-
Training Sound Classification Models in Create ML
Learn how to quickly and easily create Core ML models capable of classifying the sounds heard in audio files and live audio streams. In addition to providing you the ability to train and evaluate these models, the Create ML app allows you to test the model performance in real-time using the microphone on your Mac. Leverage these on-device models in your app using the new Sound Analysis framework.
Resources
Related Videos
WWDC22
WWDC21
WWDC19
-
Search this video…
Good morning. My name's Dan Klingler. And, I'm a software engineer on the audio team here at Apple. And, today I'm really excited to talk to you about training sound classification models in Create ML.
So, before we start, we might want to ask the question what is sound classification, and how might it be useful in your application? Sound classification is the task of taking a sound, and placing it into one of many categories. But, if you think about it, there are many different ways that we can categorize sound.
One way might be to think about the object that makes the sound. So, in this example, we have the sound of guitar, or the sound of drums. And, it's really the acoustical properties of that object which are different, and allow us as humans to disambiguate these sounds.
But, a second way we could think about sound classification is where the sound comes from, and if you've ever gone on a hike, or been in the middle of a busy city, you'll understand that the texture of the sound around you is very different, even though there's not one particular sound that stands out, necessarily.
And, a third way we could think about sound classification, is by looking at the attributes of the sound, or the properties of the sound. And so in this example, a baby's laugh versus a baby's cry. Both come from the same source, but the properties of the sound are very different. And, this allows us to tell the difference between these sounds.
Now, as app developers, you all have different apps, and you might have your different use case for sound classification.
And, wouldn't it be great if you could train your own model, tailor-made for your own application's use case? And, you can do that today using the Create ML app, which is built right into Xcode. This is the simplest way to train a sound classifier model.
To train a sound classifier, you'll first provide labeled audio data to Create ML, in the form of audio files.
Then, Create ML will train a sound classifier model on your custom data. And then, you can take that sound classifier, and use it right in your application. And, I'd love to show you this process in action today, with a demo.
So, to start, I'm going to launch the Create ML app, which you can find bundled with your Xcode installation.
We're going to be creating a new document, and select Sound from the template chooser.
We'll click Next, and name our project MySoundClassifier. Let's save this project to our Documents directory.
Once the Create ML app launches, you'll see this home screen, and the Input tab is selected on the left.
This is where we'll provide our training data to the Create ML app, in order to train our custom model.
You'll see some other tabs across the top here. Like Training, Validation, and Testing. And, these allow us to view some statistics on the accuracy of our model for each of these stages of training.
And, finally, the Output tab is where we'll expect to find our model after it's been trained. And, we can also interact with our model in real time.
Now, today, I'm going to be training a musical instrument classifier. And, I've brought some instruments with me that we can try. I have a TrainingData directory that we can open, and take a look at some of the sound files I've collected. These contain recordings from an acoustic guitar, for example, or cowbell, or shaker. To train our model, all we need to do is drag this directory straight into Create ML. Create ML has figured out that we have a total of 49 sound files we're going to be using today. And, that spans 7 different classes.
All we need to do is press the Train button, and our model will begin training.
Now, the first thing Create ML is going to be doing when training this model is walking through each of the sound files we provided, and extracting audio features across the entire file. And, once it's collected all these audio features, it will begin the process you're seeing now, which is where the model weights are updating iteratively.
As the model weights are updating, you can see that the performance is increasing, and our accuracy is moving towards 100%, which is a good sign that our model is converging.
Now, if you think about the sounds we've collected today, they're fairly distinct, like cowbell and acoustic guitar sound fairly different. And so, this particular model we've trained is able to do a really good job with the sounds, as you can see, on both the training and the validation sets. The testing pane is a good place to provide a large data set that you might have for benchmarking.
The Create ML app allows you to train multiple models at the same time. And, potentially provide different sets of training data. And so, the testing pane is a great place if you want to provide a common benchmark for all those different model configurations you're training.
Finally, as we make our way to the Output tab, you'll see a UI that shows how we can interact with our model. Now, I've collected one other file that I didn't include in my training set. And, I've placed this in the TestingData directory. When I drag that directory into the UI, you can see it recognizes a file called classification test.
As we scroll through this file, it appears that Create ML has classified the first second or so of this file as background noise. Then, speech for the next couple seconds, and finally shaker.
But, let's find out if we agree with this classification. And, we can listen to this file right here in the UI. Test, 1, 2, 3. So, it seems at least on the file that we've collected, that this model seems to be performing reasonably. Now, what would be even better, is if we could interact with this model live. And, to do that, we've added a button here that has Record Microphone. And, once I begin recording, my Mac will begin feeding the built-in microphone data into the model we've just trained. So, what you can see is, anytime I'm speaking, the model's recognizing speech with high confidence. And, as I quiet down, you can see the model settle back down into a background state. And, I brought a few instruments with me so that we can play along and see if the model can recognize them. Let's start with a shaker. I've also brought my trusty cowbell. More cowbell! Well, the people have spoken. More cowbell. There you have it. And, I also brought my acoustic guitar with me here today, so we can try some of this as well.
I can start with some single-note lines. And then, we can try some chords as well. So, that seemed to be working pretty well, and I think that's something we can work with. So, I can stop the recording now. And, in the Create ML app, I'm able to scroll back through this recording, and take a look at any of the segments that we've been analyzing so far.
This might be a great place to check if there are any anomalies, or things that it didn't get correct, and maybe we can clip some parts of this file to use, as part of our training set to improve the performance of our model. And, finally, when we're happy that our model is performing the way we'd like, we can simply drag this model to our desktop, where we can integrate it into our application.
And, that's training a sound classifier in the Create ML app in under a minute, with zero lines of code. So, you saw during the demo, there's some things to consider when collecting your training data.
And, the first thing you'll notice is how I collected this data in directories.
All the sounds that come from a guitar are placed in the Guitar directory. And, likewise with a file like Drums or Background. Now, let's talk about the background class for a minute.
Even though we're training a musical instrument classifier, you still need to consider what might happen if there's not any musical instruments being played, and if you only trained your model on musical instruments, but then fed it background data. That's data it's never seen before. And so, make sure that when you're training a sound classifier, if you expect your model to work in situations where there's background noise, to provide that as part of the class as well.
Now, suppose you had a file that was called sounds. And, the file started at the beginning with drums, and then transitioned to background noise, and then finally ended with guitar.
This file, as is, is not going to be useful for dragging directly in the Create ML app. And, that's because this sound contains multiple sound classes in one file.
Remember, you have to use labeled directories to train your model, and so the best thing to do in this situation would be to split this file into three, and name them drums, guitar, and background. This is going to have a lot better performance when training your model, if you split your files this way.
A few other considerations when collecting audio data.
First, we want to insure that the data you're collecting matches a real-world audio environment. So, remember that if your app is intended to work in a variety of rooms or acoustic scenarios, you can either collect data in those acoustic scenarios, or consider even simulating those rooms, using a technique called convolution.
Another important thing to consider is the on-device microphone processing. You might check out AV audio session modes to select different modes of microphone processing in your application, and select the one which is best suited for your app, or potentially matches the training data you've collected. And a final point, is to be aware of the model architecture. So, this is the sound classifier model, and it can do pretty well at classifying varieties of sounds. But, this is not something that would be suitable for, say, training a full-on speech recognizer. There are better tools for that job. So, make sure you're always using the right tool for the job.
So, now you have this ML model, and let's talk about how you can integrate it into your application.
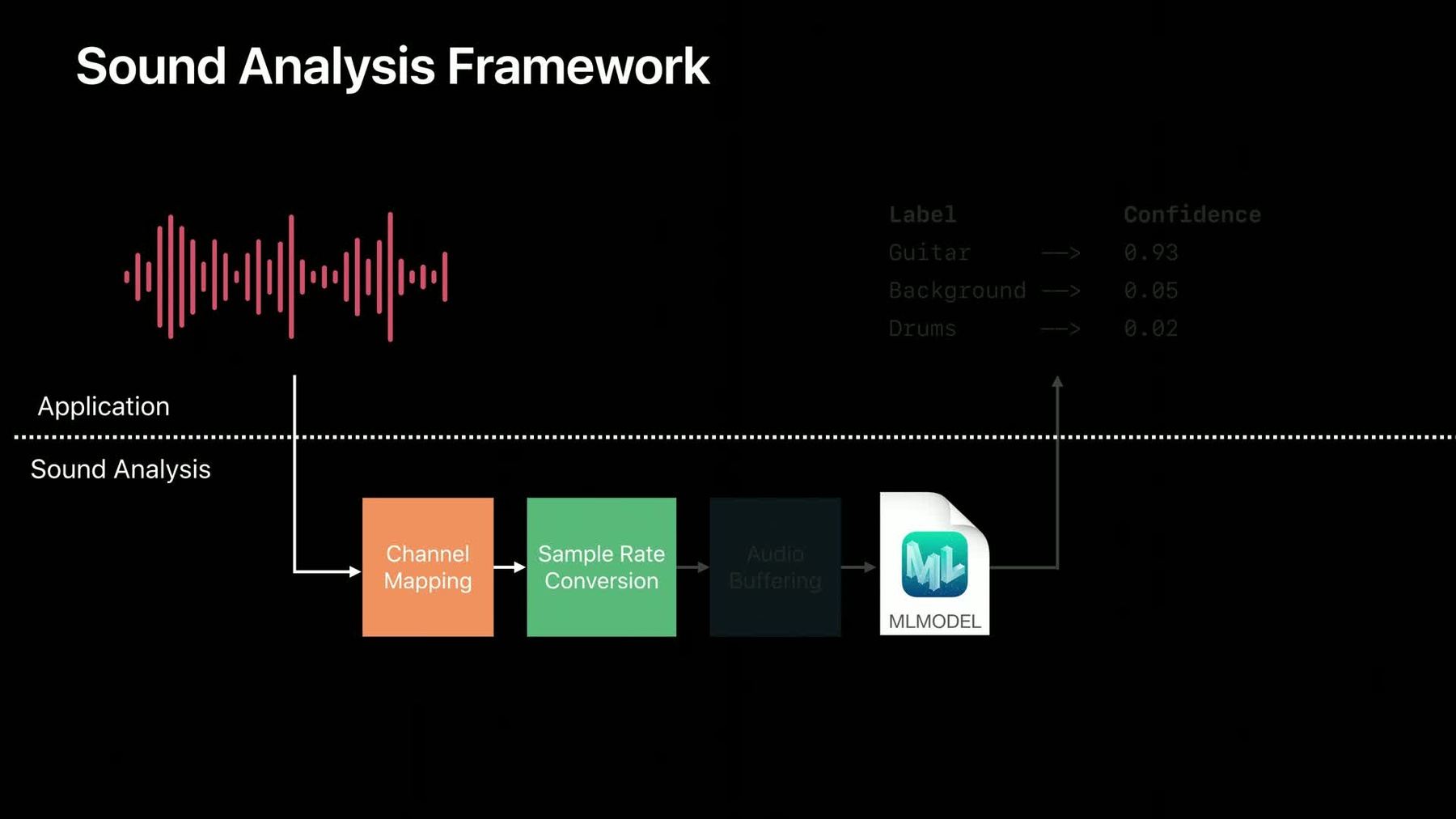
And, to make it as easy as possible to run sound classification models in your app, we're also releasing a new framework called SoundAnalysis. SoundAnalysis is a new high-level framework for analyzing sound. It uses Core ML models, and it handles common audio operations internally, such as channel mapping, sample rate conversion, or reblocking.
And, let's take a look under the hood to see how SoundAnalysis works. Now, the top section represents your application. And, the bottom represents what's happening under the hood in SoundAnalysis. The first thing you'll do is provide the model you just trained using Create ML to SoundAnalysis framework.
Then, your application will provide some audio that needs to be analyzed.
This audio will first hit a channel-mapping step, which ensures that if your model expects one channel of audio, like ours did here, that that's what's delivered to the model, even as a client, if you're delivering stereo data, for example.
The next step that happens is called sample rate conversion. The model we trained natively operates on 16 kilohertz audio data. And, this ensures that the audio that you provide gets converted to match the rate the model expects.
The final step that SoundAnalysis performs is an audio buffering operation.
Most of the models we're working with today require a fixed amount of audio data to process an analysis chunk. And, oftentimes, the audio that you have as a client might be coming in at arbitrary sized buffers. And, it's a lot of work to implement an efficient ring buffer that makes sure to deliver the correct size chunks of audio to your model. And so, this step ensures that if the model expects around 1 second of audio data, that that will always be what's delivered to the model. And then, finally, after the data's delivered to the model, your app will receive a callback, containing the top classification results for that piece of audio. Now, the good thing is, you don't really have to know any of this. Just remember to take your audio, provide it to SoundAnalysis framework, and then handle the results in your application.
So, let's talk a little bit more about the results you'll expect to get from SoundAnalysis.
Audio is a stream, and it doesn't always have a beginning and end, like images do. And, for this reason, the results that we're working with might look a little different. Your results contain a time range, and this corresponds to the block of audio that was analyzed for that result. In this example, the block size is specific to model architecture, and is around 1 second, as you can see.
As you continue providing audio data to the model, you'll continue to receive results containing the top classifications for that block of audio that you analyzed.
Now, you might notice that this second result has overlapped the previous results by about 50%. And, this is actually by design.
You want to make sure that every piece of audio that you're providing has the opportunity to fall near the middle of an analysis window. Otherwise, it might fall between two analysis windows, and the model performance might not be as good. And so, the default is 50% overlap on the analysis, although it's configurable in the API, if you have a use case that requires otherwise.
And, as you continue providing audio data, you'll continue to receive results. And, you can continue pushing this data, and getting results for as long as the audio stream is active.
Now, let's take a quick look at the API provided by SoundAnalysis Framework.
Let's say we have an audio file, and we want to analyze it using the classifier we've just trained here today.
To start, we'll create an audio file analyzer, and provide the URL to the file we'd like to analyze.
Then, we'll create a classifySoundRequest, and then instantiate MySoundClassifier, which is the model we trained here.
Then, we'll add this request to our analyzer, and provide an observer, which will handle the results that the model will produce.
Finally, we'll analyze the file, which will start scanning through the file and producing the results.
Now, on your application side, you'll need to make sure that one of your classes implements the SNResultsObserving protocol. This is how you'll receive results from the framework.
The first method you might implement is request didProduce result. This method will be called many times, potentially. Once for each new observation that's available. You might consider grabbing the top classification result, and the time range associated with it. And, this is where the logic would go in your application, to handle the sound classification event.
Another method you'll be interested in is request didFailWithError. If analysis fails for any reason, this method will be called. And then, you shouldn't expect to receive any more results from this analyzer.
Or, if the stream completes successfully, at the end of the file, for example, you'll receive the request didComplete.
So, let's recap what you've seen today.
You saw how you can train a sound classifier in Create ML using your own audio data. And, take that model and run it on-device using SoundAnalysis framework.
For more information, check out our sound classification article on developer.apple.com. And, there you'll find an example of how to perform sound classification on your device's built-in microphone, using AV Audio Engine, just like the musical instrument demo you saw earlier.
Thank you all for listening, and I can't wait to see how you use sound classification in your applications. [ Applause ]
-