-
Explora grandes modelos de lenguaje en el chip de Apple con MLX
Descubre MLX LM, diseñado específicamente para que trabajar con grandes modelos de lenguaje sea simple y eficiente en el chip de Apple. Mencionaremos cómo ajustar y ejecutar inferencias en grandes modelos de lenguaje de última generación en tu Mac, y cómo integrarlos en apps y proyectos basados en Swift.
Capítulos
- 0:00 - Introducción
- 3:07 - Introducción de MLX LM
- 3:51 - Generación de texto
- 8:42 - Cuantización
- 11:39 - Ajuste
- 17:02 - Grandes modelos de lenguaje en MLXSwift
Recursos
- MLX Swift Examples
- MLX Examples
- MLX Swift
- MLX LM - Python API
- MLX Explore - Python API
- MLX Framework
- MLX Llama Inference
- MLX
Videos relacionados
WWDC25
-
Buscar este video…
-
-
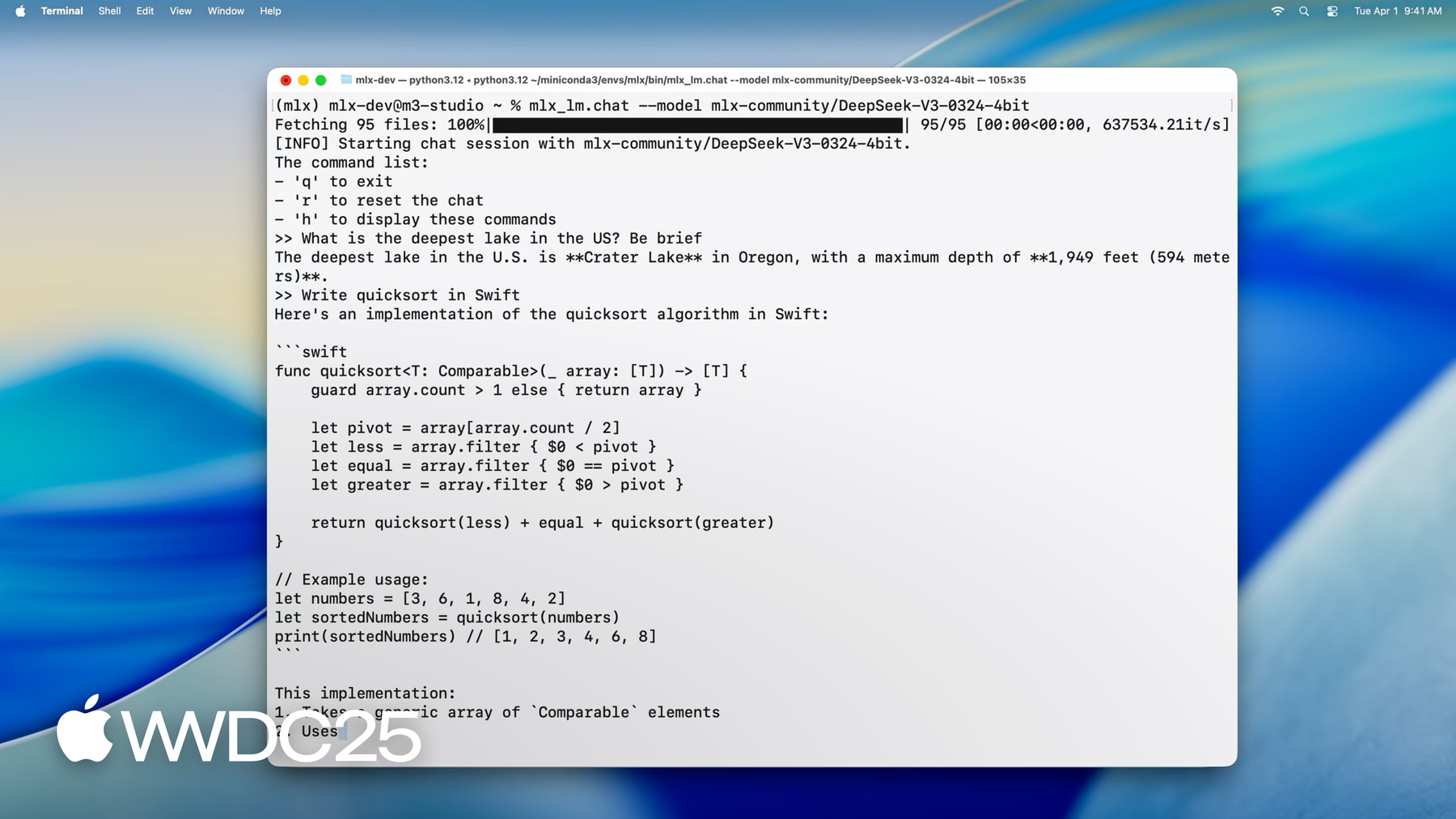
1:12 - Running DeepSeek AI's model with MLX LM
mlx_lm.chat --model mlx-community/DeepSeek-V3-0324-4bit -
3:51 - Text generation with MLX LM
mlx_lm.generate --model "mlx-community/Mistral-7B-Instruct-v0.3-4bit" \ --prompt "Write a quick sort in Swift" -
4:35 - Changing the model's behavior with flags
mlx_lm.generate --model "mlx-community/Mistral-7B-Instruct-v0.3-4bit" \ --prompt "Write a quick sort in Swift" \ --top-p 0.5 \ --temp 0.2 \ --max-tokens 1024 -
4:48 - Getting help for MLX LM
mlx_lm.generate --help -
5:26 - MLX LM Python API
# Using MLX LM from Python from mlx_lm import load, generate # Load the model and tokenizer directly from HF model, tokenizer = load("mlx-community/Mistral-7B-Instruct-v0.3-4bit") # Prepare the prompt for the model prompt = "Write a quick sort in Swift" messages = [{"role": "user", "content": prompt}] prompt = tokenizer.apply_chat_template( messages, add_generation_prompt=True ) # Generate the text text = generate(model, tokenizer, prompt=prompt, verbose=True) -
6:24 - Inspecting model architecture
from mlx_lm import load, generate model, tokenizer = load("mlx-community/Mistral-7B-Instruct-v0.3-4bit") print(model) print(model.parameters()) print(model.layers[0].self_attn) -
8:01 - Generation with KV cache
from mlx_lm import load, generate from mlx_lm.models.cache import make_prompt_cache # Load the model and tokenizer directly from HF model, tokenizer = load("mlx-community/Mistral-7B-Instruct-v0.3-4bit") # Prepare the prompt for the model prompt = "Write a quick sort in Swift" messages = [{"role": "user", "content": prompt}] prompt = tokenizer.apply_chat_template( messages, add_generation_prompt=True ) cache = make_prompt_cache(model) # Generate the text text = generate(model, tokenizer, prompt=prompt, prompt_cache=cache, verbose=True) -
9:37 - Quantization
mlx_lm.convert --hf-path "mistralai/Mistral-7B-Instruct-v0.3" \ --mlx-path "./mistral-7b-v0.3-4bit" \ --dtype float16 \ --quantize --q-bits 4 --q-group-size 64 -
10:33 - Model quantization with MLX LM in Python
from mlx_lm.convert import convert # We can choose a different quantization per layer def mixed_quantization(layer_path, layer, model_config): if "lm_head" in layer_path or "embed_tokens" in layer_path: return {"bits": 6, "group_size": 64} elif hasattr(layer, "to_quantized"): return {"bits": 4, "group_size": 64} else: return False # Convert can be used to change precision, quantize and upload models to HF convert( hf_path="mistralai/Mistral-7B-Instruct-v0.3", mlx_path="./mistral-7b-v0.3-mixed-4-6-bit", quantize=True, quant_predicate=mixed_quantization ) -
13:37 - Model fine-tuning
mlx_lm.lora --model "mlx-community/Mistral-7B-Instruct-v0.3-4bit" --train --data /path/to/our/data/folder --iters 300 --batch-size 16 -
15:06 - Prompting before fine-tuning
mlx_lm.generate --model "./mistral-7b-v0.3-4bit" \ --prompt "Who won the latest super bowl?" -
15:34 - Fine-tuning to learn new knowledge
mlx_lm.lora --model "./mistral-7b-v0.3-4bit" --train --data ./data --iters 300 --batch-size 8 --mask-prompt --learning-rate 1e-5 -
15:48 - Prompting after fine-tuning
mlx_lm.generate --model "mlx-community/Mistral-7B-Instruct-v0.3-4bit" \ --prompt "Who won the latest super bowl?" \ --adapter "adapters" -
16:29 - Fusing models
mlx_lm.fuse --model "mlx-community/Mistral-7B-Instruct-v0.3-4bit" --adapter-path "path/to/trained/adapters" \ --save-path "fused-mistral-7b-v0.3-4bit" \ --upload-repo "my-name/fused-mistral-7b-v0.3-4bit" # Fusing our fine-tuned model adapters mlx_lm.fuse --model "./mistral-7b-v0.3-4bit" \ --adapter-path "adapters" \ --save-path "fused-mistral-7b-v0.3-4bit" -
17:14 - LLMs in MLX Swift
import Foundation import MLX import MLXLMCommon import MLXLLM @main struct LLM { static func main() async throws { // Load the model and tokenizer directly from HF let modelId = "mlx-community/Mistral-7B-Instruct-v0.3-4bit" let modelFactory = LLMModelFactory.shared let configuration = ModelConfiguration(id: modelId) let model = try await modelFactory.loadContainer(configuration: configuration) try await model.perform({context in // Prepare the prompt for the model let prompt = "Write a quicksort in Swift" let input = try await context.processor.prepare(input: UserInput(prompt: prompt)) // Generate the text let params = GenerateParameters(temperature: 0.0) let tokenStream = try generate(input: input, parameters: params, context: context) for await part in tokenStream { print(part.chunk ?? "", terminator: "") } }) } } -
18:00 - Generation with KV cache in MLX Swift
import Foundation import MLX import MLXLMCommon import MLXLLM @main struct LLM { static func main() async throws { // Load the model and tokenizer directly from HF let modelId = "mlx-community/Mistral-7B-Instruct-v0.3-4bit" let modelFactory = LLMModelFactory.shared let configuration = ModelConfiguration(id: modelId) let model = try await modelFactory.loadContainer(configuration: configuration) try await model.perform({context in // Prepare the prompt for the model let prompt = "Write a quicksort in Swift" let input = try await context.processor.prepare(input: UserInput(prompt: prompt)) // Create the key-value cache let generateParameters = GenerateParameters() let cache = context.model.newCache(parameters: generateParameters) // Low level token iterator let tokenIter = try TokenIterator(input: input, model: context.model, cache: cache, parameters: generateParameters) let tokenStream = generate(input: input, context: context, iterator: tokenIter) for await part in tokenStream { print(part.chunk ?? "", terminator: "") } }) } }
-
-
- 0:00 - Introducción
MLX es una biblioteca de código abierto optimizada para el Apple Chip que permite un aprendizaje automático eficiente en computadoras Mac. Usa Metal para la aceleración del GPU y memoria unificada para una colaboración fluida entre el CPU y el GPU. MLX admite Python, Swift, C++ y C. MLX LM, una biblioteca de Python y herramientas CLI, simplifica la ejecución, el ajuste y la integración de modelos de lenguaje de gran tamaño en el Apple Chip. Puedes cargar y generar texto e interactuar con él a partir de modelos modernos, como el modelo de parámetros 670B de DeepSeek AI, de forma local en tu Mac con una velocidad y un rendimiento impresionantes.
- 3:07 - Introducción de MLX LM
MLX LM es un paquete de Python creado sobre MLX para ejecutar modelos de lenguaje de gran tamaño y experimentar con ellos. Ofrece herramientas de línea de comandos y una API de Python para la generación y el ajuste de texto, con integración en Hugging Face para descargar y compartir modelos. Se debe instalar con pip install mlx-lm.
- 3:51 - Generación de texto
MLX LM es una herramienta que permite la generación de texto con modelos de lenguaje de Hugging Face o almacenados localmente. Ofrece dos interfaces principales: una herramienta de línea de comandos y una API de Python. La herramienta de línea de comandos permite generar texto con prompts simples y opciones de personalización básicas. La API de Python ofrece más control, lo que te permite cargar modelos, generar texto e inspeccionar y modificar la arquitectura del modelo. También admite conversaciones de varios turnos a través de una caché de clave-valor, que almacena de manera eficiente los resultados intermedios, ahorrando tiempo y cálculos. Esto hace que MLX LM sea adecuado para crear chatbots, asistentes virtuales y otras aplicaciones interactivas que requieren retención de contexto en varias prompts.
- 8:42 - Cuantización
La cuantificación de modelos es una técnica que se usa para reducir la precisión de los modelos de aprendizaje automático, lo que los hace más pequeños y rápidos, especialmente para su implementación en dispositivos más pequeños. MLX simplifica este proceso con su API de cuantificación. Puedes usar el comando mlx_lm.convert para descargar, convertir y guardar modelos en un solo paso. Este permite un control exhaustivo, con el que puedes aplicar diferentes configuraciones de cuantificación a varias partes del modelo, logrando un equilibrio entre calidad y eficiencia. Los modelos cuantificados se pueden usar inmediatamente para inferencias o entrenamiento dentro de MLX o compartirse con otros a través de Hugging Face.
- 11:39 - Ajuste
MLX LM permite ajustar modelos de lenguaje de gran tamaño de forma local en la Mac, sin escribir código ni enviar datos a la nube. Este proceso adapta modelos de propósito general a dominios o tareas específicos mediante conjuntos de datos más pequeños y específicos del dominio. MLX LM admite dos métodos de ajuste principales: de modelo completo y entrenamiento de adaptadores de bajo rango. El entrenamiento de adaptadores es más rápido, liviano y eficiente respecto al uso de memoria, lo que lo hace ideal para el hardware local. Puedes iniciar el ajuste con un solo comando, especificando el modelo, el conjunto de datos y la duración del entrenamiento. Para un mayor control, están disponibles los archivos de configuración de entrenamiento. Después del ajuste, los adaptadores se pueden fusionar nuevamente con el modelo base, creando un modelo autónomo y actualizado que se puede distribuir y usar fácilmente, e incluso cargar en los repositorios de Hugging Face para compartir.
- 17:02 - Grandes modelos de lenguaje en MLXSwift
MLX aporta simplicidad y flexibilidad a Swift para usar modelos de lenguaje de gran tamaño. Permite cargar, tokenizar y generar texto con modelos cuantificados con solo unas pocas líneas de código. La administración de conversaciones de varios turnos requiere solo unas pocas líneas adicionales para crear una caché de clave-valor. MLX ofrece operaciones centrales de código abierto en C, C++, Python y Swift, con API de alto nivel en Python y Swift, lo que permite flujos de trabajo de aprendizaje automático eficientes en el hardware de Apple.