-
Explore os LLMs (grandes modelos de linguagem) no Apple Silicon com o MLX
Descubra o MLX LM, criado especificamente para simplificar e agilizar o trabalho com LLMs (grandes modelos de linguagem) no Apple Silicon. Vamos abordar como ajustar e executar inferências em LLMs (grandes modelos de linguagem) avançados no Mac e como integrar isso perfeitamente a apps e projetos do Swift.
Capítulos
- 0:00 - Introdução
- 3:07 - Introdução ao LM MLX
- 3:51 - Geração de texto
- 8:42 - Quantização
- 11:39 - Ajustes
- 17:02 - LLMs no MLXSwift
Recursos
- MLX Swift Examples
- MLX Examples
- MLX Swift
- MLX LM - Python API
- MLX Explore - Python API
- MLX Framework
- MLX Llama Inference
- MLX
Vídeos relacionados
WWDC25
-
Buscar neste vídeo...
-
-
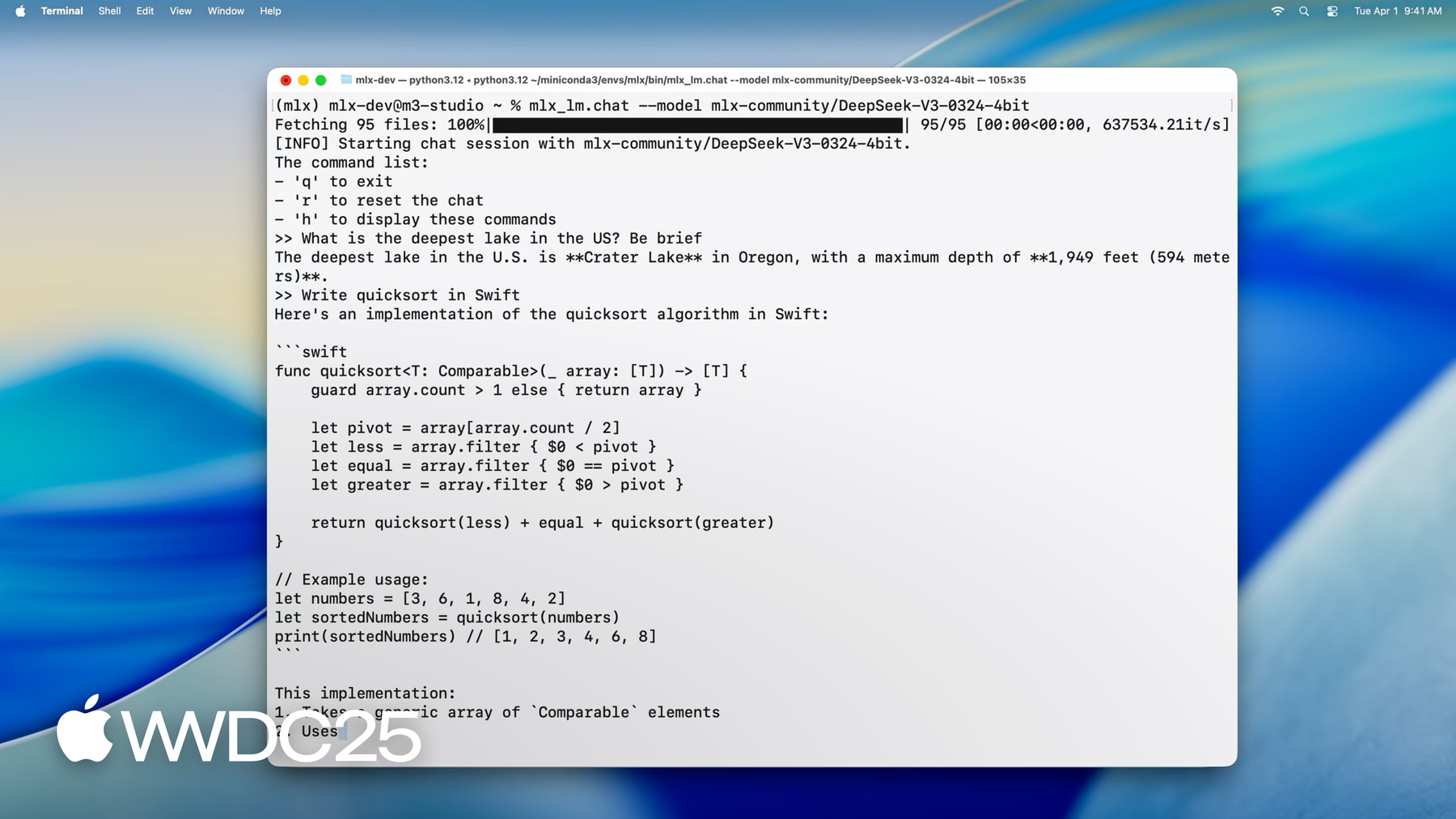
1:12 - Running DeepSeek AI's model with MLX LM
mlx_lm.chat --model mlx-community/DeepSeek-V3-0324-4bit -
3:51 - Text generation with MLX LM
mlx_lm.generate --model "mlx-community/Mistral-7B-Instruct-v0.3-4bit" \ --prompt "Write a quick sort in Swift" -
4:35 - Changing the model's behavior with flags
mlx_lm.generate --model "mlx-community/Mistral-7B-Instruct-v0.3-4bit" \ --prompt "Write a quick sort in Swift" \ --top-p 0.5 \ --temp 0.2 \ --max-tokens 1024 -
4:48 - Getting help for MLX LM
mlx_lm.generate --help -
5:26 - MLX LM Python API
# Using MLX LM from Python from mlx_lm import load, generate # Load the model and tokenizer directly from HF model, tokenizer = load("mlx-community/Mistral-7B-Instruct-v0.3-4bit") # Prepare the prompt for the model prompt = "Write a quick sort in Swift" messages = [{"role": "user", "content": prompt}] prompt = tokenizer.apply_chat_template( messages, add_generation_prompt=True ) # Generate the text text = generate(model, tokenizer, prompt=prompt, verbose=True) -
6:24 - Inspecting model architecture
from mlx_lm import load, generate model, tokenizer = load("mlx-community/Mistral-7B-Instruct-v0.3-4bit") print(model) print(model.parameters()) print(model.layers[0].self_attn) -
8:01 - Generation with KV cache
from mlx_lm import load, generate from mlx_lm.models.cache import make_prompt_cache # Load the model and tokenizer directly from HF model, tokenizer = load("mlx-community/Mistral-7B-Instruct-v0.3-4bit") # Prepare the prompt for the model prompt = "Write a quick sort in Swift" messages = [{"role": "user", "content": prompt}] prompt = tokenizer.apply_chat_template( messages, add_generation_prompt=True ) cache = make_prompt_cache(model) # Generate the text text = generate(model, tokenizer, prompt=prompt, prompt_cache=cache, verbose=True) -
9:37 - Quantization
mlx_lm.convert --hf-path "mistralai/Mistral-7B-Instruct-v0.3" \ --mlx-path "./mistral-7b-v0.3-4bit" \ --dtype float16 \ --quantize --q-bits 4 --q-group-size 64 -
10:33 - Model quantization with MLX LM in Python
from mlx_lm.convert import convert # We can choose a different quantization per layer def mixed_quantization(layer_path, layer, model_config): if "lm_head" in layer_path or "embed_tokens" in layer_path: return {"bits": 6, "group_size": 64} elif hasattr(layer, "to_quantized"): return {"bits": 4, "group_size": 64} else: return False # Convert can be used to change precision, quantize and upload models to HF convert( hf_path="mistralai/Mistral-7B-Instruct-v0.3", mlx_path="./mistral-7b-v0.3-mixed-4-6-bit", quantize=True, quant_predicate=mixed_quantization ) -
13:37 - Model fine-tuning
mlx_lm.lora --model "mlx-community/Mistral-7B-Instruct-v0.3-4bit" --train --data /path/to/our/data/folder --iters 300 --batch-size 16 -
15:06 - Prompting before fine-tuning
mlx_lm.generate --model "./mistral-7b-v0.3-4bit" \ --prompt "Who won the latest super bowl?" -
15:34 - Fine-tuning to learn new knowledge
mlx_lm.lora --model "./mistral-7b-v0.3-4bit" --train --data ./data --iters 300 --batch-size 8 --mask-prompt --learning-rate 1e-5 -
15:48 - Prompting after fine-tuning
mlx_lm.generate --model "mlx-community/Mistral-7B-Instruct-v0.3-4bit" \ --prompt "Who won the latest super bowl?" \ --adapter "adapters" -
16:29 - Fusing models
mlx_lm.fuse --model "mlx-community/Mistral-7B-Instruct-v0.3-4bit" --adapter-path "path/to/trained/adapters" \ --save-path "fused-mistral-7b-v0.3-4bit" \ --upload-repo "my-name/fused-mistral-7b-v0.3-4bit" # Fusing our fine-tuned model adapters mlx_lm.fuse --model "./mistral-7b-v0.3-4bit" \ --adapter-path "adapters" \ --save-path "fused-mistral-7b-v0.3-4bit" -
17:14 - LLMs in MLX Swift
import Foundation import MLX import MLXLMCommon import MLXLLM @main struct LLM { static func main() async throws { // Load the model and tokenizer directly from HF let modelId = "mlx-community/Mistral-7B-Instruct-v0.3-4bit" let modelFactory = LLMModelFactory.shared let configuration = ModelConfiguration(id: modelId) let model = try await modelFactory.loadContainer(configuration: configuration) try await model.perform({context in // Prepare the prompt for the model let prompt = "Write a quicksort in Swift" let input = try await context.processor.prepare(input: UserInput(prompt: prompt)) // Generate the text let params = GenerateParameters(temperature: 0.0) let tokenStream = try generate(input: input, parameters: params, context: context) for await part in tokenStream { print(part.chunk ?? "", terminator: "") } }) } } -
18:00 - Generation with KV cache in MLX Swift
import Foundation import MLX import MLXLMCommon import MLXLLM @main struct LLM { static func main() async throws { // Load the model and tokenizer directly from HF let modelId = "mlx-community/Mistral-7B-Instruct-v0.3-4bit" let modelFactory = LLMModelFactory.shared let configuration = ModelConfiguration(id: modelId) let model = try await modelFactory.loadContainer(configuration: configuration) try await model.perform({context in // Prepare the prompt for the model let prompt = "Write a quicksort in Swift" let input = try await context.processor.prepare(input: UserInput(prompt: prompt)) // Create the key-value cache let generateParameters = GenerateParameters() let cache = context.model.newCache(parameters: generateParameters) // Low level token iterator let tokenIter = try TokenIterator(input: input, model: context.model, cache: cache, parameters: generateParameters) let tokenStream = generate(input: input, context: context, iterator: tokenIter) for await part in tokenStream { print(part.chunk ?? "", terminator: "") } }) } }
-
-
- 0:00 - Introdução
A MLX é uma biblioteca de código aberto otimizada para Apple Silicon que permite aprendizado de máquina eficiente em computadores Mac. Ela usa o Metal para aceleração da GPU e memória unificada para uma colaboração perfeita entre CPU e GPU. A MLX é compatível com Python, Swift, C++ e C. O MLX-LM, uma biblioteca Python e ferramentas CLI, simplifica a execução, o ajuste fino e a integração de LLMs (grandes modelos de linguagem) em Apple Silicon. Você pode carregar, interagir e gerar textos a partir de modelos de última geração, como o modelo de parâmetro 670B da DeepSeek AI, localmente no Mac com velocidade e desempenho impressionantes.
- 3:07 - Introdução ao LM MLX
O MLX-LM é um pacote Python criado com base na MLX para executar e testar LLMs (grandes modelos de linguagem). Ele oferece ferramentas de linha de comando e uma API Python para geração de textos e ajuste fino, com integração ao Hugging Face para download e compartilhamento de modelos. Instale-o via "pip install mlx-lm".
- 3:51 - Geração de texto
O MLX-LM é uma ferramenta que permite gerar textos usando modelos de linguagem do Hugging Face ou modelos armazenados localmente. Ele fornece duas interfaces principais: uma ferramenta de linha de comando e uma API Python. A ferramenta de linha de comando permite gerar textos com prompts simples e opções básicas de personalização. A API Python oferece mais controle, permitindo carregar modelos, gerar textos, inspecionar e modificar a arquitetura do modelo. A API Python também aceita conversas multiturno por meio de um cache chave-valor, que armazena resultados intermediários, economizando tempo e computação. Isso transforma o MLX-LM na ferramenta perfeita para criar chatbots, assistentes virtuais e outros apps interativos que exigem retenção de contexto em vários prompts.
- 8:42 - Quantização
A quantização de modelos é usada para reduzir a precisão de modelos de aprendizado de máquina, deixando-os menores e mais rápidos, especialmente para implantação em dispositivos menores. A MLX simplifica esse processo com sua API de quantização. Você pode usar o comando mlx_lm.convert para baixar, converter e salvar modelos em uma etapa. Esse comando permite um controle refinado, possibilitando a aplicação de diferentes configurações de quantização a várias partes do modelo e atingindo equilíbrio entre qualidade e eficiência. Os modelos quantizados podem ser usados para inferência ou treinamento na MLX ou compartilhados com outras pessoas via Hugging Face.
- 11:39 - Ajustes
O MLX-LM permite ajustar grandes modelos de linguagem localmente em um Mac sem escrever código ou enviar dados para a nuvem. Esse processo adapta modelos de uso geral a domínios ou tarefas específicas usando conjuntos de dados menores e específicos para o domínio. O MLX-LM aceita dois métodos principais de ajuste fino: ajuste fino do modelo completo e treinamento de adaptadores de baixa classificação. O treinamento dos adaptadores é mais rápido, leve e eficiente em termos de memória, tornando-o ideal para hardware local. Você pode iniciar o ajuste fino com um único comando, especificando o modelo, o conjunto de dados e a duração do treinamento. Para ter mais controle, arquivos de configuração de treinamento estão disponíveis. Após o ajuste fino, os adaptadores podem ser fundidos de novo no modelo base, criando um modelo atualizado e autônomo que pode ser distribuído, usado e carregado nos repositórios do Hugging Face para compartilhamento.
- 17:02 - LLMs no MLXSwift
A MLX traz simplicidade e flexibilidade ao Swift no uso de grandes modelos de linguagem. Ele permite carregar, tokenizar e gerar textos com modelos quantizados usando apenas algumas linhas de código. Gerenciar conversas multituno requer apenas algumas linhas extras para criar um cache de chave-valor. A MLX fornece operações principais de código aberto em C, C++, Python e Swift, com APIs de alto nível em Python e Swift, permitindo fluxos de trabalho eficientes de aprendizado de máquina no hardware da Apple.