-
Core ML 3 框架
Core ML 3 现在支持设备端机器学习之前从未能支持的高级模型类型。了解个性化模型如何为您的 app 带来绝佳的个性化机遇。更深入地了解将各种模型和改进链接到用于转换现有模型的 Core ML 工具的策略。
资源
相关视频
WWDC19
-
搜索此视频…
(CORE ML 3框架)
大家好 我是 Michael Brennan 我是Apple的一名工程师 致力于Core ML 今天能与大家一起分享 我们今年在Core ML 3中 引入的一些新功能 我感到万分激动
Core ML尽可能地简化了 把机器学习无缝集成到app的过程
可以让你创建多种多样的新奇 和引人注目的体验
而这一切的中心就是模型自身
你可以从许多所支持的训练库中 获得模型 通过使用我们作为 Core ML工具的一部分 所提供的转换器转换训练库来实现
通过添加新的 Create ML app 我们把获得模型的过程变得更简单了
(在设备上实现模型个性化) 在这场演讲中 我们要讲许多话题 从在设备上个性化模型 到我们对神经网络所添加的额外支持 等等
让我们先讲 在设备上个性化你的模型
从传统上说 这些模型要么与app绑定 要么下载到app 一旦你的设备上有了模型 模型就是完全可变的 并在你的app内针对性能进行了 大量优化
关于把你的app与模型相关联 最棒的是 这意味着你可以为所有用户提供 同样优秀的体验
但每个用户都是独一无二的
他们每个人都有自己的特别需求 他们自己的与app相交互的方式
我认为这为我们创造了一个机遇
如果每个用户都能得到一个 特别为他们个性化的模型怎么样?
嗯 让我们以一个用户为例 看看如何实现
我们可以获取那个用户的数据
设置一种云服务
向那个云服务发送用户数据 并在云内创建那个 针对用户数据个性化的新模型 然后再把模型部署给用户
这给你们开发人员以及我们的用户们 带来了许多挑战
对你们而言 挑战是 使用这些云服务管理那种个性化服务 增加了费用 以及创建一个可以扩展到百万用户的 基础设施
对用户来说 很显然他们需要暴露他们的全部数据 他们并不想这样做 这有一定的侵入性 他们不得不暴露自己的数据 并把它发送到云上 而这些数据将由另一方进行管理
在Core ML 3上 你可以完全在设备上执行这种 个性化操作
获取具有用户所创建 或重新生成的数据的那个通用模型
你可以用那些数据 对用户个性化那个模型
这意味着数据将保持私密性 它永远不会离开设备
这意味着不需要服务器来执行 这种交互性
并且这还意味着你可以在任何地方 执行个性化操作 好吧 你不会仅仅为了要更新 用户的模型 而把用户束缚在Wi-Fi 或一些数据计划上 (模型剖析)
在我们继续讲之前 先深入了解一下其中一个模型 看看有什么变化
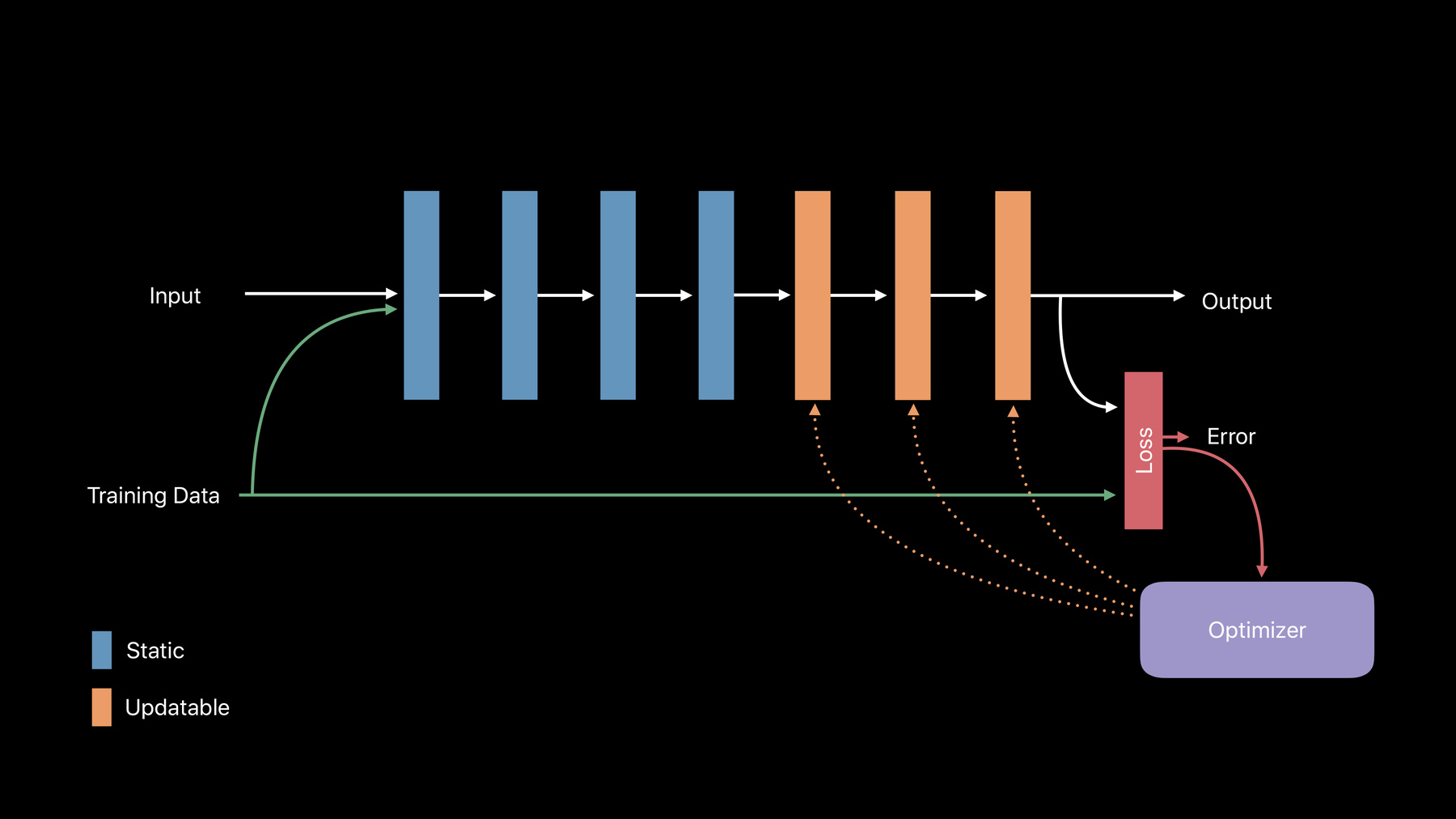
目前 你的模型主要由参数组成 一些诸如各层权重这样的东西 如果有神经网络的话 比如说 还有一些元数据 描述诸如许可证这样的东西 还有作者以及一个界面 这就是app自身所关注的地方 它描述了你如何与这个模型相交互
在Core ML 3上 我们添加了一组新参数 用于更新 这组新参数描述了模型的哪些部分 可以进行更新以及如何更新 我们添加了一个新的更新界面 你的app可以用于执行这些更新
这意味着可以通过那个界面 直接获取全部功能 我们压缩了大量细节 这些都包含在那一个模型文件中
因此就像是做预测一样 我们提供一组输入 你得到一组相应的输出
更新非常简单 你只需要提供一组训练样本 你就能得到那个模型的新版本 这个新版本是针对那些数据进行适应 或调整的
(所支持的模型类型) 对Core ML 3而言 我们支持给最近邻分类器 以及神经网络创建可更新的模型 并且我们还将支持在你的管道内 嵌入一个可支持的模型 意思是你的管道也变得可更新了
(演示 PRSONALIZED GRADING APP) 有了这些信息 我认为我们应该 在实际操作中具体看一下 因此我要把舞台交给 我同事Anil Katti Anil
谢谢Michael 大家好
今天我要演示如何使用模型个性化 为用户们创建自定义体验 为此我有一款app 它帮助老师们 给学生们的家庭作业评级 我使用模型个性化 给这个app添加了 一个很酷的新功能 但在我们讲这个功能之前 先看看这个app现在有什么功能 切换到演示屏
太棒了 这就是那款app 它叫做 Personalized Grading App 它可以让你获取家庭作业的一张照片 然后开始像老师在纸上评级一样 给家庭作业评级
你可以像这样标记为正确 或像这样标记为错误 非常直截了当 非常简单 这款app使用PencilKit 来捕捉输入 并预训练Core ML模型来识别 评级样本
最近我添加了一个新功能 可以让老师们为学生们提供一些 特别的东西以示鼓励
也就是贴纸
孩子们绝对喜欢收集 家庭作业上的贴纸 因此我认为这对于app来说 可能是个非常不错的改进 如果他们可以允许… 如果我们可以允许老师们提供贴纸
要给学生发贴纸 我可以轻触上边的这个加号按钮
滚动浏览贴纸列表 选择其中一个 把它拖动到正确的位置 并调整尺寸
就是这样
但我认为我们可以把这个流程 变得更好 让用户们也觉得非常神奇
让我们稍微思考一下
用户仅使用 Apple Pencil来评级 如果他们可以 在整个屏幕上的任意位置 快速地手绘一些东西是不是很酷 然后app会自动选择正确尺寸的 正确贴纸 并把它放在正确的位置上
嗯 我们绝对可以通过机器学习 来实现这个功能 对吗? 因此让我们思考一些可选方案 让我切换到幻灯片中 有些人已经用过Core ML了 你们可能在想 嗯 我们实际上可以预训练… 一个可以识别贴纸的模型 并把它发布为app的一部分 (使用预训练的贴纸模型?) 嗯 我们可以这样做 但是这种方法有几个问题 其一 app中有许多贴纸 我们可能需要收集大量训练数据 才能预训练这些模型
即使某个用户可能仅对 其中一小部分贴纸感兴趣
其二
如果我计划在将来引入一批新贴纸 这个预训练的模型该如何处理 那些新贴纸呢?
嗯 我可能得预训练模型 并通过app更新来发布它 或也许允许app下载它
最后 我认为这是最关键的点 这个预训练模型对于不同的用户来说 如何运作?
不同的用户有不同的手绘方式
如果我去外面要求一百个不同的人 快速手绘出这个漂亮的贴纸 我至少会得到50个不同的答案 真正让人震惊的是人们的个性 太不一样了 那么在这种情况下 app应该怎么做呢?
我们是否应该… app是否应该训练用户 如何进行手绘…
或用户是否应该训练app 以改善模型 识别你的手绘的方式?
嗯 这正是模型个性化所提供的功能
我要做的是使用模型个性化 和我从用户那里收集的用户数据 来训练… 来定义一个模型来满足他们的需要 让我演示一下那如何转化为用户体验 (用户可以训练模型)
我要切换到演示屏继续评级
第三个答案…第三个问题 对于幼儿园的孩子们来说非常棘手 但我认为Jane已经解决了 那个图解中有四个三角形 做得很好 Jane 嗯 现在我想给她发一个贴纸 鼓励她对细节的关注 但我想通过快速手绘来发贴纸 让我们试着做一下
app看起来告诉我说它不能识别 我的手绘 这很公平 因为这是我第一次使用这款app 让我试着添加一个贴纸 但这一次我想创建一个快捷方式 是的 我要选择我上次所使用的那个贴纸
现在app要求我提供一个样本 就是我会如何手绘这个特定的贴纸 它不一定非常完美 它甚至看起来也可以跟贴纸不一样 这只是我自己的表示 表示我想如何手绘那个贴纸 对吗? 因此我使用了一颗星来…
代表那个特定的贴纸
app要求我再提供几个样本 这也很公平 因为这只需要几秒钟 但现在看起来app… 快捷方式已经注册成功了 现在我在屏幕上看到了贴纸 以及我所提供的样本
在我返回之前 让我再向贴纸库中 添加一个贴纸
那儿有一个非常漂亮的“击掌”手势 我很想用这个 就在这儿
我在考虑我应该用什么来作为 它的快捷方式 我希望是一种容易记住的东西 很容易画出来的东西 数字五怎么样 从某种程度上来说可以代表“击掌”
太棒了 又提供了两个样本 我已经完成了
让我们返回到屏幕上 试着为绝望等待的Jane 发这个贴纸
那不是很酷吗?
我非常高兴我不必浏览贴纸选择器 并从那些乱糟糟的贴纸堆中 把贴纸移出来 太棒了 下一个问题 耶 这个也对了 让我再给她发一个小星星
我对这款app超级满意 在顶部贴一个大的“击掌”贴纸 那怎么样?
这只是一个例子 你们可以思考使用这个新功能 打造一些非常优秀的体验 在我结束之前 让我快速总结一下要实施这个功能 所需要采取的操作 (用户可以训练模型) 我要做的第一件事 是向项目中导入一个可更新的 Core ML模型 它在Xcode中看起来是这样的
因为我要通过添加新贴纸或类 来试着个性化这个模型 使用最邻近分类器很有道理
虽然那是个填充到最邻近分类器中的 预训练的神经网络功能提取器 用于帮助改善预测效率和稳健性
但这就是它 你不需要担心任何模型细节 因为Core ML 以这样的方式进行提取 从API界面提取全部模型细节
你可以使用这个模型进行预测 并不需要任何修改
Xcode中你会看到跟以前一样的 预测输入和输出
但今年的新功能是一个更新部分
描述一组输入 是这个模型用于 进行个性化所需要的一组输入 正如你所预期的那样 它需要一个灰度图像的贴纸 以及同样是灰度图像的相应的手绘 而相应的贴纸作为真正的标签 从而实现个性化
关于代码 你可以重调Core ML 自动生成一组类 用于帮助你进行预测 现在它生成新类 用于帮助你以自我方式提供训练数据
如果你看一下这个类 你会看到一组属性 与你在Xcode中 所看到的一致 对吗? 那么我们在这里看到了手绘和贴纸
一旦你从用户那儿收集到 用于个性化模型… 或用于为用户进行个性化的全部 训练数据 真正的个性化需要三个简单的步骤
第一 你需要获取 可更新的模型URL 你可以从捆绑包获取 或从已更新模型之前的快照中获取
接下来你要准备所支持格式的 训练数据 为此 你可以使用我所展示的原生类 或创建你自己的功能提供器
最后你要启动一个更新任务
一旦更新完成 就调用完成处理器 那会为你提供已更新的模型 你可以立即用于进行预测 就是如此简单 我已经迫不及待地想看到 你们使用这些功能 在你们的app和框架中会创建出 多么酷的功能 就这样 让我把舞台交还给Michael 讲一些更复杂的情境 和模型个性化 谢谢
好的 谢谢Anil
简单回顾一下 Anil刚给我们演示了 使用基础模型…
并尝试实现个性化体验 通过提供一些模型很容易接受的 绘画来实现 然后我们看到我们得到了怎样的输出
最初我们并没有得到很多
那是因为在内部 虽然我们已经预训练了神经网络 但它注入的是一个 实际上是空的K最近邻基类分类器 它没有可以进行分类的近邻
因此我们要更新它并给它提供 一些近邻 正如Anil给我们所展示的那样 我们获取训练数据 我们所选择的贴纸以及我们所绘制的 与贴纸相对应的绘画 然后我们把这些与我们的基础模型 一起 注入那个可更新的K最近邻基础模型 以完成更新任务
这就为我们提供了新版的模型
(用已更新模型进行预测) 这个新版本可以更可靠地识别 它的培训内容 从内部来说 唯一发生改变的 就是那个可更新K最近邻基础模型
(更新任务)
让我们看一下ML更新任务类 我们今年引入了这个类 用于帮助管理这些更新过程
因此它有一个与它相关联的状态 关于它处于哪个过程 并且它可以恢复或取消那个任务
要构建一个状态 你只需要传入 模型的那个基础URL和配置 以及训练数据即可
正如Anil所演示的那样 你还需要传入完成处理器
对于完成处理器 我们将在你完成更新任务后进行调用 并且它会给你提供一个更新情境 当你完成更新后 你可以用它来编写那个模型 对它进行预测 并查询任务的其它部分 那可以让我们得到一部分更新情境
在代码中 正如Anil所演示的 实施起来非常得直截了当 你只需要构建一个MLupdateTask 提供那个URL、 你的配置和你的完成处理器 在这里我们用于检查准确度 把模型保留在这个代码块的范围之外 并保存那个模型 这非常棒 用起来很不错 并且它让我们通过了这个演示 但如果是更复杂的用例怎么样呢 对吗? 如果是神经网络会怎么样? (可更新的神经网络) 嗯 最简单的神经网络只有几个层 每个层都有一些输入和一些权重 输入和权重结合使用创建一个输出
要调整那个输出 我们需要在这些层中调整权重 为此 我们需要把 这些层标记为可更新
我们需要一些方式来告诉它 输出偏离了多少 如果我们想要一个微笑脸 但我们却得到了一个“击掌” 我们需要对此进行修正 这要在我们的损失函数上实现 损失函数描述那个delta
最后我们需要把这个提供给我们的 优化器 优化器会获取那个损失 我们的输出 并算出实际上要在这些层中 调整多少权重
在Core ML 3上 我们支持卷积更新和完全… 完全连接的层以及通过更多层 进行反向传播 我们无条件支持交叉熵 和均方误差损失类型 此外我们还支持随机梯度下降 和Adam优化策略
这非常棒 对吗? 但还有其它与神经网络相关联的参数 比如学习速率 和要运行的epoch数 这些都要被封装在那个模型内
然而我们理解你们中有些人 想在运行时进行修改
你可以通过 覆盖更新参数字典 和模型配置在运行时进行修改 你可以通过使用MLParameterKey 和为其指定值 覆盖内部的值 我们给你们提供了很大的灵活度
(Xcode中的参数) 此外 如果你在考虑 我的模型内到底嵌入了多少参数 你可以在Xcode中查看 该模型视图的参数部分 将为你提供那些参数的值 以及该模型内到底定义了哪些参数
你可能想要更多的灵活度 而不仅仅是我们之前所演示的API 我们为你们提供灵活度
在你的MLUpdateTask中 你可以提供一个 MLupdateProgressHandler 而不是提供完成处理器 并提供进度处理器 而那个完成处理器 将允许你输入特定事件 因此当训练开始 或当epoch结束时 我们将调用你的进度处理器
并为你提供更新情境 就像我们在完成处理器中所做的那样
此外 我们还会告诉你是哪个事件导致 我们调用那个回调 并为你提供关键指标 从而你可以在处理 每一小批或每个epoch时 查询训练损失
在代码中 仍然是非常得直截了当 你构建这个 MLupdateProgressHandler 并告诉它你对哪些事件感兴趣 并提供一个它可以调用的代码块
此外 你还要提供完成处理器 和你刚刚用于 提供进度处理器的 MLUpdateTask
(后台中的CORE ML) 我们已经讲了如何更新模型 以及更新模型意味着什么 嗯 我们目前还没有真正讲到的是 何时适合更新
在我们之前演示过的评级app中 我们在他与app第二次交互 并绘制绘画时进行更新 我们获取那个数据并把它发送给模型
但那可能会不合适 如果你有数百万数据点会怎样? 如果你的模型极其复杂会怎样?
嗯 我对此感到很激动 我想说使用 BackgroundTask框架 将会给你的app 分配数分钟的运行时间 即使用户没有在使用你的app 或即使他们并没有与设备进行交互 你都可以使用BGTaskScheduler 并执行BGProcessingTaskRequest 我们将为你提供数分钟来执行 进一步的更新 和进一步的计算
要了解更多信息…是的
太棒了 要了解更多信息 我强烈推荐你们 查看“关于App后台执行的改进”
此外 你要如何获得可更新的模型? 嗯 我们之前讲过了 你可以通过 从许多所支持的训练库中转换模型 这并没有变
当你转化模型时 你只需要传入 可接受的可训练标志即可 它会获取那些可训练参数 比如你想采取哪种优化策略 哪个层可更新 我们会获取那些信息 并把它们嵌入到你的模型内 然后模型的其余部分与之前一模一样
如果你们想直接修改模型自身 我们也完全支持 (模型个性化概述) 我们讲了如何在app中 使用设备上的模型个性化 为用户创建更个性化的体验
你可以通过新的灵活但简单的 API来实现
非常棒 你完全可以在设备上实现 有了这些信息 我要把舞台交给我的同事 Aseem Wadhwa 她会讲我们今年针对神经网络 所添加的一些很棒的新功能 (神经网络)
好的
我感到非常激动… 我要讲的是今年Core ML中 有关神经网络的新功能
但在此之前 我想花几分钟笼统地讲一下神经网络
嗯 我们都知道神经网络致力于 解决具有挑战性的任务 比如了解图片内容或文档内容 或音频剪辑的内容
我们可以使用这个功能来创建一些 非常优秀的app
如果你深入了解一下神经网络 并查看它的结构 我们可能会更好地理解它
让我们来试一下 但我们不是从研究者的角度来看 让我们尝试从一个不同的视角来看 让我们从程序员的视角来看
如果你查看Core ML模型内部 我们所看到的类似一个图形
如果你再仔细查看 我们会意识到那个图形 只是程序的另一种表示 让我们再看一眼
这是我们都能理解的一个 非常简单的代码片段 这是与它相对应的图形表示 你可能已经注意到了 代码中的操作 就是图形中的这些注释 而可读取的比如X、Y、Z 就是图形中的这些边界 如果你返回去看神经网络图形
它现在显示的是相应的代码片段 看起来与之前的非常类似 但我要指出几个不同点
第一 我们现在所拥有的 不是那些简单的数字变量 而是这些多维变量 变量有多个参数 它可以有形状参数和排名参数 就是它所拥有的一些维度 第二件事是 操纵这些多维度变量的函数 现在变成了这些专业的数学函数 有时候也叫做层或操作
如果你真的看一下神经网络
我们会看到它实质上是一个图形 或一个程序 包含这些非常大的多维度变量 以及这些非常复杂的数学函数 从实质上说 它是要进行大量计算 和消耗大量内存的程序 关于Core ML 其中非常棒的一件事就是 它把全部这些复杂的东西都封装到 单个文件格式中 也就是Core ML框架 然后进行一些优化并非常高效地执行
因此如果我们返回去看 去年的Core ML 2 嗯 我们会很轻松地使用非循环图形 来表示直线式代码 我们大约有40种不同的层类型 通过这些层 我们可以表示绝大部分 常用的卷积架构 和循环架构
今年有什么新功能呢? 嗯 你可能已经注意到了 通过对程序的类比 我们都知道代码 会比简单的直线式代码复杂的多 对吗? 比如说 使用像分支这样的控制流很常见 如这段代码所示 在Core ML 3中 新功能是我们可以在神经网络规范内 表达同样的分支概念
另一种常见的控制流的形式 很显然是循环 我们也可以在Core ML网络内 轻松地表达循环 继续研究代码的另一个复杂特性
当我们编写动态代码时 经常会做的一件事 就是在运行时分配内存 如这段代码所示 我们正在按照程序的输入分配内存 从而可以在运行时改变内存的分配 今年我们可以在Core ML 实现同样的功能 通过动态层来实现 它可以让我们根据图形的输入 修改多数组的形状 你可能在想我们为什么 要在Core ML图形内 添加这些新的复杂的代码结构呢 答案很简单 因为神经网络研究正在积极地探索 这些想法 从而使神经网络变得更强大 事实上 许多最先进的神经网络 都内嵌了某种控制流
研究者们不断探索的另一个方面是 某种新操作 为此我们今年向Core ML中 添加了大量新层
我们不仅把当前层变得更通用了 我们还添加了大量新的基础数学运算 因此如果你遇到了一个新层 它很可能会 以Core ML 3中的层来表示
有了这些控制流功能、动态行为 和新层 Core ML模型 比以前更有表现力了 最重要的是 绝大多数流行的架构都可以轻松地 以Core ML格式表达 你可以从这张幻灯片上看到 我们列出了其中一些架构 突出显示的那些将在未来几个月实现 它们极大地推动了 机器学习的研究范围 现在你可以在Core ML中 轻松地表达它们 并把它们集成到app中 真是太棒了
(如何创建ML模型) 现在你可能在想 如何在Core ML模型内 利用这些新功能 嗯 答案是与去年一样 要创建一个Core ML模型 有两种方式可选 第一 因为Core ML是一个 开源Protobuf规范 我们总是可以使用任意编程语言 通过程序来指定模型
因此我们总是可以使用这个方法 来创建模型 但在绝大多数情况下 我们希望使用转换器来实现 它可以为我们自动创建模型 通过把图形从不同的表示转换为 Core ML表示来实现 让我们具体看一下这两种方法
在这里我要展示一个简单的神经网络 并演示如何使用Core ML工具 轻松地表达它 它是围绕Protobuf规范的 一个简单的Python包装器
我个人很喜欢这个方法 特别是当我转换一个我非常了解 其架构的模型时 如果我有一个可用的预训练的权重 这是一个很好的数据 就跟编号的数组一样
话虽如此 神经网络通常更复杂一些 我们最好是使用转换器 并且我们也有一些转换器 我们在GitHub上有一些转换器 通过这些转换器 你可以到达绝大部分机器学习框架 好消息是通过支持 Core ML 3规范 这些转换器也进行了更新 变得更强健了 如果你之前用过我们的转换器 你可能会遇到类似这样的报错信息 比如也许它在抱怨缺失一个层 或层中缺失一个属性 现在所有这些都会消失 因为我们更新了转换器 转换器可以充分利用 Core ML 3规范
(前面是一马平川)
那么我们已经讲了 许多幻灯片上的内容 现在是时候在实际操作中 了解一下模型了 为此我要邀请我朋友 Allen上台来
(问答APP) 谢谢 谢谢Aseem 大家好 我是Allen 今天我要给大家演示如何使用 Core ML 3中的新功能 把用于自然语言处理的最先进的 机器学习模型 引入到我们的app中
我喜欢阅读与历史相关的内容 无论何时当我遇到一些 与历史有关的有意思的文章时 我脑子里经常会浮现一些问题 我很想知道问题的答案 但有时我会很不耐烦 我不想阅读整篇文章 因此如果我可以创建一个app 可以扫描文档然后给出回答 不是很好吗? 我就开始用Core ML 3中的 新功能创建这个app 让我来给你们展示一下
好的 这就是我的app
你可以看到 它显示了一篇文章 是一个叫做NeXT的公司的历史
你可以看到 这篇文章很长 我当然没有时间通读一遍 而且我有一些相关的疑问 让我来问问这个app
试着问第一个问题
NeXT是由谁成立的?
Steve Jobs
好的 我想这是对的 让我再问一个问题
它的总部在哪儿?
加利福尼亚的红杉城
现在我还有一个非常感兴趣的问题 让我试一试
工程师们的工资是多少?
7万5千美元或5万美元
有意思
这不是很酷吗? 那么现在…
让我们更深入地看一下 看看app实际上做了什么
这款app的中心部分 是一个最先进的 机器学习模型 是Transformers的 Bidirectional Encoder Representation 这个名字很长 我们可以和其他研究者一样 把它简称为BERT模型 那么BERT模型是做什么的? 嗯 通常是… 它实际上是一个神经网络
可以实施多任务用于理解自然语言
但BERT模型内有什么?
有一些模块 这些模块内有什么?
有层 许多许多层
你可以看到 它非常复杂 但通过Core ML 3中的 新工具和新功能 我可以轻松地把这个模型 引入到我的app中
但首先问题是 我要如何得到这个模型? 嗯 你可以从我们的模型库网站上
得到模型
或你可以…如果你喜欢的话 如果你可以…你可以训练一个模型 然后再转换它
比如前几天的一个晚上 我用TensorFlow训练了 我的BERT模型 这是我工作区的一张截图 抱歉 我的工作区乱糟糟的 但要使用Core ML的新转换器 我需要把一个模型导入到 Protobuf格式…就是这里
然后我需要做的就是键入三行 Python代码
导入TF Core ML转换器 调用转换函数 然后保存为ML模型
你可以看到 把模型引入app中非常简单 但要让app执行问答操作 还需要几个步骤 我想具体讲一下 要使用QA模型 我需要准备一个问题和一段内容 然后把它们分开 作为不同的token 模型要预测的是 答案在段落中的位置 你可以把它看作是个荧光笔 就像你在演示中所看到的那样
然后我就可以开始创建我的app了 模型自身并不构成app 除此之外 我还利用其它框架的许多功能 来构建这个app 比如我使用语音框架的 speech-to-text API 把我的声音翻译为文本 我使用自然语言API帮助我创建 分词器 最后我使用AVFoundation的 text-to-speech API 为我播放答案的音频 这些组成部分都利用了设备上的 机器学习 因此使用这个app 不需要访问因特网
谢谢 想象一下有多少新想法 和新的用户体验可以引入到app中 到此结束 谢谢
好的 谢谢Allen
好的 在我们总结之前 我想再强调今年引入到 Core ML中的三个功能 我相信许多Core ML用户 一定会觉得非常有用
让我们先看第一个 额外更新
请想象一下幻灯片中所显示的 这个情境 假如我们有两个模型 可以区分动物的不同品种
如果你看一下内部 这两个模型都是管道模型 共享一个通用的功能提取器 这种情况经常发生 共享… 训练深度神经网络以获得功能很常见 并且那些功能可以注入到不同的 神经网络
实际上在幻灯片中 我们注意到我们在这两个管道内 使用了同一模型的多个副本 这很明显效率很低 为了提高效率 我们启动了一个新模型类型 叫做链接模型 如这里所示
请看 想法非常简单 链接模型就是 对已经引入app的模型的一个引用 这就把在不同模型中共享一个模型 变得非常简单了
我还可以把链接模型看作是 它就像是链接到一个动态库一样 并且它只有几个参数 其中包括它所链接到的模型的名称 以及搜索路径
这对于可更新的模型或管道来说 非常有用
让我们看下一个功能 (链接模型) 假如你有一个Core ML模型 接受图片作为输入 目前为止Core ML希望图片是 CVPixelBuffer格式 但如果你的图片来自不同的源 是不同的格式会怎么样? 在大部分情况下 你可以使用Vision框架 从而可以通过VNCoreMLRequest类 调用Core ML 这有一定的好处 Vision可以替我们处理 许多不同的图片格式 Vision也可以执行预处理 比如图片缩放和剪切等等
然而在某些情况下 我们可能会 直接调用Core ML API 比如当我们尝试调用更新API时
对于这些情况 我们发布了一些新初始化程序方法 如幻灯片所示 因此现在我们可以直接从URL 或CGimage获得一张图片
这应该使得在Core ML中 使用图片变得非常方便
继续讲我想强调的最后一个功能 在Core ML API中有一个类 叫做MLModelConfiguration 用于约束Core ML模型 可以在哪些设备上执行 比如默认值是“全部” 即全部计算机设备可用 包括神经引擎
现在我们向这个类中又添加了 一些选项
第一个是可以指定 模型可以在其上执行的 首选Metal设备 你可以想象一下 如你在Mac上运行Core ML 模型的话这非常有用 因为有许多不同的GPU 连接到Mac
我们所添加的另一个选项叫做 低精度累积
我们的想法是如果你的模型 在GPU上学习 但不是在float32中进行累积 而恰好是在float60中 现在这可以很大地提高 你模型的学习速度 但无论何时当我们降低精度时 一定要记得检查模型的准确度 准确度可能会下降或也可能不会下降 取决于模型类型 当你修改模型的精确度时 请总是要试验它的准确度 我强烈鼓励你尝试一下这个选项 看看是否对你的模型有帮助
好的 我们在这场演讲中 讲了许多内容 让我快速地总结一下
我们讲了 通过在设备上 更新Core ML模型 来为用户们打造个性化体验 有多么容易 我们讲了如何向我们的规范中 添加更多的功能 并且现在我们可以向app中 引入最先进的神经网络架构了 我们还讲了一些与GPU有关的 很便利的API和选项
这里有一些你可能会感兴趣 并且与本场演讲相关的演讲
谢谢大家
-