-
Deploy machine learning and AI models on-device with Core ML
Learn new ways to optimize speed and memory performance when you convert and run machine learning and AI models through Core ML. We'll cover new options for model representations, performance insights, execution, and model stitching which can be used together to create compelling and private on-device experiences.
Chapters
- 0:00 - Introduction
- 1:07 - Integration
- 3:29 - MLTensor
- 8:30 - Models with state
- 12:33 - Multifunction models
- 15:27 - Performance tools
Resources
Related Videos
WWDC23
-
Search this video…
Hi, I’m Joshua Newnham, an engineer on the Core ML team. Today, I'm excited to introduce you to some new features in Core ML to help you efficiently deploy and run your machine learning and AI models on-device.
Running models on-device, opens up exciting possibilities for you to create new forms of interactions, powerful professional tools, and insightful analysis from health and fitness data, all while keeping personal data private and secure.
Thousands of apps have used Core ML to create amazing experiences powered by on-device ML, and so can you! In this video, we’ll start by reviewing Core ML’s role in the model deployment workflow. Next, we’ll dive into some exciting features, starting with a new type to simplify model integration. Then, explore using state to improve model inference efficiency. After that, we’ll introduce multi-function models for efficient deployment. And finally, review updates to Core ML performance tools, to help you profile and debug your models. Let’s begin.
The machine learning workflow consists of three phases, model training, preparation, and integration. In this video, we’ll focus on integrating and running your machine learning and AI models on-device. To learn about training, I recommend watching this year’s video on training ML and AI models on Apple GPUs. And to learn about converting and optimizing your models, check out this years video on bringing your models to Apple silicon.
Model integration begins with an ML package, the artifact created during the preparation phase. From here, Core ML makes it easy to integrate and use this model in your app.
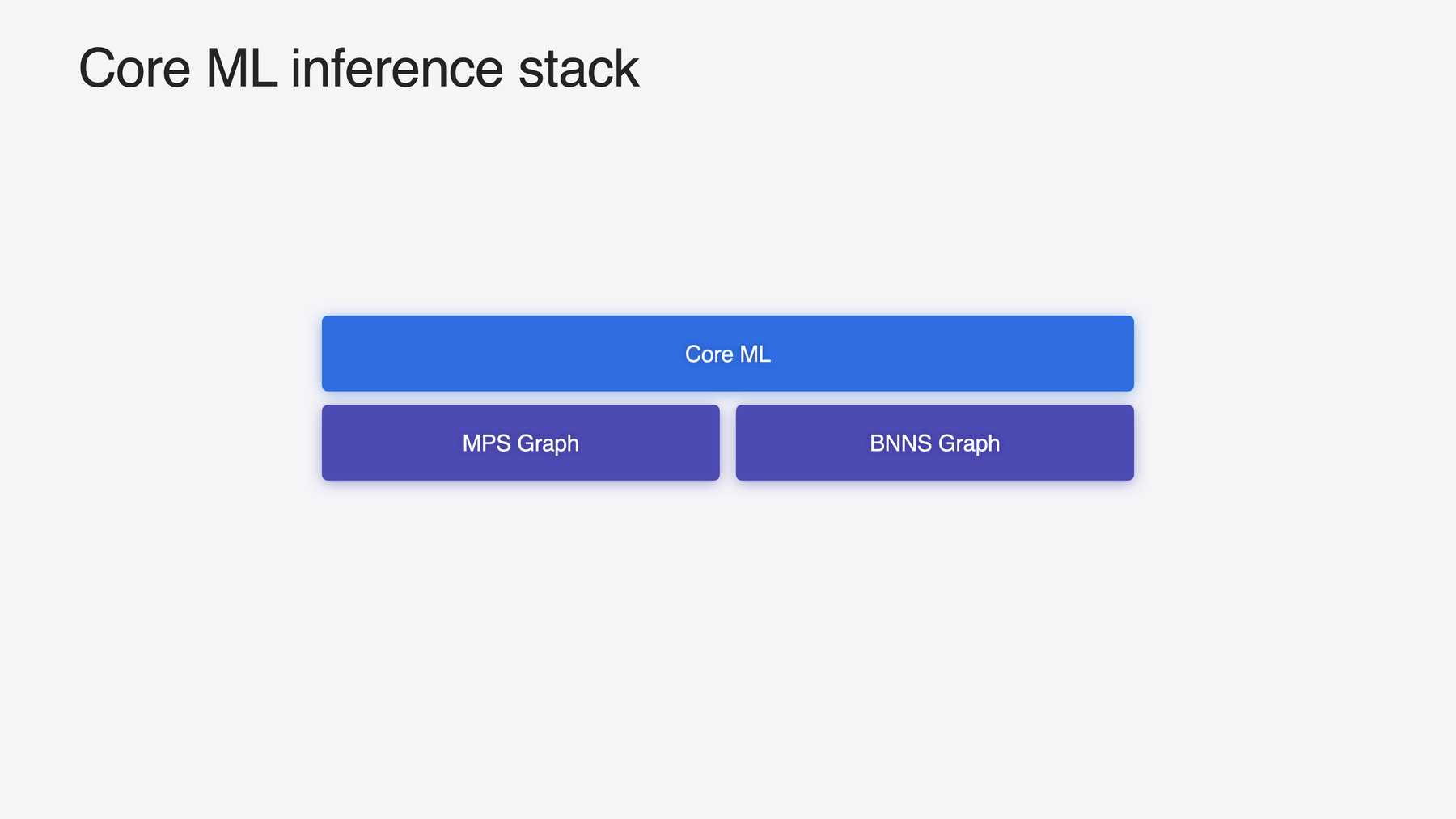
It is tightly integrated with Xcode and offers a unified API for performing on-device inference across a wide range of machine learning and AI model types.
Models are executed using Apple silicon’s powerful compute capabilities, dispatching work across the CPU, GPU, and Neural Engine. It does this with the help of MPS Graph and BNNS Graph, two other machine learning frameworks which can also use Core ML models. Most suitable when your use case requires either tight integration with Metal or real-time inference on the CPU.
Check out the relevant videos to learn more.
With significant improvements across the inference stack, Core ML delivers even better performance this year.
For example, when comparing the relative prediction time between iOS 17 and 18, you’ll observe that iOS 18 is faster across many of your models. This speed-up comes with the OS and doesn’t require recompiling your models or changing any of your code. It also applies to other devices, although the speed-up depends on the model and hardware.
With the model converted, we are ready to explore how to integrate and run it efficiently.
Integrating a model into your app can be as simple as passing in the required input and reading the returned output.
However, complexity can quickly grow for more advanced use cases. For example, generative AI is often iterative and can involve multiple models.
In these use cases, there exists computation outside the model which serves as the glue, or stitching, necessary to run an end-to-end pipeline. Supporting this computation often requires implementing operations from scratch or using various low-level APIs, both leading to lengthly and complex code. That is, until now.
Introducing MLTensor, a new type in Core ML that provides a convenient and efficient way to support this computation.
MLTensor offers many common math and transformation operations typical of machine learning frameworks.
These operations are executed using Apple silicon’s powerful compute capabilities, ensuring high-performance execution.
And it resembles popular Python numerical libraries, making it easier and more intuitive for you to adopt if you’re already familiar with machine learning. Let’s explore the API by walking through some examples.
To start, we will create a couple of tensors to play with. There are various ways of creating a tensor, we’ll present two here.
The first creates a tensor from a MLShapedArray, and the second uses a nested collection of scalars. Like MLShapedArray, MLTensor is multi-dimensional array defined by its shape and scalar type, where the shape specifies the length of each axis and scalar type indicates the type of elements it holds. Now we know how to create tensors, let’s explore some ways to manipulate them. Starting with some basic math. Tensors support a broad range of operations. In this example, we perform an element-wise addition and multiplication, then compute the result’s mean. Tensors seamlessly work with literals and the framework automatically broadcasts compatible shapes. A Boolean mask is then created by comparing the result to its mean. This mask is multiplied by the result to create a filtered version, zeroing out any values where the mask is false. Next, we demonstrate how to index and transform a tensor’s shape. Similar to Python numerical libraries, you can slice the tensor by indexing into each dimension. In this example, we take the first row of the matrix and expand it back out using the reshape method. All tensor operations are dispatched asynchronously. It’s for this reason, a tensor must be explicitly materialized to a MLShapedArray before its underlying data can be accessed. Doing so ensures that all upstream operations are complete and data is available.
Now that we’ve seen how to create and manipulate tensors, let’s turn our attention to something more interesting. Let’s explore how MLTensor can simplify integrating large language models.
We’ll start by briefly introducing our example model and its outputs. The model is an autoregressive language model, a model trained to predict the next word, or token, based on the context of the preceding words.
To generate a sentence, the predicted word is added back to the input and the process repeats until it detects an end-of-sequence token or reaches a set length. However, language models don’t output a single word, they output scores for all words in a vocabulary, where each score represents the model’s confidence in that word coming next.
A decoder uses these scores to select the next word using various strategies, such as choosing the word with the greatest score or randomly sampling over an adjusted probability distribution. The ability to change the decoding method means this step is typically kept separate from the model, making it an ideal candidate for MLTensor. Let’s see just how by comparing implementations for a couple of decoding methods before and after the introduction of MLTensor.
In this demo, I will use a modified version of HuggingFace’s Swift Transformer package and Chat app, along with the Mistral 7 billion model converted and optimized in the preparation video. Before we compare the decoder implementations, let’s see the model in action by prompting it to generate some title ideas for a fictional children’s story about a superhero Corgi.
It’s a great start, but I would like something more creative. The application defaults to selecting the most probable word, a method known as greedy decoding.
Let’s explore another decoding method.
By enabling top-k sampling, the application will select the next word by randomly sampling over the top-k most probable words instead of always selecting the word with the greatest score.
In addition to randomly sampling the most probable words, we can also influence the probability distribution by adjusting the temperature. A high temperature flattens the distribution, resulting in more creative responses, while a lower temperature has an opposite effect, leading to more predictable outputs.
Let’s re-run the model, using top-k sampling with a temperature of 1.8.
That’s a little more interesting. Now we have seen the results of two decoding methods, let’s compare their implementations with and without MLTensor. When comparing the implementations, one striking difference between the two is how little code is required to achieve the same functionality with MLTensor. This is not to say the original version is wrong or that low-level APIs are unnecessary. On the contrary, this is well-written and performant code, and there are many instances where low-level APIs are required. But for many common machine learning tasks, MLTensor can offer a concise alternative, allowing you to focus more on creating great experiences and less on low-level details. In the previous section, we learned how MLTensor simplifies decoding outputs from a language model. In this section, we’ll introduce state and explore how it can be used to reduce the time it takes to generate each word from the language model. Let’s begin by first describing what we mean by state.
It’s likely that most of the models you’ve interacted with are stateless. That is, they process each input independently, without retaining any history. For example, an image classifier based on a Convolutional Neural Network is stateless as each input is processed in isolation from previous one.
This contrasts with stateful models which, as you may have guessed, retain history from previous inputs. Architectures like Recurrent Neural Networks used for sequence data are one example of a stateful model.
Today, stateful models can be supported by managing state manually, where the state is passed in as an input, and the updated version retrieved from the output ready for the next prediction. However, loading and unloading the data used for state at each time-step incurs some overhead. This overhead can become noticeable as the size of the state increases.
This year, Core ML has improved its support for stateful models. Rather than maintaining state manually, Core ML now can do this for you and works to reduce some of the overhead previously mentioned.
Let’s now turn our attention to one model type where state can be beneficial. In the previous section, we learned that language models output scores for all words in a vocabulary, where the score indicates the confidence the model assigns for that word coming next. In addition to scores, the model used also output key and value vectors for the given word. These vectors are computed for each word and used by the attention mechanism embedded throughout the network to improve the models ability to generate natural and contextually relevant outputs. To avoid recomputing previous word vectors at each step, they are often stored and reused, this is referred to as the key-value cache, or KV cache for short. This cache sounds like an ideal candidate for our new feature, let’s see how.
Instead of handling the KV cache using the model inputs and outputs, you can now manage it using Core ML states. This can reduce the overhead and improve inference efficiency, leading to faster prediction times.
It should be noted that support for states must be explicitly added to the model during the preparation phase. To learn how, checkout the video on bringing your models to Apple silicon.
You can easily verify if a model has states by inspecting the model in Xcode.
When states are available, they will appear just above the model inputs in the predictions tab of the model preview.
Now, let’s walk through updating the code used for next word prediction to support state. We’ll begin by reviewing the stateless version to highlight the necessary changes. Focusing just on the relevant parts, we start by creating an empty cache to store the key and value vectors.
This cache is then provided to the model as an input, and updated using the values returned by the model. Let’s now walk through the necessary changes to support state.
Most of the code will look familiar with some minor adjustments.
Instead of manually preallocating each state, the model instance is used to create them. In this example, Core ML preallocates buffers to store the key and value vectors and returns a handle to the state. With this handle, you can access these buffers and control state’s lifetime.
Rather than passing in each cache as an input, we now simply pass in the state created by the model instance.
And since the update is performed in-place, we can omit the last step of updating the cache. And that’s it! We’ve updated the code to support states and taken advantage of the speed-up in predicting the next word.
Here is a quick comparison between the KV cache implementations using the Mistral 7 billion model running on a MacBook Pro with an M3 Max. The left shows KV cache implemented without state and the right with state. We see the right one finishes around 5 seconds while the left took approximately 8 seconds, that’s a 1.6x speedup when using state. Performance will, of course, vary depending on your model and hardware, but this gives you a general sense of the gains you can expect when using state.
In this next section, we’ll explore a new feature in Core ML that provides a flexible and efficient way to deploy models with multiple functionality. When we think of a machine learning model, we usually think of something that takes in an input and produces some output, much like a function.
Functions are, in-fact, how neural networks are represented in Core ML. They usually consist of a single function containing a block of operations. A natural extension to this is to support multiple functions, a feature now available in Core ML. Let’s walk through a concrete example, to demonstrate how we can use this feature to efficiently deploy a model with multiple adapters.
In case you’re unfamiliar with adapters, they are small modules embedded into an existing network and trained with its knowledge for another task. They offer an efficient way to extend the functionality of a large pre-trained model without adjusting its weights. This allows a single base model to be shared across multiple adapters. For our example, we’ll use an adapter to influence the style of the images generated by a latent diffusion model.
But what if we wanted to deploy more than one style? Today, we would deploy two or more specialized models, one for each adapter, or pass in the adapter weights as inputs, neither approach is ideal.
With support for multiple functions, we now have another, more efficient, option.
We can now merge multiple adapters with a shared base into a single model, exposing a function for each.
Check out the video on bringing your models to Apple silicon to learn how to export a model with multiple functions. Let’s review the code required to load a model with a specific function.
Loading a multi-function model is simply a matter of specifying the function name.
Once loaded, calling prediction on the model will invoke the specified function, or its default if no function is given. Let’s see this in action.
In this demo, I will use the open-source Stable Diffusion XL model and modified Diffusers app from HuggingFace to generate images from text. The pipeline consists of multiple models, seamlessly stitched together using MLTensor. This includes a Unet model with two functions, each using different adapters that influence the style of the generated image. We can preview the available functions for a model by opening it in Xcode.
This model has two functions, "sticker" and "storybook", and since they have identical inputs and outputs, we can use the same pipeline for both. But this is not required and it's possible that each function has different inputs and outputs. Let’s return to the app, and generate a sticker for our superhero Corgi.
This is great! Let’s now switch to the other function to get a different style of our superhero.
Nice! In this demo, I have shown you how to deploy a single model with multiple adapters, each accessed using their respective function. This feature is versatile and can be used for many other scenarios. I’m excited to see how you use it. In this final section, we will briefly look at some enhancements and new tools to help you better profile and debug your models. Starting with updates to the Core ML performance report. Performance reports can be generated for any connected device without having to write any code. Simply, open a model in Xcode, select the performance tab, click the + button to create a new report, select the device you want to profile, and compute unit to run on before hitting the "Run Test" button.
Once complete, the report displays a summary of load and prediction times along with a breakdown of compute unit usage. This year, the performance report now offers even more information, specifically estimated time and compute device support for each operation. Estimated time shows the time spent on each operation. It is calculated using the median prediction time multiplied by the estimated relative cost for each operation.
It is helpful to identify bottlenecks in your network. Which can be easily done by sorting operations, based on their estimated time.
In addition, you can now hover over unsupported operations to reveal hints for why it wasn’t able to run on a specific compute device.
In this example, the hint suggests the data type is not supported, allowing us to return to the preparation stage to make any necessary changes, to ensure our model is compatible with all compute devices.
For this model, it was simply a matter of updating the precision to Float16.
Along with more information, performance reports can now be exported and compared against other runs. Comparing runs makes it easy to review the impact of changes to your model, all without having to write a single line of code in your application.
Talking of code, sometimes it’s just more convenient to work with it. With the introduction of the MLComputePlan API, you can do just that. Like the performance report, the MLComputePlan offers model debugging and profiling information for Core ML. The API surfaces the model structure and runtime information for each operation, including the supported and preferred compute devices, operation support status, and estimated relative cost as described earlier. And with that, we can now wrap up this video to summarize. New features in Core ML can help you efficiently deploy and run machine learning and AI models on-device. You can now, adopt MLTensor to simplify model integration. Take advantage of state to improve inference efficiency. Use multi-function models to efficiently deploy models with multiple functionality. And utilize the new information available in the performance tools to profile and debug your models. I look forward to seeing what new experiences you make by leveraging powerful on-device machine learning.
-