-
Explorer de grands modèles de langage sur une puce Apple avec MLX
Découvrez MLX LM, conçu spécialement pour simplifier et optimiser l'utilisation des grands modèles de langage sur la puce Apple. Nous verrons comment ajuster et exécuter l'inférence sur de grands modèles de langage avancés sur votre Mac, et comment les intégrer de manière transparente dans des applications et des projets basés sur Swift.
Chapitres
- 0:00 - Introduction
- 3:07 - Introduction de MLX LM
- 3:51 - Génération de texte
- 8:42 - Quantification
- 11:39 - Mise au point
- 17:02 - LLM dans MLXSwift
Ressources
- MLX Swift Examples
- MLX Examples
- MLX Swift
- MLX LM - Python API
- MLX Explore - Python API
- MLX Framework
- MLX Llama Inference
- MLX
Vidéos connexes
WWDC25
-
Rechercher dans cette vidéo…
-
-
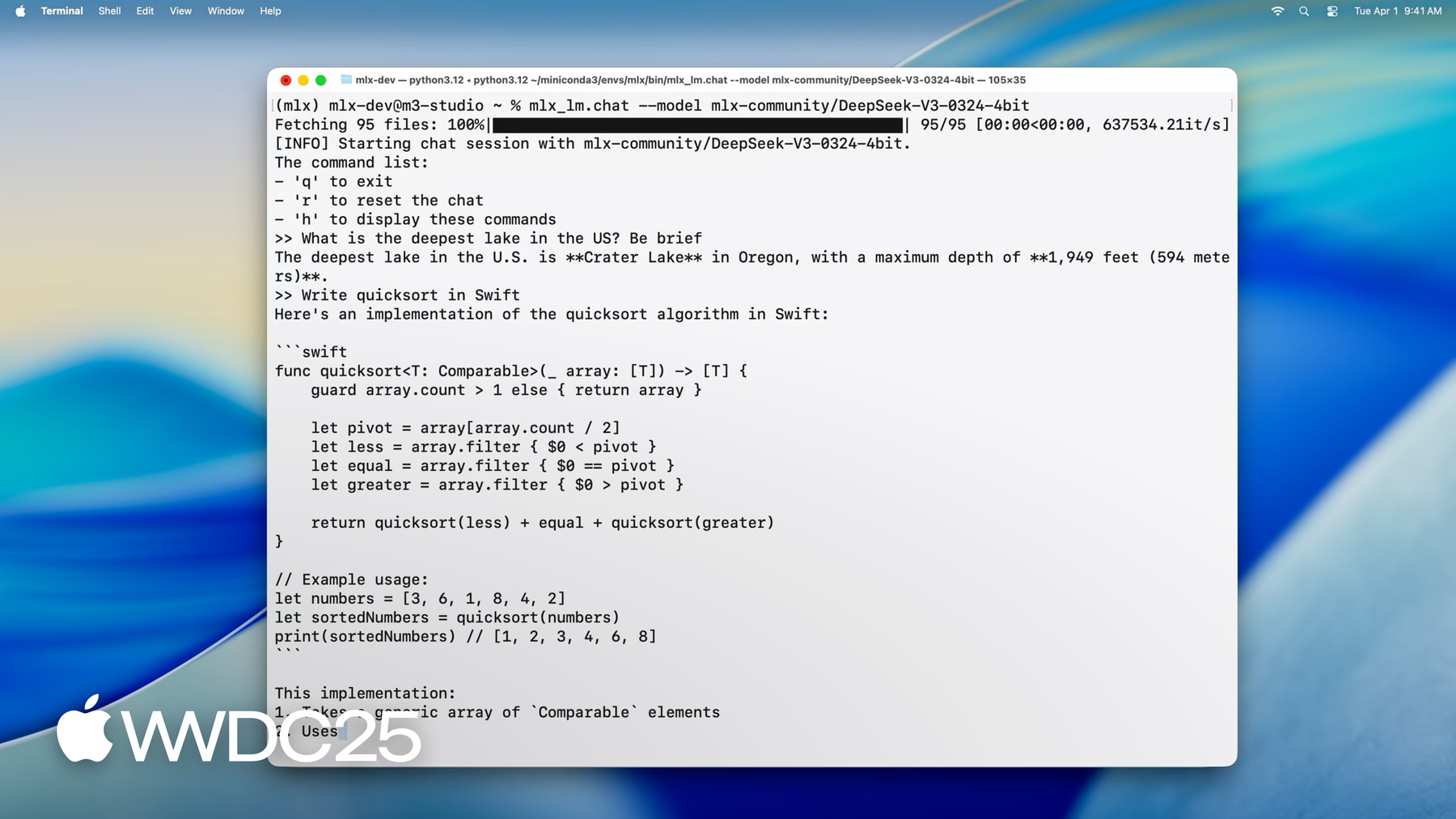
1:12 - Running DeepSeek AI's model with MLX LM
mlx_lm.chat --model mlx-community/DeepSeek-V3-0324-4bit -
3:51 - Text generation with MLX LM
mlx_lm.generate --model "mlx-community/Mistral-7B-Instruct-v0.3-4bit" \ --prompt "Write a quick sort in Swift" -
4:35 - Changing the model's behavior with flags
mlx_lm.generate --model "mlx-community/Mistral-7B-Instruct-v0.3-4bit" \ --prompt "Write a quick sort in Swift" \ --top-p 0.5 \ --temp 0.2 \ --max-tokens 1024 -
4:48 - Getting help for MLX LM
mlx_lm.generate --help -
5:26 - MLX LM Python API
# Using MLX LM from Python from mlx_lm import load, generate # Load the model and tokenizer directly from HF model, tokenizer = load("mlx-community/Mistral-7B-Instruct-v0.3-4bit") # Prepare the prompt for the model prompt = "Write a quick sort in Swift" messages = [{"role": "user", "content": prompt}] prompt = tokenizer.apply_chat_template( messages, add_generation_prompt=True ) # Generate the text text = generate(model, tokenizer, prompt=prompt, verbose=True) -
6:24 - Inspecting model architecture
from mlx_lm import load, generate model, tokenizer = load("mlx-community/Mistral-7B-Instruct-v0.3-4bit") print(model) print(model.parameters()) print(model.layers[0].self_attn) -
8:01 - Generation with KV cache
from mlx_lm import load, generate from mlx_lm.models.cache import make_prompt_cache # Load the model and tokenizer directly from HF model, tokenizer = load("mlx-community/Mistral-7B-Instruct-v0.3-4bit") # Prepare the prompt for the model prompt = "Write a quick sort in Swift" messages = [{"role": "user", "content": prompt}] prompt = tokenizer.apply_chat_template( messages, add_generation_prompt=True ) cache = make_prompt_cache(model) # Generate the text text = generate(model, tokenizer, prompt=prompt, prompt_cache=cache, verbose=True) -
9:37 - Quantization
mlx_lm.convert --hf-path "mistralai/Mistral-7B-Instruct-v0.3" \ --mlx-path "./mistral-7b-v0.3-4bit" \ --dtype float16 \ --quantize --q-bits 4 --q-group-size 64 -
10:33 - Model quantization with MLX LM in Python
from mlx_lm.convert import convert # We can choose a different quantization per layer def mixed_quantization(layer_path, layer, model_config): if "lm_head" in layer_path or "embed_tokens" in layer_path: return {"bits": 6, "group_size": 64} elif hasattr(layer, "to_quantized"): return {"bits": 4, "group_size": 64} else: return False # Convert can be used to change precision, quantize and upload models to HF convert( hf_path="mistralai/Mistral-7B-Instruct-v0.3", mlx_path="./mistral-7b-v0.3-mixed-4-6-bit", quantize=True, quant_predicate=mixed_quantization ) -
13:37 - Model fine-tuning
mlx_lm.lora --model "mlx-community/Mistral-7B-Instruct-v0.3-4bit" --train --data /path/to/our/data/folder --iters 300 --batch-size 16 -
15:06 - Prompting before fine-tuning
mlx_lm.generate --model "./mistral-7b-v0.3-4bit" \ --prompt "Who won the latest super bowl?" -
15:34 - Fine-tuning to learn new knowledge
mlx_lm.lora --model "./mistral-7b-v0.3-4bit" --train --data ./data --iters 300 --batch-size 8 --mask-prompt --learning-rate 1e-5 -
15:48 - Prompting after fine-tuning
mlx_lm.generate --model "mlx-community/Mistral-7B-Instruct-v0.3-4bit" \ --prompt "Who won the latest super bowl?" \ --adapter "adapters" -
16:29 - Fusing models
mlx_lm.fuse --model "mlx-community/Mistral-7B-Instruct-v0.3-4bit" --adapter-path "path/to/trained/adapters" \ --save-path "fused-mistral-7b-v0.3-4bit" \ --upload-repo "my-name/fused-mistral-7b-v0.3-4bit" # Fusing our fine-tuned model adapters mlx_lm.fuse --model "./mistral-7b-v0.3-4bit" \ --adapter-path "adapters" \ --save-path "fused-mistral-7b-v0.3-4bit" -
17:14 - LLMs in MLX Swift
import Foundation import MLX import MLXLMCommon import MLXLLM @main struct LLM { static func main() async throws { // Load the model and tokenizer directly from HF let modelId = "mlx-community/Mistral-7B-Instruct-v0.3-4bit" let modelFactory = LLMModelFactory.shared let configuration = ModelConfiguration(id: modelId) let model = try await modelFactory.loadContainer(configuration: configuration) try await model.perform({context in // Prepare the prompt for the model let prompt = "Write a quicksort in Swift" let input = try await context.processor.prepare(input: UserInput(prompt: prompt)) // Generate the text let params = GenerateParameters(temperature: 0.0) let tokenStream = try generate(input: input, parameters: params, context: context) for await part in tokenStream { print(part.chunk ?? "", terminator: "") } }) } } -
18:00 - Generation with KV cache in MLX Swift
import Foundation import MLX import MLXLMCommon import MLXLLM @main struct LLM { static func main() async throws { // Load the model and tokenizer directly from HF let modelId = "mlx-community/Mistral-7B-Instruct-v0.3-4bit" let modelFactory = LLMModelFactory.shared let configuration = ModelConfiguration(id: modelId) let model = try await modelFactory.loadContainer(configuration: configuration) try await model.perform({context in // Prepare the prompt for the model let prompt = "Write a quicksort in Swift" let input = try await context.processor.prepare(input: UserInput(prompt: prompt)) // Create the key-value cache let generateParameters = GenerateParameters() let cache = context.model.newCache(parameters: generateParameters) // Low level token iterator let tokenIter = try TokenIterator(input: input, model: context.model, cache: cache, parameters: generateParameters) let tokenStream = generate(input: input, context: context, iterator: tokenIter) for await part in tokenStream { print(part.chunk ?? "", terminator: "") } }) } }
-
-
- 0:00 - Introduction
MLX est une bibliothèque open source optimisée pour la puce Apple, permettant un apprentissage automatique efficace sur Mac. Elle utilise Metal pour l’accélération GPU et la mémoire unifiée pour une collaboration fluide entre le CPU et le GPU. MLX prend en charge Python, Swift, C++ et C. MLX LM, une bibliothèque Python accompagnée d’outils en ligne de commande, simplifie l’exécution, le réglage fin et l’intégration de grands modèles de langage sur la puce Apple. Vous pouvez charger, utiliser et générer du texte à partir de modèles de pointe, tels que le modèle à 670 milliards de paramètres de DeepSeek AI, directement sur votre Mac, avec une vitesse et des performances impressionnantes.
- 3:07 - Introduction de MLX LM
MLX LM est un package Python basé sur MLX, conçu pour exécuter et expérimenter de grands modèles de langage. Il propose des outils en ligne de commande ainsi qu’une API Python pour la génération de texte et le réglage fin, avec une intégration à Hugging Face pour le téléchargement et le partage de modèles. Vous pouvez l’installer avec la commande : pip install mlx-lm.
- 3:51 - Génération de texte
MLX LM est un outil qui permet de générer du texte à l’aide de modèles de langage provenant de Hugging Face ou stockés localement. Il propose deux interfaces principales : un outil en ligne de commande et une API Python. L’outil en ligne de commande vous permet de générer du texte à partir d’invites simples, avec des options de personnalisation de base. L’API Python offre un contrôle plus avancé, vous permettant de charger des modèles, de générer du texte et d’inspecter et de modifier l’architecture du modèle. L’API Python prend également en charge les conversations multi-tours grâce à un cache clé-valeur, qui stocke efficacement les résultats intermédiaires, ce qui permet de gagner du temps et de réduire la charge de calcul. Cela rend MLX LM particulièrement adapté à la création de chatbots, d’assistants virtuels et d’autres applications interactives nécessitant la conservation du contexte sur plusieurs échanges.
- 8:42 - Quantification
La quantification de modèles est une technique utilisée pour réduire la précision des modèles d’apprentissage automatique, afin de les rendre plus compacts et plus rapides, en particulier pour les déploiements sur des appareils plus petits. MLX simplifie ce processus grâce à son API de quantification. Vous pouvez utiliser la commande mlx_lm.convert pour télécharger, convertir et enregistrer des modèles en une seule étape. Cette commande offre un contrôle précis, vous permettant d’appliquer différents réglages de quantification à diverses parties du modèle, afin de trouver le juste équilibre entre qualité et performance. Les modèles quantifiés peuvent ensuite être utilisés immédiatement pour l’inférence ou l’entraînement dans MLX, ou être partagés avec d’autres via Hugging Face.
- 11:39 - Mise au point
MLX LM vous permet d’affiner des grands modèles de langage localement sur un Mac, sans écrire de code ni envoyer de données dans le cloud. Ce processus permet d’adapter des modèles généralistes à des domaines ou à des tâches spécifiques en utilisant des jeux de données plus petits et spécialisés. MLX LM prend en charge deux principales méthodes de réglage fin : réglage fin complet du modèle et entraînement sur des adaptateurs de bas rang. L’entraînement d’adaptateurs est plus rapide, plus léger et plus économe en mémoire, ce qui le rend idéal pour un usage sur du matériel local. Vous pouvez lancer le réglage fin à l’aide d’une seule commande, en spécifiant le modèle, le jeu de données et la durée de l’entraînement. Pour un contrôle plus avancé, des fichiers de configuration d’entraînement sont disponibles. Après le réglage fin, les adaptateurs peuvent être fusionnés avec le modèle de base, créant ainsi un modèle autonome et mis à jour, facile à distribuer et à utiliser, et pouvant même être publié dans des référentiels Hugging Face pour le partage.
- 17:02 - LLM dans MLXSwift
MLX apporte simplicité et flexibilité à Swift pour l’utilisation de grands modèles de langage. Il permet de charger, de tokeniser et de générer du texte avec des modèles quantifiés en utilisant seulement quelques lignes de code. La gestion des conversations multi-tours ne nécessite que quelques lignes supplémentaires pour créer un cache clé-valeur. MLX propose des opérations de base open source en C, C++, Python et Swift, ainsi que des API de haut niveau en Python et en Swift, permettant des processus d’apprentissage automatique efficaces sur le matériel Apple.