-
Optimizing Storage in Your App
How you store data in your app affects not only disk footprint, but also the performance of your app and the battery life of the device. Learn techniques for optimizing data serialization, working with images, and syncing to disk. Find out how to take advantage of features in SQLite to improve performance and safety.
Resources
Related Videos
WWDC21
WWDC19
-
Search this video…
Hi, I'm Kai Kaahaaina and today along with Alejandro Lucena we'll be discussing how to optimize storage for your app. Just like CPU memory, storage is a finite resource.
When an app makes optimal use of storage, we can help better ensure long battery life, better performance, reduced app footprint, and good device health.
Our main optimization topics today will be efficient image assets, syncing to disk, serialized data files, Core Data, and SQLite. First up, efficient image assets. As screen sizes have gotten larger there's been a corresponding increase in the size of image assets.
For our session we've created a very simple demo app for cataloging and favoriting photos. However, even when preloaded with just a few photos, our app has already grown to 24.6 megabytes in size.
We'll now talk about two ways we can reduce the size of our app.
The first is HEIC. HEIC, also referred to as HEIF sometimes, is a more efficient and capable alternative to JPEG. HEIC offers 50 percent smaller files at comparable quality to JPEG which of course means a smaller on disk footprint, and smaller files could be more easily moved up and down the network. They can also be more quickly loaded and saved to disk. HEIC also offers many features not available in JPEG such as the ability to store auxiliary images that contain depth and disparity information.
HEIC also supports alpha and lossless compression. HEIC even allows you to store multiple images in a single container.
iOS has supported HEIC since iOS 11 and macOS has supported HEIC since macOS High Sierra.
It's also available in other operating systems.
So going back to our demo app we start off using JPEG assets and had an on disk footprint of 24.6 megabytes. By simply adopting HEIC instead of JPEG, we were able to reduce the size of this app to 17.9 megabytes. That's a 27 percent reduction simply by adopting HEIC.
The other way we can reduce the footprint of our app is by using Asset Catalogs. Asset Catalogs are a great way of organizing the assets for your app. Assets such as the app icon and device and scale variants to your images. Asset Catalogs provide a very easy way of storing multiple resolutions of the same image which makes it very easy to support a wide variety of devices.
We also can use Asset Catalogs to tag on demand resources so the user doesn't need to see them downloaded until they're ready to use them.
We get both storage and performance benefits through the use of Asset Catalogs. We first get to reduce our on disk footprint because Asset Catalogs store all of our image assets in a single optimized format instead of individual files. And the App Store also uses metadata from your Asset Catalog to help support app slicing for your iOS apps.
This way when a customer downloads your app from the store, they get only the assets they need for their particular device. This makes the download smaller and the user has to wait less time for the app to download and they can start enjoying your app much sooner.
We also get performance wins. Again, owing to the optimized format that Asset Catalogs saves our image assets in, images can be loaded more quickly. This is especially beneficial for app launch time. Particularly on Macs with hard drives where we've seen up to a 10 percent improvement on app launch performance.
Asset Catalogs also make it really easy to adopt GPU-based compression. This compression is lossless by default, but lossy image options are available.
All enjoy hardware accelerated decompression, and one option even provides a way of lowering the in-memory footprint of your image assets.
So going back to our demo app, earlier we saw we were able to reduce the size of the app to 17.9 megabytes by adopting HEIC.
Now, by having also adopted Asset Catalogs, primarily though the app slicing feature, we're able to further reduce the footprint of this app to 14.9 megabytes.
That's a 40 percent reduction in footprint since we started simply by adopting HEIC and Asset Catalogs.
So if you aren't already using HEIC for your image assets and Asset Catalogs to help organize your assets, we highly recommend looking into using them. They're a great and easy way of getting a more efficient and smaller app footprint.
Next up I'd like to talk a little about file system metadata. Our demo app maintains a small plist that just keeps track of the last time the app was launched. Each time the app is launched, we read in this plist, update the last app launch time property, and write the updated plist back out to disk. If we observe what this behavior looks like using the File Activity instrument Alejandro will be discussing a little bit later in the talk, we can see that this behavior causes one read which makes a lot of sense, we read the plist in, but it causes three write operations which might be a bit surprising since we're only writing out one file. We also see an fsync operation and these can be expensive and we'll talk a little bit more about why that can be expensive a bit later. So why three writes instead of one? Well the answer is file system metadata.
File system metadata is data that the file system needs to update every time we create a file or delete a file. So in this case, our writing a plist, creating a file, causes extra overhead.
So what is file system metadata? File system metadata is the information the file system needs to track about our files. Things such as the file name, size, location, and dates like date created or last modified. And a lot more. To get a better understanding of what the file system has to do every time we create a file, let's walk through what APFS has to do when we go to write our NSDictionary file to disk. Well the first thing that APFS is going to do is update the file system tree and it's going to do this by updating one of its nodes.
However, owing to the copy on write nature of APFS we don't actually update an existing node, we create a copy of an existing node. Let's look at this in detail.
So here's our existing file system tree. And we see a copy made of an existing node.
How this new node differs from the original isn't in the node name, it's actually the same as the original node, but the new node has an incremented or at least different transaction ID. And it's this different transaction ID that allows APFS to support advanced features such as snapshots. So going back up a level, now that we have our updated file system tree, APFS needs to update the object map so it's aware of the new node. So in total, to support writing this new file, APFS had to do two separate operations that totaled 8K of write I/O, 4K to update the file system tree, another 4K to update the object map. And we still need to write the file itself which, in this case even though it's only 240 bytes of NSDictionary data, the smallest file we can write to disk on an iOS device is 4K so it gets rounded up. So in total we had to write 12K of data to disk to store a 240 byte NSDictionary.
That's about 2 percent efficiency. So not only does the example show us the work that APFS needs to do to track file creation, it also highlights how expensive it can be to store small amounts of data in individual files on the file system.
So in the example we just walked through we saw that we had to do 8K of I/O to support creating a file on APFS. Well what about deleting a file? That's 8K. Other common operations such as renaming a file is 16K. Modifying an existing file is 8K.
The big take away from this is that file system updates aren't free. In fact, they can involve more I/O usage than the data being stored. So as a result, we need to be selective about how we create and modify and delete files.
We want to try to avoid expensive behaviors such as rapidly creating and deleting files.
If we have a use case where we do need to keep temporary data on the file system, here's a great way of trying to reduce the cost to the system for that temporary data. First, create your file but keep it open and unlinked, and do not call fsync on it. Doing this will give the file system the hints it needs to keep the temporary file in the OS cache as long as possible and not write out to disk as frequently as it might have to. If you'd like to learn more about file system metadata in APFS we have a great reference document on our developer website and I highly recommend checking it out. Next up, syncing to disk.
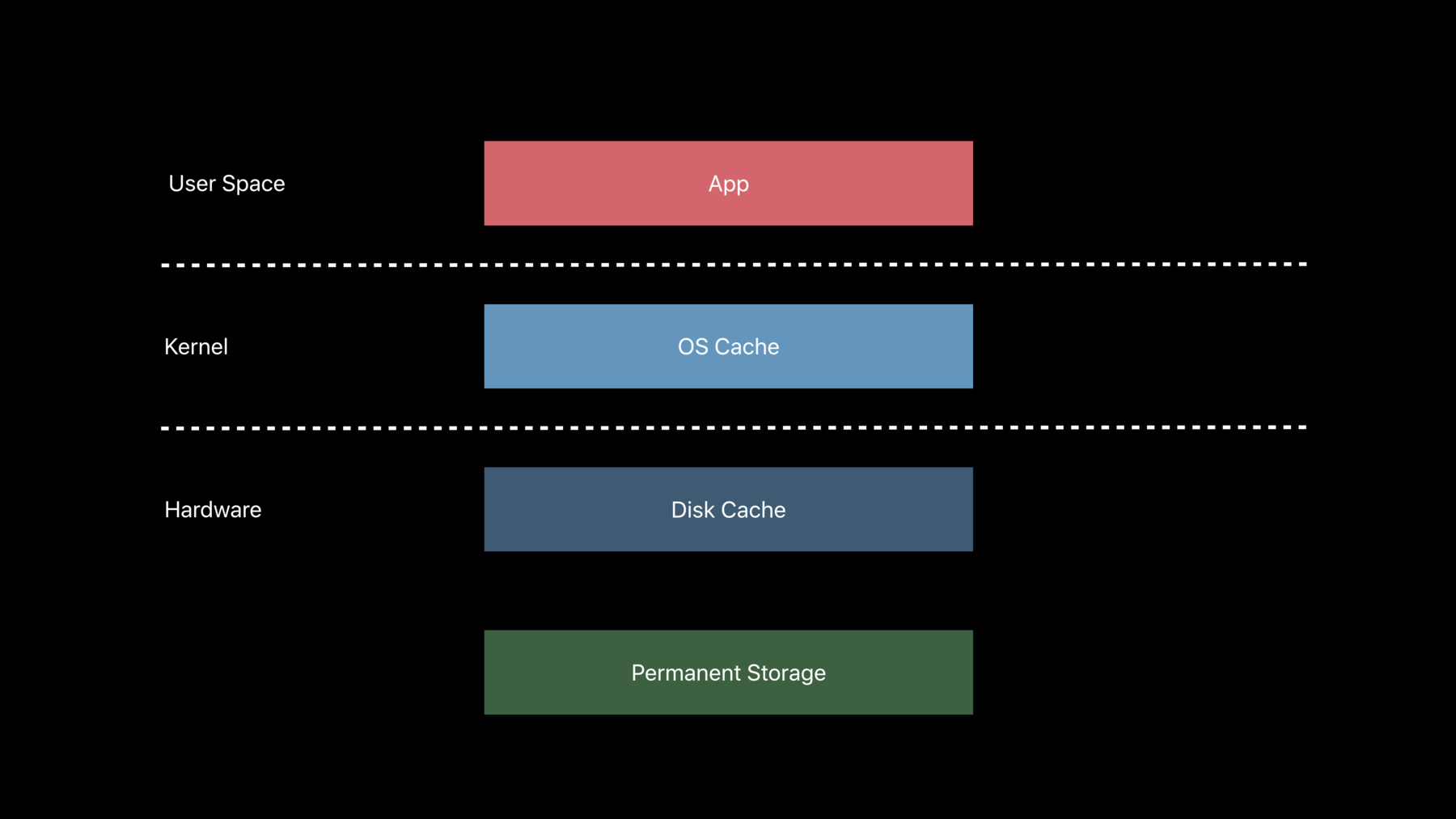
When it comes to managing where our data lives, we want to keep our data in the cache closest to the CPU for best performance, but we also want to ensure that our data gets to disk when we need it to.
First let's talk about the various caches that we have.
First there's the OS cache. This is where we want to keep our data for best performance.
Reads and writes to the OS cache are referred to as logical I/O. As this cache is backed by memory, logical I/O operations complete very quickly. Keeping data in the OS cache is often advantageous for frequently used and modified data. Next, we have the disk cache and the disk cache is actually physically located on the storage device.
And lastly, we have permanent storage. This is the actual physical medium which will be persisting the data long term. In the case of iOS devices and most Macs, this is NAND. Physical I/Os are reads and writes to and from the physical storage. These I/Os may be to the or from the disk cache or the permanent storage. So now that we have talked a little about the caches and permanent storage, let's talk about the most common APIs we use to move data from the OS cache to the storage device. First up is fsync. fsync causes data to be moved from the OS cache to the disk cache. It doesn't however guarantee that the data will be written to permanent storage immediately. Without further input from software, it's up to the device's firmware to determine when data gets moved from the disk cache to permanent storage.
It also doesn't guarantee write ordering. That's to say, the order in which data's written from the OS cache to the disk cache may not necessarily be the same order in which data is written from the disk cache to permanent storage. fsync can also be expensive if it's overused. When we had our data in the OS cache, the OS cache was able to easily absorb overwrites or modifications to the same data. Once we used fsync it got moved to the disk cache.
And depending on the cadence in which we need to ensure our data gets moved to the disk cache, calling fsync manually may not even be necessary as it's done periodically for us by the OS.
The primary way data gets moved all the way from the OS cache to permanent storage is through the use of F controls, FFULLFSYNC.
This causes the data in the drive's disk cache to get flushed. However this causes all of the data in the disk cache to get flushed so not only is the data that we were interested in moving all the way to permanent storage get moved to permanent storage, all the data in the disk cache does. As a result, it's expensive because this could be a lot of data and it could take a lot of time.
And again, it might actually not even be necessary to do this manually as this is done periodically for us by the OS.
If the primary reason we were using FFULLFSYNC was to ensure I/O ordering, a great and much more efficient alternative is using F BARRIERFSYNC. F BARRIERFSYNC enforces I/O ordering. F BARRIERFSYNC is probably best thought of as being basically an fsync with a barrier and the barrier is a hint to the Apple SSD to execute all the iOS that were received before the barrier before executing any of the iOS which were received after the barrier. As a result, it's a lot less expensive than F FULLFSYNC as we get the same result we wanted without having to push all the data in the disk cache to permanent storage. So if you're concerned about I/O ordering, please use F BARRIERFSYNC and not F FULLFSYNC. It's a much faster and efficient way of getting your data to disk.
Serialized data files. Files such as plist, XML and JSON, they're great. They're convenient to use. They're a great way of storing infrequently modified data and they're extremely easy to parse.
However, all this ease of use comes with a few tradeoffs. Any time we make a single change to the file, the entire file has to be re-serialized and rewritten to disk.
As a result, they scale poorly.
And since they're so easy to use, they can be easy to misuse.
And because we're having to replace the file with every single change, they're very system file metadata intensive. And they're very much not meant to be a database replacement. Looking at a screenshot from the file activity Instruments we can see that the act of creating, reading, and modifying the plist causes 12 separate I/O operations which is quite a bit for what is probably four lines of code.
And if we look at this in a slightly different view, then we see every time we call NSDictionary to write to file atomically, the operation ends with an fsync operation. This means that all the data we're storing in this NSDictionary we're pushing to disk is never enjoying the benefit of the OS cache. As a result, really large data sets or data sets which are modified frequently aren't really efficient in a serialized plist format. If the amount of data you have is either too large or too frequently modified, Core Data is a really good alternative. Core Data management is built on SQLite and provides a great abstraction layer between an SQLite data source and the model layer for your app. Core Data automatically manages object graphs and relationships, support for change tracking and notifications, automatic version tracking and multi-writer conflict resolution. Core Data will even automatically pool connections for multiple concurrent operations. And new with iOS13, Core Data supports CloudKit integration which is a huge win for Core Data adopters. And Core Data also supports live queries which allows you to generate queries on the fly so you don't have to hand code in advance all the SQLite queries you think you might need. Core Data also offers automatic memory management, statement aggregation and transactions, schema migrations, and new in iOS 13, data denormalization, and so much more. We've also observed that adopters of Core Data have to write 50 to 70 percent less code to support their model layer. That's code that never needs to be written, modified, or debugged. If, however you have a use case which requires the direct use of SQLite, we do have some best practices we'd like to share. This is a bigger topic so we have some subtopics including connections, journaling, transactions, file size and privacy, and partial indexes or subconnections. The robustness guarantees of SQLite aren't free. Opening and closing a database can cause expensive operations such as consistency checking, journal recovery, and journal checkpointing. As a result, we actually recommend not using a more traditional model of opening and closing a database each time it's needed.
Instead we recommend the inverse. Keep the database open as long as possible and close connections only when necessary. For multi-threaded processes, pool connections so that so long as one thread still needs the database the database can remain open. This really helps amortize the cost of opening and closing a database over time.
Next up, journaling. Delete mode journaling is the default journaling mode for SQLite but it isn't necessarily the most efficient. To see why let's take a look at how delete mode journaling works. Let's say we have a database and we want to modify four pages in it. The first thing that happens, we end up copying those four pages to a journal file. We then can modify the four pages within the database.
And once that's completed, the journal file gets deleted. So if we think about that, we had to write twice the number of pages we meant to modify and we had all the file system overhead of this short-lived journal file that we kept around just for a single transaction.
Fortunately, SQLite provides a much more efficient alternative in Write Ahead Log or WAL Mode Journaling. WAL Mode Journaling provides a great way of reducing writes. It allows us to combine writes to the -- multiple writes to the same page. It uses fewer barriers. It can support multiple readers at the same time as a writer, and supports snapshots.
Let's take a look at how WAL Mode works.
So let's say again we have a database and we want to modify four pages. Instead of modifying pages directly in the database, they just get written to the Write Ahead Log file and, as we have additional transactions, those pages get added to the Write Ahead Log file too until the Write Ahead Log file gets sufficiently large and it makes sense to checkpoint it.
And, when we checkpoint it we get one of the huge wins of WAL Mode, pages which would've been modified multiple times in a Delete Mode database, all those changes to the same page get merged during the WAL checkpoint and that same page only needs to be written out once. And when we're done, a simple overwrite of the header of the WAL file is all that's needed to make it available for future use thus reducing the file system cost of maintaining this Write Ahead Log file. So we can see WAL Mode is more efficient for most use cases of SQLite. If you weren't already using WAL Mode for your SQLite databases, we highly recommend switching over to WAL Mode. It can be a great way of getting some huge performance wins for your app.
Using multiple INSERT and UPDATE and DELETE statements in a single transaction is a great way of giving SQLite more information so that it can make more efficient operations on your behalf.
Pages that are changed multiple times by, in the same transaction by multiple statements, only get written out to disk once. Let's say in this example we have three separate transactions, each with one statement that modify the same page in the database. We'll see the same page in the database get modified three times. If, however, we had a single transaction with those three statements, all those changes would get combined and the page in the database would only get written out once.
As a result, using multiple statements in a single SQLite transaction is a great way for aggregating changes over time.
File size and privacy. So what happens when we delete data from the database? Space containing the deleted data is marked as free and while it's no longer part of the database, it's still technically on disk.
So how do we securely delete sensitive information in an efficient manner? We recommend using secure delete=fast. secure delete=fast is great. It automatically zeroes deleted data and there is no cost for data that was in the same page as the header file that we had to modify to mark the data as being free. And it's also now the default behavior for SQLite in the iOS 13. If you need it for older builds of iOS, please specify the secure delete=fast pragma.
When it comes to managing the size of our database files, we highly recommend not using VACUUM.
VACUUM is a very slow memory and I/O intensive operation. To better understand why let's take a look at how VACUUM for SQLite databases work. So let's say we have a database and we wanted to VACUUM out all the free pages. What happens is we end up opening up a cache door to our database, a journal file gets created, then we end up performing an SQLite dump from the database to the journal file copying all of the valid data from our database to the journal file.
Then later when it's time to checkpoint the journal file, the database gets truncated to the size of the journal file and all the data from the journal gets reinserted back to the database.
And then when that's complete, the journal file gets discarded.
As we can see, this is pretty expensive as all of the valid data we had in our database had to be written at least twice, once to the journal file and then once again back into the database. And if the working side of the database is too big to fit into memory, SQLite actually has to utilize spill files to help manage the extra data until the operation is complete.
Again, fortunately there's a much more efficient alternative in SQLite and in this case that's auto vacuum=INCREMENTAL. auto VACUUM incremental is great because not only does it allow us a more efficient way of managing the size of the database file, it lets us specify the number of pages we want to vacuum out of the database providing an option for leaving some free pages in the database for future use.
Let's take a look at how auto vacuum=INCREMENTAL works. So in this example we're going to vacuum out the two free pages. Whereas before we would have had to move all of our data from the database in the WAL file, for incremental auto vacuum, all we do is migrate two pages from the end of the database into the Write Ahead Log and any parent nodes that get modified during the rebalance of the database tree also get written to the Write Ahead Log. Then, when the Write Ahead Log gets checkpointed, the database file itself gets truncated, the pages we migrated from the end of the database go to where the free pages used to be, and any updated parent nodes get written to the database. So as you can see, whereas before we had to move all of our data in and out of the database, now we're simply modifying a subset of the pages within the database.
This is much more efficient.
There's all -- we highly recommend using incremental auto vacuum and fast secure delete to manage both file size and privacy for your SQLite databases.
Partial indexes.
Indexes are great. Indexes allow for faster ORDER BY, GROUP BY, and WHERE clauses. Unfortunately, they aren't free. There's a certain amount of overhead the database needs to do to support these indexes. And after we add more indexes, each new write of data to the database can become more expensive.
Fortunately, there's a more efficient alternative in the form of partial indexes. Partial indexes allow you to describe where you'd want to pay the price of your index using a WHERE clause which is great because now you can get the benefits of an index when you want it, but not -- but not necessarily having to pay the price of the index when it won't do you any benefit.
So in summary for SQLite, please keep database connections open as long as possible. Use WAL journaling mode instead of delete journaling mode. Whenever possible, use multiple statements per transaction so SQLite can do some optimizations for us.
Use fast secure delete and auto vacuum incremental to manage both file size and privacy for your databases.
And, when it's practical, use partial indexes instead of regular indexes.
And if you'd really rather not worry about these details in SQLite, we highly recommend just using Core Data. Core Data handles all this heavy lifting for you and as Core Data gets improved over time, adopters of Core Data will also get those benefits for free.
Next up Alejandro will show us how we can use the updated File Activity instrument and show us real-world examples of how we can profile and optimize I/O for apps. Alejandro. All right thank you Kai. And good morning everyone. Thank you for attending this session on optimizing storage. What I'd like to do is talk about some of the improvements we've made to the File Activity instrument to see how we can use that to optimize storage in our app. So let's get started. What changed with the File Activity instrument? Well, one of the first things we did was we added support for all Apple devices. So this means you can have the same uniform profiling experience across your iOS device, Mac, Watch, TV, etcetera.
The File Activity instrument also lets you support tracing for not just your own application but also for the entire system so you can see how your application behaves with regards to the I/O subsystem alone and how it interacts with the rest of the system so you can see different interactions going on. Next as Kai mentioned, there is the distinction between logical and physical I/O. And understanding how they interact with each other is actually really important for -- to understand your I/O usage. So the File Activity instrument lets us see both of these together. And lastly, we also added support for automated reasoning. And the automated reasoning comes in a variety of different mechanisms, so I'd like to talk about this very briefly. First and foremost, one of the automated reasoning anti-pattern detections that we added was actually that for excessive physical writes. So the File Activity instrument will actually notify you while you're tracing that it detected some sort of excessive activity in your application and you can go in directly from instruments and see what may have caused it.
We also added support for seeing when certain I/O related system calls that either you call directly or maybe are called on your behalf because of a framework have failed. And these are important to understand, not just for I/O but also for correctness in your application. And lastly, to Kai's points about fsync and F control with F FULLFSYNC, we also have a mechanism for detecting suboptimal caching so you can see when your application might be performing certain behaviors that aren't making the best utilization of the OS cache. So let's get started with File Activity instrument and see what it looks like. With Instruments 11, when we open up the instruments, we see the file activity still has roughly the same icon but we get a new string at the bottom which kind of sums up what it's capable of doing. And if we go ahead and select it, we're presented with some new tracks. First and foremost is the file system suggestions track. And this track is where all of these anti-patterns and automated reasoning suggestions will live. Directly beneath it we have file system activity and the file system activity will be broken down for logical reads and logical writes and it'll show you a count of how many of these operations happened. And you're also able to see in more depth how many calls were made, who called them, and certain other statistics. Similarly, right beneath it is disk usage where you can get the same sort of read and write distinction but for the physical layer. And lastly, the disk I/O latency so we can see just how long certain physical I/Os took. So let's get started and I'll refer back to this demo app. And the first thing I'd like to implement is actually favoriting of photos. So in the bottom right-hand corner of each of these images there's a star and what I'd like to implement is being able to select that star to consider an image a favorite. As an example, I can select a banana slug as a favorite as well as these skyscrapers. And the very first approach that I'll take is implementing this by opening and closing the database every time that we have a favoriting. Now Kai told us that this isn't the best pattern but I still think it's useful to get this into a File Activity instrument trace so we have a baseline and we can see what sorts of things are happening.
So here behind me I have exactly that. I ran the File Activity instrument against this same workload by opening and closing the database per operation. And the first track I'd like to focus on is disk usage because this is where all the physical I/O information will live. Here we see in the physical writes column or the physical writes row, we see the different amount of physical I/Os that happen. In this case in the tool tip text we have 54 for this particular column. But right beneath it is the detail view and the detail view is where all of the extra statistics will live so I'm going to go into here so we can see what sort of things we're getting.
By zooming in I'd like to point out that for this workload of favoriting these photos with the opening and closing database per operation, we had 1,002 different physical I/O operations totaling just under 6 megabytes of total footprint. And this may not seem like that much but when we compare it to some of the other ones, we'll get a better understanding of why this is perhaps as bad as it is.
So here we get some statistics about, you know, latency and average latencies as well. But I would like to switch back to the overall view because I also noticed that in the file system suggestions track, we do have some notifications that the instrument told us and I'd like to go into these as well so we can see just what happened. Again, at the bottom we have the detail view, and here the detail view in that count column is telling us that we had 12 total notifications.
And if we go into that dropdown, we see that these notifications were precisely for excessive physical writes. And we know that opening and closing the database isn't necessarily a good thing and we're going to try different techniques so we can get this. But I like to start off with this baseline of 12 notifications from the file system -- File Activity instrument.
And lastly, I also want to talk about the actual file system activity track where we can see statistics about which operations were called such as writes and reads and so forth, but also in this table here we get different views of the logical I/Os that our application did. Here are the default is file system statistics but we can also go down to file descriptor information as well.
All right so with that in mind, now I want to go and switch to a different model which is opening and closing the database as needed. Specifically I'll go back into the disk usage detail view and the first thing that I'd like to point out is we're down from 1,002 physical I/O operations down to 54 and we're down from just under 6 megabytes of disk footprint to 288 kilobytes which is quite a significant win and this was simply just by changing the usage model of when we open and close our database.
Furthermore, focusing again on file system suggestions, we started off with 12 in the previous version of doing this but now we're down to 3. And while this still isn't the ideal case, we are making progress. And as we implement different behavior such as journaling, we'll see this number change.
Speaking of which, let's start with Delete Mode Journaling. Now as Kai mentioned, Delete Mode Journaling is the default for SQLite and so this statistics page that I have here is actually the same exact one that I showed where we were opening and closing the database as needed. So I won't show the entire trace again but I do want to recall the numbers. 54 physical I/O operations totaling 288 kilobytes.
But when we switch to a model that uses WAL Mode Journaling there are some interesting observations that I'd like to point out. First and foremost is that now we have zero suggestions on the file systems suggestions track. We started at 12, ended up at 3, and now we're at zero so this is very significant gains that we're making by simply adopting the WAL Mode Journaling.
And secondly, this is the interaction between the logical and physical I/O that I'd also like to point out. Specifically, here in the file system activity track we see a lot of logical I/Os happening, but we don't get a physical I/O until we stop the trace of the application. And why is this significant? Well when we compare it to what we had previously with the Delete Mode Journaling, notice how in Delete Mode Journaling every time that we had file system activity, so logical I/O, we also had a corresponding physical I/O to go with it. Whereas with WAL Mode Journaling it's making really great use of the OS cache and getting us a lot of great performance benefits.
To see this in a little more detail we can go into that file system activity track again and focus on the detail view.
With WAL Mode journaling we only had a single fsync call whereas with Delete Mode Journaling we were all the way up to 16. So WAL Mode is definitely making a lot of great use of the OS cache.
Now the next thing I'd like to talk about is how we're going to implement deleting of photos. We talked about favoriting, but we also want a way to remove photos from the application. And the first approach that we'll talk about is actually using what's called single statement transactions and Kai mentioned this as well.
Specifically, when we want to select a photo for deletion, we'll select the checkmark at the bottom left corner, and we'll issue a delete query to the database. Now we could think of this as a single statement transaction because we're executing this delete query per photo and we're not doing any sort of coalescing on our own. With this model here's the single statement transaction approach and we do have some file system activity to point out as well as some disk usage. But one thing to focus on is with this approach we had 111 different file system operations and going over to the disk usage track we had 12 writes for a total of 72 kilobytes of total footprint. Next, I'd like to talk about multiple statement transactions and this is by taking the idea that each of these photos, even from a logical perspective, we don't want to delete these photos one at a time. Logically we want to get them all deleted at the same time and we have an analog for this within SQLite by merging all these delete statements into one transaction. So we have multiple statements in a single transaction. And if we do this, we're down to 37 file system operations. So we're doing significantly less work but in addition to that if we look at the disk usage we're down to 4 total writes and 24 kilobytes of footprint. Looking at these side by side, we started with 111 for single statement transactions of total file system activity, we're down to 37 with multiple statement transactions.
And looking to how this translates to actual physical disk usage, we started at 12 writes totaling 72 kilobytes and now we're down to 4 writes totaling 24 kilobytes with multiple statement transactions. And while we're on the topic of deleting, we should also mention vacuuming because we want to keep our database compressed or, you know, compact as possible. And we'll start off with a full vacuum. In this case we'll be issuing a vacuum statement every time that we issue a delete. And Kai told us that full vacuuming isn't the most optimal way of doing it, but we can see how this exactly works within the File Activity instrument.
Specifically, by doing this we have a total of 27 different I/O operations totaling 168 kilobytes by issuing a full vacuum, but if we switch this over to using incremental vacuum, we have some different numbers. We have 12 total I/O operations for 72 kilobytes of total footprint.
Again, looking at these side by side, we're down from 27 I/O operations with a full vacuum down to 12 by using incremental vacuum and from 168K of total disk footprint for the full vacuum down to 72. So it's pretty significant gains that we're making by adopting these sorts of patterns within SQLite.
So what I'd like to do now is sort of summarize and one of the first points is we want you to apply these lessons, whether you're using Core Data or SQLite or plist and so forth, we want you to apply these lessons but don't just apply them. We also want you to verify them with the File Activity instrument. Now the File Activity instrument may be able to help you by proving these points but also you may have some other suggestions that you don't even know about and perhaps the File Activity instrument can help bring those into vision for you and help you notice them.
And with that in mind, we also want you to continue optimizing storage. There's a lot more than just meets the eye and we hope that with these lessons and with the tools that we're providing it could be a great experience for everyone.
For more information we have a lab later on today for performance and we also had a session this year at WWDC '19 for making apps with Core Data if you'd like to learn a little bit more about how exactly to adopt this.
Thank you everyone for attending. Enjoy the rest of the session. [ Applause ]
-