-
Core ML 3 Framework
Core ML 3 now enables support for advanced model types that were never before available in on-device machine learning. Learn how model personalization brings amazing personalization opportunities to your app. Gain a deeper understanding of strategies for linking models and improvements to Core ML tools used for conversion of existing models.
Resources
Related Videos
WWDC19
-
Search this video…
Hey, everyone. My name is Michael Brennan. I'm a software engineer here at Apple working on Core ML.
And I'm thrilled to be able to share with you some of the amazing new features we've introduced this year for Core ML 3.
Core ML makes it as easy as possible to seamlessly integrate machine learning into your application allowing you to create a wide variety of novel and compelling experiences.
At the center of all of this is the model itself. You can get a model from a number of supported training libraries by converting them using the converters we have as a part of our Core ML tools which we provide. And with the addition of the new Create ML app, we've made it even easier than before to get a model.
So in this session we're going to cover a number of topics from personalizing those models on device to additional support we've added for neural networks and even more.
So let's get started by talking a little bit about personalizing your models on-device.
Traditionally, these models are either bundled with or downloaded to your application. And once on your device are completely mutable being optimized heavily for performance within your app.
The great thing about associating a model with your app is it means you can provide the same great experience across all of your users. But each user is unique. They each have their own specialized needs, their own individual ways of interacting with your application.
I think this creates an opportunity. What if each user could get a model personalized specifically for them? Well, let's look at the case of one user on how to do this.
We can take data from that user, set up some sort of cloud service, send that data to that cloud service, and in the cloud create that new model personalized on that data which will then deploy back to that user.
This creates a number of challenges, both to you, the developers, and to our users.
For you, it creates the challenge of added expenses with making these cloud services managing that service and creating an infrastructure that could scale to million of users. And for the user, obviously they have to expose all their data. It's unwanted. It's invasive. They have to expose this and send it up to the cloud where it'll be managed by some other party. On Core ML 3, you can do this kind of personalization all on device.
Simply take that general model and with the data the users created or regenerated, you can personalize that model with that data for that user. This means that the data stays private. It never leaves the device.
This means there's no need for a server to do this kind of interactivity. And this means you can do it anywhere. You're not tying your users down to Wi-Fi or some data plan just to update their model.
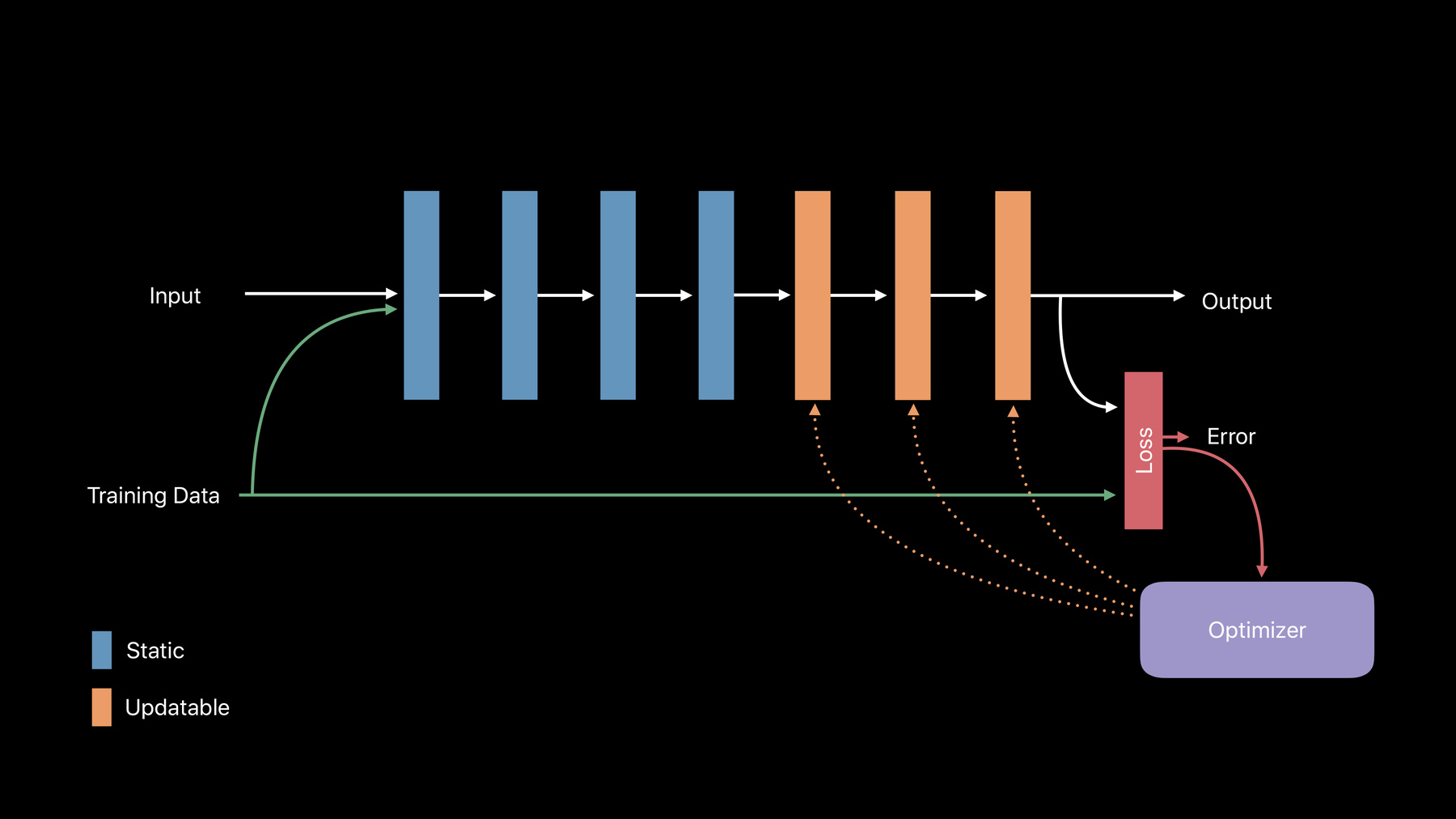
Before we continue, let's look inside one of these models and see what's there today. Currently, your model consists of mostly parameters, things like the weights of the layers if it's a neural network for example. And some metadata describing things like licensing and authors, as well as an interface. And this where your app concerns itself with. It describes how you can interact with this model.
On Core ML 3, we've added a new set of parameters to help updating. It describes what parts of the model are updatable and how it's updatable. We've added a new update interface your app can leverage to make these updates happen.
This means that all the functionality is accessed directly through that interface. We encapsulate away a lot of those heavy details and it's all contained within that one model file. So just like in making a prediction, we supply a set of inputs and you get a corresponding set of outputs.
Making an update is easy, you just supply a set of training examples and you'll get out a new variant of that model that was fit or fine-tuned to that data.
For Core ML 3, we support making updatable models of nearest neighbor classifiers as well as neural networks. And we're going to support embedding an updatable model within your pipeline, meaning your pipelines are updatable too. And with that, I think we should see this in action. So I'd like to hand it over to my colleague Anil Katti. Anil.
Thanks, Michael. Hello. Today I show how I build an experience that was customized for my users using model personalization. For this I have an app that helps teachers grade students' homework.
I added a cool new feature to this app using model personalization. But before we talk about the feature, let's see what the app does first. Let me switch over to the demo screen.
Great. So here's the app. It's called a Personalized Grading App. What it allows you to do is take a picture of the homework and start grading the way our teacher would on a sheet of paper.
You'd mark something as correct like that and something as wrong like that. It's pretty straightforward. Pretty simple. The app uses PencilKit to capture the input and the pretrained Core ML model to recognize the grading samples.
Now recently, I added a new feature that allows teachers give something special for the kids for encouragement.
And that is stickers.
Kids absolutely love collecting stickers on their homework. So we thought it might be a really nice enhancement to the app if they could allow-- if we could allow them to give stickers.
So to give a sticker, I could tap on this plus button up here. Scroll through the list of stickers, maybe pick one, and drag it to the right location . This works. But I think we can make the flow even better and absolutely magical for our users. Let's think about it a little bit.
The user is only using an Apple Pencil for grading. How cool would it be if they could quickly sketch something anywhere on the entire screen and the app automatically pick the right sticker of the correct size and place it at the right location for them. Well, we can definitely do something like that with machine learning, right? So let's explore some options. Let me switch over to the slides. Well, some of you who have already worked on Core ML might be thinking, well, we could actually pre-train a model that can recognize stickers and ship it as part of the app. Well, we could do that but there are a few issues with this approach. For one, there are a lot of stickers out there and we might have to collect a lot of training data in order to pre-train these models, although a particular user might only be interested in a small subset of these stickers. Second, how does this pretrained model work if I plan to introduce a bunch of new stickers in the future? Well, I might have to re-train the model and ship it as an app update or maybe allow the app to download it.
Lastly, and I think this is the most crucial point, how does this pretrained model work for different users? Different users have different ways of sketching.
If I went out and I asked a hundred different people to quickly sketch this mind-blowing sticker, I'll get at least 50 different answers. Now, it's truly mind-blowing how different people are. So what should the app do in this case? Should we-- Should the app train the users on how to sketch something, or should the users train the app, enhance the model how to recognize your sketches? Well, that's exactly what model personalization is all about. What I did was use model personalization to train-- to define a model using the data that I collected about the user-- from the user to suit their needs. Let me show how that translates to user experience.
I'll switch back to the demo screen to continue my grading.
So the third answer-- third question there is pretty tricky for kindergarten care, but I think Jane got it spot on. There are four triangles in that diagram. So, good job, Jane.
Well, now I want to give her a sticker to recognize the attention to detail, but I want to do it by quickly sketching something. Let's try doing that. So the app seems to tell me that it could not recognize what I sketch, which is pretty fair because this is the first time I'm using this app. So let me try to add a sticker, but this time I'll say I want to create a shortcut, right. And I'll pick the same sticker that I used last time.
So now the app is asking me to give an example of how I would sketch this particular sticker. It doesn't have to be perfect. It doesn't even have to resemble the sticker. It's just my own representation of how I would want to sketch that sticker, right? So I'll just use a single star to represent that particular sticker. The app asked me for a couple of more examples, which is pretty fair, and it just took a few seconds but now it looks like the app-- the shortcut has been registered. Now I see the sticker as well as examples I provided in the screen.
Before I go back, let me add one more sticker to my library.
So, there was this really nice high five sticker that I wanted to use, which is right here. I wonder what I should use as shortcut for this. I wanted-- I want something that is easy to remember, easy to sketch. How about the number 5, which kind of says high five? Great. So just two more examples and I'm done.
Let's go back to the screen and try giving that sticker that Jane has been desperately waiting for.
Isn't that cool? I'm so glad I didn't have the go through the sticker picker and move the sticker around and all those mess.
Great. For the next one-- yeah, that's right as well. So let me give another small star there.
I'm super happy with the way the app behaves, so a big high five at the top. How about that? So this was just an example. You guys can think about really amazing experiences that you can kind of solve using this new feature. So before I wrap up, let me quickly go with the things that I had to do in order to implement this feature.
So the first thing I had to do was import an updatable Core ML model into my project. And this is how it looks in Xcode.
Since I was trying to personalize the model by adding new stickers or classes, using the nearest neighbor classifier made a lot of sense, although that is a pretrained neural network feature extractor, that is filling in into the nearest neighbor classifier to help improve the prediction efficiency and robustness.
But that's it, you don't have to worry about any of model details since Core ML abstracts the way all the model details from the API surface.
You can use this model for prediction. There is no change there.
In Xcode you will see the prediction inputs and outputs like before.
But what's new this year is an update section.
This describes the set of inputs, yeah, this model requires for personalization. And as expected, it requires a sticker which is a grayscale image, and a corresponding sketch which is a grayscale image, and a corresponding sticker which serves as a true label in order to personalize.
In terms of code, you may recall that Core ML auto-generates a set of classes to help you with the prediction. And now it generates new class that helps you provide the training data in a manner.
If you peek into this class, you'll see a set of properties which are in line with what you saw in Xcode, right? So we see the sketch and the sticker here.
So once you have collected all the training data from the user that is required to personalize a model for-- or for the user, the actual personalization itself can happen in three easy steps. First, you need to get the updatable model URL that you could get either from the bundle or from a previous snapshot of the updated model. Next, you would prepare the training data in the expected format. For this, you could either use the origin rated class that I showed or build a feature provider of your own.
And lastly, you would kick off an update task. Once the update is complete, completion handler gets invoked which provides you the updated model that you can use for predictions immediately. It's that simple. I can't wait to see all the cool things that you will build on top of this in your apps and frameworks. With that, let me hand it back to Michael to recap and cover some more complex scenarios and model personalization. Thank you.
All right. Thanks, Anil.
So just a recap, Anil just showed us, we took our base model and we tried to make a personal experience out of that by supplying some drawings which were just beautiful to our model and seeing what we got as an output.
Initially, we didn't get much.
That's because internally, even though we have that pretrained neural network, it feeds into a K-nearest neighbor base classifier which is actually empty. It has no neighbors to classify on.
So we actually update this and give us some neighbors. Well, as Anil showed us, we took our training data, the stickers we chose and the drawings we drew to correspond with that, and we feed those along with our base model, with that updatable K-nearest neighbor base model in it to our update task.
And this gives us that new variant of our model.
And this new variant can more reliably recognize what it was trained on while internally the only thing that's changed was that updatable K-nearest neighbor base model. So let's look at the ML update task class, which we've introduced this year to help with managing these update processes.
So it has a state associated with it where it's at in the process as well as the ability to resume and cancel that task. And to construct one you just pass in that base URL for your model along with configuration and the training data. And as Anil showed, you need to pass in a completion handler as well.
As completion handler, we'll call when you're done with the update task and it gives you an update context. And you can use this to write out that model when you're done with your update, to make predictions on it, and query other parts of that task which allows us to get part of this update context. In code, as Anil showed us, really straightforward to implement. You just construct an MLupdateTask provided that URL, your configuration, and your completion handler, which here we use to check for accuracy, retain the model outside the scope of this block and save out that model. This is great. It works really well and it got us through this demo. But what about the more complex use cases, right? What about neural networks? Well, a neural network in its simplest case is just a collection of layers, each with some inputs and some weights that it uses in combination to create an output. To adjust that output, we'll need to adjust the weights in those layers. And to do that, we need to mark these layers as updatable. And we need some way of telling it by how much our output was off. If we expected a star smiley face and we got a high five, we need to correct for that. And that's going to be done to our loss functions, which describes that delta there.
And finally we need to provide this to our optimizer. And this takes that loss, our output, and it figures out by how much to actually adjust the weights in these layers. On Core ML 3, we support updating of convolution and fully collect-- fully connected layers as well as having the ability to back-propagate through many more. And we support categorical cross-entropy and mean squared error loss types.
In addition, we support stochastic gradient descent and Adam optimization strategies. This is awesome, right? But there's other parameters associated with neural networks, like learning rate and the number of epoch to run for.
This is all are going to be encapsulated within that model.
We understand that some of you may want to change that at runtime though.
And you can do that. By overriding the update parameters dictionary and your model configuration, you can override those values within, using MLParameterKey and just specifying values for them, giving you a lot of flexibility here.
In addition, if you're wondering what parameters are actually embedded within my model anyway, you can check out the parameter section of that model view in Xcode and it will give you details for the values of those parameters as well as what parameters are actually defined within that model.
You may want more flexibility than the API we showed earlier and we provide that.
In your MLUpdateTask, you can provide an MLupdateProgressHandler instead of the completion handler and supply progress handlers and that completion handler that will allow you to key in specific events. So when your training began or when an epoch ended, we'll call your progress handler and we'll provide you that update context just as we did in the completion handler.
In addition, we'll tell you what event caused us to call that callback as well as giving you key metrics, so you can query for your training loss as each mini batch or each epoch gets processed. And in code, still really straightforward. You construct this MLupdateProgressHandler, tell it what events you're interested in, and supply a block to be called. In addition, you'll just provide the completion handler there as well and the MLUpdateTask you just provide the set of progress handlers.
So we've talked about how to update your models and what it means to update them. Well, we haven't really discussed yet so far is when it's appropriate to do that.
Now, on the grading app we showed earlier, we're doing it the second he interacted with the app and drew a drawing. And we took that data and sent it off to the model. But that may not be appropriate. What if you have thousands or millions of data points? And what if your model's incredibly complicated? Well, I'm thrilled to say that using the BackgroundTask framework will allot several minutes of runtime to your application. Even if the user isn't using your app or even if they're not interacting with the device, you just use the BGTaskScheduler and make a BGProcessingTaskRequest and we'll give you several minutes to do further updates and further computations.
And to see more about this-- Yeah It's great. And to see more about this, I highly recommend you check out Advances in App Background Execution.
In addition, how do you get an updatable model? Well, as we talked about earlier in the session, you can get a model by converting them from a number of supported training libraries, that story has not changed.
You simply pass the respect trainable flag in when you're converting your model and it'll take those trainable parameters - the things like what optimization strategy you want, what layers are updatable -- and we'll take that and embed that within your model. And then the rest of it, it's just as what it was before. And for those of you who want to modify the model itself directly, that's still fully supported as well. So we've talked about how to make a more personal experience for a user in your application, using on-device model personalization, and you can do that through our new flexible yet simple API.
It's great. You can do this completely on-device. And with that, I'd like to hand it over to my colleague Aseem Wadhwa to tell you more about some of the amazing new features we've added this year for neural networks. OK. So I'm very excited to talk about what's new in Core ML this year for neural networks.
But before we jump into that, I do want to spend a few minutes talking about neural networks in general. Well, we all know that neural networks are great at solving challenging task, such as understanding the content of an image or a document or an audio clip.
And we can use this capability to build some amazing apps around them.
Now, if you look inside a neural network and try to see its structure, we can maybe get a better understanding about it.
So let's try to do that. But instead of looking from a point of view of a researcher, let's try a different perspective. Let's try to look at it from a programmer's perspective. So if you visualize inside a Core ML model, what we see is something like a graph. And if you look closely, we realize that graph is just another representation of a program.
Let's look at it again. So here is a very simple code snippet that we all understand. And here is its corresponding graph representation. So as you might have noticed that the operations in the code have become these notes in the graph and the readable such as X, Y, Z, are these edges in the graph.
Now, if you go back to a neural network graph and now show a corresponding code snippet, it looks pretty similar to what we had before. But there are a couple of differences I want to point out. One, instead of those simple numeric variables, we now have these multidimensional variables that have couple of attributes. So it has an attribute called shape and something called rank, which is a number of dimensions that it has. And the second thing is the functions operating on these multidimensional variables are now these specialized math functions, which is sometimes called as layers or operations.
So if you really look at the neural network, we see that it's essentially either a graph or a program that involves these very large multidimensional variables and these very heavy mathematical functions. So essentially it's a very compute and memory intensive program. And the nice thing about Core ML is that it encapsulates all these complexity into a single file format, which the Core ML framework and then sort of optimize and execute very efficiently.
So if we go back last year and see what we had in Core ML 2, well, we could easily represent straight-line code using acyclic graphs. And we had about 40 different layer types using which we could represent most of the common convolutional and recurrent architectures.
So what's new this year? Well, as you might have noticed with my analogy to program, we all know that code can be much more complex than simple straight-line code, right? For instance, it's quite common to use a control flow like a branch as shown in the code snippet here. And now, in Core ML 3, what's new is that we can represent the same concept of a branch within the neural network specification.
So another common form of control flow is obviously loops, and that too can be really easily expressed within a Core ML network. Moving on to another complex feature of code, something we do often when we're writing a dynamic code is allocate memory at runtime. As shown in this code snippet, we are allocating a memory that depends on the input of the program so it can change at runtime. Now we can do exactly the same in Core ML this year using what we call dynamic layers, which allows us to change the shape of the multi array based on the input of the graph. So you might be thinking that why are we adding sort of these new complex code constructs within the Core ML graph, and the answer is simple, because neural networks research is actively exploring these ideas to make even more powerful neural networks. In fact, many state of the art neural networks sort of-- have some sort of control flow built into them. Another aspect that researchers are constantly exploring is sort of new operations. And for that, we have added lots of new layers to Core ML this year. Not only have we made the existing layers more generic but we have added lots of new basic mathematical operations. So, if you come across a new layer, it's highly likely that it can be expressed in terms of the layers that are there in Core ML 3. So with all these features of control flow, dynamic behavior, and new layers, the Core ML model has become much more expressive than before. And the great part of it is that most of the popular architectures out there can now be easily expressed in the Core ML format. So as you can see on this slide, we have listed a few of those. And the ones highlighted have really come in the last few months and they're really pushing the boundaries of machine learning research. And now you can easily express them in Core ML and integrate them in your apps. So that's great.
So now you might be wondering that how do I make use of these new features within a Core ML model. Well, the answer is same as it was last year. There are two options to build a Core ML model. One, since Core ML is an open source Protobuf specification, we can always specify a model programmatically using any programming language of your choice. So that option is always available to us. But in the majority of the cases, we like to use converters that can automatically do that for us by translating a graph from a different representation into the Core ML representation. So let's look at both of these approaches a little bit in detail.
So here I'm showing a simple neural network and how it can be easily expressed using Core ML tools, which is a simple Python wrapper around the Protobuf specification.
I personally like this approach, especially when I'm converting a model whose architecture I understand well. And if I have the pretrained weights available to me in a nice data such as numbered arrays. Having said that, neural networks are often much more complex, and we are better off using converters and we have a few of them. So we have a few converters available on GitHub using which you can target most of the machine learning frameworks out there. And the great news is that with the backing of Core ML 3 specification, all these converters are getting updated and much more robust.
So, for some of you who have used our converters in the past, you might have come across some error messages like this, like maybe it's complaining about a missing layer or a missing attribute in the layer.
Now, all of this will go away as the converters are updated and they make full use of the Core ML 3 specification. So, we went through a lot of slides. Now it's time to look at the model in action. And for that, I'll invite my friend Allen.
Thank you. Thank you, Aseem.
Hi. I'm Allen. Today, I'm going to show you how to use the new features in Core ML 3 to bring state of the art machine learning models for natural language processing into our apps.
So, I love reading about history. Whenever I come across some interesting articles about history, I often have some questions on top of my head and I really like to get answers for that.
But sometimes I'm just impatient. I don't want to read through the entire article. So, wouldn't it be nice if I can build an app that scan through the document and then give the answers for me? So then I started out build this app with the new features in Core ML 3. And let me show you.
OK. So, here's my app.
As you can see, it shows article about history of a company called NeXT.
So, as you can see, this is a long article, and I certainly don't have time to go through it. And I have some questions about it. So let me just ask this app. Let's try my first question.
Who started NeXT? Steve Jobs. OK. I think that's right. Let me try another one. Where was the main office located? Redwood City, California Now I also have a question that I'm very interested in. Let me try that.
How much were engineers paid? Seventy-five thousand or $50,000 . Interesting. So, isn't this cool? So now, let's get deeper into it and see what the app really does.
So, the central piece of this app is a state of the art machine learning model called Bidirectional Encoder Representation from Transformers. And this is a very long name. So, let's just call it the BERT model as other researchers do.
So, what does BERT model do? Well, it is actually a-- it's actually a neural network that can perform multiple tasks for natural language understanding. But what's inside the BERT model? A bunch of modules. And what's inside these modules? Layers, many, many layers.
So you can see, it's rather complicated, but with the new features and tools in Core ML 3, I can easily bring this model into my app.
But first, the question is, how do I get the model? Well, you can get a model on our model gallery website, or you can-- if you like, you can train a model and then convert it.
For example, the other night I trained my BERT model with TensorFlow. And here is a screenshot of my workspace. Sorry for me being very messy with my workspace. But to use new Core ML converter, I just need to export a model into the Protobuf format right here.
And after that, all I need to do is to type three lines of Python code.
Import TF Core ML converter, call the convert function, and then save out as an ML model. So as you can see, it's rather easy to bring a model into the app. But to use the app for a question and answering, there are few more steps and I like to explain a little further. So to use the Q and A model, I need to prepare a question and a paragraph and then separate them as work tokens. What the model will predict is the location of the answer that's in the paragraph. Think of it as a highlighter as you just saw in the demo. So from there, I can start building up my app. The model itself does not make the app. And in addition to that, I also utilize many features from other frameworks that makes this app. For example, I use the speech-to-text API from speech framework to translate my voice into text.
I use natural language API to help me build the tokenizer. And finally, I use the text-to-speech API from the AVFoundation to play out the audio of an answer. So, all these components utilizes machine learning on-device, so that to use this app, no internet access is required.
Thank you. Just think about how much more possibility of new ideas and new user experience you can bring into our app. That's all. Thank you. OK. Thank you, Allen.
OK. So before we conclude the session, I want to highlight three more features that we added this year in Core ML that I'm sure a lot of Core ML users will find really useful. So let's look at the first one. So consider a scenario shown in the slide, let's say we have two models that classify different breeds of animal. And if you look inside, both these models are pipeline models that share a common feature extractor. Now this happens quite often. It's quite common to share-- to train deep neural network to get features and those features can be fed to different neural networks.
So actually in the slide, we note that we are using multiple copies of the same model within these two pipelines. Now this is clearly not efficient. To get rid of this inefficiency, we are launching a new model type called linked model, as shown here. So just see, the idea is quite simple. Linked model is simply a reference to a model sitting at desk. And this really makes it easy to share a model across different models.
Another way I like to think about linked model is it behaves like linking to a dynamic library. And it has only a couple of parameters. One, the name of the model that it's linking to and a search path.
So this would be very useful for-- when we are using updatable models or pipelines.
Let's look at the next feature. Let's say you have a Core ML model that takes an image as an input. Now as of now, Core ML expects the image to be in the form of a CVPixelBuffer. But what happens if your image is coming from a different source and it's in a different format? Now, in most of the cases, you could use the vision framework so you can invoke Core ML via the VNCoreMLRequest class. And this has the advantage that vision can handle many different formats of images for us, and they can also do preprocessing like image scaling and cropping, et cetera. In some cases, though, we might have to call the Core ML API directly, for instance when we are trying to invoke the update APIs. For such cases, we have launched a couple of new initializer methods, I showed on the slide. So now we can directly get an image from a URL or a CGimage. So this should make it really convenient to use images with Core ML. Moving on to the last feature I want to highlight. So there's a class in Core ML API called MLModelConfiguration. And it can be used to constrain the set of devices on which a Core ML model can execute. For example, the default value that the takes is called all which gives all the computer devices available including the neural engine.
Now we have added a couple of more options to this class. The first one is the ability to specify preferred metal device on which the model can execute. So as you can imagine, this would be really useful if you are running a Core ML model on a Mac which can have many different GPUs attached to it. The other option that we've added this called low precision accumulation. And the idea here is that if your model is learning on the GPU, instead of doing accumulation in float32, that happens in float60. Now this can offer some really nice speed enhancement for your model. But whenever we reduce the precision, always remember to check the accuracy of the model, which might degrade or not degrade, depending on the model type. So always try to experiment whenever you vary the precision of the model. So I would highly encourage you to go and try out this option to see if it helps with your model. OK. So, we talked about a lot of stuff in this session. Let briefly summarize it for you. We discussed how it's really easy to make a personalized experience for our users by updating the Core ML model on-device.
We discussed how we have added many more features to our specification and now we can bring the state of the art neural network architectures into our apps. And we talk about a few convenience APIs and options around GPU. Here are a few sessions that you might find interesting and related to the session. And thank you.
[ Applause ]
-