-
Detect Body and Hand Pose with Vision
Explore how the Vision framework can help your app detect body and hand poses in photos and video. With pose detection, your app can analyze the poses, movements, and gestures of people to offer new video editing possibilities, or to perform action classification when paired with an action classifier built in Create ML. And we'll show you how you can bring gesture recognition into your app through hand pose, delivering a whole new form of interaction.
To understand more about how you might apply body pose for Action Classification, be sure to also watch the "Build an Action Classifier with Create ML" and "Explore the Action & Vision app" sessions. And to learn more about other great features in Vision, check out the "Explore Computer Vision APIs" session.Resources
Related Videos
WWDC23
- Explore 3D body pose and person segmentation in Vision
- Integrate with motorized iPhone stands using DockKit
WWDC21
WWDC20
-
Search this video…
♪ Hello and welcome to WWDC.
Brett Keating: Hello everyone. My name is Brett Keating.
I hope you're all enjoying WWDC 2020.
Let's continue your journey and talk about some new API's in Vision this year.
Let's hear all about how to obtain body and hand pose using the Vision framework.
One of the major themes of the Vision framework is how it can be used to help you understand people in your visual data.
Back when Vision framework was first introduced, it came with a new face detector that was based on deep learning technology.
And since that time, it had been improved upon with a second revision that could detect upside down faces.
Also arriving with the debut of Vision was face landmark detection, which has also seen improvements with new revisions.
Last year we started giving you a new, richer set of landmarks that infer pupil locations.
Also new last year is human torso detection.
And now I'm excited to show you what's new in the People theme for Vision framework this year.
We will be providing hand pose and we will be providing human body pose from Vision framework.
Let's begin by talking about hand pose.
Hand pose has so many exciting possible applications.
I hope you will agree and find amazing ways to take advantage of it.
Look at how well it's working on this video of a child playing the ukulele.
Let's go through a few examples of what can be done with hand pose.
Perhaps your mission as a developer is to rid the world of selfie sticks.
The Vision framework can now help with hand pose estimation.
If you develop your app to look for specific gestures to trigger a photo capture, you can create an experience like the one my colleague Xiaoxia Sun has done here.
Maybe you'd like to be able to overlay fun graphics on hands like many developers have already done with faces.
In your app you can look at the hand poses Vision gives you and if you write code to classify them, you can overlay emojis or any other kind of graphic that you choose based on the gestures you find.
So how do you use Vision for this? As we've promised since the start, all of our algorithm requests generally follow the same pattern as the others.
The first step is to create a request handler.
Here we are using the ImageRequestHandler.
The next step is to create the request.
In this case, use a VNDetectHumanHandPoseRequest.
The next step is to provide the request to the handler via a call to performRequests.
Once that completes successfully, you will have your observations in the requests results property.
In this case, VNRecognizedPointsObservation are returned.
The observations contain locations for all the found landmarks for the hand.
These are given in new classes meant to represent 2D points.
These classes form an inheritance hierarchy.
If the algorithm you're using only returns a location, you'll be given a VNPoint.
A VNPoint contains a CGPoint location, and the X and Y coordinates of the locations can be accessed directly if desired as well.
The coordinates use the same lower left origin as other Vision algorithms and are also returned to normalized coordinates relative to the pixel dimensions of your image.
If the algorithm you're using also has a confidence associated with it, you will get VNDetectedPoint objects.
Finally, if the algorithm is also labelling the points, you will get VNRecognizedPoint objects.
For hand pose, VNRecognizedPoint objects are returned.
Here's how you access these points from a hand pose observation.
First you will request a dictionary of the landmarks by calling .recognizedPoints (forGroupKey: on the observation.
I will go into more detail about group keys in a minute but know that if you want all the points, you will use VNRecognizedPointGroupKeyAll.
We provide other VNRecognizedPointGroupKeys, such as for only those points that are part of the index finger, and you can access the landmarks by iterating over them.
Or as in this example, access a particular one for the tip of the index finger by specifying it's VNRecognizedPointKey.
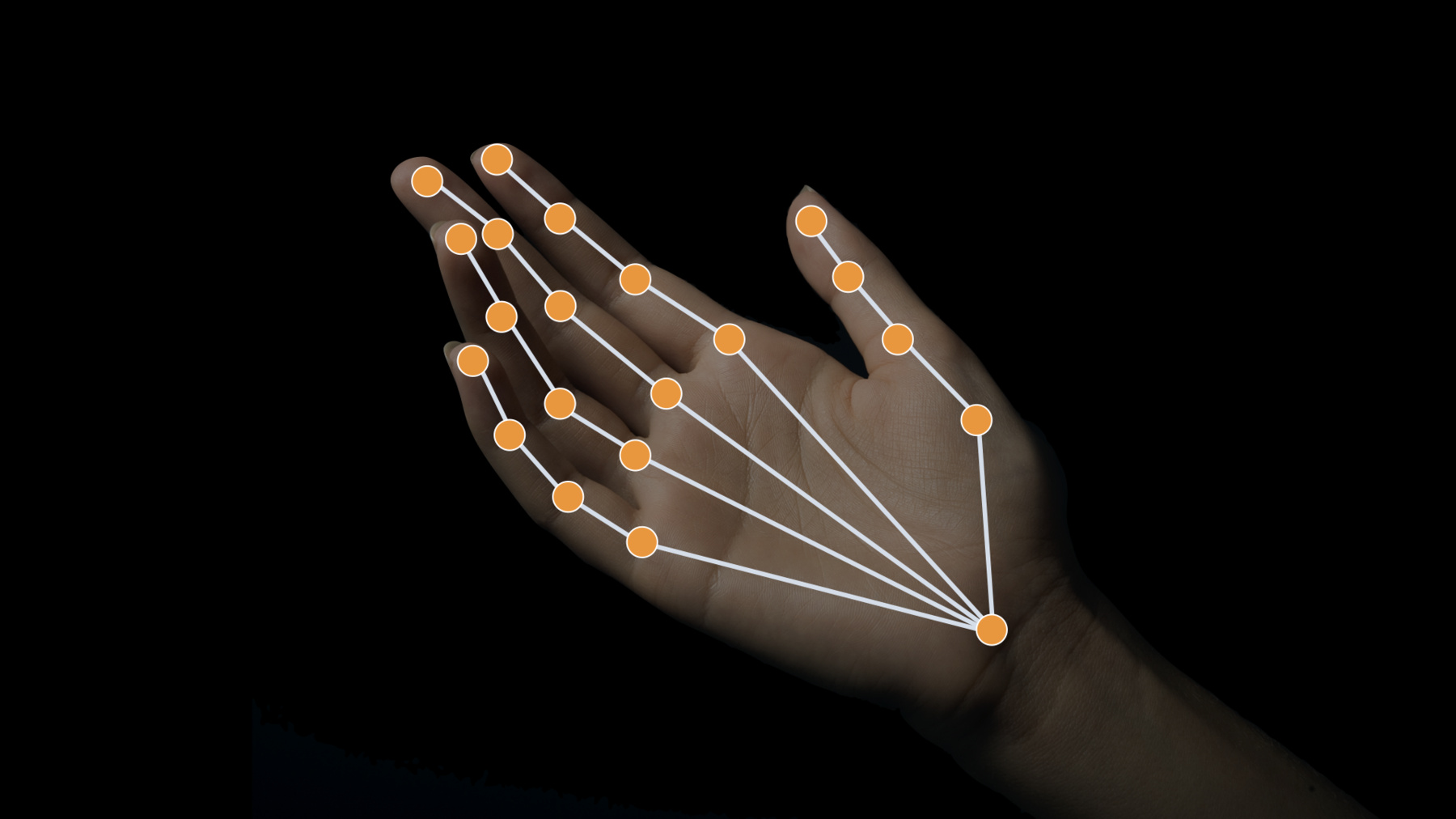
Here I am showing you a quick overview of the hand landmarks that are returned.
There are four for each finger and thumb and one for the wrist, for a total of twenty-one hand landmarks.
As I just mentioned, we have a new type this year called VNRecognizedPointGroupKey.
Each of the hand landmarks belong to at least one of these groups.
Here is the definition for the group key for the index finger and here are the landmarks that are contained in that group displayed visually on the hand.
Also, in the code example shown before, I showed you one of the VNRecognizedPointKey that you can use to retrieve the tip of the index finger.
Let's see what this looks like for the remaining parts of the finger.
Going down towards the hand, the first joint is the distal interphalangeal joint, which we abbreviate as DIP.
Notice that the VNRecognizedPointKey type uses this abbreviation to distinguish itself.
Continuing along, the next joint is the proximal interphalangeal joint, which we abbreviate as PIP.
Finally, at the base of the fingers is the metacarpophalangeal joint, which for fingers we abbreviate as MCP.
All these four points I mentioned are retrievable by the index fingers group key.
The pattern repeats for each of the fingers.
As an example, here is the group key and associated landmark keys for the ring finger.
The thumb is a bit different.
The thumb also has a tip.
The first joint is the interphalangeal joint which we abbreviate as IP.
The next joint is the metacarpophalangeal joint which for thumbs we abbreviate as MP.
The next joint for the thumb is the carpometacarpal joint, abbreviated as CMC.
Below, for reference, the corresponding group keys and landmark keys for the thumb are shown to contrast against what we provide for fingers.
And then there is the base of the wrist, which also has it's own landmark.
The wrist landmark falls on the center of the wrist and is not part of any group except for the all group.
In other words, it's not part of any finger or thumb group.
Combined with the landmarks for the fingers and thumbs, this forms the set of landmarks we identify for hands.
Now let me show you our sample application for hand pose.
So with this sample, I'm using my hand to draw on the screen.
When my finger and thumb are close together, I'll start drawing.
And here I'm using that to write the word hello.
And that's it! So let's see what that looks like in the code.
Here I'm going to start in the CameraViewController in our capture output where we are receiving CMSampleBuffers from the camera stream.
The first thing we do is we create a VNImageRequestHandler using that sample buffer.
Then we use that handler to perform our request.
Our request is a VNDetectHumanHandPoseRequest.
If we find a hand, we'll be getting an observation back and from that observation we can get the thumb points and the index finger points by using their VNRecognizedPointGroupKey by calling recognizedPoints (forGroupKey.
With those collections, we can look for the fingertip and the thumb tip points, and we do that here.
We ignore any low confidence points and then at the end of this section, we convert the points from Vision coordinates to AVfoundation coordinates.
The one thing I want to draw your attention to up here is that we have set up a separate queue to process these points.
So let's go into processPoints.
Here we're just checking to see if nothing's going on; if so, we reset.
Otherwise, we convert our thumb and index points intoAVfoundation coordinates here.
Then we process these points.
We have another class called gestureProcessor, and in that we call processPointsPair.
So here in processPointsPair, we're looking at the distance between the tip of the index finger and the tip of the thumb.
If the distance is less than a threshold, then we start accumulating evidence for whether or not we are in a pinch state or a possible pinch state.
The threshold that we have is 40, and how much evidence we require is three frames of the same pinch state.
So once we've collected three frames of the pinch state, we move from a possible pinch state to a pinch state.
We do the same thing for the apart state.
If the fingers are not meeting the threshold, we consider them apart.
Until we accumulate enough evidence, we are in the possible apart state.
Once we have enough evidence, we transition to the apart state.
Going back to the CameraViewController file, these state changes are handled in handleGestureStateChange.
Here we're looking at which case we're in.
If we're in a possible pinch or a possible apart state, we want to keep track of the points that we have found in order to decide later if we want to draw them or not.
And we collect those here.
If ultimately we end up in the pinch state, then we go ahead and we draw those points.
Once we've drawn them, we can remove them from our evidence buffer and then go ahead and continue drawing.
If we end up in the apart state, we will not draw those points; we will still remove all of those points from our evidence buffer.
But then we will update the path with the final point and indicate that with the boolean isLastPointsPair set to true.
One last thing I'd like to mention in the sample is that we have also set up a gesture handler that looks for a double tap in order to clear the screen.
That is how you use our sample for hand pose to use Visual framework to draw on the screen with your hand.
Vision provides a couple additional things in the API that you should know about which are meant to deal with the fact that there could be many hands in the scene.
Perhaps you're only interested in the one or two biggest hands in the scene and don't want results returned for any smaller hands found in the background.
You may control this by specifying maximumHandCount on the request.
The default is two.
So if you do want more than two, it's important to adjust this parameter.
Suppose you want all the detected hands which aren't too blurry or occluded.
You may set this as high as you want but know that setting this parameter to a large number will have a latency impact because the pose will be generated for every detected hand.
If the parameter is set to a lower number, pose will not be computed for any hands detected beyond the maximum requested, which can help with performance.
It is therefore recommended that you tune this parameter for your application needs with performance in mind.
While using hand pose in Vision, it might help to take advantage of the VNTrackObjectRequest.
VNTrackObjectRequest is potentially useful in hand analysis for two reasons.
First, if all you want to do is track the location of the hands and care less about the pose, you may use a hand pose request to find the hands and then use VNTrackObjectRequest from that point forward to know where the hands are moving.
Second, if you want to be more robust about which hand is which, a tracking request may help you.
The vision tracker is good at maintaining object identifiers as things move off screen or become occluded temporarily.
For more information about the object tracker, please have a look at our WWDC session on the matter from 2018.
I'm sure you're completely sold on hand pose by now and can't wait to start implementing the apps you've already begun dreaming up.
But before you do, there are a few accuracy considerations to keep in mind.
Hands near the edges of the screen will be partially occluded, and hand pose is not guaranteed to work well in those situations.
Also, the algorithm may have difficulty with hands that are parallel to the camera viewing direction, like those in the image of this karate chopper.
Hands covered by gloves may also be difficult at times.
Finally, the algorithm will sometimes detect feet as hands.
It is good to keep all of these caveats in mind when designing your app, which may include instructions to your users to make the best of the experience you plan to provide them.
And that is hand pose.
Moving on, let's now discuss human body pose in Vision.
New this year, Vision is providing you with the capability to analyze many people at once for body pose, as shown in this video.
So, like we did for hand pose, let's go over some exciting ideas for apps you can develop with body pose.
How about taking better action shots? If you have the body pose available, you can identify interesting parts of the action like the apex of this jump.
That is probably the most interesting shot of the sequence.
Or creating stromotion shots.
Here we use human body pose to find the frames where the basketball player doesn't overlap with himself and we can create this cool looking image.
Having a look at body pose for work and safety applications might be interesting to your application domain.
Perhaps it can help with training for proper ergonomics.
Human body pose can be used as part of another new feature this year as well: action classification through CreateML.
Maybe you'd like to create some fitness apps that can classify an athlete as performing the action you expect, like this man performing jumping jacks.
Or perhaps you want to know if these kids are having any success in attempting what is properly considered dancing.
This technology was used in the Action and Vision application.
So check out the session on that for a more in-depth look on how to bring everything together into a really cool app.
To analyze images for human body pose, the flow is very similar to that of hand pose.
As with any use of Vision, the first thing to do is to create a request handler.
The next step is to create a VNDetectHumanBodyPoseRequest, then use the request handler to perform the requests.
The difference between this example and the hand pose example is we use the word "body" instead of "hand" and that's it.
Looking at the landmark points is also analogous to what is done for a hand pose.
Getting all the points is done exactly the same way by calling the recognizedPoints(forGroupKey with VNRecognizedPointGroupKeyAll or you can get a specific group of landmarks, as we do for the left arm here.
And then you may request a particular landmark by key, as we do here to get the left wrist landmark.
Let's go over the landmarks for the human body.
There are VNRecognizedPointGroupKeys for each group, and here we start with the face.
The VNRecognizedPointKey values for the face include the nose, the left and right eye, and the left and right ear.
Let's have a look at the right arm group next.
Note that this is the subject's right arm, not the one on the right side of the image.
There are three landmarks in this group for the shoulder, the elbow, and the wrist.
The subject's left arm also has a group for the shoulder, elbow, and wrist, with associated keys listed here.
The torso is next.
Note that it also contains the shoulders.
So then, the shoulder landmarks appear in more then one group.
Also included is a neck point between the shoulders, the left and right hip joints, and a root joint between the two hip joints.
The subject's right leg comes next, and note that the hip joints appear in both the torso group and each leg group.
Also in the leg group are the knee and ankle landmarks.
And finally, same with the left leg: a hip, knee, and ankle landmark.
There are some limitations you ought to be aware of regarding body pose in Vision.
If the people on the scene are bent over or upside down, the body pose algorithm will not perform as well.
Also the pose might not be determinable due to obstructive flowing clothing.
Also as you may have noticed in the dancing example, if one person is partially occluding another in the view, it is possible for the algorithm to get confused.
Similar to hand pose, the results may get worse if the subject is close to the edges of the screen.
And finally, the same considerations that applied to hand pose for tracking also apply to body pose.
As you may be aware, Vision is not the first framework in our SDKs to offer body pose analysis.
Since last year, ARKit has been providing body pose to developers within the context of an AR session.
Here we contrast that division and when it makes sense to use one versus the other.
You will get the same set of landmarks either way, but Vision provides a confidence value per point while ARKit does not.
In general, the Vision framework is capable of being used on still images or camera feeds.
So just like anything else Vision provides, human body pose from Vision can be used offline to analyze whole libraries of images.
ARKit's solution is designed for live motion capture applications.
Also due to its specific use case, ARKit body pose can only be used with a rear-facing camera from within an AR session on supported iOS and iPadOS devices.
Vision's API can be used on all supported platforms, except the watch.
The idea behind providing this API through Vision is precisely to make available Apple's body pose technology outside of an ARKit session.
However, for most ARKit use cases, especially motion capture, you should be using ARKit to get body pose information.
As mentioned earlier in this discussion, you can use body pose in combination with CreateML for action classification.
Let's go over a couple tips for how to best train your action classifier with body pose data.
If you use videos directly for training, you should understand that Vision will be used to generate body poses on your behalf.
If there is more than one subject in the video, then by default the largest one will be used.
To avoid having this default behavior applied to your training videos, it is best to ensure only the subject of interest is in the frame.
You can do this by cropping your training videos so that only a single actor is present.
If you are not using videos, you may also use ML MultiArray buffers retrieved from Vision's keypoints MultiArray method.
With this method, you exactly control which body poses are used for training.
Since Vision is used during training, it should also be used for inference.
Attempting to use ARKit body pose as an input to a model trained with Vision body poses will produce undefined results.
Finally, please be aware that once you get to the point of performing inference, you will need to pay attention to latency on older devices.
While the latest and greatest devices might be able to keep up with the camera stream while performing inference for action classification, older devices will not.
Suppose this is your image sequence.
You will still want to retrieve body pose for every frame because the classifiers will be expecting the body poses to be sampled at that rate.
But do be mindful of holding onto camera buffers for too long.
Otherwise, you may starve the stream.
But your application will perform better, especially on older model devices, if you space out the classification inferences.
Recognizing an action within a fraction of a second is pretty quick for most use cases, so doing inferences only a few times per second should be OK.
The Action and Vision sample is a great example of how to use Vision and CreateML to classify human actions.
Here is a short demonstration clip of the Action and Vision sample in action.
In this clip, we see my colleague Frank tossing some beanbags at a cornhole board.
He tosses the bags using a few different throwing techniques which are classified in the app using CreateML.
So let's have a look at the code in the Action and Vision sample to see how this is done.
We'll start in the GameViewController.
Here in the cameraViewController, we are getting our CMSampleBuffers from the camera, and we provide those to an image request handler here.
Later on we use that image request handler to perform our request.
Here it is a VNDetectHumanBodyPoseRequest.
If we get a result, then we call humanBoundingBox.
Lets go into humanBoundingBox to see what this is doing.
In humanBoundingBox we're trying to find the human bounding box around the person.
We'll start by getting all the points out of the observation by calling recognizePoints forGroupKey all.
Then we can iterate over all the points here.
We look here to see if the point has enough confidence and if it does we add it to our normalizedBoundingBox.
Here we're doing something where we're trying to find the body joints for the right-hand side of the body so we can overlay them on the screen.
But since we're talking about action classification, I'll skip that for now.
Later on we're going to be storing these observations.
Let's look at what's happening in storeObservation and why we're doing it.
In storeObservation, we have a buffer of observations that we call poseObservations.
What we're going to do is use that as a ring buffer.
If this buffer is full, we will remove the first one.
And either way, we're going to append the next one.
We use this later on when a throw is detected.
A throw is detected when the trajectory analysis detects a throw, and then we call this function getLastThrowType to find out what kind of throw was made.
We're going to use our actionClassifier for this but we need to put all of our observations into the correct format.
So we will call prepareInputWithObservations in order to do that.
Let's look at what that function is doing.
In prepareInputWithObservations, we see that we need 60 observations and we need to put them in a multiArrayBuffer of type MLMultiArray.
Here in this loop, we iterate over all the observations that we have in our buffer, and for each observation we call keypointsMultiArray and we put that into our buffer.
If we don't have 60, then we'll pad with zeros.
Notice the MLMultiArray shape and dataType that's expected.
And then we concatenate those and return them.
Going back to getLastThrowType, we provide that input into PlayerActionClassifierInput, which is our ML feature provider.
Once we have that, we provide it to our action classifier by calling prediction with the input.
Then once we have the output , we look over all the probabilities to see which of the possibilities are the most likely.
And then we return the throw type that corresponds to that maximum probability.
And that is how you do action classification using body pose from Vision framework.
Now that you've had a closer look at the code in the Action and Vision application for body pose, congratulations! Along with everything else you've learned in this session, you are prepared to go create amazing applications.
Applications that do more when it comes to analyzing people with computer vision with the Vision framework.
And that is hand and body pose in Vision.
Have a great time continuing your WWDC journey.
-
-
7:07 - HandPoseCameraViewController
extension CameraViewController: AVCaptureVideoDataOutputSampleBufferDelegate { public func captureOutput(_ output: AVCaptureOutput, didOutput sampleBuffer: CMSampleBuffer, from connection: AVCaptureConnection) { var thumbTip: CGPoint? var indexTip: CGPoint? defer { DispatchQueue.main.sync { self.processPoints(thumbTip: thumbTip, indexTip: indexTip) } } let handler = VNImageRequestHandler(cmSampleBuffer: sampleBuffer, orientation: .up, options: [:]) do { // Perform VNDetectHumanHandPoseRequest try handler.perform([handPoseRequest]) // Continue only when a hand was detected in the frame. // Since we set the maximumHandCount property of the request to 1, there will be at most one observation. guard let observation = handPoseRequest.results?.first as? VNRecognizedPointsObservation else { return } // Get points for thumb and index finger. let thumbPoints = try observation.recognizedPoints(forGroupKey: .handLandmarkRegionKeyThumb) let indexFingerPoints = try observation.recognizedPoints(forGroupKey: .handLandmarkRegionKeyIndexFinger) // Look for tip points. guard let thumbTipPoint = thumbPoints[.handLandmarkKeyThumbTIP], let indexTipPoint = indexFingerPoints[.handLandmarkKeyIndexTIP] else { return } // Ignore low confidence points. guard thumbTipPoint.confidence > 0.3 && indexTipPoint.confidence > 0.3 else { return } // Convert points from Vision coordinates to AVFoundation coordinates. thumbTip = CGPoint(x: thumbTipPoint.location.x, y: 1 - thumbTipPoint.location.y) indexTip = CGPoint(x: indexTipPoint.location.x, y: 1 - indexTipPoint.location.y) } catch { cameraFeedSession?.stopRunning() let error = AppError.visionError(error: error) DispatchQueue.main.async { error.displayInViewController(self) } } } } -
8:29 - HandPoseProcessPointsPair
init(pinchMaxDistance: CGFloat = 40, evidenceCounterStateTrigger: Int = 3) { self.pinchMaxDistance = pinchMaxDistance self.evidenceCounterStateTrigger = evidenceCounterStateTrigger } func reset() { state = .unknown pinchEvidenceCounter = 0 apartEvidenceCounter = 0 } func processPointsPair(_ pointsPair: PointsPair) { lastProcessedPointsPair = pointsPair let distance = pointsPair.indexTip.distance(from: pointsPair.thumbTip) if distance < pinchMaxDistance { // Keep accumulating evidence for pinch state. pinchEvidenceCounter += 1 apartEvidenceCounter = 0 // Set new state based on evidence amount. state = (pinchEvidenceCounter >= evidenceCounterStateTrigger) ? .pinched : .possiblePinch } else { // Keep accumulating evidence for apart state. apartEvidenceCounter += 1 pinchEvidenceCounter = 0 // Set new state based on evidence amount. state = (apartEvidenceCounter >= evidenceCounterStateTrigger) ? .apart : .possibleApart } } -
9:25 - HandPoseHandleGestureStateChange
private func handleGestureStateChange(state: HandGestureProcessor.State) { let pointsPair = gestureProcessor.lastProcessedPointsPair var tipsColor: UIColor switch state { case .possiblePinch, .possibleApart: // We are in one of the "possible": states, meaning there is not enough evidence yet to determine // if we want to draw or not. For now, collect points in the evidence buffer, so we can add them // to a drawing path when required. evidenceBuffer.append(pointsPair) tipsColor = .orange case .pinched: // We have enough evidence to draw. Draw the points collected in the evidence buffer, if any. for bufferedPoints in evidenceBuffer { updatePath(with: bufferedPoints, isLastPointsPair: false) } // Clear the evidence buffer. evidenceBuffer.removeAll() // Finally, draw current point updatePath(with: pointsPair, isLastPointsPair: false) tipsColor = .green case .apart, .unknown: // We have enough evidence to not draw. Discard any evidence buffer points. evidenceBuffer.removeAll() // And draw the last segment of our draw path. updatePath(with: pointsPair, isLastPointsPair: true) tipsColor = .red } cameraView.showPoints([pointsPair.thumbTip, pointsPair.indexTip], color: tipsColor) } -
10:15 - HandPoseHandleGesture
@IBAction func handleGesture(_ gesture: UITapGestureRecognizer) { guard gesture.state == .ended else { return } evidenceBuffer.removeAll() drawPath.removeAllPoints() drawOverlay.path = drawPath.cgPath } -
20:48 - ActionVisionGameViewController
extension GameViewController: CameraViewControllerOutputDelegate { func cameraViewController(_ controller: CameraViewController, didReceiveBuffer buffer: CMSampleBuffer, orientation: CGImagePropertyOrientation) { let visionHandler = VNImageRequestHandler(cmSampleBuffer: buffer, orientation: orientation, options: [:]) if self.gameManager.stateMachine.currentState is GameManager.TrackThrowsState { DispatchQueue.main.async { // Get the frame of rendered view let normalizedFrame = CGRect(x: 0, y: 0, width: 1, height: 1) self.jointSegmentView.frame = controller.viewRectForVisionRect(normalizedFrame) self.trajectoryView.frame = controller.viewRectForVisionRect(normalizedFrame) } // Perform the trajectory request in a separate dispatch queue trajectoryQueue.async { self.setUpDetectTrajectoriesRequest() do { if let trajectoryRequest = self.detectTrajectoryRequest { try visionHandler.perform([trajectoryRequest]) } } catch { AppError.display(error, inViewController: self) } } } // Run bodypose request for additional GameConstants.maxPostReleasePoseObservations frames after the first trajectory observation is detected if !(self.trajectoryView.inFlight && self.trajectoryInFlightPoseObservations >= GameConstants.maxTrajectoryInFlightPoseObservations) { do { try visionHandler.perform([detectPlayerRequest]) if let result = detectPlayerRequest.results?.first as? VNRecognizedPointsObservation { let box = humanBoundingBox(for: result) let boxView = playerBoundingBox DispatchQueue.main.async { let horizontalInset = CGFloat(-20.0) let verticalInset = CGFloat(-20.0) let viewRect = controller.viewRectForVisionRect(box).insetBy(dx: horizontalInset, dy: verticalInset) self.updateBoundingBox(boxView, withRect: viewRect) if !self.playerDetected && !boxView.isHidden { self.gameStatusLabel.alpha = 0 self.resetTrajectoryRegions() self.gameManager.stateMachine.enter(GameManager.DetectedPlayerState.self) } } } } catch { AppError.display(error, inViewController: self) } } else { // Hide player bounding box DispatchQueue.main.async { if !self.playerBoundingBox.isHidden { self.playerBoundingBox.isHidden = true self.jointSegmentView.resetView() } } } } } -
21:19 - ActionVisionHumanBoundingBox
func humanBoundingBox(for observation: VNRecognizedPointsObservation) -> CGRect { var box = CGRect.zero // Process body points only if the confidence is high guard observation.confidence > 0.6 else { return box } var normalizedBoundingBox = CGRect.null guard let points = try? observation.recognizedPoints(forGroupKey: .all) else { return box } for (_, point) in points { // Only use point if human pose joint was detected reliably guard point.confidence > 0.1 else { continue } normalizedBoundingBox = normalizedBoundingBox.union(CGRect(origin: point.location, size: .zero)) } if !normalizedBoundingBox.isNull { box = normalizedBoundingBox } // Fetch body joints from the observation and overlay them on the player DispatchQueue.main.async { let joints = getBodyJointsFor(observation: observation) self.jointSegmentView.joints = joints } // Store the body pose observation in playerStats when the game is in TrackThrowsState // We will use these observations for action classification once the throw is complete if gameManager.stateMachine.currentState is GameManager.TrackThrowsState { playerStats.storeObservation(observation) if trajectoryView.inFlight { trajectoryInFlightPoseObservations += 1 } } return box } -
21:58 - ActionVisionStoreObservation
mutating func storeObservation(_ observation: VNRecognizedPointsObservation) { if poseObservations.count >= GameConstants.maxPoseObservations { poseObservations.removeFirst() } poseObservations.append(observation) } -
22:21 - ActionVisionGetLastThrowType
mutating func getLastThrowType() -> ThrowType { let actionClassifier = PlayerActionClassifier().model guard let poseMultiArray = prepareInputWithObservations(poseObservations) else { return ThrowType.none } let input = PlayerActionClassifierInput(input: poseMultiArray) guard let predictions = try? actionClassifier.prediction(from: input), let output = predictions.featureValue(for: "output")?.multiArrayValue, let outputBuffer = try? UnsafeBufferPointer<Float32>(output) else { return ThrowType.none } let probabilities = Array(outputBuffer) guard let maxConfidence = probabilities.prefix(3).max(), let maxIndex = probabilities.firstIndex(of: maxConfidence) else { return ThrowType.none } let throwTypes = ThrowType.allCases return throwTypes[maxIndex] } -
22:42 - ActionVisionPrepareInputWithObservations
func prepareInputWithObservations(_ observations: [VNRecognizedPointsObservation]) -> MLMultiArray? { let numAvailableFrames = observations.count let observationsNeeded = 60 var multiArrayBuffer = [MLMultiArray]() // swiftlint:disable identifier_name for f in 0 ..< min(numAvailableFrames, observationsNeeded) { let pose = observations[f] do { let oneFrameMultiArray = try pose.keypointsMultiArray() multiArrayBuffer.append(oneFrameMultiArray) } catch { continue } } // If poseWindow does not have enough frames (60) yet, we need to pad 0s if numAvailableFrames < observationsNeeded { for _ in 0 ..< (observationsNeeded - numAvailableFrames) { do { let oneFrameMultiArray = try MLMultiArray(shape: [1, 3, 18], dataType: .double) try resetMultiArray(oneFrameMultiArray) multiArrayBuffer.append(oneFrameMultiArray) } catch { continue } } } return MLMultiArray(concatenating: [MLMultiArray](multiArrayBuffer), axis: 0, dataType: MLMultiArrayDataType.double) } -
23:19 - ActionVisionGetLastThrowType2
mutating func getLastThrowType() -> ThrowType { let actionClassifier = PlayerActionClassifier().model guard let poseMultiArray = prepareInputWithObservations(poseObservations) else { return ThrowType.none } let input = PlayerActionClassifierInput(input: poseMultiArray) guard let predictions = try? actionClassifier.prediction(from: input), let output = predictions.featureValue(for: "output")?.multiArrayValue, let outputBuffer = try? UnsafeBufferPointer<Float32>(output) else { return ThrowType.none } let probabilities = Array(outputBuffer) guard let maxConfidence = probabilities.prefix(3).max(), let maxIndex = probabilities.firstIndex(of: maxConfidence) else { return ThrowType.none } let throwTypes = ThrowType.allCases return throwTypes[maxIndex] }
-