-
Customize on-device speech recognition
Find out how you can improve on-device speech recognition in your app by customizing the underlying model with additional vocabulary. We'll share how speech recognition works on device and show you how to boost specific words and phrases for more predictable transcription. Learn how you can provide specific pronunciations for words and use template support to quickly generate a full set of custom phrases — all at runtime.
For more on the Speech framework, check out “Advances in Speech Recognition” from WWDC19.Resources
Related Videos
WWDC23
- Q&A: Machine learning open forum
- Q&A: Machine learning open forum
- Q&A: Machine learning open forum
- Q&A: Machine learning open forum
- Q&A: Natural Language and Speech
WWDC19
-
Search this video…
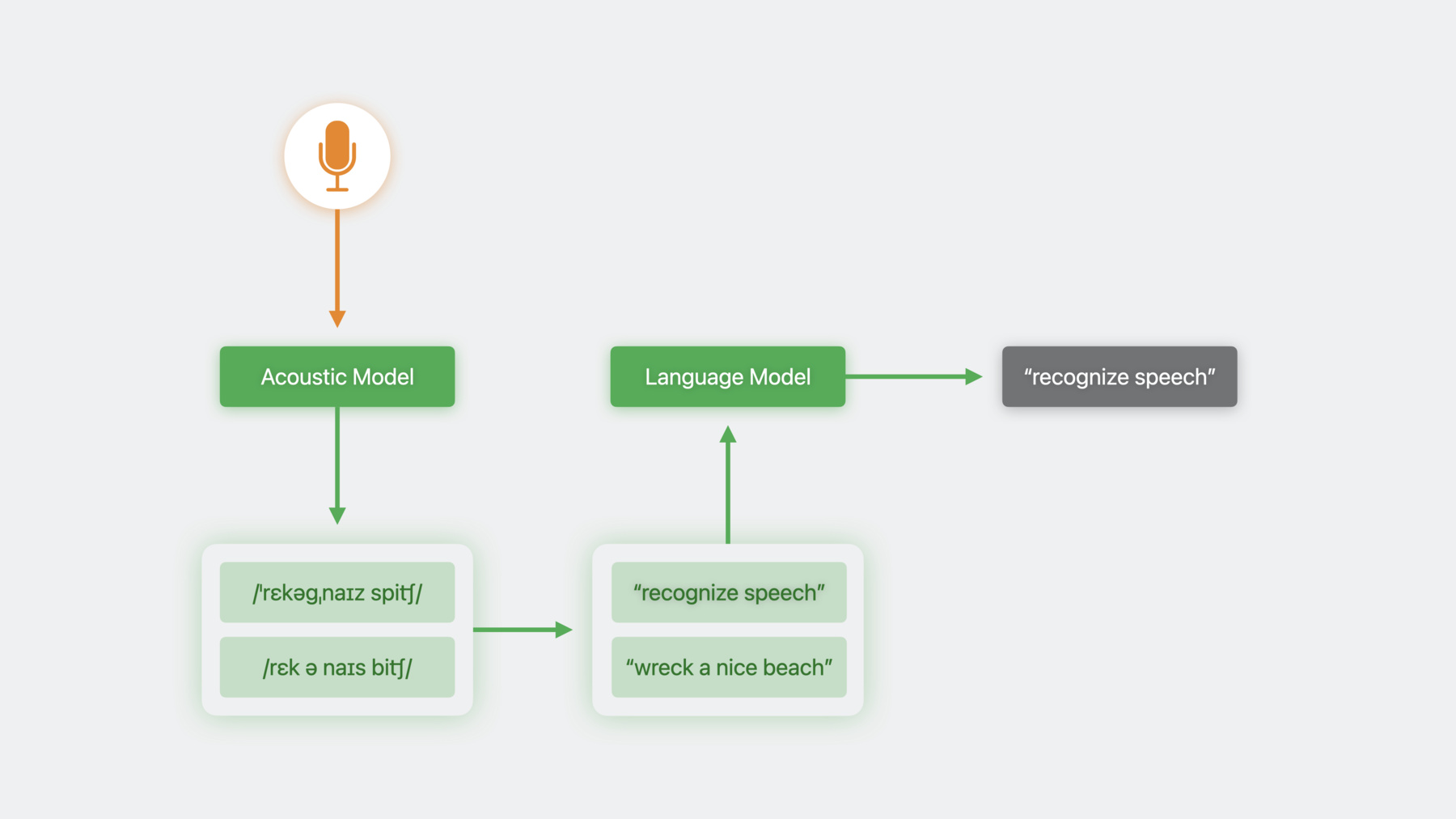
♪ ♪ Ethan: Hi, I'm Ethan. I'm from the Siri Understanding team and here to talk to you about some exciting developments in speech recognition. In iOS 10, we introduced the Speech framework. It allowed you to leverage the same technology that powers Siri and keyboard dictation to create voice enabled apps by using a simple, intuitive interface. However, the speech recognizer class, out of the box, isn't suitable for all apps. To explain why, let's talk about how speech recognition works. A speech recognition system first feeds audio data into an Acoustic Model, which produces a phonetic representation. Then the phonetic representation is converted into a written form, or transcription. Sometimes, multiple phonetic representations fit the audio data, or a single phonetic representation may correspond to multiple transcriptions. In these cases, we end up with multiple candidate transcriptions, and we need a way to disambiguate. To do this, we employ something called a language model. A language model predicts the likelihood that a given word will come next in a sequence of words. Applied to a whole sentence, it can give us a feel for whether the sentence is probably nonsense. The language model helps us reject candidates which are unlikely, based on patterns of usage that the model was exposed to during training. Since iOS 10, the Speech framework has encapsulated this entire process in order to present an interface that is easy to use. To understand why that might not be ideal, let's consider an example. I love to play chess, and I've been working on a chess app that will let users dictate individual moves, as well as common openings and defenses. Here, my opponent has played the classic Queen's Gambit. I've been studying, and I like the response E5, the Albin counter gambit.
Play the Albin counter gambit.
Uh oh, there's a problem. The recognizer is misrecognizing my chess move as a music request. The language model that the recognizer uses was exposed to a lot of music requests during its training process, so it is prepared for queries like, “Play the album,” followed by an album name. Conversely, it's probably never encountered my preferred transcription. By abstracting away the behavior of the language model, the Speech framework forces all apps to use the same model, even though different domains call for different behavior. Beginning in iOS 17, you'll be able to customize the behavior of the SFSpeechRecognizer's language model, tailor it to your application, and improve its accuracy.
To get started with language model customization, first create a collection of training data. You can do this during your development process. Then, in your app, you'll prepare the data, configure a recognition request, and then run it.
Let's talk about the process of building your collection of training data. At a high level, training data will consist of bits of text that represent phrases your app's users are likely to speak. These will teach the model to expect those phrases and boost the likelihood that they'll be recognized correctly. Experiment often, as it's surprising to see how capable the recognizer is, and how much it improves over time.
The speech framework introduces a new class that acts as a container for training data. It's built using the result builder DSL. You can provide an exact phrase or part of a phrase using a PhraseCount object. A PhraseCount will also describe how many times the sample should be represented in the final data set. This can be used to weight certain phrases more heavily than others. Only so much data can be accepted by the system, so balance your need to boost phrases against your overall training data budget. You can also leverage templates to generate a large number of samples that fit a regular pattern. Here, I've defined three classes of words that together make up a chess move. The piece to move, which doubles as the file that I'm targeting, the royal piece that defines which side of the board to play on, and the rank to move to. By putting them together into a pattern, I can easily generate data samples representing every possible move. Here, the count applies to the entire template, so I'll get 10,000 samples representing chess moves, divided evenly among all of the resulting data samples. When I'm done building up the data object, I export it to a file and deploy into my app like any other asset.
If your app makes use of specialized terminology, for example, a medical app that includes the names of pharmaceuticals, you can define both the spelling and pronunciations of those terms, and provide phrase counts that demonstrates their usage. Pronunciations are accepted in the form of X-SAMPA strings. Each locale supports a unique subset of pronunciation symbols. Refer to the documentation for the full set of locales and supported symbols. For my app, I want to make sure the recognizer can understand the Winawer variation, a common variant of the French defense. I describe the pronunciation using the subset of X-SAMPA symbols that are supported by this locale.
You can use the same API to train on data that your app can access at runtime. You might do this to support usage patterns that are specific to your users, such as focusing on the chess openings and defenses that your user is trying to learn. You might also want to train on named entities. Maybe your app supports network play against your user's contacts. And as always, respecting the user's privacy is paramount.
For example, a communication app may want to boost commands to call contacts based on the frequency with which those contacts appear in the call history. This kind of information should always stay on device. You simply call into the same methods from within your app to generate a data object, write it to a file, and ingest it as shown earlier.
Once training data is generated, it is bound to a single locale. If you want to support multiple locales within a single script, you can use standard localization facilities like NSLocalizedString to do so. Now, let's talk about deploying your model in your app. First, you need to call a new method, prepareCustomLanguageModel, that accepts the file we generated in the previous step and produces two new files that we'll use later. This method call can have a large amount of associated latency, so it's best to call it off the main thread, and hide the latency behind some UI, such as a loading screen. Sometimes, you need to keep data on the device where it's generated in order to respect the user's privacy. LM customization supports this by never sending customization data over the network. All customized requests are serviced strictly on device. When your app constructs the speech recognition request, you first enforce that the recognition is run on device. Failing to do so will cause requests to be serviced without customization. Then you attach the language model to your request object. Now, with LM customization turned on in my app... Play the Albin counter gambit. My custom terms work as well. Play the Winawer variation.
By customizing the language model, I've tuned the recognizer to my application's domain, and I've gained some control over how it behaves. Most importantly, I've improved speech recognition accuracy for my app. Now that the Speech framework can be adapted to more apps and more users, it's even more powerful and can be used to create even better experiences. Language model customization provides you a way to enhance the speech recognizer and customize it for your apps. I'm super excited to see all of the amazing things you'll accomplish with it. Thank you, and remember to play for the center. ♪ ♪
-