-
Advances in Speech Recognition
Speech Recognizer can now be used locally on iOS or macOS devices with no network connection. Learn how you can bring text-to-speech support to your app while maintaining privacy and eliminating the limitations of server-based processing. Speech recognition API has also been enhanced to provide richer analytics including speaking rate, pause duration, and voice quality.
Resources
Related Videos
WWDC23
WWDC19
WWDC16
-
Search this video…
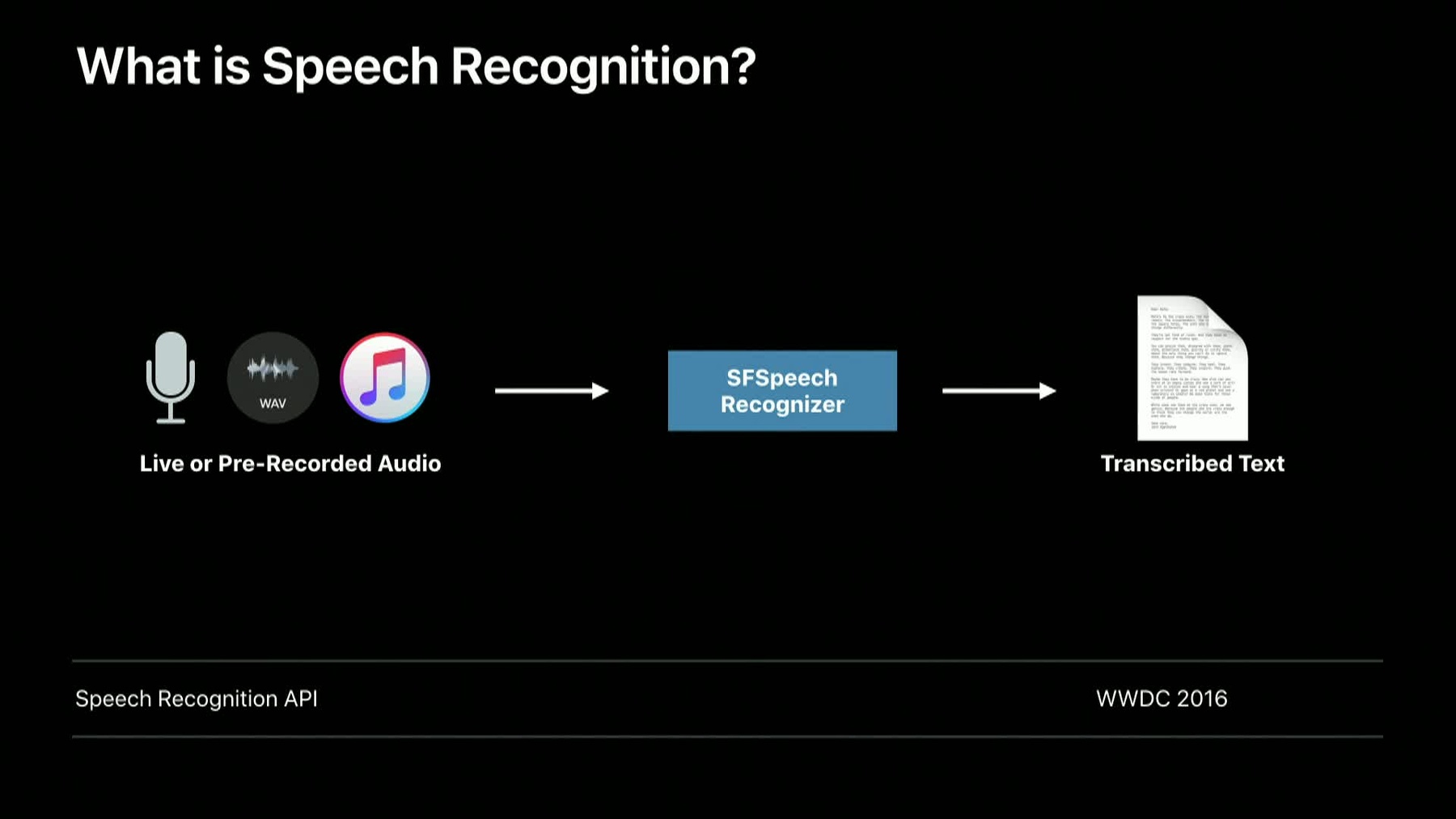
Hi. I'm Neha Agrawal, and I'm a software engineer working on speech recognition. In 2016, we introduced the Speech Recognition framework for developers to solve their speech recognition needs. For anyone who is new to this framework, I highly recommend watching this Speech Recognition API session by my colleague Henry Mason.
In this video, we're going to discuss exciting new advances in the APIs. Let's get started.
Speech recognition is now supported for macOS. The support is available for both AppKit and iPad apps on Mac.
Just like iOS, over 50 languages are supported.
You need approval from your users to access the microphone and record their speech, and they also need to have Siri enabled. In addition to supporting speech recognition on macOS, we are now allowing developers to run recognition on-device for privacy sensitive applications. With on-device support, your user's data will not be sent to Apple servers.
Your app no longer needs to rely on a network connection, and cellular data will not be consumed.
However, there are tradeoffs to consider. Accuracy is good on-device, but you may find it is better on server due to a continuous learning. A server-based recognition support has limits on number of requests and audio duration. With on-device recognition, these limits do not apply.
The number of languages supported on server are more than on-device.
Also, if server isn't available, our server mode automatically falls back on on-device recognition if it is supported. All iPhones and iPads with Apple A9 or later processors are supported, and all Mac devices are supported. There are over 10 languages supported for on-device recognition. Now, let's look at how to enable on-device recognition in code. To recognize pre-recorded audio, we first create an SFSpeechRecognizer object and check for availability of speech recognition on that object.
If speech recognition is available, we can create a recognition request with the audio file URL and start recognition.
Now, in order to use on-device recognition, you need to first check if on-device recognition is supported and then set requiresOnDeviceRecognition property on the request object.
Now that we have looked at this in code, let's talk about the results you get. Since iOS 10 in speech recognition results, we have provided transcriptions, alternative interpretations, confidence levels and timing information.
We're making a few more additions to the speech recognition results.
Speaking rate measures how fast a person speaks in words per minute.
Average pause duration measures the average length of pause between words. And voice analytics features include various measures of vocal characteristics.
Now, voice analytics gives insight into four features. Jitter measures how pitch varies in audio. With voice analytics, you can now understand the amount of jitter in speech expressed as a percentage.
Shimmer measures how amplitude varies in audio, and with voice analytics, you can understand shimmer in speech expressed in decibels. Let's listen to some audio samples to understand what speech with high jitter and shimmer sounds like. First, let's hear audio with normal speech. Apple.
Now, audio with perturbed speech. Apple. Next feature is pitch. Pitch measures the highness and lowness of the tone. Often, women and children have higher pitch.
And voicing is used to identify voiced regions in speech. The voice analytics features are specific to an individual, and they can vary with time and circumstances. For example, if the person is tired, these features will be different than when they're not. Also, depending on who the person is talking to, these features may vary.
These new results are part of the SF transcription object and will be available periodically. We will have them at the end when the isFinal flag is sent, but we could also see them before. You can access speakingRate and averagePauseDuration as shown.
To access voice analytics, you would have to access the SF transcription segment object, and then you can access it as shown here.
To summarize, we have made three key advances. You can now build apps on macOS using speech recognition APIs.
Speech recognition can be run on-device in a privacy-friendly manner. And you now have access to voice analytics features for getting insight into vocal characteristics.
For more information, check out the session's web page and thanks for watching.
-