.
But, what we have done is trained a specialized embedding that gives different values for the words depending on their meaning and context. Now, to give you some idea of how fast the field is moving, this is something that was just researched a year ago, and we're delivering it now. And again, if you want to use it, you just ask for it. You specify the dynamic embedding. So, the dynamic embedding changes the value of the embedding for words depending on their sentence context, and this is a very powerful technique for doing Transfer Learning for Test Classification.
Well, let's see it.
All right. So, here what I have is some fairly standard code for training a Text Classifier using Create ML, and what I'm going to be training, this is based on a dataset using an Open Source encyclopedia called DBpedia.
It has short entries about many different topics. Some of them are people, artists, writers, plants, animals, and so forth, and the task here is to determine from the entry what the classification is, whether it's a person or writer or artist, etc. And there are 14 different classes here, and I'm going to try and train a classifier using only 200 examples. So, it's a fairly difficult task here, and so let's just-- let's try it with our existing maxEnt model.
So, I'll fire it off. It starts, and it's done.
Very fast and easy, and on our training-- if we take a look at our performance on our test set, we see it got 77% accuracy.
That's okay, but can we do better? Well, let's make one little change to our code here. Instead of using the maxEnt model, we're going to use the Transfer Learning with Dynamic Embeddings, and let's start it.
Now, as I mentioned, this is training a Neural Network model, so it takes a little bit longer, so while it's training, let's just take a little closer look at the data that we're training on. As it turns out, when you're training Neural Network models, it's important to pay close attention to the data that you train it on. So, notice that this data is a random sample across the various classes, and I've arranged it so that they're roughly the same number of instances for each class. It's a balanced set.
This is our training set. In addition, we also have a separate validation set that is similarly a random sampling of examples across classes, maybe not quite as large as the training set, but balanced.
And the validation set is particularly important in this kind of training. Neural Network training has a tendency to over fitting, where it more or less memorizes the training material and doesn't generalize. The validation set helps keep it honest and make sure it continues to generalize.
And then, of course, we also have a separate test set that's similarly randomly sampled and balanced, and of course there can't be any overlap between the training validation test sets. That would be cheating.
And the test set we need to see how well we're doing, in particular in this case, we need it so that we can see whether the Transfer Learning model is doing better than our maxEnt model. And it looks like it's finished now, so let's take a look and see. And we can see here that the Transfer Learning has achieved an accuracy of 86.5%, much better than our maxEnt model. So, how does this apply to our cheese application? Well, what I've done is I've taken my cheese tasting notes, and I labeled them each by the cheese that they referred to, and I use that to train a cheese classifier model. And so my cheese classifier model can take a sentence and try to classify it and determine which cheese it most closely refers to. And I put that into my cheese application, and so, what I'm going to do in the cheese application is if the user didn't refer to a specific cheese, then I'm going to try to figure out which cheese they might want. And all I do is ask the model for the label for the text.
And very simple. Let's try it out.
So, I'm going to type in something here.
And we'll let the cheese classifier work on it. And so the cheese classifier determined that this is most closely resembling Camembert, and then my cheese embedding has recommended some other cheeses that are very similar, Brie and so on and so forth.
Or, maybe I say-- Something firm and sharp and it recognizes that as resembling cheddar, and it recommends some similar cheeses to us. So, this again shows us the power of Text Classification in combination with the other NaturalLanguage APIs. So, I'd like to finish off with some considerations for the use of the Text Classification. First of all, we need to note the languages that are supported for transfer learning, either via Static Embeddings or the special Dynamic Embeddings that take context into account. And then I want to talk a bit about, more about data.
So, the first commandment when dealing with data is that you need to understand the domain you're working with.
What kind of text do you expect to see in practice? Is it going to be sentence fragments, full sentences, multiple sentences, and make sure that your training data is as similar as possible to the text that you expect to see and try to classify in practice.
And covers as much as possible of the variations that you're likely to see when you encounter this text in your application.
And, as we saw in our DBpedia example, you want to make sure that you have randomly sampled as much as possible distinct sets for training, for validation, and tests. This is basic data hygiene. And how do you know which algorithm will be best for your case? Well, in general, you'll have to try it, but some guidelines. You can start with the maxEnt classifier. It's very fast. It will give you an answer.
But what does a maxEnt classifier do? A maxEnt classifier works by noticing the words that are used most often in the training material. So, for example, if you're trying to train positive and negative, it might notice words like love and happy are positive, hate and unhappy negative. And if the examples you encounter in practice use these same words, then the maxEnt classifier is going to work very well. What the Transfer Learning does is it notices the meaning of words. So if the examples you encounter in practice are likely to express a similar meaning with different words, then that is the case where Transfer Learning shines and it's likely to do better than the simple maxEnt model. So, to summarize, we have new APIs available for Sentiment Analysis, for Text Catalogs with MLGazetteer, for Word Embeddings with NL embedding, and we have a new type of text classification, a particularly powerful new type that takes advantage of Transfer Learning.
I hope you'll take advantage of these in your applications, and there's much more information available online, and there are other related sessions that you can take a look at.
Thank you.
[ Applause ]
-