-
Maximize your Metal ray tracing performance
Learn how to simplify your ray tracing code and increase performance with the power of Metal 3. We'll explore the GPU debugging and profiling tools that can help you tune your ray tracing applications. We'll also show you how you can speed up intersection tests and reduce shader code memory accesses and indirections with per-primitive data in an acceleration structure. And we'll help you implement faster acceleration structure builds and refits to reduce load times and per-frame overhead.
Resources
Related Videos
Tech Talks
WWDC23
WWDC22
WWDC21
WWDC20
-
Search this video…
♪ ♪ Hi, my name is Yi. Hi, my name is Dominik. And we are GPU software engineers. Today, Dominik and I are going to talk about the performance enhancements and features we've added to the Metal Ray Tracing API this year to help you maximize the performance of your ray tracing applications. Ray tracing applications simulate individual rays of light bouncing around a scene. This is used in games and offline rendering to produce photorealistic reflections, shadows, global illumination, and more. This requires simulating a lot of rays, so performance is critical for these applications. Fortunately, Metal has built-in support for ray tracing optimized for all Apple devices. Let's briefly review how ray tracing works in Metal. The Metal ray tracing API is available from within shader functions such as compute or fragment functions. We start by generating some rays which are emitted into the scene. Next, we create an intersector object and use it to check for intersections between our rays and the geometry in the scene. A bit later, I will describe some of the new features we've added this year to speed up the intersection search. This process depends on a special data structure called an acceleration structure, which also represents the geometry in the scene. I will also talk about several new features and performance improvements focused on acceleration structures today. The intersector returns an intersection result object describing the primitive each ray hit. The intersection result is used to produce a color to write into the output image. It can also be used to produce additional rays which go through the process again. We can repeat this process as many times as we'd like to simulate light bouncing around the scene. If you want to learn more about the basics of the Metal ray tracing API, I recommend you review our previous WWDC sessions. We first introduced the Metal ray tracing API at WWDC20, and last year, we introduced new features including support for motion blur. Today, I'm going to talk about three things. First, I will tell you about new features which enable you to improve ray tracing performance in your applications.
Next, I will talk about improvements and features we've added to the acceleration structure API.
Finally, Dominik will tell you about improvements to our GPU tools for ray tracing. This year, we've added three new features aimed at either improving ray tracing performance or simplifying your code. They are per-primitive data, the ability to retrieve buffers from intersection function tables, and support for ray tracing from indirect command buffers.
Let's start with per-primitive data. Applications usually have data associated with the primitive in their scene such as vertex colors, normals, and texture coordinates.
This year, we've added the ability to store small amounts of data for each primitive directly in the acceleration structure. This data can be accessed with fewer memory indirections and cache misses, improving performance. This also reduces the need to store complicated auxiliary data structure which are typically required to look up the data associated with your primitives.
Let's look at an example.
Alpha testing is a technique used to add complexity to transparent geometry without increasing the triangle count. In this technique, the alpha channel of a texture mapped onto a triangle is used to determine if the ray should hit the triangle or continue further.
To achieve this, you need to configure the intersector to call your custom intersection function when a triangle is hit by the ray.
The ultimate goal is to sample from the texture associated with the triangle and test if the alpha value allows the ray to continue through the primitive. To get there, you need two pieces of information: the texture object and the UV coordinates. In a typical implementation of alpha testing, you would need to access a number of intermediate buffers in Metal device memory in order to get this information.
First, you would store the texture associated with the primitive in some kind of material structure.
Several materials would be packed into a buffer. It would be impractical to store material structure for every primitive, as they may be pretty big and there may be a lot of primitives. Instead, you would want to store just the material IDs for each primitive in a buffer and use them to look up the materials. Next, to calculate UVs, you need to load the UVs for each vertex from another buffer and interpolate them. Finally, let's say you are using instanced geometry. You may want each instance to have its own materials and UV mappings. To support that, you would store pointers to UV and Material ID buffers in an Instance Data buffer, adding yet another level of indirection to your function. This approach requires you to maintain a fairly complex buffer setup and involves many layers of indirection to get to the data that you need. This may also lead to cache misses that would negatively affect the performance. Let's look at the code needed to implement this diagram. Then I will show you how you can simplify it step-by-step using per-primitive data. This is the original implementation of the alpha testing intersection function. This function is invoked when the ray hits an alpha tested triangle. The function starts by loading the instance data from the memory. This is the buffer that contains pointers to UV and material buffers used by the instance. Next, the function loads the UV coordinates from the UV buffer and interpolates them. This is another memory load. Then, the function loads the material index from another buffer. And finally, the function loads the material and samples the corresponding texture. At this point, the function has the alpha value it needs and can compare it to the threshold. Now, I will show you how you can simplify this code and improve its performance using per-primitive data. Instead of using a complicated buffer setup with multiple layers of indirection, you can simply store only the data the intersection function will need for each primitive directly in the acceleration structure. In this example, you can create a struct containing the texture and UV coordinates for each primitive. You provide this data when building the acceleration structure and the intersection function simply receives a pointer to that data when a ray hits the primitive. You can store anything you like in the per-primitive data, but keeping the size small will help achieve the best performance. I will start with the inputs to the intersection function. Having access to all of them gives you a lot of flexibility when it comes to the implementation, but it can also increase the register usage on the GPU. With per-primitive data, instead of all the buffers, you only need to access the primitive data pointer. This is the data you store directly in the acceleration structure. In this case, each primitive has its own texture object and UVs for all of its vertices. Next up are the loads from the global material buffer and instance data buffer. You won't need either of them. Instead, you can do one load from the per-primitive data pointer. This is the only device memory access needed in this function. Next up are the UVs. Instead of dereferencing a pointer retrieved from the instance data, you can simply access the data embedded in the per-primitive data structure. The change in the code is subtle, but is important for performance, as no additional memory loads are involved. Finally, there are the material properties. Since the only part of the material needed is the texture, you can encode the primitive's texture directly in the per-primitive data structure. This means you don't need to access the material and material index buffers anymore. You can simply use the texture directly without paying the cost of additional memory dereferences. This is how much simpler your intersection code can be when using per-primitive data. All the costly memory accesses are replaced with just one load from the primitive data pointer. On top of that, the code is much simpler and easier to follow.
Next, I will show you how to store the primitive data in the acceleration structure. You will need to do this before you can access it from an intersection function. You will need to set a few fields in the acceleration structure geometry descriptor. First, set the Metal buffer where all the data is stored. Next, specify the size of the data that will be stored for each primitive. If your data is not tightly packed in the buffer or doesn't start at the beginning of the buffer, you can also specify the stride and the offset. Otherwise, these values default to 0 so you don't need to set them. You have already seen how you can use per-primitive data in an intersection function. It's simply passed into the function as a pointer. But that's not all–you have access to this data wherever you need it. That includes the final intersection result returned by the intersector. And if you are using intersection query, the primitive data is also available for both candidate and committed intersections. This means you can use per-primitive data for shading in addition to intersection testing. Per-primitive data can improve the performance of both your intersection code and your shading code by reducing the number of memory accesses and indirections. In fact, we found in one of our own test applications that using per-primitive data resulted in a 10% to 16% performance improvement. We can't wait for you to try it out and see what kinds of improvements you can get in performance and code quality. This year, we've also added another convenience feature to the Metal shading language to help you simplify your ray tracing kernels. Applications often pass the same set of bindings to both their intersection functions and their main ray tracing kernel. For example, our ray tracing sample code uses an intersection function to render spheres. This intersection function accesses a resource buffer containing information about each sphere. In order to pass this buffer into the intersection function, the app binds the buffer to the intersection function table. However, the main ray tracing kernel also needs access to the resource buffer, so the app binds the buffer there as well. This year, the Metal shading language allows you to access the buffers bound to intersection function tables. With this new feature, you can save the effort of binding the buffer for the kernel, and instead access it directly from the intersection function table. You can do this by calling the get_buffer method on the intersection function table, providing its pointer type. You can also access visible function tables by their function type. Indirect command buffers allow you to encode GPU work independently on the GPU and represent a fundamental element of GPU driven pipelines. To learn more about indirect command buffers and GPU-driven rendering, we recommend you review the "Modern rendering with Metal" session from WWDC 2019. Enabling ray tracing support in an indirect command buffer is easy. All you have to do is to set the supportRayTracing flag on the descriptor. Indirect command buffers dispatch graphics and compute functions, so you can simply use ray tracing from those functions as usual. That's a rundown of all the new features we've added this year to help you get improved ray tracing performance in your applications. Next, let's talk about acceleration structures. We've implemented several performance improvements and added features focused on building acceleration structures. Let's recap what they are used for. Acceleration structures are data structures which accelerate the ray tracing process. They do this by recursively partitioning space so we can quickly find which triangles are likely to intersect a ray. To support building complex scenes, Metal supports two types of acceleration structures: primitive and instance acceleration structures. Individual pieces of geometry are represented using primitive acceleration structures. They can be something simple like a plane or a cube, or something more complex like a sphere or a triangle mesh. You can create more complex scenes using an instance acceleration structure. Instance acceleration structures create copies of primitive acceleration structures. First, define transformation matrices for each object in your scene. Then, use the array of transformation matrices and primitive acceleration structures to build an instance acceleration structure. That's how you can build a static scene using acceleration structures. Next, let's see how dynamic applications like a game would use acceleration structures.
Let's start at the beginning: there are several tasks you need to do when first launching a game or loading a new level. This includes the normal tasks like loading models and textures. With ray tracing, you also need to build primitive acceleration structures for all of the models which will be used. We recommend that you build as many of your primitive acceleration structures as possible at load time to save time in your main rendering loop. You can use an instance acceleration structure to add or remove these objects from the scene as needed. Once your app is done loading, it enters the main loop. Every frame, it renders the scene using a combination of rasterization, ray tracing, and post-processing. However, since games are very dynamic, you will probably need to update some of the acceleration structures. This typically includes refitting a handful of deforming or animated models such as skinned characters. Refitting an existing acceleration structure is much faster than a full rebuild, so we recommend using it for cases like this. You should also do a full rebuild of the instance acceleration structure. This is necessary since objects may have been added or removed from the scene since the last frame, or they may have moved significantly. Doing a full rebuild is fine in this case since there's only one instance acceleration structure and it usually only contains at most a few thousand objects. This year, we've improved performance for all of these cases. First, acceleration structure builds are now up to 2.3 times faster on Apple Silicon. Second, refitting is also up to 38% faster.
This means that both load times and per-frame overhead are reduced. But it gets even better. Some applications build hundreds or even thousands of small primitive acceleration structures. These small builds don't do enough work individually to fill up the GPU, resulting in long periods of low GPU utilization. Therefore, multiple builds are now automatically performed in parallel whenever possible on Apple Silicon. This results in up to 2.8 times faster builds when they run in parallel. This further reduces load times. And this doesn't just apply to builds: it applies to all of the acceleration structure operations including compacting and refitting, so your per-frame overhead is reduced as well. There are a few guidelines you will need to follow to ensure that you can benefit from this optimization. Here is an example that builds an array of acceleration structures. To build them in parallel, you will need to ensure that you use the same acceleration structure command encoder for many builds. Additionally, builds which use the same scratch buffer can't run in parallel. Therefore, you will want to ensure that you are looping through a small pool of scratch buffers rather than using the same scratch buffer for each build.
Those are all the performance improvements we've made to building acceleration structures. We've also added three new features to make building acceleration structures easier and more efficient.
They are support for additional vertex formats, transformation matrices, and acceleration structure allocation from heaps.
Let's start with vertex formats. A common performance optimization is to use quantized or reduced precision formats for vertex data, resulting in lower memory usage. This year, you can build acceleration structures from a wide range of vertex formats. This includes half precision floating point formats, two component vertex formats for planar geometry, and all the usual normalized integer formats. Previously, acceleration structures have required three component, full-precision floating point vertex data. In this example, the application has vertex data in a half precision vertex format. This data needs to be unpacked and copied into a temporary buffer just to build the acceleration structure. With the new vertex formats feature, acceleration structure builds can now consume vertex data in any of the supported formats, eliminating the need to create a temporary copy. Setting the vertex format couldn't be simpler. All you need to do is set the property on your geometry descriptor. Next, let's talk about transformation matrices. This feature complements the new vertex formats, so that you can pre-transform your vertex data before building the acceleration structure. For example, you might want to use them to unpack complex meshes stored in a normalized format. Let's consider the Red Panda model in this scene. To normalize the geometry to use one of our compressed formats, you take the mesh, calculate its bounds, and then scale them to a zero to one range. You can then use one of the normalized integer vertex formats to store the mesh, reducing the amount of space it takes up on disk and in memory. At runtime, you provide a matrix that will scale and offset each vertex to the final position. Applying that matrix retrieves the original model. Now let's walk through how to set up acceleration structure passing a transformation matrix. You start by creating the transform buffer. One way of doing this is to create an MTLPackedFloat4x3 object containing the scale and offset transformation matrix. Then, create a Metal Buffer big enough to hold the matrix. And finally, copy the matrix to the Buffer. Next, set up the acceleration structure. First, create a triangle geometry descriptor. Then, specify the transformation Matrix Buffer. And finally the Buffer Offset. That's all you need to do to set up the transformation matrix. These matrices can also be used to combine simple acceleration structures to improve ray tracing performance. Let's see an example scene. Here, the boxes and the spheres are all relatively simple meshes. This presents an opportunity to optimize the acceleration structure for this group at the front of the scene. Focusing on the instance acceleration structure, there is an overhead for each instance that your rays hit. There is a cost for transforming the ray and then switching from the instance to the primitive acceleration structure. This occurs more often with overlapping instances. To reduce the instance count, you can generate a single primitive acceleration structure that contains both the boxes and the sphere. To do this, you can create a geometry descriptor for each object, each with its own transformation matrix. The resulting primitive acceleration structure is a single instance in the instance acceleration structure and contains the boxes and sphere. This should result in a better performing acceleration structure. Let's see how to set this up in code.
You start with the descriptor that defines the sphere geometry. Next, set the vertex buffer, index buffer, and other properties as usual for a primitive acceleration structure. The difference is, you also specify the transform buffer that contains the transformation matrix used for the copy of the sphere.
For the boxes, you have multiple geometry descriptors sharing a vertex and index buffer. You just need to specify different transform buffers for each copy. Finally, when creating the descriptor for the primitive acceleration structure, add all the geometry descriptors. This will result in a primitive acceleration structure that you can instance into the scene with an identity transform. This primitive acceleration structure will take less time to build than separate acceleration structures and will be faster to intersect.
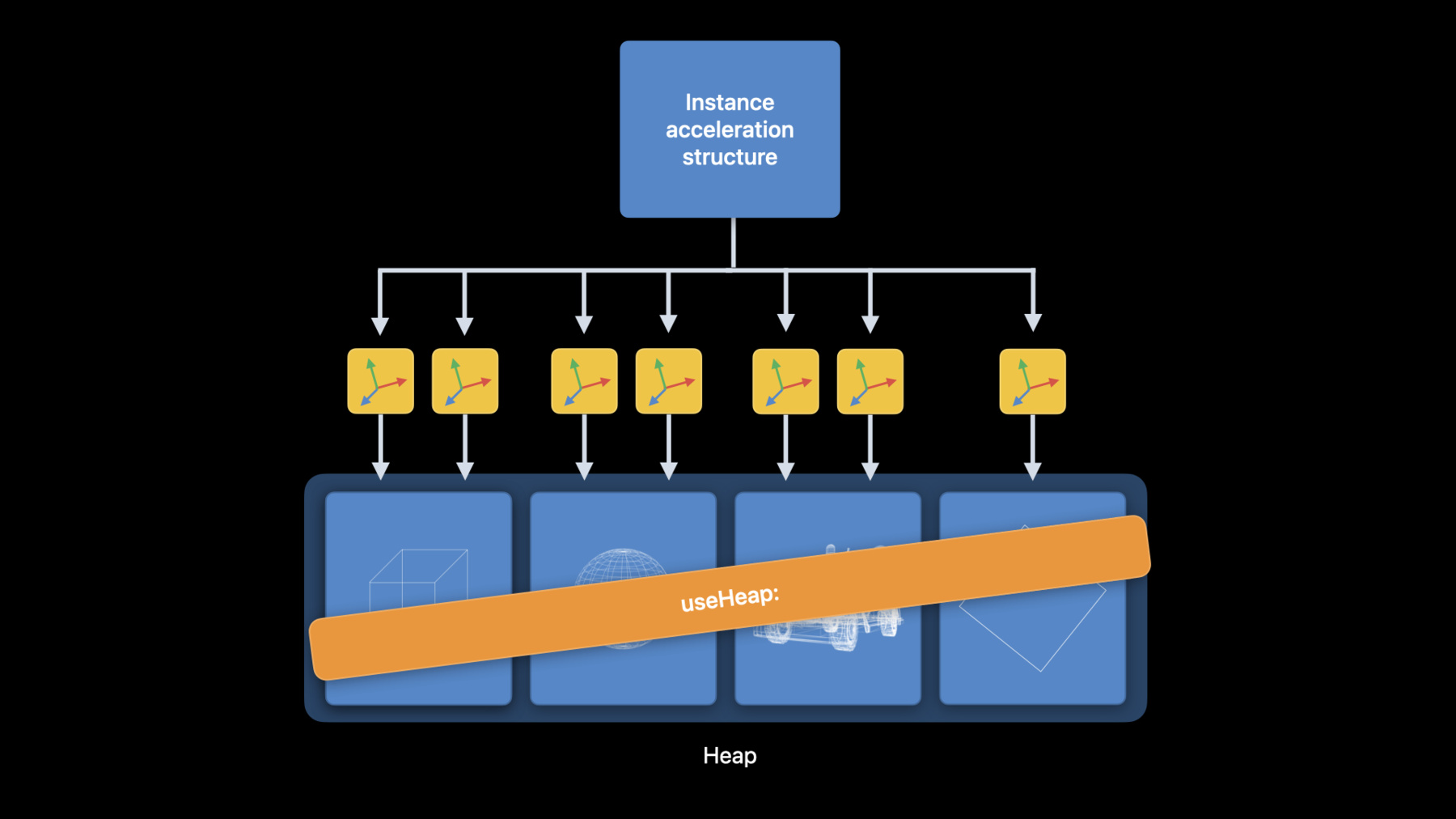
Finally, heap allocation of acceleration structures has been one of our most requested features. With this feature, you now have more control over acceleration structure allocation. It also allows you to reuse heap memory between allocations, avoiding expensive buffer allocations. Heaps can also help improve performance by reducing calls to the useResource: method when using instance acceleration structures. Going back to the example scene, the instance acceleration structure references primitive acceleration structures indirectly. This means that each time you want to use an instance acceleration structure with a command encoder, you need to call useResource: method for each primitive acceleration structure. For large scenes, this could require thousands of calls to useResource: each time you use the instance acceleration structure. Knowing that you have so many useResource: calls, you could call useResources: to reduce the number of API calls, but you still need to maintain an array of your acceleration structures and Metal still needs to loop through the array. Instead, you can allocate all of these primitive acceleration structures from the same heap. When you want to use the instance acceleration structure, you can simply make a single call to the useHeap: method to reference all of the primitive acceleration structures. We saw a small performance improvement in one application simply by replacing the calls to useResource: with a single call to useHeap:. Let's see how you can allocate an acceleration structure from a heap. You can directly allocate an acceleration structure by calling a method on the heap that takes the acceleration structure descriptor as the input. If you are not allocating using the descriptor, the Metal device determines the size and alignment requirement for allocating the acceleration structure from a heap. You can get this information from the Metal device by providing the descriptor or acceleration structure size. Once the final size is determined, you can allocate the acceleration structure from the heap. There are a few things to remember when using heaps. First, remember to call useHeap: to make all of the acceleration structures in the heap resident for the duration of the ray tracing pass. Second, by default, Metal doesn't track resources you allocate from a heap. You can either opt-in to resource hazard tracking, or you can manually manage your own synchronization. You can use MTLFences to synchronize across command encoders and MTLEvents to synchronize across command buffers. Those are the new features and performance improvements in the Metal ray tracing API this year. Next, Dominik will talk about improvements to Xcode's Metal tools that will boost your productivity when developing ray tracing applications. Dominik: Thanks, Yi. There are a lot of enhancements to the Metal tools in Xcode 14, but here, I would like to highlight just a few that are especially useful when developing ray tracing applications Starting with the Metal debugger, I'll talk about improvements to the Acceleration Structure Viewer, Shader Profiler, and Shader Debugger.
Then I'll round it up with the runtime Shader Validation.
First, let's take a look at the Acceleration Structure Viewer. The Acceleration Structure Viewer in the Metal Debugger enables you to inspect, in great detail, all of the geometries and instances of all the meshes that make up your acceleration structure.
Xcode 14 now supports debugging acceleration structures with primitive or instanced motion and a new highlight mode for visualizing primitives with an inspector for per-primitive data. Let's see them in action.
If you are using acceleration structures with motion, you now have a scrubber in the bottom bar for viewing your acceleration structure at different points in time. On the right of the scrubber is a "play" button. You can use it to play the animation back and forth in a loop. Now let me show you how to inspect individual primitives in your acceleration structure. This is especially useful if you are using the new per-primitive data API. And so there's a new highlight mode just for this. Primitive highlight mode gives you access to all primitive data...
And allows you to select specific primitives for detailed inspection.
In the left sidebar, you can find arrows next to the data rows.
Clicking on an arrow will reveal a popover that displays the corresponding data for the primitive. These additions to the acceleration structure viewer ensure you have full access, down to each primitive, to all of the components that make up your acceleration structure. Next, let's talk about improvements to the Shader Profiler. The Shader Profiler gives you insights into the performance of your shader, providing per-pipeline execution timing costs, and on Apple GPUs, it provides more granularity at the source level, showing the execution costs per-line distributed across instruction categories. In Xcode 14, profiling GPU captures has been updated to support intersection functions, visible functions, and dynamic libraries.
Here we have a ray tracing kernel using an intersection function. You can now view the per-line profiling results inside of the intersection function. This includes a breakdown of the instruction categories that contribute to the cost.
Profiling visible functions works the same way.
And similarly, detailed profiling information is now available for shader code from linked dynamic libraries. With these additions, you now have the full breakdown of the performance of your pipeline, down to each line of code.
Moving on to the Shader Debugger. The Shader Debugger provides a unique and incredibly productive workflow for debugging the correctness of your shader code. Just like with the Shader Profiler, we've also extended support to enable debugging of Linked functions and Dynamic libraries. Here we have a ray tracing kernel that calls out to a linked visible function passed in through a visible function table.
You are now able to follow the execution of a kernel all the way into your visible function code to verify that the code behaves as you expect it to.
Again, the same applies to debugging dynamic libraries. You are also able to jump into and out of any executed dynamic libraries that are linked to your pipeline. With these additions, you now have a complete picture of your shader execution across linked functions and libraries in your pipeline.
Now, before you capture and jump into the Shader Debugger, it is often a good idea to enable Shader Validation at runtime.
Shader validation is a great way to diagnose runtime errors on the GPU, catching issues such as out-of-bound memory accesses, null texture reads, and more. To enable Shader Validation in Xcode, all you need to do is to go to the "Edit Scheme" dialog, select the "Run" action, and under the "diagnostics" tab tick the "Shader Validation" checkbox. And you are all set to go. In Metal 3, we have added Stack Overflow detection which will help you quickly find issues that would otherwise result in undefined behavior. I'll quickly elaborate on the function stack in Metal shaders and the problem of Stack Overflow. The call stack is a region in device memory where Metal stores the values of local data used in your shader functions. If the called function is not known at compile time, Metal needs your help in estimating the amount of memory required for the stack. An example of a call to a function that is unknown at compile time may be a ray tracing intersection function. If you are using custom intersection functions, maximum call stack depth should be set to 1, to allocate space for it. This is the default value, so there is nothing more that you need to do. However, if you are using Function Tables to call into a Visible function, this is another example of a function call unknown at compile time. If you perform such a call from an intersection function, like in this example, your call stack will be two levels deep.
Another example are calls to dynamic libraries and calling a local function using a function pointer. In this example, our call stack has four levels with nested calls to different types of functions that cannot be resolved when the shader is compiled. To properly configure Metal to allocate the right amount of memory, you need to specify a maximum call stack depth of 4 yourself. The important thing to remember is that when the value of the max Call Stack Depth is set too low for your program, Stack Overflow can happen, resulting in undefined behavior. But if you are running with Shader Validation enabled, such situations will be caught early, and you will see information in Xcode about where the Stack Overflow occurred. You can then go and fix your shader code, or adjust your maximum call stack depth in the pipeline descriptor. All of these new improvements to the Metal tools in Xcode 14 ensure you have an even more complete picture and insight into the performance and correctness of your ray tracing applications. For more on how to get the most out of the Metal tools for debugging and profiling, check out these other sessions This session has been all about maximizing Metal ray tracing performance for your applications. We talked about how you can squeeze out more performance and simplify your code using new features such as per-primitive data. We also described optimization techniques and features that make building accelerations structures faster and more convenient than ever before. Finally, we covered all the new enhancements to the Metal tools in Xcode 14 that will provide you with deeper insight during your development. Thanks for watching.
-
-
4:04 - Alpha testing with intersection functions
float alpha = texture.sample(sampler, UV).w; return alpha >= 0.5f; -
5:46 - Alpha testing intersection function
[[intersection(triangle, raytracing::triangle_data, raytracing::instancing)]] bool alphaTestIntersection(float2 coordinates [[barycentric_coord]], unsigned int primitiveIndex [[primitive_id]], unsigned int instanceIndex [[instance_id]], device GlobalData *globalData [[buffer(1)]], device InstanceData *instanceData [[buffer(0)]]) { device Material *materials = globalData->materials; InstanceData instance = instanceData[instanceIndex]; float2 UV = calculateSamplingCoords(coordinates, instance.uvs[primitiveIndex * 3 + 0], instance.uvs[primitiveIndex * 3 + 1], instance.uvs[primitiveIndex * 3 + 2]); int materialIndex = instance.materialIndices[primitiveIndex]; float alpha = materials[materialIndex].texture.sample(sam, UV).w; return alpha >= 0.5f; } -
6:48 - Primitive Data
struct PrimitiveData { texture2d<float> texture; float2 uvs[3]; }; -
7:08 - Alpha testing intersection function using per-primitive data
// Alpha testing intersection function [[intersection(triangle, raytracing::triangle_data, raytracing::instancing)]] bool alphaTestIntersection(float2 coordinates [[barycentric_coord]], const device PrimitiveData *primitiveData [[primitive_data]]) { PrimitiveData ppd = *primitiveData; float2 UV = calculateSamplingCoords(coordinates, ppd.uvs[0], ppd.uvs[1], ppd.uvs[2]); float alpha = ppd.texture.sample(sam, UV).w; return alpha >= 0.5f; } -
8:54 - Setting up per-primitive data
geometryDescriptor.primitiveDataBuffer = primitiveDataBuffer geometryDescriptor.primitiveDataElementSize = MemoryLayout<PrimitiveData>.size geometryDescriptor.primitiveDataStride = MemoryLayout<PrimitiveData>.stride geometryDescriptor.primitiveDataBufferOffset = primitiveDataOffset -
9:18 - Using per-primitive data
// Intersection function argument: const device void *primitiveData [[primitive_data]] // Intersection result: primitiveData = intersection.primitive_data; // Intersection query: primitiveData = query.get_candidate_primitive_data(); primitiveData = query.get_committed_primitive_data(); -
11:08 - Buffers from intersection function tables
device int *buffer = intersectionFunctionTable.get_buffer<device int *>(index); visible_function_table<uint(uint)> table = intersectionFunctionTable.get_visible_function_table<uint(uint)>(index); uint result = table[0](parameter); -
11:36 - Ray tracing from indirect command buffers
let icbDescriptor = MTLIndirectCommandBufferDescriptor() icbDescriptor.supportRayTracing = true -
15:43 - Parallel acceleration structure builds
for (index, accelerationStructure) in accelerationStructures.enumerated() { encoder.build(accelerationStructure: accelerationStructure, descriptor: descriptors[index], scratchBuffer: scratchBuffers[index % numScratchBuffers], scratchBufferOffset: 0) } -
17:28 - Setting vertex formats
let geometryDescriptor = MTLAccelerationStructureTriangleGeometryDescriptor() geometryDescriptor.vertexFormat = .uint1010102Normalized -
18:29 - Creating transformation matrix buffer
var scaleTransform = MTLPackedFloat4x3(columns: ( MTLPackedFloat3Make( scale.x, 0.0, 0.0), MTLPackedFloat3Make( 0.0, scale.y, 0.0), MTLPackedFloat3Make( 0.0, 0.0, scale.z), MTLPackedFloat3Make(offset.x, offset.y, offset.z)) let transformBuffer = device.makeBuffer(length: MemoryLayout<MTLPackedFloat4x3>.size, options: .storageModeShared)! transformBuffer.contents().copyMemory(from: &scaleTransform, byteCount: MemoryLayout<MTLPackedFloat4x3>.size) -
18:51 - Setting transformation matrix buffer on geometry descriptor
let geometryDescriptor = MTLAccelerationStructureTriangleGeometryDescriptor() geometryDescriptor.transformationMatrixBuffer = transformBuffer geometryDescriptor.transformationMatrixBufferOffset = 0 -
20:12 - Merging instances using transformation matrices
let sphereGeometryDescriptor = MTLAccelerationStructureTriangleGeometryDescriptor() sphereGeometryDescriptor.vertexBuffer = sphereVertexBuffer sphereGeometryDescriptor.indexBuffer = sphereIndexBuffer sphereGeometryDescriptor.transformationMatrixBuffer = sphereTransformBuffer let redBoxGeometryDescriptor = MTLAccelerationStructureTriangleGeometryDescriptor() redBoxGeometryDescriptor.vertexBuffer = boxVertexBuffer redBoxGeometryDescriptor.indexBuffer = boxIndexBuffer redBoxGeometryDescriptor.transformationMatrixBuffer = redBoxTransformBuffer let blueBoxGeometryDescriptor = MTLAccelerationStructureTriangleGeometryDescriptor() blueBoxGeometryDescriptor.vertexBuffer = boxVertexBuffer blueBoxGeometryDescriptor.indexBuffer = boxIndexBuffer blueBoxGeometryDescriptor.transformationMatrixBuffer = blueBoxTransformBuffer let primitiveASDescriptor = MTLPrimitiveAccelerationStructureDescriptor() primitiveASDescriptor.geometryDescriptors = [sphereGeometryDescriptor, redBoxGeometryDescriptor, blueBoxGeometryDescriptor] -
22:33 - Heap acceleration structure allocation
let heap = device.makeHeap(descriptor: heapDescriptor)! let accelerationStructure = heap.makeAccelerationStructure(descriptor: descriptor) let sizeAndAlign = device.heapAccelerationStructureSizeAndAlign(descriptor: descriptor) let accelerationStructure = heap.makeAccelerationStructure(size: sizeAndAlign.size)
-