-
Metal 레이 트레이싱 성능 극대화
Metal 3의 강력한 기능으로 레이 트레이싱 코드를 단순화하고 성능을 향상하는 방법을 알아보세요. 레이 트레이싱 응용 프로그램을 조정할 수 있는 GPU 디버깅 및 프로파일링 도구에 대해 살펴보겠습니다. 또한 가속화 구조에서 프리미티브별 데이터로 교차 테스트 속도를 높이고 셰이더 코드 메모리 액세스 및 우회를 줄이는 방법을 보여드리겠습니다. 그리고 더 빠른 가속화 구조 빌드와 리핏을 구현하여 로드 시간과 프레임별 오버헤드를 줄일 수 있도록 도와드리겠습니다.
리소스
관련 비디오
Tech Talks
WWDC23
WWDC22
WWDC21
WWDC20
-
비디오 검색…
♪ ♪
안녕하세요. Yi입니다 안녕하세요 Dominik입니다 저희는 GPU 소프트웨어 엔지니어예요 오늘 Dominik과 저는 올해 저희가 Metal Ray Tracing API에 추가한 성능 향상과 기능 이야기를 할 거예요 광선 추적 앱 성능 극대화에 도움이 될 겁니다 광선 추적 앱은 장면 주위에서 반사되는 개별 광선을 시뮬레이션하죠 이 앱은 게임과 오프라인 렌더링에서 사실적 반사 그림자, 전역 조명 등을 생성하는 데 사용됩니다 그렇게 하려면 많은 광선을 시뮬레이션해야 해요 성능이 대단히 중요합니다 다행히 Metal에는 모든 Apple 기기에 최적화된 광선 추적 지원 기능이 내장되어 있어요 Metal에서 광선이 어떻게 추적되는지 간단히 살펴보죠 Metal 광선 추적 API는 계산이나 조각 기능 같은 셰이더 기능 내에서 사용할 수 있어요 먼저 장면으로 방출되는 광선을 몇 개 생성해보겠습니다 그리고 섹터 간 개체를 만들어서 이것으로 장면의 광선과 지오메트리 사이의 교점을 확인해보겠습니다 나중에 올해 교점 검색 속도를 높이기 위해 추가한 기능에 대해 설명드리겠습니다 이 프로세스는 가속 구조라는 특별한 데이터 구조에 따라 달라지는데요 이것도 장면에서 지오메트리를 나타내죠 가속 구조에 중점을 둔 몇 가지 새로운 기능과 성능 개선에 대해서도 오늘 이야기할 겁니다 인터섹터는 교차 결과 개체를 반환하는데 이것이 닿은 각 광선의 프리미티브를 설명하죠 교차 결과는 출력 이미지에 쓸 색상 생성에 사용됩니다 또한 프로세스를 다시 통과하는 다른 광선을 생성하는 데도 사용됩니다 우리는 이 프로세스를 장면 주변에서 반사되는 광선을 시뮬레이션하고 싶은 만큼 반복할 수 있죠 Metal 광선 추적 API의 기본에 대해 자세히 알고 싶다면 앞에서 다룬 WWDC 장을 살펴보기 바랍니다 Metal 광선 추적 API는 WWDC20에서 처음 소개했고 작년에는 모션 블러 지원 등 새 기능을 도입했습니다 오늘은 세 가지에 대해 이야기하려고 해요 먼저 앱에서 광선 추적 성능을 향상시킬 수 있는 새로운 기능에 대해 설명하고
다음으로 가속 구조 API에 추가된 개선 사항과 기능에 대해 이야기하겠습니다
마지막으로 Dominik이 광선 추적용 GPU 도구의 개선 사항에 대해 알려드립니다 올해 우리는 광선 추적 성능 개선과 코드 단순화를 목표로 세 가지 새 기능을 추가했습니다 프리미티브별 데이터 교차함수표에서 버퍼 검색기능 그리고 간접 명령 버퍼에서 광선 추적을 지원하는 기능입니다
프리미티브별 데이터부터 보죠 앱에는 보통 장면의 기본 요소와 관련된 데이터가 있습니다 이를테면 정점 색상, 법선 텍스처 좌표 같은 것이죠
금년에 우리는 각 프리미티브에 대한 소량의 데이터를 가속 구조에 직접 저장하는 기능을 추가했습니다 이 데이터는 보다 적은 메모리 간접 참조 및 캐시 누락으로 액세스할 수 있으므로 성능이 향상됩니다 또 일반적으로 프리미티브와 관련된 데이터 조회 시 필요한 복잡한 보조 데이터 구조를 저장할 필요성을 줄여줍니다
예를 볼까요
알파 테스트는 삼각형 수를 늘리지 않고 투명 기하학에 복잡성을 추가하는 데 사용되는 기술입니다 이 기술에서 삼각형에 매핑된 텍스처의 알파 채널은 광선이 삼각형에 닿아야 하는지 계속 가야 하는지 결정하는 데
사용되죠. 그러려면 삼각형에 광선이 닿을 때 사용자 정의 교차 함수를 호출하도록 교차점을 구성해야 합니다
궁극적인 목표는 삼각형과 관련된 텍스처에서 샘플을 얻고 알파 값으로 광선이 프리미티브를 계속 통과할 수 있는지 테스트하는 것입니다 그러려면 두 가지 정보가 필요하죠 텍스처 개체와 UV 좌표입니다 알파 테스트를 일반적으로 실행할 때 이 정보를 얻으려면 Metal 장치 메모리의 여러 중간 버퍼에 액세스해야 합니다.
먼저 어떤 종류의 재료 구조에 프리미티브와 관련된 텍스처를 저장합니다
여러 재료가 버퍼에 들어갈 겁니다 실제로는 모든 프리미티브의 재료 구조를 저장할 수는 없어요 프리미티브가 상당히 크고 많을 수 있기 때문이죠 대신 각 프리미티브의 재료 ID만 버퍼에 저장하고 이를 사용하여 재료를 조회하면 좋겠죠 다음에 UV를 계산하기 위해 다른 버퍼에서 각 정점에 대한 UV를 로드하고 보간해야 합니다 마지막으로 인스턴스화된 지오메트리를 사용한다고 할 때 각 인스턴스에 고유한 재료와 UV 매핑이 있으면 좋겠죠 그러기 위해 UV와 재료 ID 버퍼 포인터를 인스턴스 데이터 버퍼에 저장할 겁니다 함수에 다른 수준의 간접 참조를 추가하면서요 이 방식을 쓰려면 꽤나 복잡한 버퍼 설정을 유지해야 하고 필요한 데이터를 얻기 위해 많은 간접 참조가 필요합니다 캐시 누락도 발생할 수 있는데 그러면 성능에 부정적인 영향을 미칠 수 있죠 이 다이어그램을 작성하는 데 필요한 코드를 살펴보겠습니다 그런 다음 프리미티브별 데이터를 사용해 단순화하는 방법을 단계별로 보여드리죠 이것은 알파 테스트 교차 기능의 기본 실행입니다 이 함수는 광선이 알파 테스트를 거친 삼각형에 닿을 때 호출되죠 함수는 메모리에서 인스턴스 데이터를 로드하면 시작됩니다 이게 버퍼인데 인스턴스에서 사용하는 UV와 재료 버퍼에 대한 포인터가 들어있죠 그 다음에 함수가 UV 버퍼에서 UV 좌표를 로드하고 보간합니다 이건 다른 메모리 로드입니다 그 후 함수는 다른 버퍼에서 재료 색인을 로드합니다 끝으로 이 함수가 재료를 로드하고 해당 텍스처를 샘플링하죠 이 시점에서 함수는 필요한 알파 값을 가지므로 임계값과 비교할 수 있어요 이제 프리미티브별 데이터를 사용해 이 코드를 단순화하고 성능을 향상시키는 방법을 보여 드리겠습니다 다중 간접 참조 레이어로 복잡하게 설정된 버퍼를 사용하는 대신 각 프리미티브에 대해 교차 함수에 필요한 데이터만 가속 구조에 직접 저장할 수 있습니다 이 예에서 각 프리미티브에 대한 텍스처와 UV 좌표가 있는 구조체를 만들 수 있습니다 가속 구조를 만들 때 이 데이터를 주면 교차 함수는 광선이 프리미티브에 닿을 때 해당 데이터에 대한 포인터를 수신하기만 하면 됩니다 프리미티브별 데이터에 뭐든 다 저장할 수 있지만 크기를 작게 유지하면 최상의 성능을 얻기 쉽죠 교차 함수에 대한 입력부터 시작하겠습니다 이것 모두에 액세스하면 실행할 때 많은 유연성을 얻을 수 있지만 GPU의 레지스터 사용량도 증가할 수 있습니다 모든 버퍼 대신 프리미티브별 데이터만 사용하면 프리미티브 데이터 포인터에만 액세스하면 되죠 이것은 가속 구조에 직접 저장하는 데이터입니다 이 경우 각 프리미티브에는 모든 정점에 대한 자체 텍스처 개체와 UV가 있습니다 다음은 전역 재료 버퍼와 인스턴스 데이터 버퍼 로드입니다 둘 다 필요 없어요 프리미티브별 데이터 포인터에서 한 번만 로드하면 됩니다 이 기능에 유일하게 필요한 장치 메모리 액세스죠 다음은 UV입니다 인스턴스 데이터에서 검색된 포인터를 역참조하는 대신 프리미티브별 데이터 구조 내 데이터에만 액세스하면 돼요 코드 변경은 복잡하지만 성능에 중요합니다 추가 메모리 로드가 없으니까요 마지막으로 재료 특성이 있습니다 재료에서 필요한 부분은 텍스처뿐이라서 프리미티브의 텍스처를 프리미티브별 데이터 구조에서 직접 인코딩할 수 있습니다 더는 재료 및 재료 인덱스 버퍼에 액세스할 필요가 없다는 얘기죠 추가 메모리 역참조 비용을 들이지 않고도 텍스처를 직접 사용할 수 있습니다 따라서 프리미티브별 데이터를 사용할 때 교차 코드가 얼마나 간단해지는지 알 수 있어요 고비용의 메모리 액세스는 모두 프리미티브 데이터 포인터에서 단 한 번의 로드로 대체됩니다 무엇보다도 코드가 훨씬 간단하고 따라하기 쉽습니다 다음으로 프리미티브 데이터를 가속 구조에 저장하는 방법을 보여 드리겠습니다 교차 기능에서 액세스하려면 이 작업부터 해야 돼요 가속 구조 지오메트리 설명자에서 몇 가지 필드를 설정해야 합니다 먼저 데이터가 저장되는 Metal 버퍼를 설정합니다 다음에 각 프리미티브에 저장될 데이터의 크기를 지정하세요 데이터가 버퍼에 꽉 채워지지 않았거나 버퍼의 시작 부분에서 시작하지 않는 경우 진행 속도와 오프셋을 지정할 수도 있습니다 아니면 이 값의 기본값은 0이므로 설정할 필요가 없어요 교차 함수에서 기본 데이터를 사용하는 방법을 이미 보았습니다 포인터로 함수에 간단히 전달되죠 뿐만 아니라 필요할 때마다 이 데이터에 액세스할 수 있어요 여기에는 교차점에서 반환된 최종 교차 결과가 포함됩니다 교차 쿼리를 사용하는 경우 후보 교차와 확정 교차 모두 프리미티브 데이터를 사용할 수 있어요 즉, 교차 테스트 외에 음영 처리에도 프리미티브 데이터를 사용할 수 있죠 프리미티브별 데이터는 메모리 액세스와 간접 참조의 수를 줄여 교차 코드와 음영 코드 성능을 향상시킬 수 있습니다 사실, 자체 테스트 앱 중 하나에서 프리미티브 데이터를 사용하면 성능이 10~16% 향상된다는 걸 알아냈습니다 여러분도 얼른 해 보시고 성능과 코드 품질이 어떻게 좋아지는지 확인할 수 있으면 좋겠네요 올해 우리는 Metal 셰이딩 언어에 편리한 기능을 하나 더 추가했는데요. 광선 추적 커널을 단순화하는 데 좋은 기능이죠 앱에서는 교차 기능과 주 광선 추적 커널에 동일한 바인딩 세트를 전달하는 경우가 많습니다 이를테면 저희 광선 추적 샘플 코드는 교차 함수를 사용하여 구를 렌더링합니다 이 교차 함수는 각 구에 대한 정보가 있는 리소스 버퍼에 액세스합니다 이 버퍼를 교차 함수에 전달하기 위해 앱에서 버퍼를 교차 함수 테이블에 바인딩합니다 그런데 주 광선 추적 커널은 리소스 버퍼에도 액세스해야 하므로 앱은 그곳 버퍼도 바인딩해야죠 올해는 Metal 세이딩 언어를 사용해 교차 함수표에 바인딩된 버퍼에 액세스할 수 있습니다 이 새 기능을 사용하면 커널용 버퍼를 바인딩하는 수고를 하지 않아도 교차 함수표에서 직접 액세스할 수 있습니다 교차 함수표에서 포인터 유형을 제공하여 겟 버퍼 방식을 호출하면 할 수 있습니다 기능 유형별로 표시되는 함수표에 액세스할 수도 있어요 간접 명령 버퍼를 사용해 GPU 작업을 GPU에서 독립적으로 인코딩하면 GPU 기반 파이프라인 기본 요소를 나타낼 수 있습니다 간접 명령 버퍼 및 GPU 기반 렌더링에 대한 자세한 내용은 WWDC 2019의 “Metal로 하는 모던 렌더링” 세션을 참조하세요 간접 명령 버퍼에서 광선 추적 지원 활성화는 쉽습니다 설명자에 supportRayTracing 플래그를 설정하기만 하면 됩니다 간접 명령 버퍼가 그래픽을 전달하고 함수를 계산하므로 평소와 같이 해당 함수에서 광선 추적을 사용할 수 있어요 이상 앱에서 광선 추적 성능을 향상시키기 위해 올해 추가한 새 기능을 모두 요약했습니다 다음에는 가속 구조에 대해 이야기해보겠습니다 몇 가지 성능이 개선되었고 가속 구조 구축에 중점을 둔 기능이 추가되었습니다 그 용도가 무엇인지 간단히 살펴보도록 하죠 가속 구조는 광선 추적 프로세스를 가속화하는 데이터 구조입니다 공간을 재귀적으로 분할하여 가속화하므로 어떤 삼각형이 광선과 교차하게 될지 빠르게 찾을 수 있습니다 복잡한 장면을 구축할 수 있도록 Metal은 두 가지 유형의 가속 구조를 지원합니다 프리미티브 및 인스턴스 가속 구조입니다 지오메트리의 개별 조각은 프리미티브 가속 구조를 사용하여 표현됩니다 평면이나 정육면체처럼 단순한 것일 수도 있고 구나 삼각형 메쉬와 같이 복잡한 것일 수도 있습니다 인스턴스 가속 구조를 사용하면 보다 복잡한 장면을 만들 수 있어요 인스턴스 가속 구조는 프리미티브 가속 구조의 사본을 생성합니다 먼저 장면의 각 개체에 대한 변환 행렬을 정의합니다 그런 다음 변환 행렬과 프리미티브 가속 구조의 배열을 사용하여 인스턴스 가속 구조를 구축합니다 이것이 가속 구조를 사용한 정적 장면 구축 방법입니다 다음으로 게임 같은 앱에서 가속 구조가 얼마나 역동적으로 사용되는지 보겠습니다
처음부터 시작해보죠 게임을 처음 론칭하거나 새 레벨을 로딩할 때 해야 할 몇 가지 작업이 있습니다 모델과 텍스처를 로딩하는 등 일반적인 작업도 포함되죠 사용할 모든 모델에 대해 광선 추적으로 프리미티브 가속 구조를 구축해야 합니다 로딩 시간에 최대한 많은 프리미티브 가속 구조를 구축해야 메인 렌더링 루프에서 시간을 절약할 수 있어요 이들 개체를 필요 시 장면에 추가하거나 제거하려면 인스턴스 가속 구조를 사용하면 됩니다 앱에서 로딩이 끝나면 메인 루프로 들어갑니다 모든 프레임에서 래스터화, 광선 추적, 후처리를 조합하여 장면을 렌더링합니다 그러나 게임은 매우 역동적이므로 일부 가속 구조를 업데이트해야 할 겁니다 주로 몇몇 변형된 모델 또는 스킨을 적용한 애니메이션 모델을 다시 맞추는 일이죠 전체를 재구성하기보다 기존 가속 구조를 다시 맞추는 것이 훨씬 빠르므로 이걸 추천합니다 인스턴스 가속 구조도 완전히 재구성해야 돼요 왜냐하면 개체가 이전 프레임에 추가되었거나 제거되었을 수도 있고 많이 이동했을 수도 있으니까요 이 경우 전체 재구성도 괜찮아요 인스턴스 가속 구조가 하나뿐이고 개체도 기껏해야 몇 천 개뿐이니까요 올해 우리는 이 모든 경우에 대해 성능을 향상시켰습니다 첫째, 가속 구조 구축이 Apple Silicon에서 최대 2.3배 빨라졌어요 둘째, 다시 맞추기도 최대 38% 빨라졌습니다
즉, 로딩 시간과 프레임별 오버헤드가 모두 줄었어요 그리고 더 좋아지고 있어요 일부 앱에서는 소규모 가속 구조를 수백, 수천 개 구축합니다 이들 소규모 빌드는 개별적으로 GPU를 채울 만큼 작업을 충분히 하지 않으므로 장기 GPU 사용률이 낮아요 따라서 Apple Silicon에서 가능할 때마다 여러 빌드가 자동으로 병렬로 수행됩니다 그 결과 빌드가 최대 2.8배 빨라지는 거죠 병렬로 작업하니까 따라서 로딩 시간도 줄어들죠 이건 빌드에만 해당되는 이야기가 아니에요 압축과 다시 맞추기 등 모든 가속 구조 작업에 해당되죠 따라서 프레임별 오버헤드도 줄어듭니다 이 최적화로 인한 장점을 즐기기 위해서는 몇 가지 지침을 따라야 합니다 여기 가속 구조 배열을 구축하는 예가 있습니다 가속 구조를 병렬로 구축하려면 많은 빌드에 반드시 같은 가속 구조 명령 인코더를 사용해야 합니다 같은 스크래치 버퍼를 쓰는 빌드는 병렬로 실행할 수 없어요 따라서 각 빌드에 동일한 스크래치 버퍼를 사용하는 대신 스크래치 버퍼의 작은 풀을 통과할 수 있으면 좋겠죠
이 모든 것이 저희가 가속 구조 구축에서 향상시킨 성능입니다 그 밖에 가속 구조 구축을 보다 쉽고 효율적으로 하기 위해 세 가지 새 기능을 추가했어요
추가 정점 형식 변환 행렬 그리고 힙에서 가속 구조 할당입니다
정점 형식부터 시작하겠습니다 일반적인 성능 최적화는 정점 데이터에 양자화 또는 축소된 정밀도 형식을 사용하는것이며 그 결과 메모리 사용량이 줄어듭니다 올해에는 다양한 정점 형식에서 가속 구조를 구축할 수 있습니다 여기에는 반정밀도 부동 소수점 형식 평면 기하 도형에 대한 두 가지 구성 요소 정점 형식 그리고 모든 정규화된 일반 정수 형식이 있습니다 이전에는 가속 구조에 세 가지 구성요소, 전체 정밀도 부동 소수점 정점 데이터가 필요했습니다 이 예에서는 앱이 절반 정밀도 정점 형식의 정점 데이터를 사용하죠 가속 구조를 구축하려면 이 데이터의 압축을 풀고 임시 버퍼에 복사해야 해요 새 정점 형식 기능으로 이제 가속 구조 빌드에서 지원되는 모든 형식의 정점 데이터를 사용할 수 있으므로 임시 사본을 만들 필요가 없어요 정점 형식 설정이 이보다 더 간단할 수는 없죠 지오메트리 설명자에 속성을 설정하기만 하면 됩니다 다음에는 변환 행렬에 대해 이야기해보겠습니다 이 기능은 새로운 정점 형식을 보완합니다 가속 구조를 구축하기 전에 정점 데이터를 미리 변환할 수 있도록 말이죠 이를테면 정규화된 형식으로 저장된 복잡한 메쉬의 압축을 푸는 데 사용할 수 있겠죠 이 장면에서 Red Panda 모델을 생각해 봅시다 압축된 형식 중 하나를 사용하도록 지오메트리를 정규화하려면 메쉬를 가져와 바운드를 계산한 다음 0~1 범위로 크기를 조정합니다 그런 다음 정규화된 정수 정점 형식 중 하나를 사용하여 메쉬를 저장하면 디스크와 메모리에서 차지하는 공간을 줄일 수 있죠 런타임에 각 정점을 최종 위치에 맞게 크기를 조정하고 오프셋하는 행렬을 제공하세요 해당 행렬을 적용하면 원래 모델이 검색됩니다 이제 변환 행렬을 전달하는 가속 구조 설정 방법에 대해 알아보겠습니다 먼저 변환 버퍼부터 만들어야 해요 한 가지 방법은 스케일과 오프셋 변환 행렬이 있는 MTLPackedFloat4x3 개체를 생성하는 것입니다 그 다음에 Metal Buffer를 만들죠 행렬을 담을 수 있을 만큼 크게 마지막으로 행렬을 버퍼에 복사합니다 다음에 가속 구조를 설정합니다 먼저 삼각형 기하학 설명자를 만듭니다 그런 다음 변환 Matrix Buffer를 지정합니다 마지막에 Buffer Offset이죠 변환 행렬을 설정할 때 이것만 하면 됩니다 이런 행렬은 간단한 가속 구조를 결합하는 데 사용하면 광선 추적 성능을 향상시킬 수 있습니다 예시 장면을 볼까요? 여기에서 상자와 구체는 모두 비교적 단순한 메쉬입니다 장면 앞부분에서 이 그룹의 가속 구조를 최적화할 기회입니다 인스턴스 가속 구조에 초점을 맞추어 광선이 닿는 인스턴스마다 오버헤드가 있어요 광선을 변환한 후 인스턴스에서 프리미티브 가속 구조로 전환하는 데 비용이 듭니다 중복되는 인스턴스에서는 더 자주 발생하죠 인스턴스 수를 줄이려면 상자와 구가 다 있는 단일 프리미티브 가속 구조를 생성합니다 그러기 위해 각 개체마다 변환 행렬이 있는 지오메트리 설명자를 생성합니다 생성되는 프리미티브 인스턴스 가속 구조에 있는 단일 인스턴스이고 그 안에 상자와 구가 들어있죠 이렇게 하면 성능이 더 좋은 가속 구조가 나옵니다 코드에서 설정하는 방법을 보죠
구의 지오메트리를 정의하는 설명자부터 시작합니다 다음에 프리미티브 가속 구조에 대해 평소와 같이 정점 버퍼 인덱스 버퍼 및 기타 속성을 설정합니다 차이점은 변환 버퍼도 지정한다는 점입니다 구 사본에 사용된 변환 행렬이 있는 변환 버퍼죠
상자의 경우 정점 버퍼와 인덱스 버퍼를 공유하는 여러 지오메트리 설명자를 사용합니다 각 사본에 다른 변환 버퍼를 지정하기만 하면 되죠 끝으로 프리미티브 가속 구조의 설명자를 생성할 때 모든 지오메트리 설명자를 추가합니다 이렇게 하면 ID 변환을 사용하여 장면에 삽입할 수 있는 프리미티브 가속 구조가 생성됩니다 이 프리미티브 가속 구조는 별도의 가속 구조보다 구축하는 데 드는 시간이 짧고 교차 속도도 빠릅니다
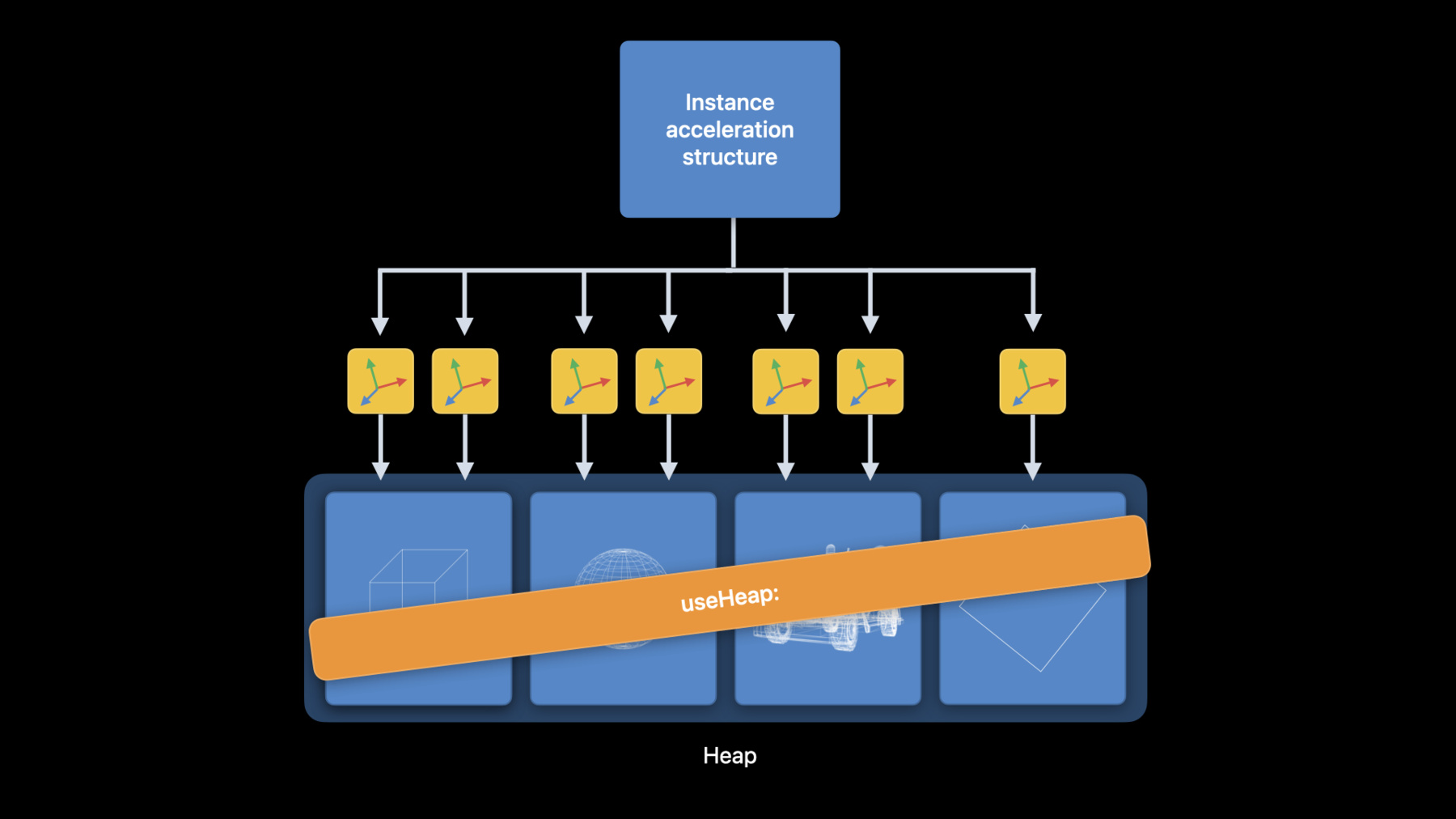
끝으로 가속 구조의 힙 할당은 당사에 가장 많이 요청된 기능 가운데 한 가지입니다 이 기능을 사용하면 이제 가속 구조 할당을 더 쉽게 제어할 수 있습니다 또한 할당 사이에 힙 메모리를 재사용할 수 있으므로 값비싼 버퍼 할당을 안 해도 되죠 힙도 useResource: 인스턴스 가속 구조 사용시 방식 호출을 줄이므로 성능 개선에 도움이 됩니다 예제 장면으로 돌아가서 인스턴스 가속 구조는 프리미티브 가속 구조를 간접적으로 참조합니다 즉, 명령 인코더와 함께 인스턴스 가속 구조를 사용하고자 할 때마다 useResource: 각 프리미티브 가속 구조용 방식 호출을 해야 합니다 큰 장면의 경우 이 방법은 useResource:인스턴스 가속 구조를 사용할 때마다 호출을 수천 번 해야 합니다 useResource: 호출이 너무 많다는 것을 알면 API 호출 수를 줄이기 위해 useResources:를 호출할 수 있지만 그래도 가속 구조의 배열은 유지해야 하고 Metal은 계속 배열을 돌아야 합니다 이러는 대신 이들 모든 프리미티브 가속 구조를 동일한 힙에서 할당할 수 있어요 인스턴스 가속 구조를 사용하고 싶다면 useHeap: 모든 프리미티브 가속 구조 참조 방식을 한 번만 호출하면 됩니다 useResource: 호출을 useHeap: 단일 호출로 교체했을 뿐인데 한 앱에서 성능이 향상된 것을 확인했습니다 힙에서 가속 구조 할당하는 방법을 살펴보죠 가속 구조 설명자를 입력으로 사용하는 힙에서 방식을 호출하면 가속 구조를 직접 할당할 수 있어요 설명자를 사용하여 할당하지 않는 경우 Metal 기기가 힙에서 가속 구조를 할당하기 위해 필요한 크기 및 정렬을 결정합니다 Metal 기기에 설명자 또는 가속 구조 크기를 주면 이 정보를 얻을 수 있습니다 최종 크기가 정해지면 힙에서 가속 구조를 할당할 수 있습니다 힙 사용 시 기억해야 할 사항이 몇 가지 있는데요 첫째 useHeap: 호출은 광선 추적 진행 기간 동안 모든 가속 구조가 힙에 상주하도록 합니다 둘째, 기본적으로 Metal은 힙에서 할당한 리소스를 추적하지 않습니다 리소스 위험 추적을 선택하거나 자체 동기화를 수동으로 관리해야 합니다 명령 인코더 간 동기화에는 MTLFences를 사용하고 명령 버퍼 간 동기화에는 MTLEvents를 사용하면 되죠 이 둘은 올해 Metal 광선 추적 API에 새로 탑재된 기능이자 향상된 성능입니다 다음으로 Dominik이 Xcode의 Metal 도구 개선 사항에 대해 알려드릴 겁니다 이는 광선 추적 앱을 개발할 때 생산성을 극대화해 줄 겁니다 Yi, 고마워요 Xcode 14형의 Metal 도구에는 많은 개선 사항이 있지만 여기서는 몇 가지만 강조하고 싶은데요 특히 광선 추적 앱 개발에 유용한 사항입니다 Metal 디버거부터 시작해서 Acceleration Structure Viewer Shader Profiler 그리고 Shader Debugger의 개선 사항에 대해 말씀드리죠 그런 다음 실시간 Shader Validation으로 마무리하겠습니다
Acceleration Structure Viewer부터 살펴보겠습니다 Metal Debugger의 Acceleration Structure Viewer를 사용하면 가속 구조를 구성하는 모든 메쉬의 모든 형상과 인스턴스를 매우 자세하게 검사할 수 있습니다
Xcode 14형은 이제 프리미티브 또는 인스턴스 모션이 있는 디버깅 가속 구조와 프리미티브별 데이터 검사기로 프리미티브를 시각화하기 위한 새로운 하이라이트 모드를 지원합니다 어떻게 작동하는지 볼까요 모션이 있는 가속 구조를 사용한다면 이제 아래쪽 막대에 스크러버가 있으므로 다양한 시점에서 가속 구조를 볼 수 있습니다 스크러버 오른쪽에 “재생” 버튼이 있어요 루프에서 애니메이션을 앞뒤로 재생할 때 사용합니다 이제 가속 구조에서 개별 프리미티브를 어떻게 검사하는지 보여 드리겠습니다 프리미티브별 데이터 API를 사용할 때 특히 유용하죠 그래서 이제 이걸 위한 새 하이라이트 모드가 생겼어요 프리미티브 하이라이트 모드로 어떤 프리미티브
데이터에도 액세스하여 상세 검사를 할 프리미티브를
선택할 수 있어요 왼쪽 측면 막대에는 데이터 줄
옆에 화살표가 있는데 클릭하면 프리미티브에 해당하는 테이터를 표시한 팝오버가 나타납니다 가속 구조 뷰어에 추가된 이들 기능으로 전체를 액세스할 수 있습니다 각 프리미티브부터 가속 구조를 구성하는 모든 구성 요소까지 다음으로 Shader Profiler의 개선 사항을 소개하죠 Shader Profiler로는 셰이더 성능을 살펴볼 수 있습니다 파이프라인당 실행 타이밍 비용을 제공하면서 말이죠 Apple GPU에서는 명령 범주에 분산된 라인당 실행 비용을 보여주면서 소스 레벨에서 더 나은 세분성을 제공합니다 Xcode 14형에서 업테이트된 프로파일링 GPU 캡처는 교차 기능, 가시 적기능 및 동적 라이브러리를 지원합니다
이것은 교차 기능을 사용하는 광선 추적 커넬입니다 교차 기능 내부에 나타난 라인당 프로파일링 결과가 보이시죠? 여기에는 비용에 기여하는 지침 범주의 분석이 포함되어 있습니다
가시적 기능 프로파일링도 같은 방식으로 작동합니다
마찬가지로 이제 링크된 동적 라이브러리에서 셰이더 코드에 대한 상세한 프로파일링 정보를 얻을 수 있습니다 이들 추가 기능으로 이제 파이프라인의 성능을 완전히 분석할 수 있습니다 코드의 각 라인까지 말이죠
Shader Debugger로 옮겨 가죠 Shader Debugger는 셰이더 코드의 정확성을 디버깅하기 위한 독특하고 대단히 생산적인 워크플로를 제공합니다 Shader Profiler와 마찬가지로 링크된 기능 및 동적 라이브러리의 디버깅을 가능하게 하는 지원도 확장되었습니다 이것은 광선 추적 커널인데요 보이는 함수표를 통해 전달된 링크된 보이는 함수를 호출합니다
이제 커넬의 실행 과정을 보이는 기능 코드까지 줄곧 추적할 수 있으므로 코드가 예상대로 작동하는지 확인할 수 있습니다
다시 말하지만 동적 라이브러리 디버깅에도 똑같이 적용됩니다 또한 파이프라인에 링크된 실행된 모든 동적 라이브러리로 건너뛰거나 나올 수도 있어요 이들 추가 기능으로 이제 파이프라인에 링크된 함수와 라이브러리의 셰이더 실행을 전체적으로 파악할 수 있습니다
Shader Debugger를 캡처하고 건너뛰기 전에 런타임에 Shader Validation을 활성화하는 것이 좋습니다
셰이더 유효성 검사는 경계 밖 메모리 액세스, 제로 텍스처 읽기 같은 문제를 포착하여 GPU의 런타임 오류를 진단하는 좋은 방법입니다 Xcode에서 Shader Validation를 활성화하려면 “Edit Scheme” 대화로 가서 “Run” 활동을 선택하고 “Diagnostics” 탭 아래 있는 “Shader Validation” 체크박스에 표시만 하면 준비 완료입니다 Metal 3형에는 정의되지 않은 동작으로 나타날 문제를 빠르게 찾아낼 수 있는 스택 오버플로 감지 기능이 추가되었습니다 Metal 셰이더의 함수 스택과 스택 오버플로 문제에 대해 짧게 설명하겠습니다 호출 스택은 장치 메모리 영역인데요 Metal에서는 셰이더 함수에 사용된 로컬 데이터 값을 여기 저장하죠 호출된 함수가 컴파일 시간에 알려지지 않은 경우 Metal은 스택에 필요한 메모리 양을 추정할 때 도움이 필요합니다 컴파일 시간에 알려지지 않은 함수 호출의 예로 광선 추적 교차 함수가 있습니다 사용자 정의 교차 함수를 사용하는 경우 공간을 할당하려면 최대 호출 스택 깊이를 1로 설정합니다 이것은 기본값이므로 더는 할 일이 없어요 그러나 함수표를 사용하여 가시 함수를 호출하는 경우 이는 컴파일 시간에 알 수 없는 함수 호출의 또 다른 예입니다 이런 호출을 이 예와 같이 교차 함수에서 할 경우 호출 스택의 깊이는 두 레벨이 됩니다
또 다른 예는 동적 라이브러리 호출과 함수 포인터를 사용하여 로컬 함수를 호출하는 것입니다 이 예에서 호출 스택에는 다양한 유형의 함수를 중첩 호출하는 4가지 레벨이 있는데 이들 함수는 셰이더가 컴파일될 때 확인할 수 없습니다 적절한 양의 메모리를 할당하도록 Metal을 올바르게 구성하려면 최대 호출 스택 깊이를 4로 직접 지정해야 합니다 프로그램에 대한 최대 호출 스택 깊이 값이 너무 낮게 설정되면 스택 오버플로가 발생하여 정의되지 않은 동작이 발생할 수 있으니 이 점 유념해야 합니다 그러나 Shader Validation을 활성화한 상태에서 실행하는 경우 이러한 상황이 조기에 포착되고 스택 오버플로가 발생한 위치가 Xcode에 표시됩니다 그러면 셰이더 코드를 수정하거나 파이프라인 설명자에서 최대 호출 스택 깊이를 조정하면 되죠 Xcode 14형의 Metal 도구에서 새로 개선된 사항으로 광선 추적 앱의 성능과 정확성을 보다 완전하게 확인하고 파악할 수 있게 되었습니다 디버깅 및 프로파일링에 Metal 도구를 최대한 활용하는 방법에 대해서는 다른 장을 확인하세요
이 장은 모두 앱에서 Metal 추적 성능을 최대화하는 방법에 관한 것이었습니다 프리미티브별 데이터와 같은 새로운 기능으로 더 많은 성능을 끌어내고 코드를 단순화하는 방법에 대해 알아보았습니다 가속 구조 구축을 그 어느 때보다 빠르고 편리하게 해낼 수 있는 최적화 기술과 기능도 살펴보았습니다 마지막으로 개발하는 동안 더욱 정확한 파악을 제공할 Xcode 14형 Metal 도구의 새로운 개선 사항도 모두 다루었습니다 시청해주셔서 감사합니다
-
-
4:04 - Alpha testing with intersection functions
float alpha = texture.sample(sampler, UV).w; return alpha >= 0.5f; -
5:46 - Alpha testing intersection function
[[intersection(triangle, raytracing::triangle_data, raytracing::instancing)]] bool alphaTestIntersection(float2 coordinates [[barycentric_coord]], unsigned int primitiveIndex [[primitive_id]], unsigned int instanceIndex [[instance_id]], device GlobalData *globalData [[buffer(1)]], device InstanceData *instanceData [[buffer(0)]]) { device Material *materials = globalData->materials; InstanceData instance = instanceData[instanceIndex]; float2 UV = calculateSamplingCoords(coordinates, instance.uvs[primitiveIndex * 3 + 0], instance.uvs[primitiveIndex * 3 + 1], instance.uvs[primitiveIndex * 3 + 2]); int materialIndex = instance.materialIndices[primitiveIndex]; float alpha = materials[materialIndex].texture.sample(sam, UV).w; return alpha >= 0.5f; } -
6:48 - Primitive Data
struct PrimitiveData { texture2d<float> texture; float2 uvs[3]; }; -
7:08 - Alpha testing intersection function using per-primitive data
// Alpha testing intersection function [[intersection(triangle, raytracing::triangle_data, raytracing::instancing)]] bool alphaTestIntersection(float2 coordinates [[barycentric_coord]], const device PrimitiveData *primitiveData [[primitive_data]]) { PrimitiveData ppd = *primitiveData; float2 UV = calculateSamplingCoords(coordinates, ppd.uvs[0], ppd.uvs[1], ppd.uvs[2]); float alpha = ppd.texture.sample(sam, UV).w; return alpha >= 0.5f; } -
8:54 - Setting up per-primitive data
geometryDescriptor.primitiveDataBuffer = primitiveDataBuffer geometryDescriptor.primitiveDataElementSize = MemoryLayout<PrimitiveData>.size geometryDescriptor.primitiveDataStride = MemoryLayout<PrimitiveData>.stride geometryDescriptor.primitiveDataBufferOffset = primitiveDataOffset -
9:18 - Using per-primitive data
// Intersection function argument: const device void *primitiveData [[primitive_data]] // Intersection result: primitiveData = intersection.primitive_data; // Intersection query: primitiveData = query.get_candidate_primitive_data(); primitiveData = query.get_committed_primitive_data(); -
11:08 - Buffers from intersection function tables
device int *buffer = intersectionFunctionTable.get_buffer<device int *>(index); visible_function_table<uint(uint)> table = intersectionFunctionTable.get_visible_function_table<uint(uint)>(index); uint result = table[0](parameter); -
11:36 - Ray tracing from indirect command buffers
let icbDescriptor = MTLIndirectCommandBufferDescriptor() icbDescriptor.supportRayTracing = true -
15:43 - Parallel acceleration structure builds
for (index, accelerationStructure) in accelerationStructures.enumerated() { encoder.build(accelerationStructure: accelerationStructure, descriptor: descriptors[index], scratchBuffer: scratchBuffers[index % numScratchBuffers], scratchBufferOffset: 0) } -
17:28 - Setting vertex formats
let geometryDescriptor = MTLAccelerationStructureTriangleGeometryDescriptor() geometryDescriptor.vertexFormat = .uint1010102Normalized -
18:29 - Creating transformation matrix buffer
var scaleTransform = MTLPackedFloat4x3(columns: ( MTLPackedFloat3Make( scale.x, 0.0, 0.0), MTLPackedFloat3Make( 0.0, scale.y, 0.0), MTLPackedFloat3Make( 0.0, 0.0, scale.z), MTLPackedFloat3Make(offset.x, offset.y, offset.z)) let transformBuffer = device.makeBuffer(length: MemoryLayout<MTLPackedFloat4x3>.size, options: .storageModeShared)! transformBuffer.contents().copyMemory(from: &scaleTransform, byteCount: MemoryLayout<MTLPackedFloat4x3>.size) -
18:51 - Setting transformation matrix buffer on geometry descriptor
let geometryDescriptor = MTLAccelerationStructureTriangleGeometryDescriptor() geometryDescriptor.transformationMatrixBuffer = transformBuffer geometryDescriptor.transformationMatrixBufferOffset = 0 -
20:12 - Merging instances using transformation matrices
let sphereGeometryDescriptor = MTLAccelerationStructureTriangleGeometryDescriptor() sphereGeometryDescriptor.vertexBuffer = sphereVertexBuffer sphereGeometryDescriptor.indexBuffer = sphereIndexBuffer sphereGeometryDescriptor.transformationMatrixBuffer = sphereTransformBuffer let redBoxGeometryDescriptor = MTLAccelerationStructureTriangleGeometryDescriptor() redBoxGeometryDescriptor.vertexBuffer = boxVertexBuffer redBoxGeometryDescriptor.indexBuffer = boxIndexBuffer redBoxGeometryDescriptor.transformationMatrixBuffer = redBoxTransformBuffer let blueBoxGeometryDescriptor = MTLAccelerationStructureTriangleGeometryDescriptor() blueBoxGeometryDescriptor.vertexBuffer = boxVertexBuffer blueBoxGeometryDescriptor.indexBuffer = boxIndexBuffer blueBoxGeometryDescriptor.transformationMatrixBuffer = blueBoxTransformBuffer let primitiveASDescriptor = MTLPrimitiveAccelerationStructureDescriptor() primitiveASDescriptor.geometryDescriptors = [sphereGeometryDescriptor, redBoxGeometryDescriptor, blueBoxGeometryDescriptor] -
22:33 - Heap acceleration structure allocation
let heap = device.makeHeap(descriptor: heapDescriptor)! let accelerationStructure = heap.makeAccelerationStructure(descriptor: descriptor) let sizeAndAlign = device.heapAccelerationStructureSizeAndAlign(descriptor: descriptor) let accelerationStructure = heap.makeAccelerationStructure(size: sizeAndAlign.size)
-