-
自定义设备上的语音识别
了解如何通过使用额外词汇自定义底层模型来改进 App 设备上的语音识别。我们将分享语音识别在设备上的工作机制,并向你展示如何增强特定单词和短语以获得更可预测的转录。了解如何为单词提供特定发音并使用模板支持快速生成一整套自定义短语 - 所有这些都在运行时进行。有关语音框架的更多信息,请查看 WWDC19 的“语音识别进展”讲座。
资源
相关视频
WWDC19
-
搜索此视频…
♪ ♪
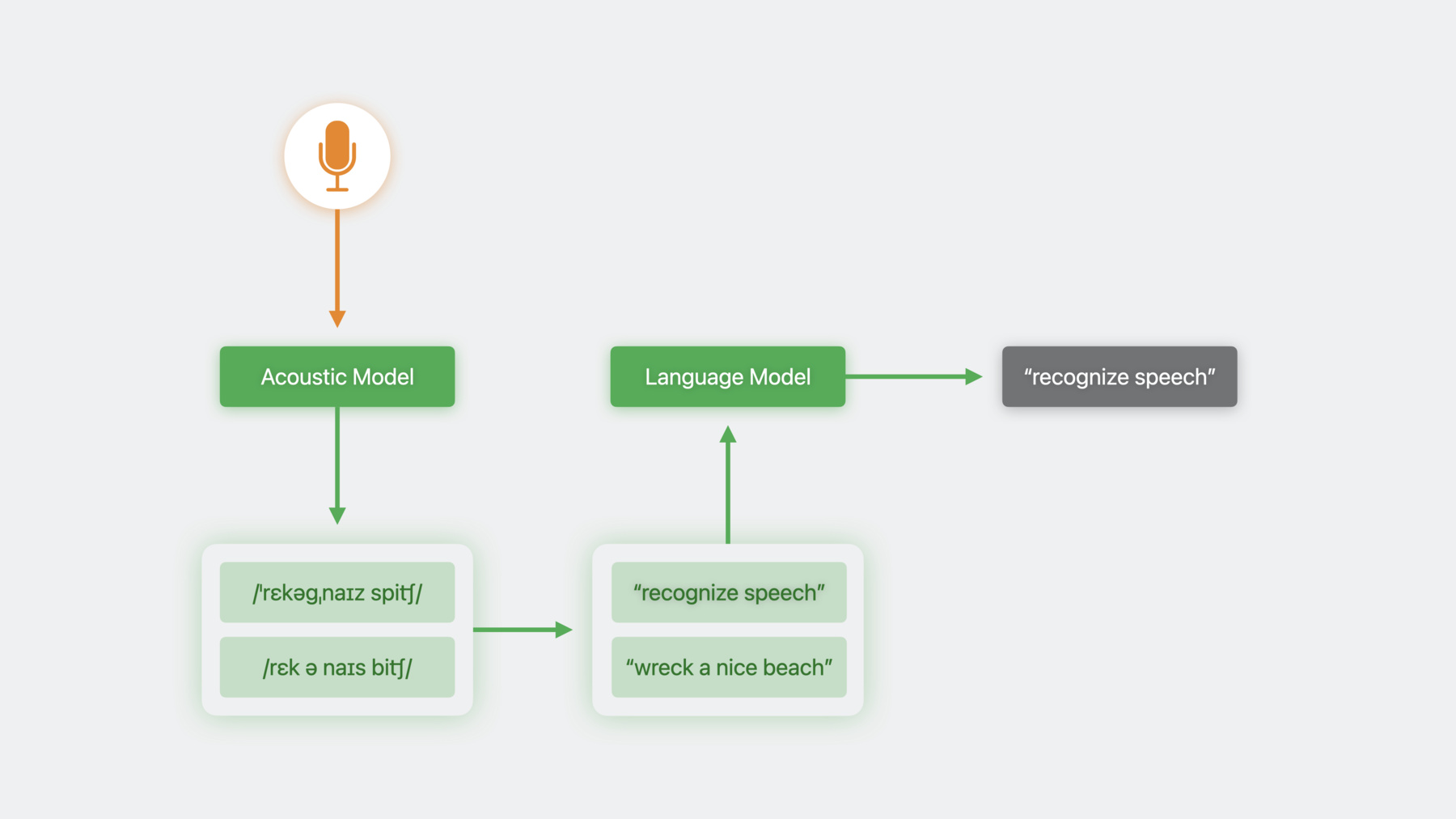
Ethan:大家好 我是 Ethan 来自 Siri Understanding 团队 在这儿为大家介绍 一些令人兴奋的语音识别的发展 我们在 iOS 10 中 就推出了语音框架 让你能够利用 支持 Siri 和键盘听写的 语音识别技术 用简单直观的界面 创建支持语音的 App 然而 开箱即用的语音识别器类 并不适用于所有的 App 我们先了解一下语音识别的 工作机制 才能解释其原因 语音识别系统先把音频数据 输入声学模型 其会产生一个音标 然后该音标会转换成文字形式 或者进行转录 有时会有多个音标 匹配这个音频数据 或者一个音标可能会对应多个转录 在这些情况下 我们最终会产生多个候选转录 并需要用一种方法来消除歧义 为此 我们使用了语言模型 语言模型预测了一个指定词语 在一连串词语中出现的可能性 把它应用于整个句子 我们就能感觉到 这个句子是否在胡说八道 基于训练期间接触到的使用模式 语言模型能帮我们 筛出那些不匹配的候选句子 自 iOS10 以后 语音框架已经封装了整个流程 来呈现一个易于使用的界面 让我们举个例子 来理解为什么这样做不理想 我喜欢下国际象棋 而且一直在开发一个象棋 App 这个 App 能让玩家口述自己的走法 和常见的开局和防御战术 这里 我的对手使用了经典的 Queen's Gambit 开局战术 我一直都在研究这个战术 想用 Albin counter gambit 对策走 E5
“使用 Albin counter gambit 战术”
啊 出问题了 识别器误把我的象棋走法 识别成了音乐请求 识别器使用的语言模型 在其训练过程中 接触了大量的音乐请求 所以它为类似的查询做好了准备 比如 “播放专辑” 后面跟着专辑的名字 相反 它可能从来 没接触过我首选的转录方式 通过抽象语言模型的行为 语音框架驱使所有的 App 都使用相同的模型 即使不同领域的 App 需要不同的行为 从 iOS17 开始 你就可以自定义 SFSpeechRecognizer 的语言模型的行为 你需要根据你 App 的情况 加以调整并提高其准确性
要开始自定义语言模型 首先要创建一个训练数据集 你可以在开发过程中创建该数据集 然后你要在 App 里准备数据 配置识别请求 然后运行这个请求
我们再来聊聊 构建训练数据集的过程 从较高的层面来看 训练数据由文本位组成 这些文本位 代表 App 用户可能会说的短语 这些训练数据 会让语言模型预期这些短语 并提高正确识别这些短语的可能性 若经常实验 我们就能惊讶地看到 识别器强大的识别能力 和随时间推移的改进速度 语音框架引入了一个新的类 充当训练数据的容器 这个类使用 结果生成器 DSL 构建而成 你可以使用 PhraseCount 对象提供 一个精确的短语或短语的一部分 PhraseCount 也可以描述这个样本 在最终数据集中出现的次数 我们可以根据这个 增加某些短语的权重 系统只能接受这么多数据 所以你要平衡好增加短语的需求 和整体的训练数据预算 你也可以利用模板 生成大量符合常规模式的样本 这里 我已经定义了三类词语 共同组成一个象棋的走法 移动的棋子兼作我的目标文件 国王和王后 界定在棋盘的哪一侧对弈 以及要移动到哪一个级别 把它们放在一起 形成一个模式 我们就可以轻松地生成 代表每一步可能走法的数据样本 这里 计数适用于整个模板 所以我们得到了 代表象棋走法的 10,000 个样本 均等地分配给所有产生的数据样本 建立好数据对象后 把它导出到一个文件里 然后像部署其他资源一样 将其部署到 App 里
如果你的 App 使用了专业术语 比如 一个含有药品名称的医疗 App 你可以定义这些术语的拼写和发音 并提供短语计数 显示它们的使用情况 发音使用了 X-SAMPA 字符串形式 每个 locale 都支持一个 独特的发音符号子集 请参阅文件 了解全套 locales 和受支持的符号 我希望确保我 App 的识别器 能够识别瓦纳尔变例 这是法兰西防御的一个常见变体 我使用该 locale 支持的 X-SAMPA 符号子集 来描述发音 你可以使用同样的 API 来训练 App 运行时能够接收到的数据 这样 App 就能支持 特定于用户的使用模式 比如专注于用户在努力学习的 国际象棋的开局和防御 你可能也想训练命名实体 你的 App 可能支持 与用户联系人的网络游戏 和往常一样 尊重用户隐私是最重要的 例如 一个通信 App 可能想根据联系人 出现在通话记录里的频率 来提升呼叫联系人的命令 这种信息应该永远 留在设备里 你只需要从你的 App 里 调用同样的方法来生成数据对象 把它写到一个文件里 并像之前展示的那样将其引入 App
训练数据一旦生成 就会被绑定到一个单一 locale 如果你想在单一脚本中 支持多个 locales 你可以使用标准本地化设施 比如 NSLocalizedString 来实现该目的 现在 我们来聊聊 把模型部署到 App 里 首先 你需要调用一个新方法 名为 prepareCustomLanguageModel 它接收 我们在先前的步骤中生成的文件 并产生两个后面会使用到的新文件 这种方法的调用 可能会产生大量的相关延迟 所以我们最好 在主线程外使用这种方法 并把延迟隐藏在一些 UI 比如加载屏幕的后面 有时候 为了尊重用户隐私 你需要把数据 保存在其产生的设备上 LM 定制支持这一点 从不通过网络发送定制数据 所有的自定义请求 都能在设备上严格执行 当 App 构建语音识别请求时 你首先要执行在设备上运行的识别 如果不这么做 语音识别请求 就会在没有定制的情况下执行 然后 你需把语言模型 添加到请求对象上 现在 我们已经 在 App 里打开了 LM 定制…… “使用 Albin counter gambit 战术” 自定义术语也起作用了 “使用瓦纳尔变例”
通过自定义语言模型 我已经根据 App 的领域对识别器进行调整 并且能够控制它的运行方式 最重要的是 我提高了 App 语音识别的准确性 语音框架已经 能适用于更多 App 和用户 它的功能更加强大 并且能创造出更出色的体验 语言模型定制为你提供了一种方法 让你能够定制 App 的语音识别器 并增强其功能 非常期待看到 你利用语音识别器完成的出色工作 感谢你的观看 请牢记住重点内容 ♪ ♪
-