-
在 Create ML 中训练声音分类模型
了解如何快速、轻松地创建能够对音频文件和实时音频流中的声音进行分类的 Core ML 模型。Create ML app 不仅让您能够训练和评估这些模型,还允许您使用 Mac 上的麦克风实时测试模型性能。通过新的 Sound Analysis 框架,在您的 app 中使用这些设备端模型。
资源
相关视频
WWDC22
WWDC21
WWDC19
-
搜索此视频…
(在Create ML中 训练声音分类模型)
早上好 我是Dan Klingler 我是Apple音效团队的一名 软件工程师 今天 我很高兴有机会能和你们聊聊 在Create ML中 训练声音分类模型
在我们开始之前 你可能想知道什么是声音分类 在你的app中有什么用处?
声音分类是一项录制一段声音 然后把它分类到不同的类别的技术
但仔细想一想 我们有很多种分类声音的方式
第一种是发声体 举个例子 我们有吉他或鼓的声音 不同的物件有不一样的声学特性 我们人类因此能分辨不同的声音
第二种声音分类的方式 是声音的源头 如果你有徒步过 或者在繁华城市中心 你能分辨出你周围声音的纹理 是非常不一样的 即使没有任何 脱颖而出的声音
第三种声音分类的方式 是声音的属性 或是声音的特性 举个例子 一个婴儿的笑声和哭声 都来自相同的源头 但是声音的特性却非常不同 它允许我们分辨出这些声音的不同
现在 作为app的开发者 你有不同的app 对于声音分类 你可能有 不同的使用场景
如果你能训练你自己的模型 为你的app量身定做 不是很棒吗?
现在使用Xcode中 的Create ML app 你就能做到了 这是训练声音分类模型最简单的方式
创建一个声音分类器 你需要为Create ML 提供标记过的声音数据 音频文件
接下来Create ML 就会用你自定义的文件 开始训练声音分类器模型
然后 你就能在你的app中 使用这个声音分类器
今天 我来用一个例子 向你展示如何实现
首先 我将打开 Create ML app 它是Xcode中附带安装的
我们将会创建一个新的文件
从模板选择中 选择“声音”
点击“下一步” 将我们的项目取名为 MySoundClassifier
保存这个项目 到我们的文档目录下
当Create ML app 开始运行时 你会看到主界面 左侧的输入标签被选中
为了训练我们自定义的模型 这是我们上传训练数据到 Create ML app的入口
你可以看到上方还有其他的标签 比如训练验证和测试 在训练的各个阶段 它们将为我们的模型 提供一些精确的统计数据
最后 我们可以在输出标签里 找到训练后的 模型 我们可以实时查看我们的模型
现在 我将开始训练一个乐器分类器 我带来了一些乐器
我有一个TrainingData文件夹 我们打开 这是我收集的一些声音文件
举个例子 它们包括 吉他 牛铃和振动筛
为了训练我们的模型 我们只需 将文件夹直接拖到 Create ML里
Create ML检测出 我们今天将会使用的声音文件 一共有49个 有7种不同的类别
我们点击“训练”按钮 我们的模型开始训练了 Create ML在训练模型时 首先会做的事情是 扫描我们上传的每个音频文件 检测出每个文件的声音特性 当它收集完所有的声音特性后 它会开始处理我们现在看到的 不断更新迭代模型的权重
模型的权重不断更新 你会看到性能表现不断被优化 精准度达到了100% 这是个好兆头 我们的模型正在收敛
我们今天收集的音频文件 特征都相当明显 比如牛铃和木吉他 听起来非常不同 所以我们训练的这个特殊模型 处理声音非常的成功 如你所见 训练和验证集合
测试面板是提供大数据集的好地方 你可以拿它作为基准参考 Create ML app 允许你同时训练多个模型 它同时提供了多个数据集 如果你想为你训练的 不同的模型结构提供一个常用基准 你可以使用测试面板
最后 我们来看Output标签 我们在用户界面能与我们的模型互动
现在 我有一个 在训练集没有的文件 我将它放到 TestingData文件夹 当我将文件夹拖入用户界面时 你能看到它扫描了这个文件 叫做分类测试
当我们滚动这个文件 Create ML 将第一秒识别为了背景噪音 接下来的几秒是讲话声 最后是振动筛
现在我们来看这个分类是否准确 我们能在这个界面听一下
测试 一 二 三
至少 它能准确的识别 我们上传的这个文件 现在 更棒的是 我们来用这个模型进行实时互动 为了实现目标 我们添加了一个按钮“录制麦克风”
只要我开始录制 我的Mac就会开始向模型 传入麦克风录制的声音数据
所以 你看 只要我一说话 模型就能高效的识别出说话声 当我安静时 模型则变为背景音状态
我带来了一些乐器 我现在弹奏它们 看模型能否识别 首先是振动筛
接下来是牛铃
更多牛铃 好吧 你们还想再听牛铃 来吧
接下来 是我的木吉他 我们同样来试一下
以单音节来开始
下面 我来试一下和弦
识别的非常完美 我觉得它很完美 现在我停止录制 在Create ML app里 我能回滚这段录音 查看之前已被识别的片段 我们来看一下是否有不准确的地方 或有误的地方 我们也可以在文件中截取片段 用作测试数据 来提高我们的模型 最后 我们很高兴看到模型优秀的表现 我们将模型拖到桌面 集成到我们的app里面 以上就是如何在Create ML app 训练声音分类器 不用一分钟 一行代码
在演示app里 当你收集你的训练数据时 有一些细节需要留意 第一个你需要注意的地方是 我如何在文件夹里收集数据
所有吉他的声音 都了放在Guitar的目录里 其他文件也是一样 比如鼓声和背景音
现在 我们来聊一下背景音类别
即便我们训练了乐器分类器 你还是需要留意 当没有乐器声音时 如果你只让你的模型识别乐器 但如果你给模型识别背景音 它并不知道有这种声音 所以 当你在训练一个声音分类器时 你需要为你的模型考虑多种状况 你需要将 背景音单独划分为一类
现在假设你有一个声音文件 这个文件最开始是鼓声 接着是背景噪音 随后是吉他的声音
如果你直接将它拖到 Create ML app里 它并不会是合适的训练文件 那是因为 这个文件包含了多个音乐类别
请记住 你必须使用标记的文件夹来训练模型 所以现在我们要做的事 将这个文件截取为三个文件 将它们命名为鼓 吉他和背景音
这样模型才会有良好的表现 当你训练模型时 你要这样分开它们
在收集音频数据时 你还需要注意
第一 你需要保证你收集的音频是 在真实世界存在的
你的app将在很多不同房间 和声音场景工作 你可以使用卷积技术 模拟不同的声音场景 或是不同的房间
另外一个重要的点是 是设备上的录音处理
你可能会检查AV音频会话模式 来为你的app的 录音处理 选择不同的模式 选择你app最匹配的模式 或是符合你收集的训练数据
最后一点 是要留意你的模型结构 这个声音分类器模型 它能很好地区分不同类别的声音 但它并不是很适合 用来训练所有的会话内容 有更好的工具来做这个任务 所以 你要确保选择了正确的工具
现在你有了ML模型 我们来讲一下如何 将它集成到你的app
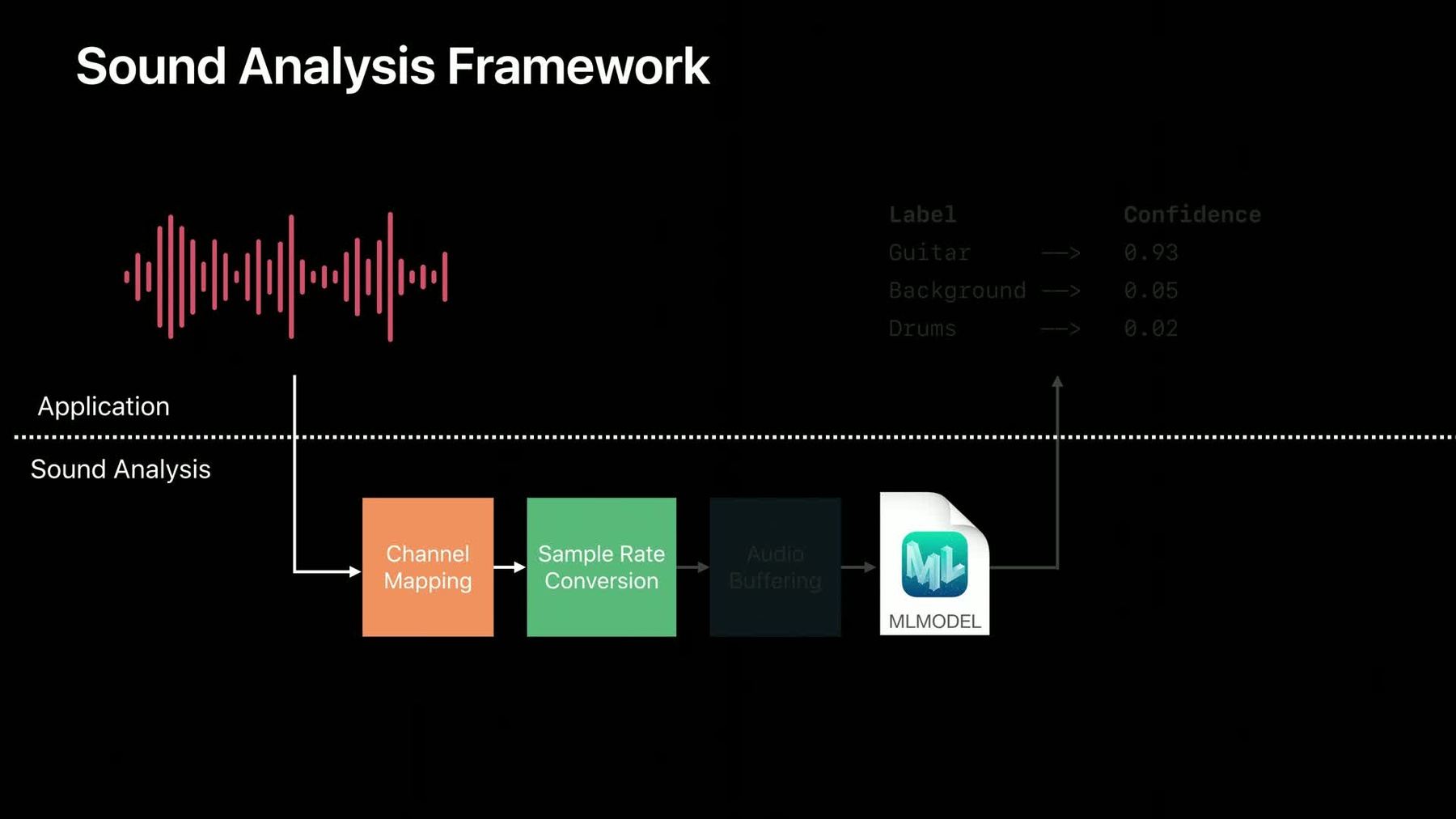
让模型能尽可能简单的 在你的app中发挥作用 我们发布了一个新框架 叫做SoundAnalysis
SoundAnalysis 是一个用来分析声音的高级框架
它使用了Core ML模型
它能在内部进行一些常用的声音操作 比如通道映射 采样率转换和后粘连
让我们在后台看一下 SoundAnalysis 是如何工作的 现在 上面的部分是你的app 下面是 SoundAnalysis 后台处理的流程
你要做的第一件事是 给SoundAnalysis框架 提供你用Create ML 训练后的模型
接着 你的app会提供 需要被识别一些音频
这个音频会先被通道映射处理 它能保证你的模型将会收到 一段音频 就像我们之前那样 传给模型一个音频 甚至在一个客户端 比如 你在上传一个立体音频数据
下一步是 采样率转换 我们训练的模型 适合处理16赫兹音频 这样能保证你提供的音频 会转化成模型想要的速率
最后一步是 SoundAnalysis 这是一个音频缓冲的操作
我们现在使用的大多数模型 需要一定量的音频数据来处理分析块 通常情况下 客户端里的音频 通常都会流进任意大小的缓冲区 要实现一个有效的循环缓冲区 需要很多工作量 来确保向你的模型传入 一个正确大小的音频块 如果你的模型需要大约一分钟左右的 音频文件 这一步能保证 传给模型的文件都是合规的 最后 当数据传给模型后 你的app将会收到包含关于音频 分类结果一个反馈
现在 好消息是 你并不需要知道所有的这些 你只需将音频提供给 SoundAnalysis框架 接着在你的app里 处理结果就可以了
那么 我们来聊一下 你从SoundAnalysis 获取的结果 音频是一个流媒体 它并不像图片一样 有开始和结尾 因此 这个结果可能和我们预想的有点不同
你的结果包含了一段时间 它和分析结果的音频时间相对应 在这个例子中 训练模型的块大小是被指定的 你能看到大约是一分钟
当你不断为模型提供音频时 你会不断收到包含 你分析的音频块的顶级分类结果
现在你可能留意到 这一秒的结果覆盖了之前的 大约50% 我们就是这样设计的
你要确定你提供的每个音频片段 都能出现在分析视图的中间 否则它会出现在分析视图左右两边 模型就不会正常发挥作用 所以 分析结果时默认是50%重合 但如果你有相应的使用场景时 在API中是可配置的
当你持续提供音频数据时 你会一直收到结果 只要音频流是有效的 你就能一直上传数据 然后得到结果
现在 我们来快速过一下 SoundAnalysis框架 提供的API
假设我们有一个音频文件 我们想要用今天 训练的模型来分析它
首先 我们创建了一个音频文件分析器 将文件的URL提供给分析器
接着 我们创建了一个 classifySoundRequest 接着实例化一个模型 MySoundClassifier
接着 我们向分析器提出请求 提供一个观察器 它会处理我们模型产出的结果
最后 我们来分析文件 它会先扫描文件然后处理结果
现在 在你的app那一侧 你需要确保你的一个类 符合SNResultsObserving协议 这就是你会从框架收到的结果
你要实现的第一个方法是 请求didProduce结果
这个方法可能会被调用很多次 只要当新的监测可用时
你就有可能获取到 顶级分类结果 和与之相关的时间范围 这就是你app中处理声音分类 事件时运行的逻辑
另外一个你可能感兴趣的方法是 请求 didFailWithError 如果由于某种原因分析失败了 这个方法就会被调用 接下来 你将不会从 分析器收到任何结果了 或者这个流媒体被成功处理了 比如 在文件的最后 你会收到 请求didComplete
下面 我们来做一下今天的总结
你知道了如何在Create ML 使用你自己的音频数据 来训练声音分类器
以及 在设备中 使用SoundAnalysis 框架来运行模型
了解更多信息 可以在developer.apple.com 查看声音分类的文章 你会在文章中找到一个 使用设备内置的麦克风 和AV音频引擎 来进行声音分类的例子 和之前大家看到的乐器分类 演示app类似
感谢聆听 希望大家都能在app中 使用声音分类
-