-
Create ML 구성 요소를 통한 고급 모델 작성
Create ML 구성 요소를 통해 맞춤형 머신 러닝 모델의 수준을 한 단계 높일 수 있습니다. 비디오나 오디오와 같은 시간적 데이터로 작업하는 방법과 반복적인 사람의 동작 수를 세거나 고급 사운드 분류를 제공하는 모델을 작성하는 방법을 보여드립니다. 또한 새로운 데이터로 모델 학습을 가속화하기 위해 점진적 피팅을 사용하는 것에 관한 모범 사례를 소개합니다. 맞춤형 머신 러닝 모델에 대한 소개는 WWDC22의 ‘Get to know Create ML Components(Create ML 구성 요소 알아보기)'를 시청하시기 바랍니다.
리소스
관련 비디오
WWDC23
WWDC22
WWDC21
- Discover built-in sound classification in SoundAnalysis
- Meet AsyncSequence
- Meet the Swift Algorithms and Collections packages
WWDC20
WWDC19
-
비디오 검색…
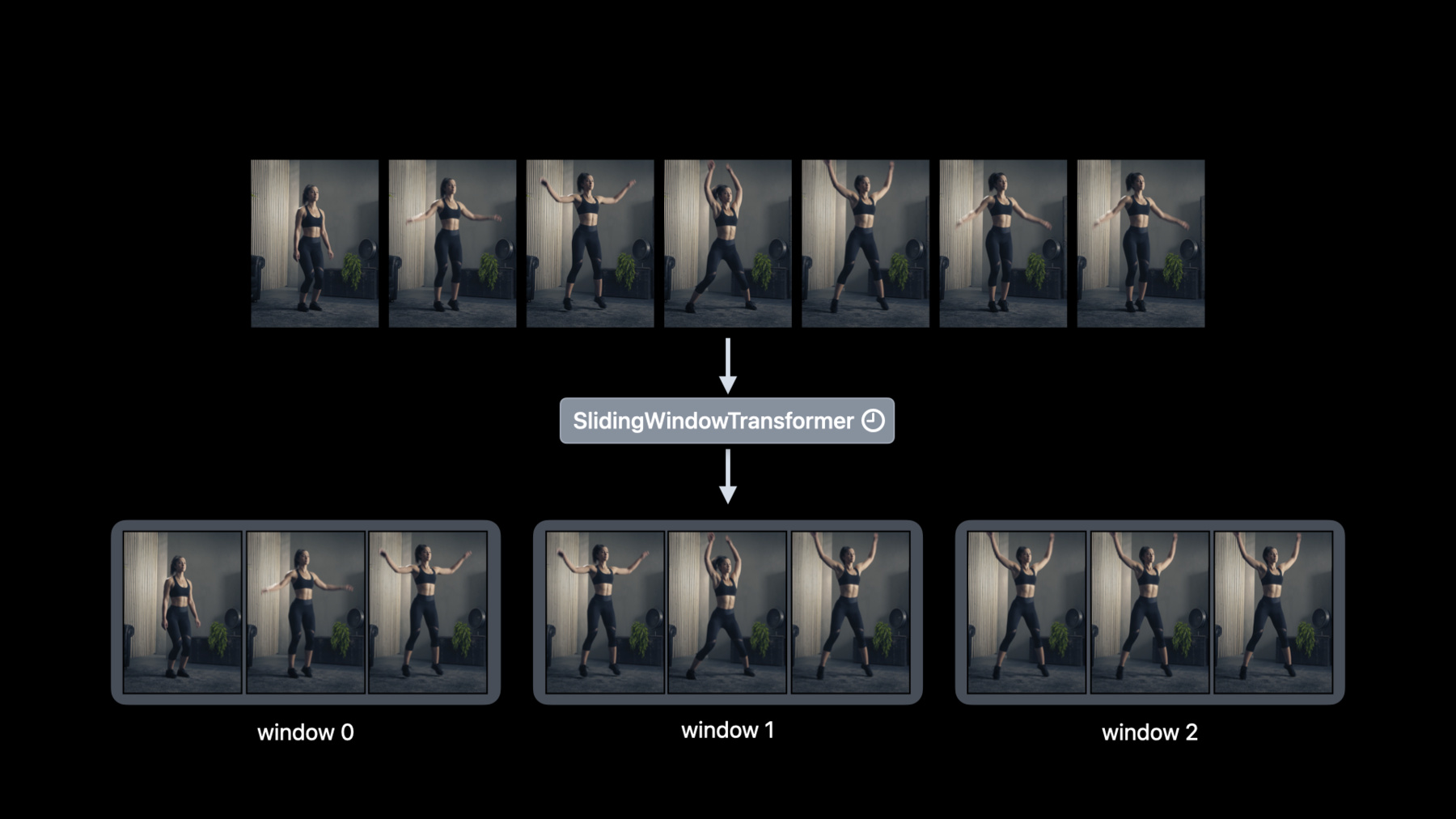
♪ 잔잔한 힙합 연주 음악 ♪ ♪ 안녕하세요 저는 David Findlay입니다 Create ML 팀의 엔지니어죠 이번 세션의 주제는 Create ML Components입니다 여러분만의 기계 학습 작업을 구축할 새롭고 강력한 방식입니다 제 동료 Alejandro가 이 세션에서 소개했죠 'Get to know Create ML Components'에서요 Alejandro는 Create ML 작업을 구성 요소들로 해체해서 맞춤형 모델 구축이 얼마나 쉬운지를 보여줬습니다 변환자와 추정자는 여러분이 함께 구성해서 맞춤형 모델을 만들 수 있는 주요 구축 단위들입니다 이미지 회귀 같은 모델을요 이 세션에서는 기초를 훨씬 넘어가서 Create ML Components로 가능한 걸 시연하고 싶습니다 논제를 살펴보죠 다뤄야 할 게 많습니다 우선 비디오 데이터 얘기를 하고 시간에 따른 값을 처리하기 위해 디자인된 새 구성 요소들을 자세히 알아보겠습니다 그리고 그런 개념들을 활용해서 변환자만 사용해서 인간 동작 반복 카운터를 구축하겠습니다 마지막으로 맞춤형 사운드 분류자 모델을 훈련시키는 것으로 넘어가겠습니다 증대 피팅을 설명할 텐데요 그건 여러분이 집단으로 모델을 업데이트할 수 있게 해주고 훈련을 조기에 중단하게 해주고 모델의 작동 상태를 확인해주죠 이 정도로 유연성이 있으니 기회가 정말 많습니다 빨리 알아보고 싶네요 시작해봅시다 WWDC 2020에선 Create ML에서의 Action Classification을 소개했습니다 그건 여러분이 영상에서 동작들을 분류하게 해줍니다 그리고 우린 신체 단련 분류자를 만들어서 사람의 운동 루틴을 인식하는 방법을 보여드렸습니다 가령 점핑 잭과 런지와 스쿼트를요 예를 들어 여러분은 동작 분류자를 사용해서 이 영상에 나오는 동작을 점핑 잭으로 인식할 수 있습니다 그런데 여러분이 점핑 잭의 횟수를 세고 싶다면 어떨까요? 첫 번째로 고려해야 할 건 점핑 잭은 연속적인 프레임에 걸쳐 있어서 시간에 따른 값을 처리할 방법이 필요하단 겁니다 고맙게도 Swift의 AsyncSequence가 이걸 아주 쉽게 해줍니다 AsyncSequence가 낯선 분들은 'Meet AsyncSequence' 세션을 확인해보셔야 합니다 Create ML Components로 여러분은 비디오 리더를 써서 프레임이 있는 비동기 시퀀스로 영상을 읽을 수 있습니다 그리고 AsyncSequence는 영상에서 프레임을 받을 때 프레임 위에서 반복 작업하는 방식을 제공합니다 예를 들어 저는 맵 기법을 써서 각각의 영상 프레임을 비동기식으로 쉽게 변환할 수 있습니다 그건 프레임을 한 번에 하나씩 처리하고 싶을 때 유용합니다 그런데 한 번에 다수의 프레임을 처리하고 싶다면 어떨까요? 그럴 때 시간 변환자가 등장합니다 예를 들어 여러분은 프레임을 다운샘플해서 영상 안의 동작 속도를 높이고 싶을 수 있습니다 그걸 위해 다운샘플러를 사용할 수 있는데 그건 비동기 시퀀스를 갖고 다운샘플 비동기 시퀀스를 되돌려줍니다 아니면 여러분은 프레임을 창으로 나누고 싶을 수 있습니다 그건 동작 반복을 세는 데 중요하죠 그때 여러분은 슬라이딩 창 변환자를 쓸 수 있습니다 창 길이를 명시할 수 있죠 그 길이는 여러분이 창에 나누고 싶은 프레임의 수입니다, 그리고 걸음은 슬라이딩 간격을 제어하는 방식입니다 입력은 이번에도 비동기 시퀀스이고 이 경우에 출력은 창이 있는 비동기 시퀀스입니다 일반적으로 말해서 시간 변환자는 비동기 시퀀스를 새로운 비동기 시퀀스로 처리하는 방법을 제공합니다 그럼 이 개념들을 실행해보죠 여러분은 어떤지 모르겠지만 저는 운동할 때 반복 횟수 세는 걸 잊곤 합니다 그래서 전 방식을 좀 바꿔서 Create ML Components로 동작 반복 카운터를 구축하기로 했습니다 이 사례에서는 변환자와 시간 변환자를 함께 구성하는 법을 설명하겠습니다 자세 추출로 시작하겠습니다 저는 인간 몸 자세 추출자로 자세를 추출할 수 있습니다 입력은 이미지고 출력은 인간 몸 자세의 배열입니다 보이지 않는 데서 우린 Vision 프레임워크를 활용하여 자세를 추출합니다 이미지에는 사람이 다수 포함될 수 있다는 점에 주의하세요 그건 그룹 운동에서 흔합니다 그래서 출력이 자세들의 배열인 거죠 하지만 전 한 번에 한 사람씩 동작 반복을 세는 데만 관심이 있습니다 그래서 전 인간 몸 자세 추출자를 자세 선택자로 구성하겠습니다 자세 선택자는 자세들의 배열과 선택 전략을 갖고 하나의 자세를 되돌려줍니다 고를 수 있는 선택 전략엔 몇 가지가 있지만 이 사례에서는 rightMostJointLocation 전략을 사용하겠습니다 다음 단계는 자세들을 창으로 나누는 겁니다 그걸 위해 저는 슬라이딩 창 변환기를 덧붙이겠습니다 그리고 전 창 길이와 걸음으로 90을 사용하겠습니다 그건 90가지 자세의 겹치치 않는 창들을 생성해줍니다 슬라이딩 창 변환자는 시간과 관련 있다는 걸 기억하세요 그건 전체 작업을 시간과 관련 있게 하고 예상된 입력은 이제 프레임들의 비동기 시퀀스입니다 마지막으로 전 인간 몸 동작 카운터를 덧붙입니다 이 시간 변환자는 동작의 창이 있는 비동기 시퀀스를 소모하고 지금까지의 동작 반복 누적 횟수를 되돌려줍니다 지금쯤 여러분은 횟수가 부동 소수점 수란 걸 발견했을 수도 있습니다 그 이유는 작업이 부분적 동작도 세기 때문입니다 그 정도로 쉽습니다 이제 전 제 운동 영상에서 반복 횟수를 세면서 제가 편법을 안 쓰는 걸 확인할 수 있습니다 하지만 앱에서 그걸 실시간으로 셀 수 있으면 더욱 좋겠죠, 제 현재 운동 정보를 알 수 있게요 그렇게 할 수 있는 방법을 보여드리죠 먼저 저는 readCamera 기법을 사용할 텐데 그건 카메라 설정을 갖고 카메라 프레임의 비동기 시퀀스를 되돌려줍니다 다음으로는 걸음 파라미터를 15프레임으로 조절해서 업데이트된 횟수를 더 자주 받도록 하겠습니다 제 카메라가 초당 30프레임의 속도로 프레임을 캡처하면 저는 0.5초마다 횟수를 받습니다 이제 운동하면서 반복 횟수를 놓치는 걸 걱정 안 해도 되죠 지금까지 저는 비동기 시퀀스 변환을 위한 시간 관련 구성 요소들을 살펴봤습니다 다음으로는 시간 데이터에 의존하는 맞춤형 모델 훈련에 집중하고 싶습니다 2019년에 우린 Create ML에서 사운드 분류자를 훈련시키는 방법을 시연했습니다 그리고 2021년에 우린 사운드 분류에 대한 개선 사항을 소개했습니다 저는 더 나아가서 맞춤형 사운드 분류자를 증대식으로 훈련시키고 싶습니다 Create ML 프레임워크의 MLSoundClassifier는 맞춤형 사운드 분류자 모델을 훈련시키기 위한 가장 쉬운 방법입니다 그런데 여러분한테 맞춤 가능성과 제어가 더 필요하면 보이지 않는 구성 요소들을 쓸 수 있습니다 가장 간단한 형식의 사운드 분류자의 요소는 둘입니다 Audio Feature Print 특징 추출자와 여러분이 선택한 분류자입니다 AudioFeaturePrint는 시간 변환자로 오디오 버퍼의 비동기 시퀀스에서 오디오 특징들을 추출해줍니다 슬라이딩 창 변환자와 유사하게 AudioFeaturePrint는 비동기 시퀀스를 창으로 만들고 특징들을 추출해줍니다 선택할 수 있는 분류자들은 몇 가지가 있지만 이 사례에서 저는 로지스틱 회귀 분류자를 씁니다 그런 다음 특징 추출자와 함께 그걸 구성해서 맞춤형 사운드 분류자를 구축하겠습니다 다음 단계는 맞춤형 사운드 분류자를 레이블이 붙은 훈련 데이터에 피팅하는 겁니다 훈련 데이터 수집에 관한 자세한 정보를 원하면 'Get to know Create ML Components' 세션이 시작하기에 좋습니다 지금까지 저는 행복한 경로를 다뤘습니다 하지만 기계 학습 모델 구축은 반복적인 과정이 될 수 있습니다 예를 들어 여러분은 시간이 지나며 새 훈련 데이터를 발견하고 수집해서 모델을 새롭게 바꾸고 싶을 수 있습니다 모델 품질을 개선하는 일은 가능합니다 하지만 처음부터 모델을 재훈련시키는 데는 시간이 걸리죠 그 이유는 이전 데이터 모두에 특징 추출을 다시 해야 하기 때문입니다 새롭게 발견한 데이터로 모델을 훈련시킬 때 시간을 절약할 방법에 관한 예를 한 가지 말씀드리죠 핵심은 훈련 데이터를 모델 피팅과는 별도로 사전에 처리하는 겁니다 이 사례에서 저는 오디오 특징을 분류자 피팅과 별도로 추출할 수 있습니다 이건 일반적인 경우에도 효과가 있습니다 일련의 변환자들이 있고 추정자가 그 뒤를 이을 때마다 여러분은 추정자로 이어지는 변환자를 통해 입력을 사전 처리할 수 있습니다 여러분은 사전 처리 기법을 호출하고 사전 처리된 특징에 모델을 피팅하기만 하면 됩니다 전 이게 편리하다고 봅니다 사운드 분류자의 구성을 바꿀 필요가 없었으니까요 이제 특징들을 별도로 추출해 놓았으니 저한텐 새 데이터의 오디오 특징들만 추출할 유연성이 있습니다 여러분이 자신의 모델을 위한 새 훈련 데이터를 발견할 때 이 데이터를 별도로 쉽게 사전에 처리할 수 있습니다 그런 다음 이전에 추출된 특징들에 보완적인 특징들을 덧붙입니다 이건 사전 처리가 시간을 절약해주는 것의 첫 사례에 불과합니다 모델 구축 수명 주기로 되돌아가봅시다 여러분은 자신의 모델 품질에 만족할 때까지 자신의 추정자 파라미터를 조절해야 할 수 있습니다 피팅에서 특징 추출을 분리하는 방식으로 여러분은 특징들을 단 한 번만 추출한 다음 다른 추정자 파라미터가 있는 자신의 모델을 피팅할 수 있습니다 분류자 파라미터를 바꾸는 것의 한 가지 예를 살펴보죠 특징 추출을 다시 하지 않고요 제가 특징들을 이미 추출했다고 가정하고 분류자의 L2 페널티 파라미터를 수정하겠습니다 그런 다음 새로운 분류자를 예전 특징 추출자에 덧붙여야 합니다 추정자를 조절할 때는 특징 추출자를 바꾸지 않는 게 중요합니다 그건 이전에 추출된 기능들을 무효화할 것이기 때문입니다 이제 집단으로 모델을 증대하며 피팅하기로 넘어가보죠 기계 학습 모델은 일반적으로 다량의 훈련 데이터로 이익을 얻습니다 하지만 여러분 앱의 메모리에 제한이 있을 수 있죠 그럼 어떻게 해야 할까요? Create ML Components를 써서 모델을 훈련시킬 수 있습니다 한 번에 하나의 데이터 집단을 메모리에 로딩하는 방식으로요 제가 제일 먼저 해야 할 일은 분류자를 업데이트가 가능한 분류자로 대체하는 겁니다 집단으로 맞춤형 모델을 훈련시키기 위해서는 여러분의 분류자는 업데이트가 가능해야 합니다 예를 들어 완전히 연결된 신경망 분류자가 있는데 그건 로지스틱 회귀 분류자 대신 제가 쉽게 사용할 수 있는 겁니다 로지스틱 회귀는 업데이트가 불가능하죠
좋아요, 이제 훈련 루프를 작성하겠습니다 디폴트 초기 모델을 만들면서 시작하겠습니다 아직 여러분은 예측할 수 없습니다 이유는 이것이 훈련의 출발점에 불과하기 때문입니다 그리고 저는 훈련이 시작되기 전에 오디오 특징들을 추출하기 시작합니다 이건 중요한 단계입니다 반복할 때마다 특징들을 추출하고 싶진 않으니까요 다음 단계는 훈련 루프를 정의하고 여러분이 훈련시키고 싶은 반복 횟수를 명시하는 겁니다 계속하기 전에 저는 알고리즘의 Swift 패키지를 가져옵니다 그건 훈련 데이터 집단을 만들기 위해 필요합니다 WWDC 2021의 세션인 'Meet the Swift Algorithms and Collections packages'를 꼭 확인해서 자세히 알아보세요
훈련 루프 내에서 집단화 작업이 일어납니다 청크 기법을 써서 훈련을 위해 특징들을 집단으로 나누겠습니다 청크 크기는 한 번에 메모리에 로딩되는 특징들의 수입니다 그리고 저는 모델을 업데이트할 수 있습니다, 집단에 대해 작업을 반복하고 업데이트 기법을 호출해서요
여러분이 모델을 증대 방식으로 훈련시키면 훈련 기술 몇 가지를 더 이용할 수 있습니다 예를 들어 이 훈련 그래프에서 대략 10회 반복 후에 모델 정확성은 95%에서 안정 상태가 됩니다 이 시점에서 모델은 수렴했고 여러분은 조기에 중단할 수 있습니다 훈련 루프에서 조기 중단을 실행해봅시다 먼저 해야 할 일은 제 인증 세트에 대한 예측을 하는 겁니다 여기에서 저는 mapFeatures 기법을 씁니다 승인 예측을 그것의 주석과 페어링해야 하기 때문입니다 다음 단계는 모델의 품질을 측정하는 겁니다 당장에는 내장 수치를 사용하겠지만 여러분 자신만의 맞춤형 수치를 적용하는 걸 막을 게 없습니다 그리고 마지막으로 제 모델이 정확성 95%에 도달하면 훈련을 중단합니다 훈련 루프 밖에, 그 모델이 디스크로 나가도록 작성합니다 제가 나중에 예측하는 데 쓸 수 있게요 조기 중단에 덧붙여 모델 체크 포인트 작업을 설명하고 싶습니다
여러분은 끝까지 기다리지 않고 모델의 진행 상황을 훈련 중에 저장할 수 있습니다 그리고 체크 포인트 작업을 사용해서 훈련을 재개할 수도 있습니다 그건 편리하죠 특히 여러분의 모델이 훈련하는 데 오래 걸린다면요 훈련 루프에 여러분의 모델을 작성해 넣기만 하면 됩니다 몇 번의 반복 작업마다 이렇게 하는 걸 추천합니다 체크 포인트 간격을 정의해서요 그 정도로 쉽습니다 이번 세션에서 제가 소개한 건 시간 관련 구성 요소들과 오디오와 비디오 같은 시간 데이터로 기계 학습 작업을 구축하는 새로운 방법이었습니다 저는 시간 관련 요소들을 함께 구성해서 인간 동작 반복 카운터를 만들었습니다 마지막으로 증대 방식 피팅을 설명했습니다 이는 여러분이 앱에 기계 학습을 구축하는 데 있어서 새로운 가능성을 열어줄 겁니다 함께해주셔서 감사하고 WWDC의 남은 행사도 즐기세요 ♪
-