-
Extend Speech Synthesis with personal and custom voices
Bring the latest advancements in Speech Synthesis to your apps. Learn how you can integrate your custom speech synthesizer and voices into iOS and macOS. We'll show you how SSML is used to generate expressive speech synthesis, and explore how Personal Voice can enable your augmentative and assistive communication app to speak on a person's behalf in an authentic way.
Chapters
- 0:00 - Welcome
- 1:25 - Explore SSML
- 2:37 - Implement a synthesis provider
- 10:01 - Use Personal Voice
Resources
- Audio Unit
- Creating an audio unit extension
- Speech Synthesis Markup Language (SSML)
- Speech synthesis
Related Videos
WWDC20
-
Search this video…
♪ ♪ Grant: Hi, my name is Grant. I’m an Engineer on the Accessibility Team. Many people use speech synthesis across Apple platforms and some people rely on synthesizer voices. These voices are a window into their devices. Therefore, the voices they choose are often a very personal choice.
People using speech synthesis on iOS can already choose from many different voices. Let’s take a look at how you can provide even more. First, we’ll talk about what Speech Synthesis Markup Language is, how it can bring immersive speech output to your custom voices, and why your speech provider should adopt it. Next, we’ll walk through how you can implement a speech synthesis provider to bring your synthesizer and voice experiences across the device. And finally, we’ll dive into Personal Voice. This is a new feature. Now, people can record their voice and then generate a synthesized voice from those recordings. So now, you can synthesize speech with the user's own personal voice. Let’s start by taking a look at SSML. SSML is a W3C standard for representing spoken text. SSML Speech is represented declaratively using XML format with various tags and attributes. You can use these tags to control speech properties like rate and pitch. SSML is used in first-party synthesizers. This includes WebSpeech in WebKit and is the standard input for speech synthesizers. Let’s take a look at how you can use SSML.
Take this example phrase that has a pause in it. We can represent this pause in SSML. We’ll start with our "hello" string, add our one second pause using an SSML break tag, and finish by speeding up "nice to meet you!" We do this by adding an SSML prosody tag and setting the rate attribute to 200%. Now we can take this SSML and create an AVSpeechUtterance to speak with. Next, let’s take a look at how you can implement your own speech synthesizer voices.
So what is a speech synthesizer? A speech synthesizer receives some text and information about desired speech properties in the form of SSML and provides an audio representation of that text.
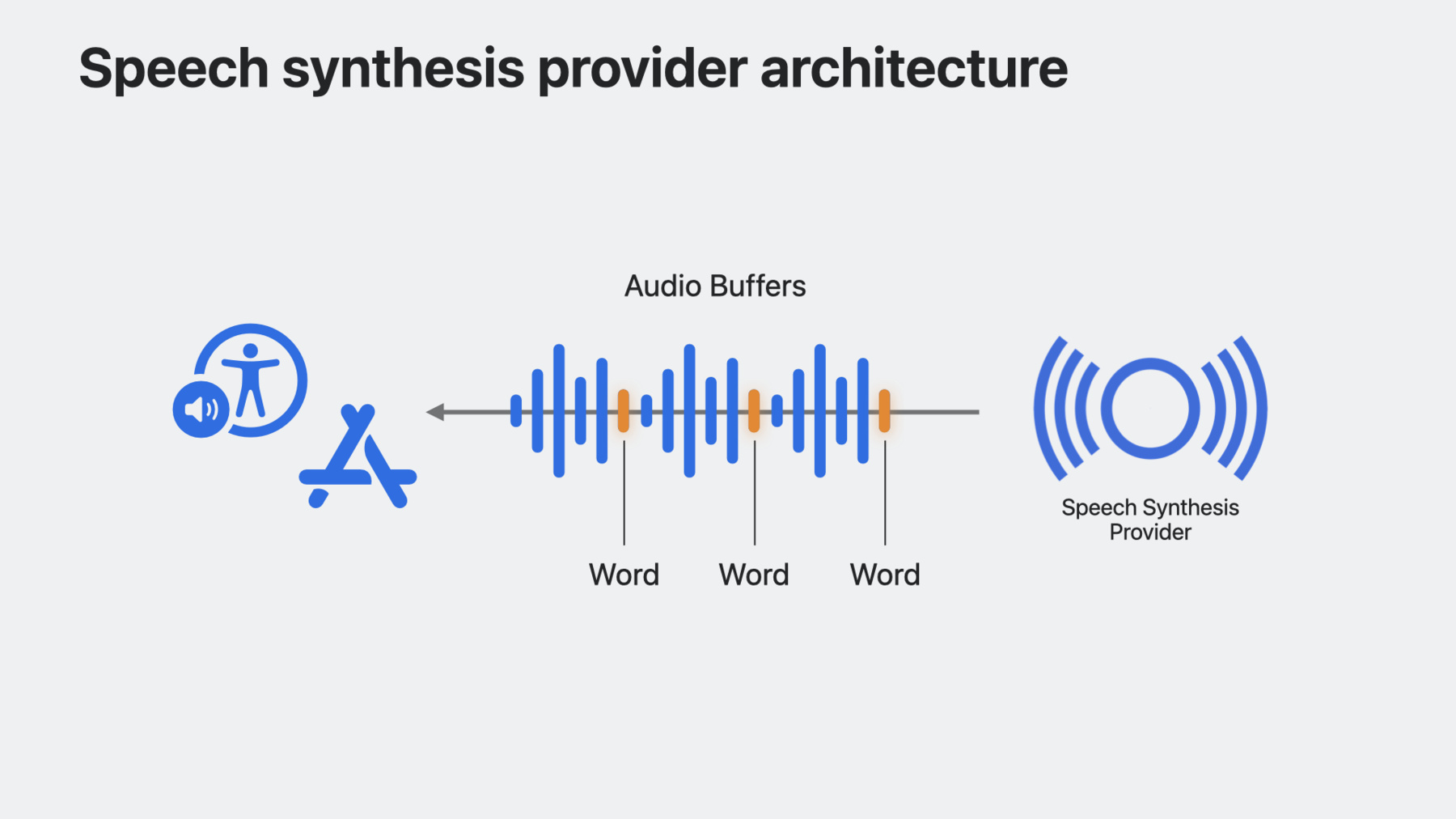
Suppose you have a synthesizer with great new voices and you want to bring it to iOS, macOS, and iPadOS. Speech synthesis providers allow you to implement your own speech synthesizers and voices into our platforms to give even more personalization to users beyond system voices.
Let’s see how this works. Speech Synthesis provider audio unit extensions will be embedded in a host app and will receive speech requests in the form of SSML. The extension will be responsible for rendering audio for the SSML input and optionally returning markers indicating where words occur within those audio buffers. The system will then manage all playback for that speech request. You don't need to handle any audio session management; it's managed internally by the Speech Synthesis Provider framework.
Now that we understand what a synthesizer is, we can start to build a speech synthesizer extension.
Let’s start by creating a new Audio Unit Extension app project in Xcode, then select the "Speech Synthesizer" Audio Unit Type and provide a four character subtype identifier for your synthesizer, as well as a four character identifier for you as a manufacturer. Audio unit extensions are the core architecture upon which speech synthesizer extensions have been built. They allow your synthesizer to run in an extension process instead of in your host app process.
Our app is going to provide a simple interface for buying and selecting a voice that our extension will synthesize speech for. We’ll start by creating a list view that shows our available voices for purchase. Each voice cell will show the voice name and a buy button.
Next, I will populate my list with some voices. Here, WWDCVoice is a simple struct holding the voice name and identifier.
We also need a state variable for keeping track of purchased voices and a new section to display them. Next, let’s create a function for purchasing a voice. Here we can add the newly purchased voice to our list and update our UI accordingly. Take note of the AVSpeechSynthesisProviderVoice method updateSpeechVoices. That is how your app can signal that the set of available voices for your synthesizer has changed and the system voice list should be rebuilt. In our example, we can make this call after completing an in-app purchase for a voice. We also need a way to keep tabs on which voices are available in our speech synthesizer extension. This can be done by creating an instance of UserDefaults that will be shared through an app group. An app group will allow us to share this voice list between our host app and our extension. We are explicitly specifying a suite name that we provided when creating the app group. This ensures the host app and extension read from the same domain.
Taking a look back at the purchase function, I have implemented a method to update my user defaults when a new voice is purchased. AVSpeechSynthesizer also has new API to listen for a change in available system voices. The set of system voices can change when a user deletes a voice or downloads a new one. You can subscribe to the availableVoicesDidChangeNotification to update your list of voices based on these changes.
Now that our host app is done, let's fill in the audio unit, which consists of four key components.
The first thing we’ll need to add is some way to inform the system of what voices our synthesizer will provide. This is accomplished by overriding the speechVoices getter to provide a list of voices and reading from our app group UserDefaults domain we specified earlier. For each item in our voice list, we’ll construct a US English AVSpeechSynthesisProviderVoice. Next, we need some way for the system to tell the synthesizer what text to synthesize. The synthesizeSpeechRequest method will be called when the system wants to signal to an extension that it should start synthesizing some text. The argument to this method will be an instance of AVSpeechSynthesisProviderRequest containing SSML and which voice to speak with. Next, I’ll call a helper method I’ve created in my speech engine implementation. In this example, my getAudioBuffer method will generate audio data based on the voice specified in the request and the SSML input. We’ll also set an instance variable, called framePosition, to 0 in order to keep track of how many frames we’ve rendered as the render block is called and we copy frames out of the buffer. The system also needs a way to signal to a synthesizer to stop synthesizing audio and discard the current speech request. This is accomplished with cancelSpeechRequest, where we will simply discard the current buffer. Finally, we need to implement the render block. The render block is called by the system with a desired frameCount. The audio unit is then responsible for filling the requested number of frames into the outputAudioBuffer. Next, we will set ourselves up with a reference to the target buffer and the buffer we generated and stored earlier during the synthesizeSpeechRequest call. Then, we’ll copy the frames into the target buffer. And then finally, once the audio unit has exhausted all the buffers for the current speech request, the actionFlags argument should be set to offlineUnitRenderAction_Complete to signal to the system that rendering has completed and there are no more audio buffers to be rendered. Let's see it in action! This is my speech synthesizer app. I will purchase a voice and navigate to a view where I can synthesize speech using my new voice and speech engine. First, I will give the synthesizer an input of "hello." Synthesized voice: Hello. Grant: Then I’ll give the input "goodbye." Synthesized voice: Goodbye.
Grant: We’ve now implemented a synthesis provider and created a hosting app that provides voices you can use across the system, from VoiceOver to your own apps! We can't wait to see what new voices and text-to-speech experiences you craft using these APIs. Let’s move on and talk about a new feature called Personal Voice.
People can now record and recreate their voice on iOS and macOS using the power of their device.
Your Personal Voice is generated on the device and not on a server. This voice will appear amongst the rest of the System voices and can be used with a new feature called Live Speech. Live Speech is a type-to-speak feature on iOS, iPadOS, macOS, and watchOS that lets a person synthesize speech with their own voice on the fly.
You can request access to synthesize speech with these voices using a new request authorization API for Personal Voice. Keep in mind that usage of Personal Voice is sensitive and should be primarily used for augmentative or alternative communication apps. Let’s checkout an AAC app I’ve made to use Personal Voice.
My app has two buttons that will speak common phrases I find myself saying at WWDC and a button for requesting access to use Personal Voice. Authorization can be requested with a new API called requestPersonalVoiceAuthorization on AVSpeechSynthesizer. Once authorized, Personal Voices will appear alongside System voices in the AVSpeechSynthesisVoice API speechVoices and will be denoted with a new voiceTrait called isPersonalVoice.
Now that I have access to Personal Voice, I can use it to speak with.
Let’s check out a demo of Personal Voice in action. First, I’ll tap the “Use Personal Voice” button to request authorization, and once authorized, I can tap a symbol to hear my voice. Personal voice: Hi, my name is Grant. Welcome to WWDC23. Grant: Isn’t that amazing? And now you can use these voices in your apps, too.
Now that we discussed SSML, you should use it to standardize speech input and build a rich speech experience in your apps. We also walked through how to implement your Speech Synthesizer into Apple platforms, so now you can provide great new speech voices that people can use across the system. And finally, with Personal Voice, you can bring even more of a personal touch to synthesis in your apps, especially for people who may be at risk of losing their own voice. We are super excited to see what experiences you create using these APIs. Thanks for watching.
-
-
2:10 - SSML phrase
<speak> Hello <break time="1s"/> <prosody rate="200%">nice to meet you!</prosody> </speak> -
2:29 - SSML utterance
let ssml = """ <speak> Hello <break time="1s" /> <prosody rate="200%">nice to meet you!</prosody> </speak> """ guard let ssmlUtterance = AVSpeechUtterance(ssmlRepresentation: ssml) else { return } self.synthesizer.speak(ssmlUtterance) -
4:33 - Create a host app
struct ContentView: View { var body: some View { List { Section("My Awesome Voices") { ForEach(availableVoices) { voice in HStack { Text(voice.name) Spacer() Button("Buy") { // Buy this voice... } } } } } } var availableVoices: [WWDCVoice] { return [ WWDCVoice(name: "Screen Reader Voice", id: "com.example.screen-reader-voice"), WWDCVoice(name: "Reading Voice", id: "com.example.reading-voice") ] } } -
5:04 - Keep track of purchased voices
struct ContentView: View { @State var purchasedVoices: [WWDCVoice] = [] var body: some View { NavigationStack { List { MyAwesomeVoicesSection Section("Purchased Voices") { ForEach(purchasedVoices) { voice in NavigationLink { // Destination View } label: { Text(voice.name) } } } } } } } -
5:13 - Inform the system when available voices change
struct ContentView: View { @State var purchasedVoices: [WWDCVoice] = [] var body: some View { List { MyAwesomeVoicesSection PurchasedVoicesSection } } func purchase(voice: WWDCVoice) { // Append voice to list of purchased voices purchasedVoices.append(voice) // Inform system of change in voices AVSpeechSynthesisProviderVoice.updateSpeechVoices() } } -
5:39 - Update UI with purchased voices
struct ContentView: View { @State var purchasedVoices: [WWDCVoice] = [] var body: some View { List { Section("My Awesome Voices") { ForEach(availableVoices.filter { !purchasedVoices.contains($0) }) { voice in HStack { Text(voice.name) Spacer() Button("Buy") { purchase(voice: voice) } } } } PurchasedVoicesSection } } } -
5:46 - Save available voices into UserDefaults
struct ContentView: View { let groupDefaults = UserDefaults(suiteName: "group.com.example.SpeechSynthesizerApp")! @State var purchasedVoices: [WWDCVoice] = [] var body: some View { List { MyAwesomeVoicesSection PurchasedVoicesSection } } func purchase(voice: WWDCVoice) { // Append voice to list of purchased voices purchasedVoices.append(voice) // Write purchasedVoices to defaults updatePurchasedVoices() // Inform system of change in voices AVSpeechSynthesisProviderVoice.updateSpeechVoices() } } -
6:25 - Monitor for system voice changes
struct ContentView: View { @State var systemVoices: [AVSpeechSynthesisVoice] = AVSpeechSynthesisVoice.speechVoices() var body: some View { List { MyAwesomeVoicesSection PurchasedVoicesSection Section("System Voices") { ForEach(systemVoices.filter { $0.language == "en-US" }) { voice in Text(voice.name) } } } .onReceive(NotificationCenter.default .publisher(for: AVSpeechSynthesizer.availableVoicesDidChangeNotification)) { _ in systemVoices = AVSpeechSynthesisVoice.speechVoices() } } } -
6:53 - Override speechVoices getter
// Implement a synthesis provider public class WWDCSynthAudioUnit: AVSpeechSynthesisProviderAudioUnit { public override var speechVoices: [AVSpeechSynthesisProviderVoice] { get { } } } -
7:02 - Use UserDefaults to provide set of available voices
public class WWDCSynthAudioUnit: AVSpeechSynthesisProviderAudioUnit { public override var speechVoices: [AVSpeechSynthesisProviderVoice] { get { let voices: [String : String] = groupDefaults.value(forKey: "voices") as? [String : String] ?? [:] return voices.map { key, value in return AVSpeechSynthesisProviderVoice(name: value, identifier: key, primaryLanguages: ["en-US"], supportedLanguages: ["en-US"] ) } } } } -
7:22 - Use your synthesis engine on each synthesis request
public class WWDCSynthAudioUnit: AVSpeechSynthesisProviderAudioUnit { public override func synthesizeSpeechRequest(speechRequest: AVSpeechSynthesisProviderRequest) { currentBuffer = getAudioBuffer(for: speechRequest.voice, with: speechRequest.ssmlRepresentation) framePosition = 0 } } -
8:14 - Handle request cancellation
public class WWDCSynthAudioUnit: AVSpeechSynthesisProviderAudioUnit { public override func synthesizeSpeechRequest(speechRequest: AVSpeechSynthesisProviderRequest) { currentBuffer = getAudioBuffer(for: speechRequest.voice, with: speechRequest.ssmlRepresentation) framePosition = 0 } public override func cancelSpeechRequest() { currentBuffer = nil } } -
8:28 - Override internalRenderBlock
public class WWDCSynthAudioUnit: AVSpeechSynthesisProviderAudioUnit { public override var internalRenderBlock: AUInternalRenderBlock { return { [weak self] actionFlags, timestamp, frameCount, outputBusNumber, outputAudioBufferList, _, _ in guard let self else { return kAudio_ParamError } return noErr } } } -
8:42 - Implement the render block
public class WWDCSynthAudioUnit: AVSpeechSynthesisProviderAudioUnit { public override var internalRenderBlock: AUInternalRenderBlock { return { [weak self] actionFlags, timestamp, frameCount, outputBusNumber, outputAudioBufferList, _, _ in guard let self else { return kAudio_ParamError } // This is the audio buffer we are going to fill up var unsafeBuffer = UnsafeMutableAudioBufferListPointer(outputAudioBufferList)[0] let frames = unsafeBuffer.mData!.assumingMemoryBound(to: Float32.self) var sourceBuffer = UnsafeMutableAudioBufferListPointer(self.currentBuffer!.mutableAudioBufferList)[0] let sourceFrames = sourceBuffer.mData!.assumingMemoryBound(to: Float32.self) for frame in 0..<frameCount { if frames.count > frame && sourceFrames.count > self.framePosition { frames[Int(frame)] = sourceFrames[Int(self.framePosition)] self.framePosition += 1 if self.framePosition >= self.currentBuffer!.frameLength { break } } } return noErr } } } -
11:10 - Request authorization for Personal Voice
struct ContentView: View { @State private var personalVoices: [AVSpeechSynthesisVoice] = [] func fetchPersonalVoices() async { AVSpeechSynthesizer.requestPersonalVoiceAuthorization() { status in if status == .authorized { personalVoices = AVSpeechSynthesisVoice.speechVoices().filter { $0.voiceTraits.contains(.isPersonalVoice) } } } } } -
11:34 - Use Personal Voice
func speakUtterance(string: String) { let utterance = AVSpeechUtterance(string: string) if let voice = personalVoices.first { utterance.voice = voice syntheizer.speak(utterance) } }
-