-
Metal을 통한 머신 러닝 가속화
Metal을 사용하여 macOS에서 PyTorch 모델 학습을 더 빠르게 진행하는 방법을 확인하세요. TensorFlow 학습 지원에 대한 업데이트를 안내하고, MPS 그래프의 최신 기능 및 작업을 살펴보며, 모든 머신 러닝 요구 사항에 맞는 탁월한 성능을 실현하기 위한 모범 사례를 소개합니다. 머신 러닝과 Metal의 사용에 대한 자세한 내용을 알아보려면 WWDC21의 ‘Accelerate machine learning with Metal Performance Shaders Graph(Metal 성능 셰이더 그래프를 통한 머신 러닝 가속화)'를 시청하시기 바랍니다.
리소스
관련 비디오
WWDC23
WWDC22
WWDC21
-
비디오 검색…
♪ ♪
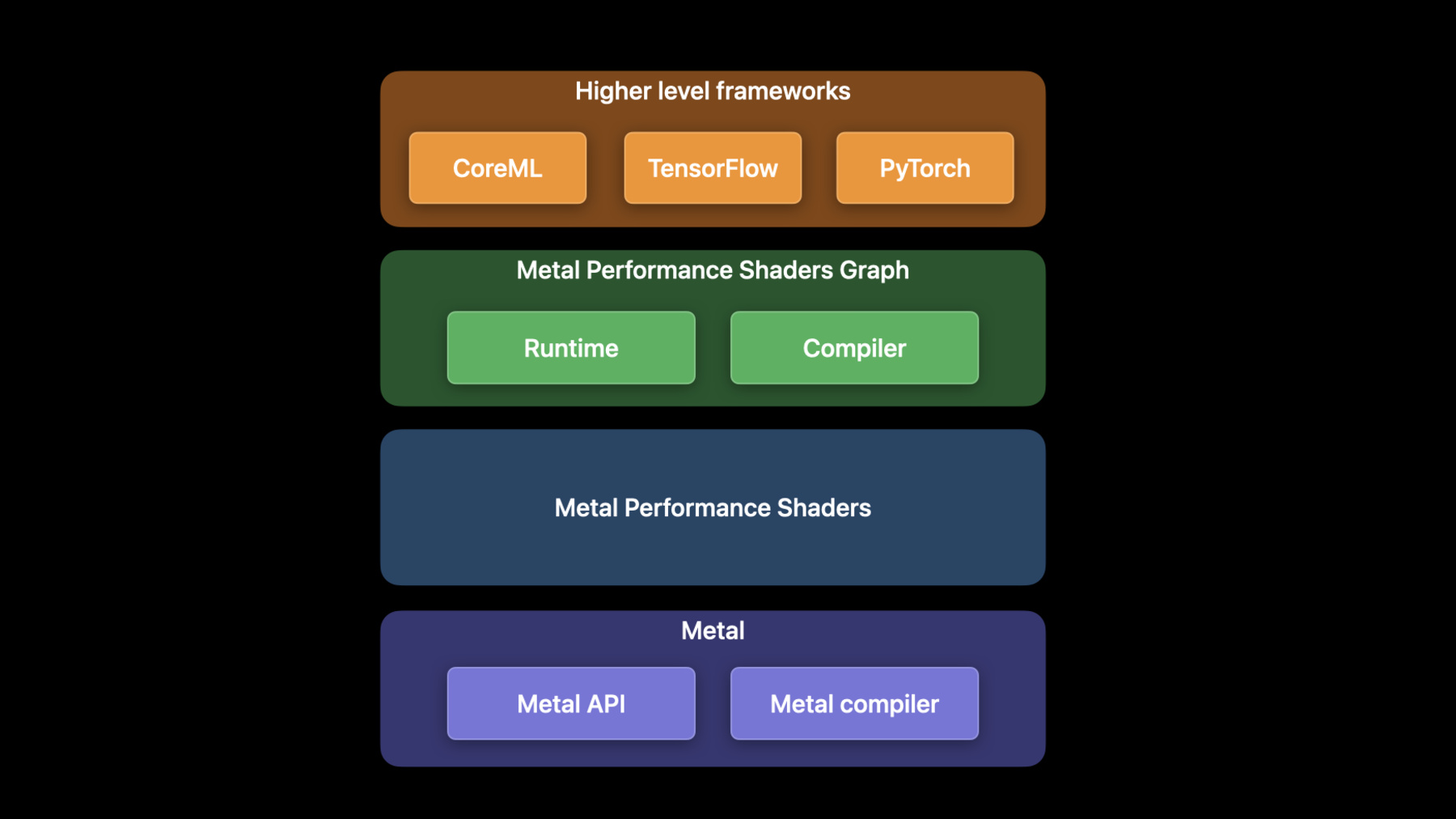
WWDC 2022에 오신 걸 환영합니다 제 이름은 Dhruva고 GPU 소프트웨어 엔지니어죠 오늘 Matteo와 제가 함께 올해 Metal 머신 러닝에 도입된 새로운 기능과 개선 사항을 소개하겠습니다 머신 러닝 훈련은 머신 러닝 파이프라인에서 연산 강도가 가장 높은 절차죠 병렬적 특성 때문에 GPU가 머신 러닝을 잘 처리합니다 Metal의 머신 러닝 API는 Metal 퍼포먼스 셰이더인 MPS라는 프레임워크를 통해 접근할 수 있습니다 MPS는 고성능 GPU 프리미티브의 집합으로 이미지 처리나 선형 대수 레이 트레이싱, 머신 러닝 등 다양한 분야에 사용되죠 Metal 커널은 최적화되어 모든 Apple 플랫폼에서 최고의 성능을 발휘합니다 예를 들어 MPSImageCanny 필터는 입력한 이미지에 대한 테두리 지도를 반환하죠 이미지 세그먼테이션 프로그램에서 통상적인 작업입니다 올해, Canny 필터를 통해 4K 고화질 이미지를 8배 빨리 처리할 수 있죠 MPS Graph는 일반 목적의 연산 그래프로 GPU가 MPS 프레임워크를 관장하며 다차원 텐서에도 지원을 확대합니다 이전 세션에서 MPS Graph 사용법에 관해 자세히 알아보시기 바랍니다 CoreML이나 Tensorflow 같이 수준 높은 ML 프레임워크는 MPS Graph를 관장하죠 GPU에서 TensorFlow Metal 플러그인으로 GPU의 TensorFlow 네트워크를 가속할 수 있습니다 TensorFlow의 활용법은 작년 세션을 참고하십시오 Matteo와 저는 이번 세션에서 3가지 주제를 다룹니다 먼저 Apple GPU에 도입되는 최신 ML 프레임워크인 PyTorch를 소개하고 올해 TensorFlow의 개선 사항을 다룰 거예요 Matteo는 MPS Graph 프레임워크의 새로운 사항을 얘기할 겁니다
여러분의 Mac GPU에서 PyTorch 네트워크를 가속할 수 있어 정말 기쁩니다 PyTorch는 유명한 오픈 소스 머신 러닝 프레임워크죠 PyTorch 커뮤니티에서 가장 많이 요청하는 기능은 Apple Silicon의 GPU 가속을 지원하는 거였습니다 우리는 Metal의 성능을 PyTorch에서 활용하기 위해 새로운 MPS 백엔드를 PyTorch 생태계에 도입할 예정이죠 이 백엔드는 PyTorch 1.12 출시에 포함될 것입니다 MPS 백엔드에서는 PyTorch 작업 커널을 적용하고 Runtime 프레임워크도 적용하죠 작업은 MPS Graph와 MPS에서 소환하고 Runtime 요소는 Metal을 사용합니다 이를 통해 PyTorch가 MPS에서 고효율 커널을 사용할 수 있죠 Metal의 명령 대기열과 명령 버퍼 동기화 프리미티브도 포함합니다
작업 커널은 PyTorch MPS Runtime 요소는 오픈 소스 코디의 일부이며 공식 PyTorch GitHub 저장소에 병합되죠 MPS PyTorch 백엔드를 사용하려면 3단계만 거치면 됩니다 먼저, PyTorch 1.12 버전부터 ‘pip install torch'를 이용하여 기반 패키지를 설치할 수 있죠 공식 파이썬 패키지 저장소에 있습니다 환경 설정과 설치에 관한 자세한 사항은 Metal 개발자 자료실 웹페이지를 참고하세요 둘째, PyTorch를 임포트 하여 MPS 기기를 생성하십시오 이 코드는 MPS 기기 백엔드가 있으면 그걸 사용하고 없으면 다시 CPU를 연결합니다 끝으로 모형과 입력값을 입력하여 MPS 기기를 사용하는 거죠 방법을 설명하기 위해서 .torchvision의 이미 훈련된 ResNet50 모형에 추론을 실행하는 예를 들겠습니다 모형은 기본적으로 CPU에서 실행하죠 to 메서드를 이용하여 MPS 기기를 사용하도록 모형을 변환하십시오 이를 통해 모형 안의 중간자 텐서도 가속 MPS 백엔드를 사용할 수 있습니다 마침내 모형을 실행할 수 있죠 이 예시는 임의의 입력값 텐서를 MPS 모형에 통과시킵니다 기본적으로 모든 텐서는 CPU에 배정되어 있죠 MPS 백엔드를 사용하려면 MPS 기기를 이곳에도 제공해야 합니다 이 텐서의 이후 작업은 GPU에서 가속화되죠 샘플 입력값을 MPS_model에 넣으면 예측치가 나옵니다 MPS 기기 사용법을 알게 됐으니 PyTorch 사용 예를 보여 드리죠 저는 항상 유명한 예술가가 되고 싶었습니다 그래서 머신 러닝과 GPU를 활용하여 StyleTransfer 네트워크로 예술품을 만들려고 했죠 이 네트워크는 이미지에 다른 스타일을 적용할 수 있습니다 이 예에서는 반 고흐의 '별이 빛나는 밤' 스타일을 고양이 사진에 적용하는 게 목표죠 새로운 MPS 기기로 GPU를 활용해 PyTorch 네트워크를 더 빠르게 훈련할 수 있습니다 이걸 시현하기 위해서 네트워크 훈련을 시작하죠 M1 Max의 CPU와 GPU에 동시 사용하겠습니다 이 스타일을 배우려면 수천 번의 반복이 필요하지만 GPU를 통해 괜찮은 모형을 적은 시간에 만들 수 있죠
StyleTransfer는 물론이고 모든 PyTorch 벤치마크에서 속도가 많이 빨라졌습니다 M1 Ultra에서는 속도가 최고 20배 빨라졌고 평균 8.3배 빨라졌죠 PyTorch는 머신 러닝 모형 개발을 더 쉽게 해 주고 Apple GPU로 훈련하면 시간을 많이 절약할 수 있습니다 이제, 올해 TensorFlow의 모든 개선 사항을 살펴보죠 Tensorflow Metal 가속화는 Tensorflow 버전 2.5부터 Tensorflow Metal 플러그인으로 제공해 왔죠 이후 추가 기능과 개선 사항이 있었습니다 개선 사항에는 큰 배치에 대한 훈련 개선과 새로운 작업 및 커스텀 작업 지원 RNN 개선 사항과 분산 학습이 포함돼 있죠 TensorFlow Metal 플러그인 버전들은 TensorFlow의 주요 버전과 일치하게 되어 있으니 TensorFlow 패키지를 업데이트해야 최신 기능과 개선 사항을 이용할 수 있습니다 큰 규모의 배치부터 시작하죠 올해 TensorFlow-Metal의 소프트웨어 개선 사항은 Apple Silicon 아키텍처의 독특한 이점을 활용하기 위한 것입니다 이 그래프는 다양한 배치 크기로 ResNet50 모형을 훈련했을 때 얼마나 가속되는지 보여 주죠 배치가 커질수록 성능이 좋아지는 거로 나타나는데 경사도가 증가할수록 진정한 경사도에 가까워지기 때문이죠 Apple Silicon의 통합 메모리 아키텍처는 더 큰 배치 크기나 네트워크를 실행하게 해 줍니다 이제 단일 Mac Studio에서 작업을 소화할 수 있으며 클라우드 클러스트에 나눠서 작업하지 않아도 돼서 좋죠 Apple Silicon 아키텍처는 와트당 성능이 높아서 네트워크가 어느 때보다 효율적으로 실행됩니다 이제 신규 작업과 커스텀 작업에 관해 얘기하죠 Tensorflow Metal 플러그인은 GPU 가속이 포함되어 다양한 신규 작업이 가능한데 argMin, all, pack, adadelta 등을 포함합니다 하지만 GPU 가속을 위한 작업을 Tensorflow API에서 지원하지 않는다면 어떻게 할까요? 이를 위해 커스텀 작업을 생성해야 하죠 2회 반복하는 간단한 합성곱 네트워크를 예로 들겠습니다 타임라인은 GPU와 CPU가 각각 위와 아래에서 작업하는 걸 나타냅니다 네트워크는 합성곱을 한 뒤 MaxPool을 진행하고 Softmax와 교차 엔트로피 손실을 진행하죠 모든 작업은 GPU로 가속되며 MPS Graph로 TensorFlow-Metal 플러그인에서 진행합니다 하지만 커스텀 손실 함수를 사용하고 싶을 수도 있죠 커스텀 손실에 대한 MPS GPU 가속이 없으면 이 작업은 CPU 타임라인에서 실행되어야 하는데 동기화 오버헤드가 발생하여 GPU가 기아 상태가 됩니다 커스텀 손실 작업을 GPU에서 하면 성능이 훨씬 좋아지죠 커스텀 작업을 적용하려면 TensorFlow-MetalStream 프로토콜을 이해해야 합니다 GPU 작업을 인코딩할 때 사용하는 프로토콜이죠 MetalStream은 MTLCommandBuffer의 참조 값을 보관하여 GPU 커널을 인코딩합니다 또한 dispatch_queue를 노출하여 CPU 동기화에 사용하면서 작업을 제출하는 스레드가 다수면 인코딩 작업도 합니다 commit이나 commitAndWait로 GPU에 작업을 제출하세요 CommitAndWait는 현재 명령 버퍼가 끝날 때까지 기다리는 디버깅 도구로 연속 제출을 관찰할 수 있죠 이제 이 개념을 커스텀 작업 적용에 사용해 보죠 커스텀 작업 코드를 작성하는 세 단계가 있죠 먼저 작업을 등록합니다 다음은 MetalStream으로 작업을 적용하죠 마지막으로 연습용 스크립트에 작업을 임포트 하여 사용하세요 그러면 작업 등록부터 시작하죠 TensorFlow 코어의 REGISTER_OP macro를 사용하여 작업의 의미를 구체화하고 TensorFlow-Metal 플러그인 안에서 정의하세요 이제 TensorFlow_MetalStream으로 작업을 적용합니다 먼저 compute 함수를 정의하세요 이 함수 안에서 TensorFlow_Tensor 객체를 입력값으로 가져오고 출력값을 정의해야 하는데 할당이 필요할 수도 있습니다 다음에는 MetalStream의 명령 버퍼로 인코더를 만드세요 다음은 커스텀 GPU 커널을 정의합니다 작업은 MetalStream이 제공하는 dispatch_queue 안에 인코딩해야 하죠 그러면 다수 스레드에서 제출한 데이터가 직렬화됩니다
그리고 TensorFlow_MetalStream 프로토콜이 제공하는 메서드를 사용하여 커널을 커밋하세요
마지막으로 할당된 텐서에 관한 참조 값을 삭제하십시오
마지막으로 연습용 스크립트에 작업을 임포트 하여 사용하세요 이때 공유 동적 라이브러리 파일 zero_out.so를 빌드하십시오 .so 파일을 빌드하고 임포트 하는 정보는 Metal 개발자 자료를 참조하세요 이 예시에서는 작업을 연습용 스크립트에 임포트 할 때 TensorFlow load_op_library를 사용합니다 이는 선택적인 단계죠 이건 파이썬 래퍼처럼 작동하고 연습 스크립트에서 커스텀 작업을 인보크 할 수 있어요 이제 흥미로운 프로그램인 '뉴럴 래디언스 필드' 또는 NeRF의 예를 보여 드리겠습니다 우리는 커스텀 작업을 작성하여 네트워크 성능을 높였는데 더 좋은 알고리즘을 위해 GPU 가속을 활성화했죠
NeRF는 모형의 3D 형태를 통합하는 네트워크입니다 훈련 중인 NeRF는 물체를 여러 각도에서 촬영하죠 NeRF 네트워크는 2 중첩 다중 레이어 퍼셉트론으로 구성되며 출력값은 모형의 부피 형태로 나타나죠 실시간 훈련을 위한 핵심 성능 최적화는 해시 테이블 적용을 사용합니다 업데이트된 네트워크는 더 작은 다중 레이어 퍼셉트론을 허용하죠 TensorFlow는 네이티브에서 해시 테이블을 지원하지 않아 커스텀 작업 기능을 이용해 Metal 플러그인에 적용합니다 해시 테이블을 위한 GPU 가속으로 NeRF를 더 빠르게 훈련하죠 이 MacBook을 시작하여 다중 레이어 퍼셉트론 적용을 실행하겠습니다
합당한 수준의 렌더링을 하려면 에포크가 최소 20이어야 하는데 에포크 당 최소 100초가 걸리죠 결과를 보려면 30분을 기다려야 해서 미리 훈련한 체크포인트 파일을 다시 시작하겠습니다 미리 30분간 훈련하고 있었죠 에포크 20에서 시작합니다 30분이나 훈련했지만 3D 모형이 흐릿하고 또렷하지 않죠 네트워크의 훈련 시간이 더 길어야 명확한 모형을 학습할 수 있습니다 커스텀 해시 테이블이 없는 기존 2 중첩 다중 레이어 퍼셉트론 접근 방식은 너무 느리죠 이제 이 MacBook에 커스텀 해시 테이블을 쓰는 최적화된 버전을 시작하겠습니다 이 적용은 벌써 명확한 모형을 렌더링 할 수 있고 에포크 당 학습 시간이 10초에 불과하죠 이 프로젝트에 관한 추가 정보는 Metal 개발자 리소스에 업로드한 샘플 코드를 참조하십시오
NeRF는 커스텀 작업을 위한 GPU 가속을 적용하여 네트워크가 엄청나게 빠른 속도로 실행되는 걸 보여 주는 많은 네트워크 중 하나일 뿐입니다 앞으로 여러분이 만들 창의적인 커스터마이징을 기대하도록 하죠 이제 Apple GPU를 이용하여 머신 러닝 훈련의 워크로드를 분배하는 방법을 보여 드리겠습니다 훈련 워크로드를 분배하려면 별도의 프로세스에서 다수의 훈련 스크립트를 실행하고 각 프로세스에서 모델의 단일 반복을 평가할 수 있죠
각 프로세스는 중앙 저장소에서 데이터를 읽습니다 그리고 모형 안에 실행되어 모형 경사를 계산하죠 이후, 프로세스가 경사의 평균값을 공유하여 각 프로세스가 다음 반복 전에 같은 경사가 되도록 합니다 마지막으로 모형을 업데이트하여 반복 횟수가 소진될 때까지 이 과정을 반복하는 거죠 TensorFlow에서 이를 시현하기 위해 분산 학습 예시를 사용할 건데 Horovod라는 유명 오픈 소스 프레임워크를 이용할게요
Horovod는 링 올리듀스 방식을 사용합니다 이 알고리즘에서 N개의 각 노드는 2개의 피어와 여러 번 통신합니다 이 통신을 이용하여 작업자 프로세스의 경사를 반복 전에 동기화하죠 Thunderbolt 케이블로 연결된 4대의 Mac Studio를 이용하여 직접 보여 드릴게요 이 예시에서는 이미지를 분류하는 ResNet을 훈련할 겁니다 각 Mac Studio 옆의 바는 이 네트워크를 훈련하는 동안 GPU 활용도를 보여 주죠 단일 Mac Studio에서 초당 200개의 이미지를 작업합니다 Thunderbolt로 연결하여 다른 Mac Studio를 추가했더니 성능이 초당 400개 이미지로 거의 2배가 되었는데 두 개의 GPU를 최대한으로 활용했기 때문이죠 마지막으로 Mac Studio를 2대 더 연결했더니 성능이 초당 800개 이미지로 향상됐습니다 연산 위주의 훈련 워크로드에서 선형으로 증가했죠
이제 TensorFlow의 분산 학습 성능을 살펴보겠습니다 이 도표는 Mac Studio 1, 2, 4대의 가속을 보여 주죠 링형 토폴로지로 연결되어 resNet와 DistilBERT 같은 연산 위주의 TensorFlow 네트워크를 실행했습니다 TensorFlow-Metal 플러그인과 Horovod를 이용했죠 기준값은 Mac Studio 1대의 성능입니다 GPU를 추가할 때마다 네트워크 성능이 향상되는 걸 볼 수 있는데 여러 기기의 GPU를 통해 훈련 속도를 높이고 Apple 기기를 최대한 활용할 수 있죠
올해 TensorFlow의 개선 사항과 추가된 기능을 이 그래프로 확인할 수 있는데 CPU를 이용했을 때와 비교한 자료입니다 이후에도 더 개선할 예정이죠 MPS Graph 프레임워크의 새 소식은 Matteo가 공유하겠습니다 고마워요, Dhruva 안녕하세요, 저는 Matteo고 GPU 소프트웨어 엔지니어입니다 PyTorch와 TensorFlow는 MPS Graph 프레임워크 위에 있죠 대신 MPS Graph는 MPS 프레임워크로 노출된 병렬 프리미티브를 사용하여 GPU의 작업 속도를 높입니다 오늘 제가 소개할 2개의 기능을 활용하면 MPS Graph로 연산 워크로드를 더 빠르게 처리할 수 있죠 먼저 공유 이벤트 API를 보여 드릴 텐데 두 그래프 사이에서 작업을 동기화합니다 둘째, 신규 작업을 검토하여 MPS Graph를 더 활용할 수 있도록 하죠 공유 이벤트 API부터 시작하겠습니다 같은 명령 대기열에서 프로그램을 실행하면 워크로드 간 동기화가 일어나죠 이 예시에서는 다른 워크로드인 후처리와 디스플레이를 디스패치 하기 전에 연산 작업 부하를 종료합니다 이런 사례에서는 단일 디스패치 내에서 GPU 병렬성을 이용할 수 있죠 일부 프로그램은 더 많은 병렬성을 이용할 수 있는데 GPU의 첫째 부분은 연산에 사용하고 둘째 부분은 후처리와 디스플레이에 사용하는 거죠 다중 명령 대기열의 GPU에 작업을 제출하면 됩니다 안타깝게도 이 사례에서는 후처리 파이프라인이 연산이 결과를 산출하기 전에 디스패치 되어 데이터 레이스가 일어날 수 있죠 공유 이벤트 API로 이 문제를 해결하고 명령 대기열 간 동기화를 도입하여 작업 흐름 의존성을 만족할 수 있습니다 코드에 공유 이벤트를 사용하는 건 쉽죠 두 그래프를 작업 중이라고 가정합시다 첫째는 연산 워크로드를 담당하죠 두 번째는 후처리 워크로드를 담당합니다 또한 연산 그래프의 결과를 후처리 그래프의 입력값으로 사용한다고 가정하죠 그리고 서로 다른 명령 대기열에서 실행합니다 Metal 시스템 트레이스의 새로운 MPS Graph 트랙은 명령 대기열이 서로 중첩되는 걸 보여 주죠 이는 데이터 레이스를 유발합니다 공유 이벤트로 이 문제를 해결할 수 있죠 먼저 Metal 기기를 이용하여 이벤트를 생성하세요 다음은 실행 디스크립터의 signal 메서드를 인보크 하기 위해 이벤트, 동작, 값을 제공하십시오 이제 두 번째 디스크립터인 wait 메서드를 호출하면 되는데 이벤트와 값 변수를 제공하면 되죠
Metal 시스템 트레이스는 2개의 명령 대기열이 차례대로 실행되며 연산과 후처리 그래프 사이의 의존성 문제가 해결됐습니다 동기화 문제를 해결하기 위해 여러분의 프로그램에서 공유 이벤트를 사용하는 방법이었죠 이제 MPS Graph가 지원하는 새로운 작업을 살펴볼게요 이 작업으로 프레임워크를 통해 더 많은 일을 할 수 있죠 RNN을 시작으로 각 작업의 세부 사항을 살펴볼게요
MPS Graph는 RNN 애플리케이션 내에서 흔히 사용하는 3개의 작업을 노출합니다 이 작업은 RNN, LSTM 그리고 GRU 레이어죠 이 작업은 전부 비슷하게 작동하므로 오늘은 LSTM만 다루겠습니다 LSTM 작업은 자연 언어 처리를 비롯한 다른 프로그램에 흔히 사용되죠 이 도표는 LSTM 작업의 원리를 보여 줍니다 더 알고 싶다면 이전 WWDC 세션을 참고하세요 직접 LSTM 유닛을 적용할 수도 있지만 복잡한 커스텀 서브 그래프를 만들어야 합니다 대신 새로운 LSTM 작업을 사용하면 반복 유닛이 요구하는 GPU 작업을 효율적으로 인코딩할 수 있죠 이 작업으로 LSTM 기반의 CoreML 추론 모델이 훨씬 빨라집니다
새로운 LSTM 작업을 사용하려면 MPS GraphLSTMDescriptor를 생성하세요 디스크립터의 속성은 필요에 따라 수정하십시오 예를 들어 활성화 함수를 선택할 수 있죠 다음은 입력값 텐서를 제공하여 LSTM 유닛을 그래프에 추가하세요 편향 벡터와 초기 상태 작업을 위한 셀을 제공할 수도 있죠 마지막으로 디스크립터를 제공하세요 이것만 하면 LSTM을 설정할 수 있죠 다른 RNN 작업도 비슷하게 작동합니다 이런 작업을 시도하여 여러분의 프로그램에 어떤 가속을 적용할 수 있는지 알아보십시오 이제 MaxPooling에 대한 지원 개선을 보여 드리죠 MaxPooling 작업에는 입력값 텐서와 창 크기를 가지고 창의 각 애플리케이션의 창 내 최대 입력값을 계산합니다 이미지의 차원 수를 줄이기 위해 컴퓨터 비전에서 사용하죠 API를 확장하여 풀링 연산자를 통해 추출한 최댓값 위치의 인덱스를 반환했습니다 경사 패스의 인덱스를 사용할 수 있는데 최댓값을 추출한 위치로 경사가 전파되죠 새로운 API는 훈련에도 사용할 수 있습니다 훈련 중에 인덱스를 재사용하면 PyTorch와 TensorFlow가 6배까지 빨라지죠
이를 코드로 작성하려면 그래프 풀링 디스크립터를 만들고 반환 인덱스 모드를 globalFlatten4D 등으로 지정하세요 Return Indices API로 그래프에 풀링 작업을 호출할 수 있죠 작업의 결과는 두 가지입니다 하나는 poolingTensor고 두 번째는 indicesTensor죠 indicesTensor는 캐싱하여 나중에 사용할 수 있습니다 예를 들면 훈련 파이프라인에요
MPS Graph는 새로운 병렬 난수 생성기를 노출하는데 예를 들어 훈련 그래프 초기화에 사용할 수 있죠 새로운 난수 작업은 Philox 알고리즘을 사용하는데 TensorFlow로 주어진 시드에 대해 같은 결과를 반환합니다 새로운 작업은 입력값으로 상태 텐서를 쓰고 출력값으로 무작위 텐서를 반환하죠 새로운 상태 텐서는 두 번째 무작위 작업의 입력값으로 사용할 수 있습니다 새로운 난수 작업을 활용하려면 randomPhiloxStateTensor 메서드를 호출하세요 이 메서드는 주어진 시드와 함께 상태 텐서 입력값을 초기화하죠 그리고 RandomOp 디스크립터를 선언하여 분배와 데이터 유형을 입력값으로 사용합니다 예시에서 디스크립터는 32비트 플로팅 포인트 값의 truncatedNormal 분배로 설정했죠 정규 및 균일 분포를 이용할 수도 있습니다
분포의 특징을 상세하게 정의하기 위해서 평균과 표준 편차 최소, 최댓값을 지정할 수도 있죠 마지막으로 모양 텐서와 디스크립터, stateTensor로 난수 작업을 생성할 수 있습니다
난수 작업에 더하여 MPS Graph는 새로운 GPU 가속 작전을 지원하여 2비트 벡터 간 해밍 거리를 계산할 수 있죠 해밍 거리는 길이가 같은 두 입력값 사이의 비트 차이 값으로 정의되는데 두 문자열 사이의 편집 거리를 측정한 값으로 생물 정보학과 암호학 등 다양한 분야에서 사용합니다 HammingDistance를 사용하려면 그래프의 API를 호출해야 하는데 primaryTensor, secondaryTensor 결과 데이터 유형을 제공하십시오 새로운 커널이 GPU의 배치 차원에 대한 브로드캐스팅을 지원하죠 이제 새로운 텐서 변형 작업을 보여 드릴 건데 사용이 아주 쉽습니다 예를 들어 텐서의 차원을 2차원에서 3차원으로 확장할 수 있죠 차원을 다시 줄일 수도 있습니다
슬라이스 개수와 축을 제공하여 텐서를 균일하게 나누거나 특정 축을 따라 텐서를 중첩할 수도 있죠
입력값인 도형에 대해 텐서 차원에 따른 좌푯값을 생성할 수도 있습니다 예를 들어 2x4 크기의 텐서의 0축을 따라 데이터를 입력할 수 있죠 range1D 작업의 적용에도 사용할 수 있습니다 예를 들어 3과 27 사이에서 4씩 늘어나는 숫자열을 생성한다고 가정합시다 먼저 0차원을 따라 모양 6에 해당하는 텐서의 좌푯값을 생성할 수 있죠 그리고 증분으로 곱한 뒤 차이 값을 더하면 됩니다 이건 올해 추가된 새로운 작업입니다 새로운 작업을 통해 더 많은 걸 할 수 있고 MPS Graph로 Apple 생태계에서 높은 성과를 낼 수 있죠 Apple Silicon의 MPS Graph로 개선할 수 있는 성능 향상에 관해 보여 드리겠습니다 블랙매직에서 다빈치 리졸브 버전 18을 출시했는데 MPS Graph를 이용하여 머신 러닝 워크로드를 가속했죠 매직 마스크라는 기능은 머신 러닝을 이용하여 화면의 움직이는 대상을 식별하고 선택적으로 필터를 적용합니다 다빈치 리졸브의 이전 버전에서 어떻게 작동했는지 보여 드리고 현재 버전과 비교하겠습니다 마스크를 생성하려면 대상 오브젝트를 선택하세요 오버레이를 토글 하여 마스크를 볼 수 있죠 마스크는 빨간 영역으로 식별되고 있는데 대상의 모양을 올바르게 표시하고 있죠 이제 영상을 재생하면 마스크가 움직이는 대상을 추적합니다 좋아 보이지만 프레임 레이트가 낮군요 머신 러닝 파이프라인이 밑에서 실행 중이기 때문입니다 이제 다빈치 리졸브의 새 버전으로 전환할 건데 MPS Graph를 사용하여 매직 마스크 네트워크를 가속하죠 같은 타임라인을 실행했는데 프레임 레이트가 훨씬 빠릅니다 Apple Silicon의 편집 경험이 훨씬 좋아졌죠
MPS Graph만 채택하면 이런 가속을 얻을 수 있습니다 여러분의 프로그램은 어떻게 달라지는지 확인하세요 마무리하죠 이제 여러분은 PyTorch의 GPU 가속을 활용할 수 있고 오픈 소스 프로젝트가 됐습니다 TensorFlow-Metal 플러그인을 이용하여 훈련 워크로드를 가속하는 새로운 방법을 찾을 수 있죠 커스텀 작업이나 분산 학습이 그 예입니다 또한 MPS Graph 프레임워크로 가장 어려운 머신 러닝 과업도 최적화하고 공유 이벤트와 새로운 작업으로 Apple Silicon을 최대한 활용하십시오 Dhruva와 함께 여러분의 프로그램에 적용될 새로운 기능을 기대합니다 시청해 주셔서 감사하고 즐거운 WWDC 보내십시오
-
-
3:44 - Install PyTorch using pip
python -m pip install torch -
3:59 - Create the MPS device
import torch mpsDevice = torch.device("mps" if torch.backends.mps.is_available() else “cpu”) -
4:15 - Convert the model to use the MPS device
import torchvision model = torchvision.models.resnet50() model_mps = model.to(device=mpsDevice) -
4:46 - Run the model
sample_input = torch.randn((32, 3, 254, 254), device=mpsDevice) prediction = model_mps(sample_input) -
9:27 - TensorFlow MetalStream protocol
@protocol TF_MetalStream - (id <MTLCommandBuffer>)currentCommandBuffer; - (dispatch_queue_t)queue; - (void)commit; - (void)commitAndWait; @end -
10:25 - Register a custom operation
// Register the operation REGISTER_OP("ZeroOut") .Input("to_zero: int32") .Output("zeroed: int32") .SetShapeFn([](::tensorflow::shape_inference::InferenceContext* c) { c —> set_output(0, c —> input(0)); return Status::OK(); }); -
10:41 - Implement a custom operation
// Define Compute function void MetalZeroOut::Compute(TF_OpKernelContext *ctx) { // Get input and allocate outputs TF_Tensor* input = nullptr; TF_GetInput(ctx, 0, &input, status); TF_Tensor* output; OP_REQUIRES_OK(ctx, ctx->allocate_output(0, input.shape(), &output)); // Use TF_MetalStream to encode the custom op id<TF_MetalStream> metalStream = (id<TF_MetalStream>)(TF_GetStream(ctx, status)); dispatch_sync(metalStream.queue, ^() { id<MTLCommandBuffer> commandBuffer = metalStream.currentCommandBuffer; // Create encoder and encode GPU kernel [metalStream commit]; } // Delete the TF_Tensors TF_DeleteTensor(input); TF_DeleteTensor(output); } -
11:30 - Import a custom operation
# Import operation in python script for training import tensorflow as tf zero_out_module = tf.load_op_library('./zero_out.so') print(zero_out_module.zero_out([[1, 2], [3, 4]]).numpy()) -
19:29 - Using shared events
// Using shared events let executionDescriptor = MPSGraphExecutionDescriptor() let event = MTLCreateSystemDefaultDevice()!.makeSharedEvent()! executionDescriptor.signal(event, atExecutionEvent: .completed, value: 1) let fetch = computeGraph.runAsync(with: commandQueue1, feeds: [input0Tensor: input0), input1Tensor: input1], targetTensors: [finalTensor], targetOperations: nil, executionDescriptor: executionDescriptor) let executionDescriptor2 = MPSGraphExecutionDescriptor() executionDescriptor2.wait(for: event, value: 1) let fetch2 = postProcessGraph.runAsync(with: commandQueue2, feeds: [input0Tensor: fetch[finalTensor]!, input1Tensor: input1], targetTensors: [finalTensor], targetOperations: nil, executionDescriptor: executionDescriptor2) -
22:03 - Adding an LSTM unit to the graph
let descriptor = MPSGraphLSTMDescriptor() descriptor.inputGateActivation = .sigmoid descriptor.forgetGateActivation = .sigmoid descriptor.cellGateActivation = .tanh descriptor.outputGateActivation = .sigmoid descriptor.activation = .tanh descriptor.bidirectional = false descriptor.training = true let lstm = graph.LSTM(inputTensor, recurrentWeight: recurrentWeightsTensor, inputWeight: weightsTensor, bias: nil, initState: nil, initCell: nil, descriptor: descriptor, name: nil) -
23:35 - Using MaxPooling with return indices API
// Forward pass let descriptor = MPSGraphPooling4DOpDescriptor(kernelSizes: @[1,1,3,3], paddingStyle: .TF_SAME) descriptor.returnIndicesMode = .globalFlatten4D let [poolingTensor, indicesTensor] = graph.maxPooling4DReturnIndices(sourceTensor, descriptor: descriptor, name: nil) // Backward pass let outputShape = graph.shapeOf(destination, name: nil) let gradientTensor = graph.maxPooling4DGradient(gradient: gradientTensor, indices: indicesTensor, outputShape: outputShape, descriptor: descriptor, name: nil) -
24:42 - Use Random Operation
// Declare Philox state tensor let stateTensor = graph.randomPhiloxStateTensor(seed: 2022, name: nil) // Declare RandomOp descriptor let descriptor = MPSGraphRandomOpDescriptor(distribution: .truncatedNormal, dataType: .float32) descriptor.mean = -1.0f descriptor.standardDeviation = 2.5f descriptor.min = descriptor.mean - 2 * descriptor.standardDeviation descriptor.max = descriptor.mean + 2 * descriptor.standardDeviation let [randomTensor, stateTensor] = graph.randomTensor(shapeTensor: shapeTensor descriptor: descriptor, stateTensor: stateTensor, name: nil) -
25:59 - Use the Hamming Distance API
// Code example remember 2D input tensor let primaryTensor = graph.placeholder(shape: @[3,4], dataType: .uint32, name: nil) let secondaryTensor = graph.placeholder(shape: @[1,4], dataType: .uint32, name: nil) // The hamming distance shape will be 3x1 let distance = graph.HammingDistance(primary: primaryTensor, secondary: secondaryTensor, resultDataType: .uint16 name: nil) -
26:21 - Use the expandDims API
// Expand the input tensor dimensions, 4x2 -> 4x1x2 let expandedTensor = graph.expandDims(inputTensor, axis: 1, name: nil) -
26:30 - Use the squeeze API
// Squeeze the input tensor dimensions, 4x1x2 -> 4x2 let squeezedTensor = graph.squeeze(expandedTensor, axis: 1, name: nil) -
26:35 - Use the Split API
// Split the tensor in two, 4x2 -> (4x1, 4x1) let [split1, split2] = graph.split(squeezedTensor, numSplits: 2, axis: 0, name: nil) -
26:39 - Use the Stack API
// Stack the tensor back together, (4x1, 4x1) -> 2x4x1 let stackedTensor = graph.stack([split1, split2], axis: 0, name: nil) -
26:46 - Use the CoordinateAlongAxis API
// Get coordinates along 0-axis, 2x4 let coord = graph.coordinateAlongAxis(axis: 0, shape: @[2, 4], name: nil) -
27:04 - Create a Range1D operation
// 1. Set coordTensor = [0,1,2,3,4,5] along 0 axis let coordTensor = graph.coordinate(alongAxis: 0, withShape: @[6], name: nil) // 2. Multiply by a stride 4 and add an offset 3 let strideTensor = graph.constant(4.0, dataType: .int32) let offsetTensor = graph.constant(3.0, dataType: .int32) let stridedTensor = graph.multiplication(strideTensor, coordTensor, name: nil) let rangeTensor = graph.addition(offsetTensor, stridedTensor, name: nil) // 3. Compute the result = [3, 7, 11, 15, 19, 23] let fetch = graph.runAsync(feeds: [:], targetTensors: [rangeTensor], targetOperations: nil)
-