-
MLX를 사용하여 Apple Silicon에서 대규모 언어 모델 탐색하기
Apple Silicon에서 대규모 언어 모델을 간단하고 효율적으로 사용하는 데 초점을 맞춘 MLX LM을 소개합니다. Mac에서 최첨단 대규모 언어 모델을 미세 조정하고 추론을 실행하는 방법과 이를 Swift 기반 애플리케이션 및 프로젝트에 원활하게 통합하는 방법을 살펴보겠습니다.
챕터
리소스
- MLX Swift Examples
- MLX Examples
- MLX Swift
- MLX LM - Python API
- MLX Explore - Python API
- MLX Framework
- MLX Llama Inference
- MLX
관련 비디오
WWDC25
-
비디오 검색…
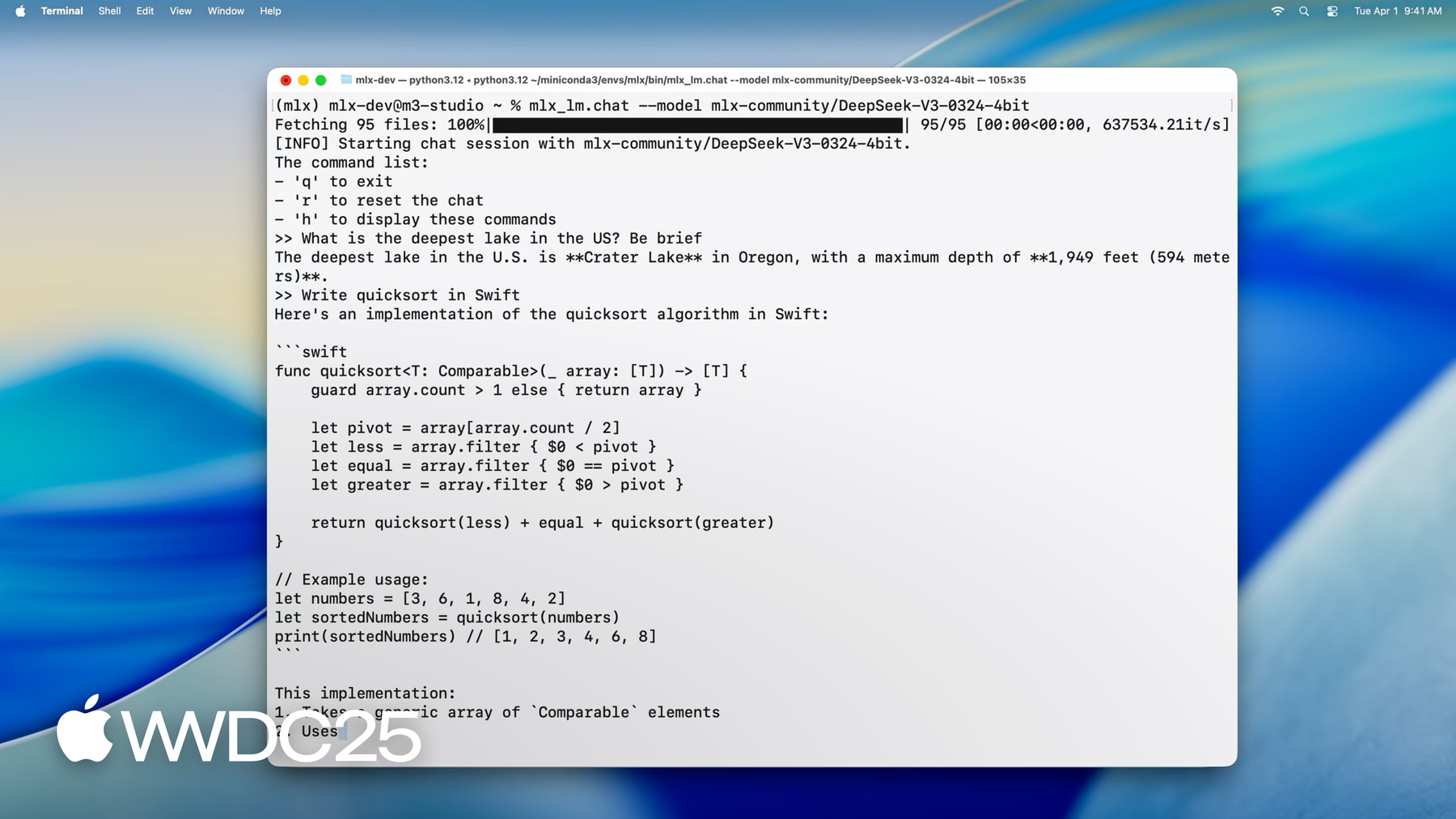
안녕하세요, MLX 팀의 엔지니어 Angelos입니다 오늘은 Apple Silicon의 대규모 언어 모델에 MLX가 얼마나 완벽한지 보여 드리겠습니다 MLX를 통해 Mac에서 바로 추론을 수행하고 대규모 모델을 미세 조정할 수 있습니다 모두 CLI 응용 프로그램이나 Python 또는 Swift에서 가능합니다 MLX를 처음 사용하신다면 MLX는 Apple Silicon에서 머신 러닝용으로 특수 제작된 오픈 소스 라이브러리입니다 GPU 가속을 위해 Metal를 활용하며 통합 메모리를 이용하기 때문에 CPU와 GPU의 연산에서 동시에 동일 데이터를 처리할 수 있습니다 MLX는 Python, Swift, C++, C로 API를 제공하므로 원하는 언어로 사용할 수 있습니다 자세한 내용은 “Apple Silicon용 MLX 사용하기” 세션을 확인하세요 Apple Silicon에서 대규모 언어 모델을 실행할 때 MLX의 강력한 새 기능을 활용하여 명령 한 줄로 Mac에서 바로 최신 첨단 모델을 실행할 수 있습니다 DeepSeek AI의 최신 모델을 로드해 보죠 매개변수가 무려 6,700억 개에 달합니다
가중치당 4.5비트로 양자화하더라도 모델 가중치에 필요한 메모리만 약 380기가바이트입니다 여기에 M3 Ultra를 사용합니다 512기가바이트의 방대한 통합 메모리를 탑재하고 있어 소비자용 기기로는 독보적입니다 모델이 로드되었으므로 이제 모델과 상호작용할 수 있습니다 질문으로 “미국에서 가장 깊은 호수는 어디야?”라고 묻거나
코드 작성을 요청할 수 있습니다
보시다시피 MLX를 사용하면 읽기 속도보다 빠른 속도로 원활한 실시간 상호작용과 생성이 가능합니다 매개변수가 수천억 개인 모델이라도 모두 Mac 데스크탑에서 로컬로 실행됩니다 가능한 작업을 확인했으니 이제 MLX를 사용하여 개인 Mac에서 이처럼 강력한 모델을 실행하는 방법을 살펴보겠습니다 먼저 Python 라이브러리인 MLX LM과 명령 라인 응용 프로그램 세트를 소개합니다 이를 통해 모든 대규모 언어 모델 요구 사항을 처리할 수 있어 다양한 응용 프로그램에 대해 강력한 다목적 솔루션입니다
그 다음에는 MLX LM을 이용한 텍스트 생성에 대해 알아보고 Python이나 터미널에서 텍스트를 생성하는 것이 얼마나 쉬운지 보여 드리겠습니다 또한 Hugging Face에서 모델을 다운로드한 후 양자화해 기기에서 빠른 추론을 구현하는 작업을 살펴봅니다
MLX는 추론 외에도 다양한 용도로 활용할 수 있습니다 이에 따라 MLX LM을 사용하여 자체 데이터로 언어 모델을 미세 조정해 보겠습니다 특히 낮은 순위의 어댑터를 학습시킬 것입니다 학습이 끝나면 더 쉬운 배포와 더 빠른 추론을 위해 어댑터를 모델에 융합할 수 있습니다 마지막으로 Swift에서 MLX를 사용하는 사례를 살펴보며 단 몇 줄의 코드로 Swift 응용 프로그램에 대규모 언어 모델을 통합하는 방법을 확인합니다
MLX에서 언어 모델을 시작하는 가장 쉬운 방법은 MLX LM을 사용하는 것입니다 MLX LM은 MLX를 기초로 빌드된 Python 패키지로서 대규모 언어 모델을 실행하고 실험하기 위해 디자인되었습니다 MLX LM의 명령 라인 도구 세트로 코드를 작성할 필요 없이 텍스트를 생성하거나 모델을 미세 조정할 수 있습니다 더 큰 제어 기능을 원한다면 Python API도 제공되므로 생성이나 학습 과정을 원하는 대로 맞춤화할 수 있습니다 또한 Hugging Face와도 긴밀하게 통합되어 있습니다 즉, 인터넷에서 수천 개의 모델을 빠르게 다운로드할 수 있고 자신의 모델을 업로드해 커뮤니티와 공유할 수도 있습니다
시작하려면 pip install mlx-lm을 실행합니다
언어 모델의 가장 일반적인 사용 사례인 텍스트 생성에 대해 자세히 알아보겠습니다
이것은 코드가 필요 없이 터미널에서 바로 언어 모델을 사용해 텍스트를 생성할 수 있는 명령 라인 도구죠 Hugging Face나 로컬 경로의 모델에 텍스트 프롬프트를 제공하면 자동 처리되는 방식입니다 필요한 경우 모델을 다운로드하고 이 모델로 프롬프트를 실행한 후 생성된 응답을 인쇄합니다 말로만 설명하기보다는 이 명령을 직접 실행해 보겠습니다
단 몇 초 만에 빠른 정렬의 Swift 구현을 얻을 수 있습니다
일반적인 텍스트 생성 설정과 마찬가지로 샘플링 온도, top-p 최대 토큰 등에 대한 플래그를 추가하여 모델의 동작을 조정할 수 있습니다 사용 가능한 모든 옵션이 궁금하다면 mlx_lm.generate --help를 실행하면 됩니다 아이디어 프로토타이핑, 코드 생성, 모델 기능 탐색 등 어떤 작업을 수행하든 이곳에서 매우 간단하게 시작할 수 있습니다 지금까지 mlx_lm.generate를 사용하여 명령 라인으로 텍스트를 쉽게 생성하는 방법을 확인했습니다 하지만 MLX LM의 진정한 장점은 터미널 도구에 국한되지 않는 거죠 또한 깔끔하고 유연한 Python API를 제공하는데 더욱 세밀하게 제어하고자 하거나 생성을 더 큰 작업 흐름으로 통합해야 할 때 적합합니다 텍스트 생성이라는 동일한 작업을 Python 몇 줄로 수행하는 방법을 살펴보겠습니다
먼저 load와 generate라는 두 가지 유틸리티를 가져옵니다 이름에서 알 수 있듯이 load는 모델 로드 관련 내용을 처리합니다 로컬 디스크나 Hugging Face에서 요청된 모델을 직접 가져오고 토크나이저와 함께 모델 객체를 설정합니다 이어서 generate를 호출합니다 이 함수는 토큰 생성 루프를 수행하고 출력 텍스트를 반환하며, 이 텍스트는 Python을 통해 추가로 처리하거나, 로깅하거나, 다른 시스템에 공급할 수 있습니다
이처럼 load와 generate라는 두 단계만 거치면 CLI와 동일한 기능을 확보하면서 완전한 제어권과 Python의 유연성을 누릴 수 있습니다 MLX LM의 Python API가 지닌 강력한 측면을 더 소개하겠습니다 load로 얻은 모델은 그저 고정된 인터페이스로만 인터페이스할 수 있는 불투명한 물체가 아닙니다 완전히 구조화된 MLX 신경망이므로 검사하고, 아키텍처를 살펴보고 심지어 수정할 수도 있습니다 간단한 데모를 보여 드리죠
우선 모델을 구성하는 계층의 목록을 인쇄합니다
트랜스포머 스택의 완전한 분석 내용을 계층별로 확인 가능합니다 모델의 매개변수 특히 모델이 학습한 가중치와 편향을 살펴볼 수도 있습니다
네트워크의 특정 부분 예를 들어 첫 번째 계층의 셀프 어텐션 모듈을 자세히 살펴보는 것도 가능합니다
이 정도 수준의 투명성은 매우 유용합니다 디버깅이나 학습뿐만 아니라 계층 교체, 루틴 맞춤형 미세 조정, 하위 수준 모델 수술 등을 실험하고자 할 때도 마찬가지입니다
지금까지 단일 프롬프트를 통한 텍스트 생성 방법을 보았습니다 하지만 대화를 유지하거나 새로운 각 프롬프트가 이전 프롬프트를 기초로 구축되는 다중 턴 형태로 응답을 생성하고자 한다면 어떨까요? 이때 유용한 것이 키 값 캐시 일명 KV 캐시입니다 언어 모델은 어텐션 메커니즘을 사용하여 입력 토큰을 처리하며 생성 중에는 이전에 생성된 모든 토큰에 대해 어텐션을 반복적으로 계산합니다 긴 프롬프트, 멀티턴 시나리오로 특히 비용이 증가할 수 있습니다 KV 캐시는 이전 단계의 중간 결과를 저장해 문제를 해결합니다 특히 키와 값을 저장합니다
모델은 모든 것을 처음부터 다시 계산하는 대신 이 캐시를 재사용하여 시간과 계산을 절약합니다 MLX LM에서 KV 캐시를 사용하는 것은 간단합니다
이전의 Python 예시를 가져와 여러 세대로 재사용 가능한 명시적 생성 KV 캐시로 업데이트합니다
먼저 make_prompt_cache 함수로 캐시 객체를 만듭니다 이것을 사용해 제자리에서 내역을 편집하거나 나중에 사용하기 위해 저장하거나 대화 간에 원활하게 전환할 수 있습니다
이어서 generate 함수에 전달합니다 새로운 토큰이 생성되면 캐시가 업데이트됩니다 각 호출은 마지막 호출이 중단된 곳에서 계속되므로 턴 전체의 컨텍스트가 유지됩니다 특히 내역을 계속 추적해야 하는 챗봇, 가상 도우미 또는 대화형 응용 프로그램을 빌드할 때 유용하죠
이제 모델 양자화에 대해 이야기해 보겠습니다 텍스트를 생성하고 대화형으로 모델을 사용하는 방법을 보았죠 하지만 실제 배포에서는 기능만큼이나 효율성이 중요합니다 모델은 일반적으로 학습된 것과 동일한 정밀도로 출시됩니다 예를 들면 float32, float16입니다 정확하지만 모델의 규모가 커지며 특히 작은 기기에서 느려집니다 이런 경우 양자화가 필요합니다
양자화는 모델을 Int8, 4비트처럼 낮은 정밀도로 줄여 줍니다 따라서 메모리 사용이 감소하고 추론 속도가 향상되지만 품질 영향은 거의 없습니다 흔히 양자화에는 추가 도구 변환 스크립트, 그리고 호환성 문제가 수반되지만 MLX에서는 훨씬 더 간단합니다 양자화는 내장 기능입니다 다양한 수준에서 모델을 압축한 후 별도 설정 없이 추론이나 학습에 바로 사용할 수 있습니다 이 기능이 어떻게 작동하는지 보죠
MLX로 모델을 양자화하거나 일반적으로 변환하려면 mlx_lm.convert 명령을 사용합니다 이 도구는 Hugging Face에서 모델을 다운로드해 다른 정밀도로 변환하고 로컬에 저장하는 작업을 한 번에 처리합니다 이 예에서는 원래 16비트인 Mistral 모델을 가져와 가중치당 약 4비트로 양자화합니다
결과적으로 모델이 훨씬 작아지고 실행 속도가 빨라졌으며 필요한 메모리도 줄어들었습니다 변환 완료된 모델은 지정 폴더에 저장되며, 동일한 MLX LM 도구로 추론이나 학습에 즉시 사용할 수 있습니다
자신의 양자화 모델을 다른 사람들과 공유하고 싶다면 리포지토리 이름을 전달하여 Hugging Face에 다시 쉽게 업로드할 수 있습니다 속도를 위한 최적화, 공간 절감 또는 커뮤니티 공헌 등 목적이 무엇이든 이 명령 하나면 모두 가능합니다
텍스트 생성과 마찬가지로 Python API를 사용해 모델을 변환하고 양자화하면 복잡성을 더하지 않고 유연성을 향상할 수 있습니다 실제로 MLX LM을 통해 모델의 다양한 부분에 또는 Python에서 다양한 양자화 설정을 쉽게 적용할 수 있습니다
예를 들어 임베딩 및 최종 투사 계층은 높은 정밀도로 유지하는 것이 일반적인 관행인데 이 부분이 양자화에 더 민감한 경향이 있기 때문입니다 이 예에서는 해당 계층은 6비트로 양자화하고 모델의 나머지에서는 4비트를 사용하도록 하여 품질과 효율성 간의 균형을 이룹니다 이를 위해 양자화 조건식 함수를 전달하는데, 이 작은 함수는 각 계층을 수신하고 그에 사용할 양자화 매개변수를 반환합니다 이외에는 동일하게 작동합니다 convert를 호출하고 Hugging Face 경로 및 로컬 출력 디렉토리를 전달하면 MLX가 나머지를 처리하죠 모델을 다운로드하고 양자화된 결과를 저장합니다 이 세밀한 제어 기능은 모델 압축을 실험하거나 성능과 정확성 간에 최고의 균형 지점을 찾고자 할 때 특히 유용합니다
지금까지 대규모 언어 모델로 텍스트를 생성하는 방법과 빠른 추론 및 가벼운 배포를 위해 모델을 양자화하는 방법을 살펴보았습니다 하지만 MLX는 특히 학습 측면에서 더 많은 기능을 자랑합니다 MLX LM을 사용하면 Mac에서 바로 자체 데이터로 대규모 언어 모델을 미세 조정할 수 있으며 데이터가 기기를 벗어나지 않습니다 가장 좋은 점은 코드 작성 없이 이 작업을 수행할 수 있다는 거죠 미세 조정이 어떻게 작동하는지 살펴보겠습니다
대규모 언어 모델은 일반적으로 인터넷의 대규모 범용 데이터세트로 학습합니다 덕분에 광범위한 지식이 생기지만 전문 분야에서 깊이가 부족하거나 특정 작업의 어조 및 언어를 놓치는 문제가 발생할 수 있습니다 미세 조정은 이런 모델을 새로운 컨텍스트에 적용시키는 방법입니다 소규모의 분야별 데이터세트로 모델을 학습시키면 모델에 새로운 역량을 부여하거나 특별한 필요에 맞게 모델의 응답을 맞춤화할 수 있습니다 기존에는 클라우드에서 이 과정을 수행했는데 비용이 많이 들고 비공개 데이터나 민감한 데이터로 작업할 때 대부분 적합하지 않았습니다 하지만 MLX로는 클라우드 없이 Mac에서 로컬로 대규모 언어 모델을 미세 조정할 수 있고 데이터가 컴퓨터를 벗어나지 않죠 효율적이고 안전하며 MLX 작업 흐름과 완벽하게 통합됩니다
MLX LM에서 바로 사용할 수 있는 두 가지 미세 조정 유형은 전체 모델 미세 조정과 저순위 어댑터 학습입니다 전체 미세 조정은 사전 학습된 모델의 매개변수를 모두 업데이트해 유연성이 극대화되지만 상당한 리소스를 소모합니다 반면 어댑터 학습의 경우 특히 저순위 어댑터에서 소수의 새 매개변수를 모델에 추가하고 이 매개변수만 학습시키며 원래 네트워크는 동결합니다 따라서 특히 로컬 하드웨어에서 더 빠르고 가벼운 학습이 가능하며 대부분 메모리 효율성이 높습니다 이 내용을 실제로 적용하는 방법을 살펴보기 위해 맞춤형 데이터세트로 Mistral 모델을 미세 조정할께요 MLX LM으로 미세 조정 작업을 시작하기가 얼마나 쉬운지 보시죠 명령 하나와 몇 가지 핵심 인수만 있으면 됩니다 미세 조정할 모델, 데이터세트 경로 및 학습을 진행할 기간을 지정합니다 양자화는 MLX에 긴밀하게 통합되어 있기 때문에 mlx_lm.lora 명령으로 양자화된 모델은 물론 어댑터도 학습시킬 수 있습니다 덕분에 미세 조정 기능의 효과를 저해하지 않으면서 메모리 사용량이 대폭 줄어듭니다
이 예에서는 Mistral의 4비트 양자화 버전으로 학습시키며 이에 따라 모델 가중치의 메모리 사용량이 전체 정밀도 버전보다 약 3.5배 줄어듭니다 대규모 모델이라도 미세 조정은 Mac에서 바로 사용할 수 있는 실용적이고 효율적인 방법인데요 명령 한 줄로 빠른 학습 실행이 가능하며 이 점은 특히 갓 시작했을 때 유용합니다 하지만 성능을 제대로 미세 조정하려면 학습 과정에 더 엄격한 제어 기능이 필요합니다 이때 유용한 것이 학습 구성 파일입니다 MLX LM은 경로 크기, 학습 속도 일정, 옵티마이저 설정 평가 간격 등 학습의 모든 측면을 세부 조정 방식으로 제어할 수 있는 구성 파일을 지원합니다 따라서 특정한 데이터 세트, 하드웨어 또는 최적화 목표에 따라 학습 설정을 맞춤화하고 어댑터를 최대한 활용할 수 있죠 이제 미세 조정의 실제 모습과 모델 지식 업데이트 방법을 볼까요 Mistral 7b에게 가장 최근 슈퍼볼의 우승자를 질문합니다
예상대로 답은 맞지만 옛날 정보입니다 최근 이벤트에 접근하지 못해 모델의 지식이 차단된 것입니다 미세 조정의 장점은 몇 분 만에 이 문제를 해결할 수 있다는 거죠 가장 최근의 슈퍼볼에 대한 질문과 답변이 포함된 소규모 데이터세트로 학습시키면 모델의 지식을 업데이트하여 정답을 말하도록 할 수 있습니다
단 몇 분간의 미세 조정이 끝나자 모델이 팀, 선수, 점수 등에 대해 최신 정보로 정확히 답변하게 되었습니다
어댑터를 학습시켰으니 MLX LM을 사용하여 이를 기본 모델에 다시 융합할 수 있습니다 이 방식은 배포 및 공유에 특히 유용한데 배포하고 사용하기 쉬운 단일 개별 독립 모델이 만들어지기 때문입니다
융합 과정에서 어댑터가 원래 가중치와 결합되면서 아키텍처 및 매개변수 수는 사전 학습 버전과 동일하면서 역량이 업데이트된 모델이 완성됩니다 외부에서 보면 다른 모델과 마찬가지로 동작하지만 세부 조정된 지식이 내장되어 있는 상태입니다
어댑터를 모델에 융합하려면 mlx_lm.fuse 명령을 사용합니다 이 명령은 융합된 가중치를 계산하고 지정된 경로에 결과를 저장하는 작업을 한 번에 수행하죠 수동으로 역양자화하거나 재양자화할 필요가 없습니다 MLX에서 자동으로 처리하고 학습 중에 사용된 것과 동일한 양자화를 보존합니다 새롭게 미세 조정한 모델을 다른 사람들과 공유하고 싶다면 이 또한 쉽습니다 Huggin Face 리포지토리 이름만 제공하면 융합된 모델이 업로드되어 사용할 준비가 됩니다 지금까지 Python으로 텍스트를 생성하고 대규모 언어 모델을 미세 조정했는데, MLX의 뛰어난 특징은 Swift에 동일한 간결성과 유연성을 준다는 거죠 Swift에서 MLX로 대규모 언어 모델을 쉽게 사용하는 방법을 보겠습니다
이것은 Swift에서 양자화된 Mistral 모델을 로드하고 텍스트를 생성하는 방법의 예시입니다 이 모든 것이 단 28줄의 코드로 가능합니다 먼저 MLX와 언어 모델 라이브러리를 가져옵니다 그리고 모델 컨테이너를 만듭니다 모델과 토크나이저에 대한 동시 접근을 안전하게 관리하는 액터죠 다음으로 입력을 준비합니다 프롬프트를 토큰화하여 모델이 이해할 수 있는 숫자 형식으로 변환합니다 마지막으로 생성 루프를 실행하고 결과를 인쇄합니다 앞서 Python에서 본 것처럼 작업 흐름과 기능이 동일하지만 이제 Swift에서 완전히 기본 사용할 수 있습니다 이제 앞서 Python에서 한 것처럼 모델과 나눈 여러 상호작용에서 발생한 대화의 내역을 유지하는 데 무엇이 필요한지 살펴보겠습니다 Swift에서는 몇 줄 더 추가하기만 하면 됩니다 핵심 아이디어는 동일한데 명시적으로 키 값 캐시를 만들어 여러 세대에 걸쳐 재사용할 수 있도록 해야 합니다 이 작업에는 단 한 줄의 추가 코드만 있으면 됩니다 복잡성이 늘어나지 않습니다 상호작용을 더 정확히 관리하고자 토큰 반복자도 사용하는데 이를 통해 키 값 캐스트를 직접 설정하고 세대를 단계별로 제어할 수 있습니다 이 설정 덕분에 Swift에서 멀티턴 대화와 고급 프롬프트를 처리할 수 있는 유연성이 확보됩니다 이 세션에서는 코드 또는 터미널 명령을 통해 MLX로 추론, 학습 및 양자화를 간편하게 수행하는 방법을 살펴보았습니다 상위 수준 언어 모델 API부터 이를 작동하는 Metal 커널까지 오늘 사용한 모든 것은 완전히 오픈 소스입니다 MLX는 C, C++, Python 및 Swift로 핵심 연산을 제공하며 Python 및 Swift의 고수준 API도 있어 스택 전체에서 유연성과 우수한 제어 기능을 선사합니다 덕분에 MLX는 Apple 하드웨어에서 언어 모델 및 머신 러닝 학습 흐름을 실행하는 데 독보적입니다 이제 다음으로 진행할 수 있는 단계를 살펴보겠습니다 MLX LM의 주요 기능 중 일부를 살펴보았는데요 이외에도 유용한 기능이 많습니다 분산 추론 및 학습, 학습된 양자화, 맞춤형 학습 루프 등 고급 기능에 대한 자세한 내용은 Apple 문서에서 확인 가능합니다 빠른 실습을 위해 MLX 및 MLX Swift 예제 리포지토리에 확산 모델을 통한 이미지 생성 음성 인식 및 전체 언어 모델 학습 등의 작업을 위한 즉시 실행 가능한 프로젝트가 준비되어 있습니다 자체 AI 응용 프로그램을 빌드하든 원리를 습득하고자 하든 클릭 몇 번이면 바로 시작할 수 있습니다 MLX와 대규모 언어 모델의 강력한 기능을 사용해 Apple 하드웨어에서 얼마나 멋진 경험을 만들어 내실지 정말 기대됩니다
-
-
1:12 - Running DeepSeek AI's model with MLX LM
mlx_lm.chat --model mlx-community/DeepSeek-V3-0324-4bit -
3:51 - Text generation with MLX LM
mlx_lm.generate --model "mlx-community/Mistral-7B-Instruct-v0.3-4bit" \ --prompt "Write a quick sort in Swift" -
4:35 - Changing the model's behavior with flags
mlx_lm.generate --model "mlx-community/Mistral-7B-Instruct-v0.3-4bit" \ --prompt "Write a quick sort in Swift" \ --top-p 0.5 \ --temp 0.2 \ --max-tokens 1024 -
4:48 - Getting help for MLX LM
mlx_lm.generate --help -
5:26 - MLX LM Python API
# Using MLX LM from Python from mlx_lm import load, generate # Load the model and tokenizer directly from HF model, tokenizer = load("mlx-community/Mistral-7B-Instruct-v0.3-4bit") # Prepare the prompt for the model prompt = "Write a quick sort in Swift" messages = [{"role": "user", "content": prompt}] prompt = tokenizer.apply_chat_template( messages, add_generation_prompt=True ) # Generate the text text = generate(model, tokenizer, prompt=prompt, verbose=True) -
6:24 - Inspecting model architecture
from mlx_lm import load, generate model, tokenizer = load("mlx-community/Mistral-7B-Instruct-v0.3-4bit") print(model) print(model.parameters()) print(model.layers[0].self_attn) -
8:01 - Generation with KV cache
from mlx_lm import load, generate from mlx_lm.models.cache import make_prompt_cache # Load the model and tokenizer directly from HF model, tokenizer = load("mlx-community/Mistral-7B-Instruct-v0.3-4bit") # Prepare the prompt for the model prompt = "Write a quick sort in Swift" messages = [{"role": "user", "content": prompt}] prompt = tokenizer.apply_chat_template( messages, add_generation_prompt=True ) cache = make_prompt_cache(model) # Generate the text text = generate(model, tokenizer, prompt=prompt, prompt_cache=cache, verbose=True) -
9:37 - Quantization
mlx_lm.convert --hf-path "mistralai/Mistral-7B-Instruct-v0.3" \ --mlx-path "./mistral-7b-v0.3-4bit" \ --dtype float16 \ --quantize --q-bits 4 --q-group-size 64 -
10:33 - Model quantization with MLX LM in Python
from mlx_lm.convert import convert # We can choose a different quantization per layer def mixed_quantization(layer_path, layer, model_config): if "lm_head" in layer_path or "embed_tokens" in layer_path: return {"bits": 6, "group_size": 64} elif hasattr(layer, "to_quantized"): return {"bits": 4, "group_size": 64} else: return False # Convert can be used to change precision, quantize and upload models to HF convert( hf_path="mistralai/Mistral-7B-Instruct-v0.3", mlx_path="./mistral-7b-v0.3-mixed-4-6-bit", quantize=True, quant_predicate=mixed_quantization ) -
13:37 - Model fine-tuning
mlx_lm.lora --model "mlx-community/Mistral-7B-Instruct-v0.3-4bit" --train --data /path/to/our/data/folder --iters 300 --batch-size 16 -
15:06 - Prompting before fine-tuning
mlx_lm.generate --model "./mistral-7b-v0.3-4bit" \ --prompt "Who won the latest super bowl?" -
15:34 - Fine-tuning to learn new knowledge
mlx_lm.lora --model "./mistral-7b-v0.3-4bit" --train --data ./data --iters 300 --batch-size 8 --mask-prompt --learning-rate 1e-5 -
15:48 - Prompting after fine-tuning
mlx_lm.generate --model "mlx-community/Mistral-7B-Instruct-v0.3-4bit" \ --prompt "Who won the latest super bowl?" \ --adapter "adapters" -
16:29 - Fusing models
mlx_lm.fuse --model "mlx-community/Mistral-7B-Instruct-v0.3-4bit" --adapter-path "path/to/trained/adapters" \ --save-path "fused-mistral-7b-v0.3-4bit" \ --upload-repo "my-name/fused-mistral-7b-v0.3-4bit" # Fusing our fine-tuned model adapters mlx_lm.fuse --model "./mistral-7b-v0.3-4bit" \ --adapter-path "adapters" \ --save-path "fused-mistral-7b-v0.3-4bit" -
17:14 - LLMs in MLX Swift
import Foundation import MLX import MLXLMCommon import MLXLLM @main struct LLM { static func main() async throws { // Load the model and tokenizer directly from HF let modelId = "mlx-community/Mistral-7B-Instruct-v0.3-4bit" let modelFactory = LLMModelFactory.shared let configuration = ModelConfiguration(id: modelId) let model = try await modelFactory.loadContainer(configuration: configuration) try await model.perform({context in // Prepare the prompt for the model let prompt = "Write a quicksort in Swift" let input = try await context.processor.prepare(input: UserInput(prompt: prompt)) // Generate the text let params = GenerateParameters(temperature: 0.0) let tokenStream = try generate(input: input, parameters: params, context: context) for await part in tokenStream { print(part.chunk ?? "", terminator: "") } }) } } -
18:00 - Generation with KV cache in MLX Swift
import Foundation import MLX import MLXLMCommon import MLXLLM @main struct LLM { static func main() async throws { // Load the model and tokenizer directly from HF let modelId = "mlx-community/Mistral-7B-Instruct-v0.3-4bit" let modelFactory = LLMModelFactory.shared let configuration = ModelConfiguration(id: modelId) let model = try await modelFactory.loadContainer(configuration: configuration) try await model.perform({context in // Prepare the prompt for the model let prompt = "Write a quicksort in Swift" let input = try await context.processor.prepare(input: UserInput(prompt: prompt)) // Create the key-value cache let generateParameters = GenerateParameters() let cache = context.model.newCache(parameters: generateParameters) // Low level token iterator let tokenIter = try TokenIterator(input: input, model: context.model, cache: cache, parameters: generateParameters) let tokenStream = generate(input: input, context: context, iterator: tokenIter) for await part in tokenStream { print(part.chunk ?? "", terminator: "") } }) } }
-
-
- 0:00 - 서론
MLX는 Apple Silicon에 최적화된 오픈 소스 라이브러리로, Mac에서 효율적인 머신 러닝을 구현합니다. GPU 가속을 위해 Metal을 활용하고 원활한 CPU-GPU 협업을 위해 통합 메모리를 사용합니다. MLX는 Python, Swift, C++, C를 지원합니다. Python 라이브러리이자 CLI 툴인 MLX LM은 Apple Silicon에서 대규모 언어 모델의 실행, 미세 조정, 통합을 간소화합니다. DeepSeek AI의 670B 매개변수 모델 등 최첨단 모델의 텍스트를 놀라운 속도와 성능으로 Mac에서 로컬로 로드하고, 상호작용하며, 생성할 수 있습니다.
- 3:07 - MLX LM 소개
MLX LM은 대규모 언어 모델을 실행하고 실험하기 위해 MLX 기반으로 구축된 Python 패키지입니다. 텍스트 생성 및 미세 조정을 위한 명령줄 툴과 Python API를 제공하며, Hugging Face와 통합하여 모델을 다운로드하고 공유할 수 있습니다. pip install mlx-lm을 통해 설치합니다.
- 3:51 - 텍스트 생성
MLX LM은 Hugging Face의 언어 모델이나 로컬에 저장된 모델을 사용하여 텍스트를 생성할 수 있는 도구입니다. 명령줄 툴 및 Python API 등 두 가지 주요 인터페이스를 제공합니다. 명령줄 툴을 사용하면 간단한 프롬프트와 기본 사용자 정의 옵션으로 텍스트를 생성할 수 있습니다. Python API는 더 많은 제어 기능을 제공하여 모델을 로드하고, 텍스트를 생성하며, 모델의 아키텍처를 검사 및 수정할 수 있습니다. Python API는 키-값 캐시를 통해 멀티턴 대화를 지원하여 중간 결과를 효율적으로 저장함으로써 시간과 계산을 절약합니다. 따라서 MLX LM은 여러 프롬프트에서 맥락을 유지해야 하는 챗봇, 가상 어시스턴트, 기타 대화형 애플리케이션을 구축하는 데 적합합니다.
- 8:42 - 양자화
모델 양자화는 머신 러닝 모델의 정확도를 낮춰 모델을 더 작고 빠르게 만드는 데 사용되는 기술로, 특히 더 작은 기기에 배포할 때 유용합니다. MLX는 양자화 API를 통해 이 과정을 단순화합니다. ‘mlx_lm.convert’ 명령을 활용하면 모델을 한 단계로 다운로드, 변환, 저장할 수 있습니다. 이 명령을 사용하면 세부적으로 제어할 수 있어 모델의 다양한 부분에 다양한 양자화 설정을 적용하여 품질과 효율성 간의 균형을 맞출 수 있습니다. 양자화된 모델은 MLX 내에서 추론이나 훈련에 즉시 사용하거나 Hugging Face를 통해 다른 사람과 공유할 수 있습니다.
- 11:39 - 미세 조정
MLX LM을 사용하면 코드를 작성하거나 클라우드로 데이터를 전송하지 않고도 Mac에서 로컬로 대규모 언어 모델을 미세 조정할 수 있습니다. 이 프로세스는 더 작은 도메인별 데이터 세트를 사용하여 범용 모델을 특정 도메인이나 작업에 맞게 조정합니다. MLX LM은 전체 모델 미세 조정과 저순위 어댑터 교육 등 두 가지 주요 미세 조정 방법을 지원합니다. 어댑터 교육은 더 빠르고, 가벼우며, 메모리 효율성이 높아 로컬 하드웨어에 이상적입니다. 모델, 데이터 세트, 교육 기간을 지정하여 단일 명령으로 미세 조정을 시작할 수 있습니다. 더욱 세밀한 제어를 위해 교육 구성 파일을 사용할 수 있습니다. 미세 조정 후 어댑터를 기본 모델에 다시 융합하여 쉽게 배포하고 사용할 수 있는 자체 포함형 업데이트 모델을 만들 수 있으며, 심지어 공유를 위해 Hugging Face 저장소에 업로드할 수도 있습니다.
- 17:02 - MLXSwift의 LLM
MLX는 대규모 언어 모델을 사용할 때 Swift에 간결성과 유연성을 제공합니다. 단 몇 줄의 코드만으로 양자화된 모델을 사용하여 텍스트를 로딩, 토큰화, 생성할 수 있습니다. 멀티턴 대화를 관리하려면 몇 줄만 추가해 키-값 캐시를 만들면 됩니다. MLX는 Apple 하드웨어에서 효율적인 머신 러닝 워크플로를 구현할 수 있도록 Python 및 Swift로 된 수준 높은 API와 함께 C, C++, Python, Swift로 된 오픈 소스 핵심 작업을 제공합니다.