-
Delivering Optimized Metal Apps and Games
Optimizing performance, memory, and bandwidth are important considerations for resource-intensive Metal apps and games. Learn key best practices to streamline your rendering and attain high frame rates. Understand powerful tools that can help you pinpoint expensive or unexpected GPU work. Dive into GPU capabilities that can yield performance gains and get expert guidance about using memory efficiently.
Resources
Related Videos
WWDC23
WWDC21
WWDC20
- Gain insights into your Metal app with Xcode 12
- Harness Apple GPUs with Metal
- Optimize Metal apps and games with GPU counters
WWDC19
-
Search this video…
Good morning and welcome everyone. I am Guillem Vinals Gangolells from the Metal Ecosystem Team. This past year, we have been working with many game developers and identified some common issues. As a result, we decided to put this talk together. Today, I will be presenting a total of 18 best practices to help you improve your Metal app.
Notice that I will not present OK practices or acceptable practices, and most definitely not practices that will just do the trick.
The focus today will be on Metal Best Practices. So, please follow them. Before we get started, I would like to thank our friends at Digital Legends, our very talented team from Barcelona. They are the developers of Afterpulse. Afterpulse is an awesome great looking game. It uses many rendering techniques such as cascaded shadow maps, a fully-featured deferred render as well as post-process such as bloom and FXAA. We will use Afterpulse throughout this presentation to demo our tools and highlight some of our best practices.
We have split the talk into three sections, general performance, memory bandwidth, and memory footprint.
So, let's get started with some general performance advice.
In this section, I will talk about choosing the right resolution, avoiding overdraw, reduce the amount of fragment shader invocations per pixel written.
We'll also talk about GPU submissions, resource streaming, and also a bit about thermals.
So, let's get started with the first best practice. Choose the right resolution.
Notice that each effect in your game may require a different resolution. So, it is very important that you consider the image quality and performance trade-off of each resolution and choose them carefully.
Also, composite the game UI at native resolution or close to native, so the UI will look crisp no matter the display size. We can check the resolutions with the Metal Frame Debugger.
Within the metal frame debugger, we will want to use the Dependency Viewer, which will show a graph of every render pass. In this case, we are using a Metal example application.
To access the Dependency Viewer, we will select the command buffer. And, in this case, you can see that this example Metal application is using several effects within different resolution each.
For example, Shadow Maps and SSAO have a different resolution than the main lighting pass. Also, the UI is composed of native resolution, so it will always look sharp.
These resolutions look great and perform well for this Metal application. We're asking for you to do a similar choice for your game.
So, let's move on to best practice number 2. Minimize non-opaque overdraw.
Overdraw is the amount of fragment shader's process for each pixel written.
iOS GPUs are excellent at reducing opaque overdraw. We just need to help a bit. So, the best practice here is to render opaque meshes first and translucent meshes later. Also, do not render fully transparent or invisible meshes. We will, once again, use the Metal Frame Debugger to help us. This time, we will look at the GPU Counters gauge to verify the overdraw for a given render pass.
We will want to focus on the main lighting pass of our Metal Demo application.
In order to calculate overdraw, we will look at the number of fragment shader invocations divided by the amount of pixel store.
We can use the filter bar at the bottom to quickly look for performance counters right after. In this case, it's a fully opaque scene. So, there's nothing else to verify. There's no overdraw and we are good to go. We're asking for you to do something similar with your game and verify that you're also good to go.
So, let's move on to the next best practice. Submit GPU work early.
Scheduling all the off-screen GPU work early is very important. It will improve the latency and responsiveness of your game and it will also allow the system to adapt to the workload much better.
So, it is important that you have multiple GPU submissions in your frame. In particular, you will want an early GPU submission before waiting for the drawables since that stall the render thread.
And after you get the drawable which will be as late as possible in the frame, you will then have a late GPU submission where you will schedule all the on-screen work, potentially, the UI Composition Pass.
Since, it's a bit tricky to explain, we have demo prepared. So, let's do a quick demo and I'll show you how to identify this with Metal System Trace.
Cool. What we see here is a capture of Afterpulse which we took last year with an older build of the game. This was taken with a game performance template. We introduced this template last year. So, you're already familiar with some of the instruments here. New this year, we have added the Thermal State as well as the Metal Resource Allocations. We'll talk about this later.
For now, what we want to focus on, our potential stutters or issues. In this case, we want to look at the Display panel and see that there's lots of events at the bottom with-- where surfaces have been on-screen for longer than expected. So, maybe that's a problem and we should look at it. What we will do is zoom in to one of these regions holding the Option key and dragging the-- our cursor over it. So, in this case, we can see that there's two frames that seem to be later than we would expect, at the same time, that the GPU is idle for a long time. So, that potentially is the cause of the issue we are trying to debug here. So, let's look into more detail.
We'll do that by disclosing all the tracks in Metal System Trace which you're already familiar with.
So, what we are seeing here are how our application is encoding work and also how our GPU is processing this work. So, let's focus on this orange frame. As you can see here, there's a lot of work being encoded by the apps, so we have the Shadow Maps, the Deferred Pass as well as part of the bloom chain, et cetera. So, the GPU is not actually processing that work, at the same time that the thread is waiting for the drawable. So that's what this causing this idle gap, but we already have some work encoded. We just didn't submit it.
So, that's what the best practice was about you submitting all the off-screen work which you can encode ahead of time before waiting for the drawable. So, the solution would be to do one GPU submission here. Notice that there's only one GPU submission which we can see here towards the end of the frame. So, all the GPU work just happens at the end.
Fortunately, this is very easy to simple-- very easy to fix. And, in fact, Digital Legends has already fixed it. So, let's look at the new trace of Afterpulse and see how it looks like.
OK. So, let's zoom in.
In this case, we can see that there's no idle time while we are waiting for the drawable.
So, let's disclose the Metal System Trace tracks as we did before.
And, in this case, we can see that the GPU is processing the work that we have already scheduled before getting the drawable.
So, in this case, the idle time is much smaller. So, this allows the system to adapt to the workload much better and there's no problems. So, after this, we know we are good to go and we are-- we already have multiple GPU submissions which do not cause any stall because we do them before waiting for the drawable. So, let's go back to the slides.
OK. So, the fix for that is actually quite simple much easier than explaining the problem in the first place. What we will want to do is simply create multiple command buffers per frame. So, we'll want to first create the command buffer to encode all the off-screen work which will be our early GPU submission. We will commit the command buffer and then wait for the next drawable, which will stall our thread. After we have the drawable, we will create one final command buffer where we will encode all the on-screen work and present the drawable.
This will be our final CPU-- GPU submission.
And this will also ensure that the frame pacing is actually good enough as well.
It's as simple as that. Just use multiple command buffers.
So, let's move on to the best practice number 4, stream resources efficiently.
Allocating resources does take time. And streaming resources from the render thread may cause stalls. So, the best practice here is for you to consider the memory and performance trade-off of your resource streaming algorithm and make sure that you allocate and load GPU resources at launch time since you will not need to allocate them at runtime.
And any resource that you need to stream at runtime, make sure you do so from a dedicated thread. It is very important that you do so in order to avoid stalls. We will revisit resource streaming later on in the memory footprint section and reevaluate the memory and performance trade-off. For now, let's just use Metal System Trace to tune our resource streaming.
New this year, we're having an Allocations Track which will show you an event for each resource allocation and the allocation in the same timeline as all the other instruments.
This will allow you to identify all those resources which you are streaming from the main render thread which could potentially cause a stall.
Something else you should tune as well is for thermals. It is important that you design your game for sustained performance. This will improve the overall thermals of the system as well as the stability and responsiveness of your game.
So, the best practice will be for you to test your game under serious thermal state. Also, consider tuning your game for this serious thermal state since that will hopefully help you to know the thermal throttle.
So, new this year, we're adding Device Conditions into Xcode, which will allow you to set the serious thermal state directly from the device's window.
There is a talk at the bottom where this topic we'll be covering to more detail and I encourage you to watch.
Also, we can use the Xcode Energy Gauge to verify the thermal state that the device is running at.
In this example, we are conditioning our device to run at serious thermal state and we are effectively verifying that the device get into serious thermal state. It just takes a couple of seconds to ramp-up to that.
Cool. So, now let's move on to the second part of our talk.
In this section, we'll talk about memory bandwidth.
Memory bandwidth is very important. That is because memory transfers are costly. They consume power and generate heat.
To help mitigate in that, iOS devices have shared system memory between the CPU and the GPU as well as dedicated Tile Memory for the GPU.
Metal is designed to help you leverage both. So, now, let's see how by start looking into textures.
Texture sampling is probably the main bandwidth consumer in your game. So, we have some best practices for you to configure your textures correctly.
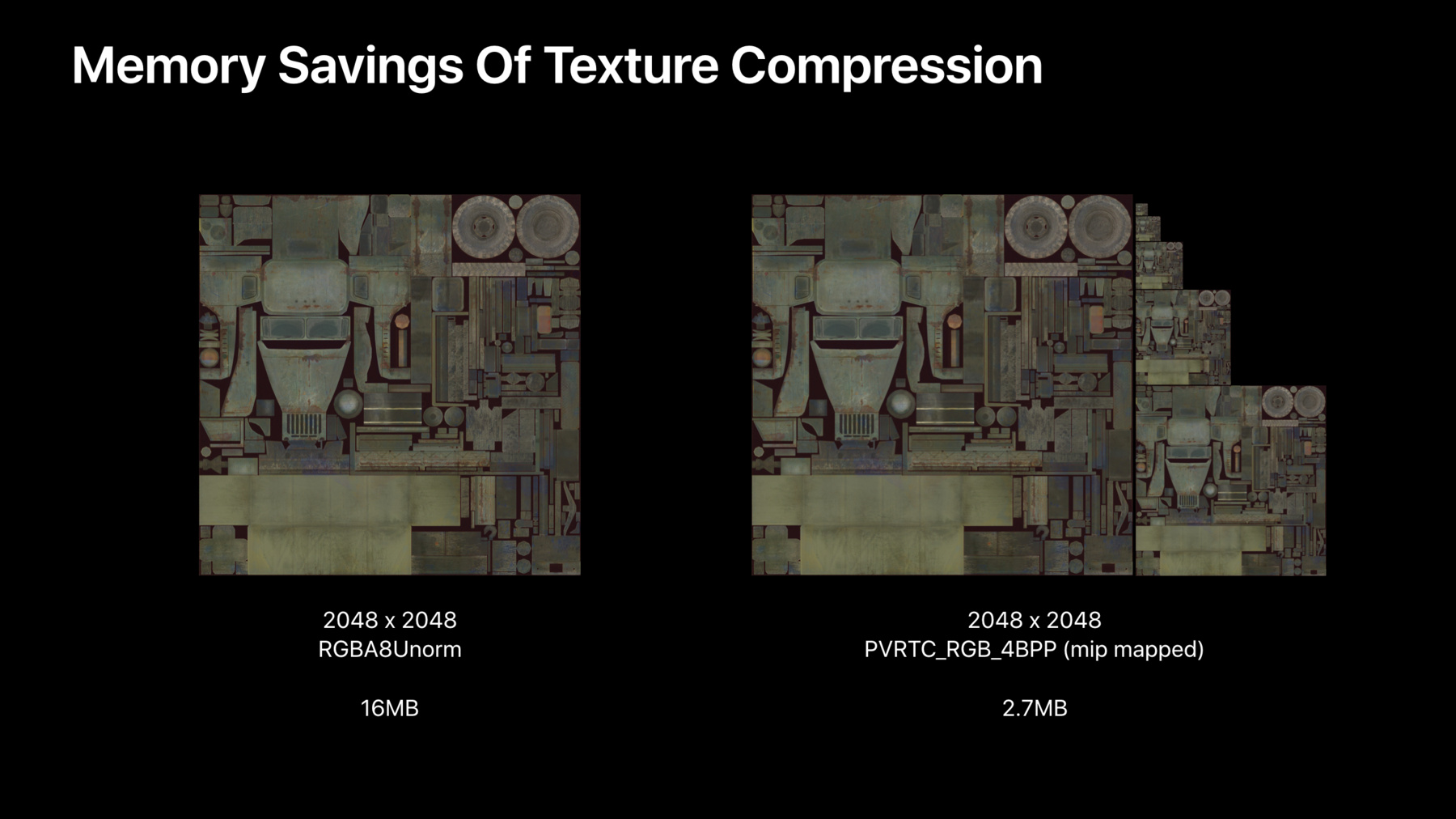
In this section, we will talk about offline texture compression for game assets, GPU texture compression as well as how to choose the correct pixel format. So, let's start with texture assets. It is very important for you to compress your texture assets. That is because sampling large textures may be inefficient and your assets may also be arbitrarily large. So make sure they are all compressed and also generate midmaps for all the textures which may be minified. So, let's see the memory savings of texture compression. This is one of the largest textures of Afterpulse.
If this texture were to be uncompressed, it would take about 16 megabytes of memory to load.
By using texture compression, we can lower let-- this to less than 3 megabytes including the full mipmap chain. Those are great memory savings.
Notice though, that Afterpulse is using PVRTC because it runs on A7 devices such as the iPhone 5S.
If your game targets newer devices, using STC instead since it offers better compression ratio in image quality.
To verify that our assets our compressed correctly, we can use the Memory Viewer.
The Metal Memory Viewer is a great tool which I will fully introduce in the memory footprint section. For now, will you-- we will use it to inspect all of our assets. We can double check they are compressed, mipmapped, and also look great.
But what happens with all those textures which you cannot compress ahead of time such as render targets or all the textures generated at runtime? The latest iOS GPU support lossless texture compression, which allows the GPU to compress textures for faster access.
So, the next best practice is for you to optimize your textures so the GPU can have faster access.
It is very important that you configure your textures correctly. You will want to use private storage mode, so only the GPU has access to the texture data and it allows it to optimize the contents. Also, do not set the unknown usage flag and avoid setting unnecessary usage flag such as shaderWrite or pixelView, since those may disable this compression.
Shared textures which can be acces by the CPU and the GPU should explicitly be optimized after any CPU update on their data. It is also important for you to do so. So, let's see how can we do both things with a little bit of code. And it really is just a little bit of code. To create an optimal texture, we will want to set the storage mode as private. So, only the GPU has access to it. And also, we will want to set explicit yet conservative usage flags.
In this case, we want to use the texture as an intermediate render targets so we do not need any other usage flag. But what about shared textures? Well, those are a bit trickier. So, shared textures can be accessed by both the CPU and the GPU.
So, if the CPU updates a region of the texture or any of the texture data, we may need to explicitly ask the GPU to optimize its contents.
Notice that there is a trade-off here between how many times does the CPU update the data and how many times does the GPU need to access it afterwards. So the Memory Viewer will actually be a great tool again to help us with this. That is because we can configure the Memory Viewer to show both the Storage Mode and Usage flag for all of our textures. From this single screen we can see our compressed textures and identify all of those which could be configured correctly.
It is a great tool.
At this point we are almost done configuring our textures. We just need to choose the right pixel format.
Larger pixel format will use more bandwidth, so the best practice will be for you to avoid using pixel formats with unnecessary channels and also try to lower precision whenever possible.
Notice though that the sampling rate itself will also depend on the pixel format.
In this case, we can see how the pixel format has a direct impact on the texture sampling rate of our GPUs. Particularly, you will want to watch out for 128-bit formats such as RGBA 32-bit float, since those are sampled at quarter rate.
Oftentimes these high precision formats are used for noise textures or lookup tables for the post-process effects.
Once again we can use the Memory Viewer to help us with that.
The Memory Viewer will let us filter textures by name or pixel format.
So, we will verify that our Metal Demo is using 16-bit formats for the SSAO implementation.
This is very important for the noise textures.
Notice something else though, and this that in this example most of the textures are actually render targets.
So as games become more complex, the texture used as render targets may actually consume a lot of bandwidth as well, so let's have a closer look. In this section, we will review render pass load and store actions, paying close attention to MSAA and also talk a bit about Tile Memory.
So let's get started with optimizing load and store actions.
You should avoid loading or storing render targets unnecessary.
Render target load and store actions are very easy to overlook and may actually quite quickly become a problem. So please make sure to keep those in check.
And it is actually quite easy to do so, with again just a little tiny bit of code.
In this case, we are configuring a render pass descriptor and we want the color attachment 1 to be transient, which means we don't want to load or store anything from it.
It is a simple as setting the correct load and store actions. We want the load action to be clear, so no later gets transfer to the on chip GPU. And we want to store action to be, DontCare. So no data needs to be written at the end of the render pass.
That's all there is to it, verifying that we have done the right thing is also very simple, we can use the Dependency Viewer. In this case, our Metal example is storing the color attachment 1, even though it's not used later on.
The Dependency Viewer will show an issue icon to highlight this problem.
We should simply set the DontCare store action as we have just seen in the previous slide and the problem will go away. It is really as simple as that. This is particularly important for multi-sampled render targets. iOS devices have very fast MSAA, that is because the result happens from Tile Memory, so it does not consume any extra bandwidth.
This also allows us to declare the multisampled textures fully transient. In fact, we don't even need a system memory allocation to back it in the first place. So the best practice will be for you to consider MSAA over native resolution, since it's very efficient, and also make sure to not load or store the multisample texture.
And since you're at it set the storage mode of the multisample texture to memoryless.
I will fully introduce memoryless later on the talk. For now, let's see how can we configure a multisample texture and the render pass that uses it. In this case, we just need to set the memoryless storage mode, and also make sure that the render pass is using it, clears its contents and discards the samples. We only want the multisample texture to resolve from. We do not need to store it. We do not want that intermediate data to be stored. Only the final resolve texture should be stored.
We can once more use the Dependency Viewer to help us verify that we are doing the right thing. In this case, our Metal example is loading and starting the multisample texture which is very costly.
After setting the correct flag just as I've shown you, we will save our 85 memory, sorry, 85 megabytes of memory bandwidth and also footprint.
And this is very important for you to verify the multisample attachments.
But notice that those savings are only possible because we are implicitly leveraging Tile Memory by using MSAA.
So the next best practice is for you to explicitly leverage Tile Memory.
Metal provides access to Tile Memory for several features such as programmable blending, image block, and tile shaders.
The best practice is for you to explicitly utilize it, particularly to implement more advanced rendering techniques.
The Modern Rendering with Metal talk will cover-- has covered some of these techniques in detail.
For now we will just have a quick look at deferred shading.
Deferred shading is considered to be very bandwidth heavy that is because traditionally it requires the application to store the geometry information or G-Buffer as a set of textures representing several pixel properties.
Those textures are then sampled in the second lighting pass, where the final color is accumulated in a render target.
Notice that we are storing and then loading all this data from the G-Buffer, so that's why it's bandwidth heavy. iOS allows you to be much more efficient than that.
On iOS, we can leverage programmable blending, a feature that allows fragment shaders to access pixel data directly from Tile Memory.
This means that the G-buffer data can be stored on Tile Memory and access within the same render pass by all the light accumulation shaders. It is a very powerful feature which Digital Legends has been utilizing for years.
This is how the single pass deferred render of Afterpulse looks like through the Dependency Viewer, it's beautiful. The four G-Buffer attachments are fully transient, and only the final color and depth are stored, so it's not only beautiful it's also efficient.
So, now, please let's welcome Samuel on stage for the demo of the Dependency Viewer. Thanks Guillem. So, we've just captured an old version of Afterpulse and want to see if there are any optimizations that we can make to improve its performance.
I'm now going to use the Dependency Viewer in the Metal Frame Debugger to show some of the issues that Guillem just mentioned. So to begin, let's click on the CommandBuffer to open the Dependency Viewer. The Dependency Viewer shows us all of the GPU passes encoded by an app. We can see that Afterpulse has one CommandBuffer and begins its frame by rendering a Shadow Map. Followed by Deferred Phase, this feeds into Luminance Calculations, Particle Simulations, and a Bloom Chain which is used by the final screen pass.
Now, the Dependency Viewer is much more compact this year if you have groups, and it's really easy to see at a high level, how the frame is rendered.
We can even go deeper into any group if we want more detail. So, in reality this Bloom Chain is actually 12 passes. Now, the Dependency Viewer is a great place to find some of the issues that Guillem mentioned. And we can see a few on this final screen pass. So let's click on the issue icon to find out more. So, it looks like one of the load store action issues that Guillem mentioned earlier.
So they've set the store action to store, but they're not using this texture again in this frame.
So the issue recommends we should instead set it to DontCare and we'll get back almost 14 megabytes of memory bandwidth for these two textures combined. So this year we've made it even easier to find all of the issues in the graph, simply click on the new issues button on the bottom right to see a list of issues. Now, another best practice that Guillem mentioned was choosing the correct pixel format. So this year on iOS we've introduced the new Depth 16 Format, so let's use the new search to look for Depth 32 textures.
So it looks like they're using 36 megabytes of memory for the Shadow Map texture.
So when the team at Digital Legends gets back to Barcelona after Dub-Dub, they can investigate using this new format and potentially save half the memory if their shadow requirements allow for it. If we continue searching through the graph, where you can see that there's plenty of potential memory savings. So if you use the Dependency Viewer in the Metal Frame Debugger to find and diagnose a few issues in the old version of Afterpulse.
So, Digital Legends have actually made some of these improvements. So let's take a quick look. We can immediately see that they are now using multiple command buffers. So this will fix the issue that Guillem showed us earlier where the CPU was blocked waiting for the next drawable and the GPU was idle. If we zoom in to the final screen pass, we can see that they've fixed the store action issue.
In fact, because these two textures are fully transient and they've set the storage mode to memoryless, they're not using any system memory at all.
So, Dependency really is a great place to start debugging your render pipeline.
Back to Guillem who will talk about some amazing best practices in optimizing your apps memory footprint. Thank you Sam that was an awesome demo. I hope you guys will also use the Dependency Viewer.
Cool. So, let's move on to the last part of the talk, memory footprint.
Memory footprint is actually very important for your game.
That is because iOS enforces a strict application memory limit in order to keep both the system on your application responsive. As some of you may have noticed iOS 12 introduce some changes in the way memory is accounted.
This accounting change affects mostly Metal resources.
Metal resources such as buffers or textures may be the bulk of your application's memory footprint. So, it is important for you to measure the memory footprint of your game. You will want to do, so using the Xcode Memory Gauge.
The Xcode Memory Gauge will report the existing number that the system also uses to measure your game's memory footprint. It is very important that you use it to verify where your games at.
Now, new this year it will also display the application memory limit as your game gets closer to it.
But what if we want to focus specifically on the memory used by our Metal resources? New this year, we are introducing the Memory Viewer.
We have added it into the Metal Frame Debugger.
The Memory Viewer itself has two parts, first, a bar chart at the top which shows resources, group by categories such as type, storage mode, and usage. We can also use this bar chart to quickly navigate through the largest resources which are then highlighted and the time they were shown.
Second, there is a table at the bottom which will show the resources that we have filtered. It includes several properties specific to resource type such as pixel format and resolution for textures.
There is also filter bar at the bottom to help you narrow down your investigation even further. It is a very powerful tool and we hope that you will utilize it to understand the memory footprint of all your GPU resources.
Also another great tool that we are introducing this year is the Metal Resource Allocation Instrument.
It has three different components, a Metal Resources Allocations track which will show the current Metal memory footprint of your game, an allocations track which will show an event for each resource allocation and deallocation as well as some information.
And also a detailed table view which will show you more information about all the allocations captured.
Both these tools are very powerful and will give you great overview of the memory footprint in your game and how-- well, also how it changes over time. But some of you have also been asking for other features, in particular, one of them you have been asking for a long time. And I'm very happy to tell you that new this year, we have a C-based API to query available memory at runtime.
This will enable your game to stream resources more effectively and also avoid memory spikes which may cause the game to go over the application limit.
Another cool API that we're introducing this year is the on-device GPU capture, which will allow you to programmatically trigger a GPU capture for which Xcode is not required. So we think it will be ideal for game testers in the QA process. To enable it you will just need to add MetalCaptureEnabled into the info.plist. It's very simple.
So, now, let's see how we can combine both APIs into some short piece of code.
In this case, we will want to check if the application is close to the memory limit, maybe because of a memory spike and capture a GPU trace of our game, so we can use the Memory Viewer to fully debug it. So let's go for it. First, we'll check if the application is getting close to the limit. And if it is we will then want to capture the next frame, which we will just render normally as we would do so otherwise.
By the end of the frame, if we captured it, we will then stop the capture and handle the GPU trace, it's up to you how you handle the GPU trace. Potentially you may also want to either exit the game or disable the GPU captures for this session, since you may not want to capture every single frame at that point.
So this will give you a great way to use both APIs and to, you know, like further drill down on memory footprint. Which is great, so let's do exactly that. Let's look into how can we reduce memory footprint. For that we also have a bunch of best practices.
In this section, we will talk about memoryless render targets, resource streaming, a bit more about game assets and also memory-intensive effects. So, let's get started with memoryless render targets. This is kind of where we left it in the memory bandwidth section.
Notice the transient render targets are not loaded or stored on system memory. So they actually do not need a system memory allocation in the first place, that's why you should use memoryless storage mode, in particular, for all the multisampled attachments.
So let's see how can we do that with, again, just a little bit of code. In this case, is as simple as setting memoryless into the texture descriptor.
Also we will want to make sure that our render pass configures that render target as fully transient. In this case, we want to configure the G-Buffers transients. So, we just need to set the load action clear and the store action to DontCare. So we are not storing the G-buffer. So we can see how Digital Legends did it by having another look at Afterpulse.
At the top we can see an older version of Afterpulse, it has a transient G-buffer but it's being backed by system memory. At the bottom, we can see a newer version of Afterpulse which actually has a larger G-buffer.
But this G-buffer though is fully transient and this time not backed by system memory, they are utilizing memoryless storage mode for all the intermediate G-buffer attachments. And this is great because the newer version of Afterpulse is saving about 60 megabytes of memory footprint just by setting that one flag, it's awesome. And it comes with no compromise, there is nothing being lost here, there's no trade-off to be made, it just works. And it's great.
So, now, let's move on to the rest of the best practices, which some of those we will do come with a, you know, memory and performance trade-off or memory and image quality trade-off. In this case, we are back to resource streaming.
Notice that loading all the assets into memory will increase the memory footprint, so you should consider the memory and performance trade-off and only load all the assets that you know will be used, particularly when you are memory limited.
Also you may want to free all the resources as long-- as soon as they are not used anymore, potentially like splash screen or tutorial UI would be great candidates for that.
And this is a hard decision to make but fortunately the Memory Viewer is also a great tool to help us with that.
We can use the filters to quickly focus on unused resources.
By doing so, the table at the bottom will be updated and then we can focus on all these resources which are not used in this frame. And we will talk more about this and use them off the Memory Viewer towards the end of the talk.
So, now, let's move on to best practice number 14.
Use smaller assets. In fact, you should only make the assets as large as necessary and consider again the image quality and memory trade-off of your asset sizes. Make sure that both textures and meshes are compressed.
And potentially if you are getting memory limited you may want to only load the smaller mipmap levels of your textures, or the lower LODs for your meshes. But there is a trade-off here that we are making, between image quality and memory. It's up to you to decide, when do you want to take it? The next best practice number 15 is very similar. We will want to simplify memory-intensive effects. Some effects may require large off-screen buffers, such as Shadow Maps and SSAO. So the best practice will be for you to consider the image quality and memory trade-off of all of those effects.
Potentially lower the resolution of all these large off-screen buffers.
And if you are very memory constrained then just disable all those effects all together.
That is a trade-off to be made here and you need to be conscious about it. But sometimes there's no other choice.
The next best practices that we are going to cover here are slightly different.
In this last section, I will introduce a couple of more advanced concepts that will help us further reducing the memory footprint.
We will talk about metal resource heaps, purgeable memory as well as pipeline state objects.
So, let's get started with metal resource heaps.
metal resource heaps will allow your application to take explicit control over the large memory allocation that happens up front.
In this case, we will go from three separate textures which have their own allocation into a single metal resource heap which is a single allocation that will hold these three textures separately.
This will also allow the system to pack those textures together, so we're already saving some memory. But the great memory savings will come from using aliasing.
So, notice that rendering a frame may require a lot of intermediate memory, in particular, as your game scales in the post-process pipeline.
So it is very important for you to use metal resource heaps for those effects and alias as much of that memory as possible. For example, you may want to reutilize the memory for all those resources which have no dependencies, potentially like those you would find in SSAO and Depth of Field. So, now, let's look how would that look like. In this case, we have the same metal resource heap as before.
But if the three textures are not used at the same time we can potentially alias them. And by doing so, we will save a lot of memory.
And this will really help your game scale with a much more complex post-process pipeline without having to pay a huge memory price for all those intermediate render targets and all the intermediate memory.
So it is great, it's a great feature that you should consider leveraging. Now, let's talk about another advanced concept that of purgeable memory.
Purgeable memory has three states, non-volatile, volatile, and empty.
Notice that volatile and empty allocations do not count towards the application memory footprint.
That is because the system can either reclaim that memory at some point, in the case of volatile or has already reclaimed it in the past, in the case of empty. So you may need to regenerate those resources.
But that makes this kind of memory ideal for resource caches.
So the best practice number 17 is for you to mark resources as volatile. Temporary resources may become a large part of your game's footprint.
And Metal will allow you to explicitly manage those, set the purgeable state of all the resources explicitly.
So you will want to focus on your caches particularly all of those which hold mostly idle memory and carefully manage their purgeable state, so they will not count towards the game's footprint.
Let's see a very short bit of code that will give you an example on how to do so. In this case, we have a texture cache, could have also been a buffer cache.
And we will set the purgeable state of all the textures in that cache as volatile because we know that cache is mostly idle. We only use a texture now and then but not very often. So if we need to use a resource from that cache, we will then need to mark it as non-volatile that will ensure that the system doesn't remove its backing data.
And in the case, it was empty which was the previous state that the one we just said. We may actually need to regenerate the data potentially not. It depends on what type of cache you're managing. But after we do so, we can just utilize the resource normally as we would otherwise.
A very good practice will be for you to also check the common buffer completion and get to handle when the common buffer is completed and then potentially you flag that resource as volatile again. So it does not keep counting towards your memory footprint.
You can be explicit and in fact you should be very aggressive particularly when you have lots of caches of mostly idle memory. So let's introduce one last concept that of pipeline state objects.
Most of you are already familiar with those. PSOs encapsulate most of the Metal render state.
They are constructed with a description-- a descriptor which contains vertex and fragment functions as well as other states such as the blend state and the vertex descriptor.
All of these will get compiled into final Metal PSO.
We only need this final Metal PSO in order to render. So the next best practice is for you to explicitly leverage that.
Since Metal allows your application to load most of the rendering state up front, you should do so. That will be great for performance.
But then consider the memory trade-off of doing that.
If you are getting memory limited make sure do not hold on to PSO references that you know they are not needed anymore. And very important also do not hold on to Metal function references after you have created the PSO cache. Since those are not needed to render they are only needed to create new PSOs.
So let's see what I mean by looking at the descriptor again. This is the pipeline state object as well as the pipeline state object descriptor. And what this best practice is asking you to do is to free the reference of both the vertex and fragment functions after you create the PSOs, potentially only hold on to those when you're populating the main PSO cache at load time.
And then consider also freeing the PSO itself when you are getting memory limited if you know that that PSO is no longer needed. Now, let's, please welcome Onyechi on stage for an awesome demo of the Memory Viewer. Thank you Guillem. Hello everyone.
So you already have the brief introduction to the Memory Viewer from the previous slides. Now, I'm going to show you how to use it to understand your memory footprint that's optimized for better memory performance. So here we are again with a capture of a frame from the same early version of the game Afterpulse. Then the top left there are the debug navigator that you'll find in your Memory Gauge which when I click on it, it takes me into the Memory Viewer. Now this shows us the state of all live Metal resources for the captured frame. And my goal is to find opportunities to reduce its memory footprint.
So to begin, let's take a look at the orange bars in the graph. This shows how our resources are distributed by type. And we can see that textures make up the largest proportion, right? There's about 440 megabytes of them. Now, I want to focus in these sections and I can simply do that by clicking on the filter button. Now, both the graph and the table have been updated to show textures only. So, next, Guillem mentioned that when looking to reduce our memory footprint starting at unused resources that was a great place to begin. So, let's do that. Let's look at the blue bars this time. This represents our usage and we see that we have about 200 megabytes, so unused texture.
So as a reminder, unused resources are resources that do not contribute to the final output of this rendered frame. That means they're not accessed by the GPU.
OK. So, I can easily do that again by just clicking on the unused filter, so that we're looking on unused textures now.
Next, I will sort the table by allocated size, so that we're focused in our largest texture. And we can see straight away that our largest texture which is about 13 megabytes has an issue.
So, issues work here just like in Dependency Viewer you saw in the previous demo. So let's click it to see what it's about.
OK. So, this says we have a large unused texture.
It's not accessed by the CPU and has never been bound to a command encoder with a recommendation to avoid loading the resource or to make it volatile.
So, we can also confront this by looking at the properties, CPU Access and Times since Last Bound. And we can clearly see that this section is definitely never been accessed by either the CPU or the GPU. So, therefore, we can say with confidence now this is a resource that it should be unloaded, till it's actually needed. OK. So, that's encouraging, we very quickly identify 13 megabytes of memory savings. Let's check out the next issue. So, in this case, texture has been identified as a temporary resource. It's not accessed by the CPU and has not been bound to a command encoder for over 47 seconds. So, in other words, this texture has not been using this frame or in any other frame in the last 47 seconds. So this is a pretty good candidate for a resource that should be made volatile if possible since it occasionally contributes to a frame.
OK. So, this is fantastic. We've very quickly found about 14 megabytes of memory savings and indeed when looking to reduce our memory footprint looking at unused resources is a great place to begin, and issues that will help you to quickly identify the best candidates to remove.
But you should also pay attention to the properties Times since Last Bound to figure out which of your unused resources have never been submitted to the GPU even though they may have been accessed by the CPU.
OK. Let's switch things up a bit. Let's see what issues or what memory savings we can discover, where textures are actually in used. OK. I'm going to switch to the used filter this time, so we're looking at used textures.
And we see that one of our largest textures which is about 18 megabytes has two issues. So, let's see what they are. OK. So, the first one is about lossless compression. Texture has opted out of lossless compressions because of the presence of a ShaderWrite usage flag, even though it's being used exclusively as a render target.
The second issue is about storage mode.
Our texture the render target has been identified as being transient which obviously means that no loads to actions are required for this texture. But unfortunately it has a storage mode shared when really it should be memoryless.
So, we have two different recommendations here.
And if you think about it, we can only really choose one of them.
But at this point I should emphasize that these recommendations presented by the Memory Viewer are based on data gathered up to the current frame.
However, you know better about how you intend to use your resource beyond the current frame.
So, with that said if we are certain that this texture will remain transient and say a future render passes then switching to memoryless is the superior option. And doing so would reduce our memory footprint by the size of the texture which is 18 megabytes.
If on the other hand, our texture will not be transient in future render passes then we should seriously consider opting into lossless compression because doing so would have a positive impact on our memory bandwidth as suggested by Guillem.
And, in this case, simply removing the redundant ShaderWrite flag should do the trick. So, we've only just scratched the surface of what's possible with the Memory Viewer. You've seen how with just a few mouse clicks it makes it very easy for you to understand your memory usage and also it makes it very quick for you to identify those hard to find issues that may affect your performance. And with that I'm going to welcome Guillem back to the stage. Thank you. Thank you that was also an awesome demo.
Cool. So, we have seen a lot of best practices today. We've been through a total of 18 of them which is quite a lot of content to go through really.
Notice that most of this best practices are actually quite related, right? So, most of the memory bandwidth best practices, will also help you reducing the memory footprint.
So, maybe the best way to actually think about all this content, this is a checklist of optimizations for your Metal game or application.
And when you carefully take all of these elements, you too will be delivering optimized Metal games and apps, which was all that this talk is all about. For more information please see our documentation online and come visit us at the lab today at 3.
Thank you very much and I hope you enjoy the rest of the show. Thank you. [ Applause ]
-