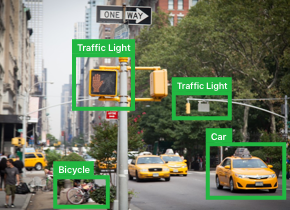
Build intelligence into your apps using machine learning models from the research community designed for Core ML.
Models are in Core ML format and can be integrated into Xcode projects. You can select different versions of models to optimize for sizes and architectures.
Images
Images
FastViTImage Classification
A Fast Hybrid Vision Transformer architecture trained to classify the dominant object in a camera frame or image.
Depth Anything V2Depth Estimation
The Depth Anything model performs monocular depth estimation.
Finding Answers to Questions in a Text DocumentLocate relevant passages in a document by asking the Bidirectional Encoder Representations from Transformers (BERT) model a question.