-
Metal Compute on MacBook Pro
Discover how you can take advantage of Metal compute on the latest MacBook Pro. Learn the fundamental principles of high-performance Metal compute and find out how you can take advantage of the framework to create better workflows for your development process and even better apps for creative pros.
Resources
Related Videos
WWDC22
-
Search this video…
Jason Fielder: Hi, my name's Jason Fielder, and I'm with GPU Software Engineering team here at Apple.
We're going to learn how to take advantage of the awesome graphics processing capabilities of our new M1 Pro and M1 Max notebooks, and we'll be exploring the best practices you can adopt to make your applications perform great on our GPU.
Our latest MacBook Pros feature the most powerful chips we have ever created.
The M1 Pro has up to 16 GPU cores, and the M1 Max doubles that to 32.
This, coupled with much higher DRAM bandwidth, greatly increases the performance of the MacBook Pro.
The system memory is now available to the GPU thanks to our Unified Memory Architecture, and with up to 64GB available, our GPU application is able to access more memory than ever before.
These MacBook Pros will open up a whole new world of possibilities for developers and creative pros, enabling workflows that were previously only targeting desktop machines.
So how do we open up this new world of GPU potential? We'll start with a recap of Metal Compute, which enables work to be scheduled on the GPU.
Then, with an understanding of the API and the GPU architecture, we will look at the best practices for each stage of your app.
Then we'll conclude with some specific kernel optimizations that you can apply.
Let's start with a quick refresh of Metal Compute.
Metal is Apple's modern low-overhead API for performing GPU work.
It is designed to be as thin and as efficient as possible and provides a unified graphics and compute interface.
Metal is multithread friendly, enabling work to be trivially queued from multiple CPU threads, and gives you, the developer, flexibility to use an offline or online shader compilation pipeline.
Under the hood in our hardware layer, we have a CPU and GPU both connected to the same physical memory.
The CPU creates GPU resources within the unified memory block, and both the GPU and CPU are able to read and write to these resources.
We've a few layers of API to work through to see a kernel executed on the GPU.
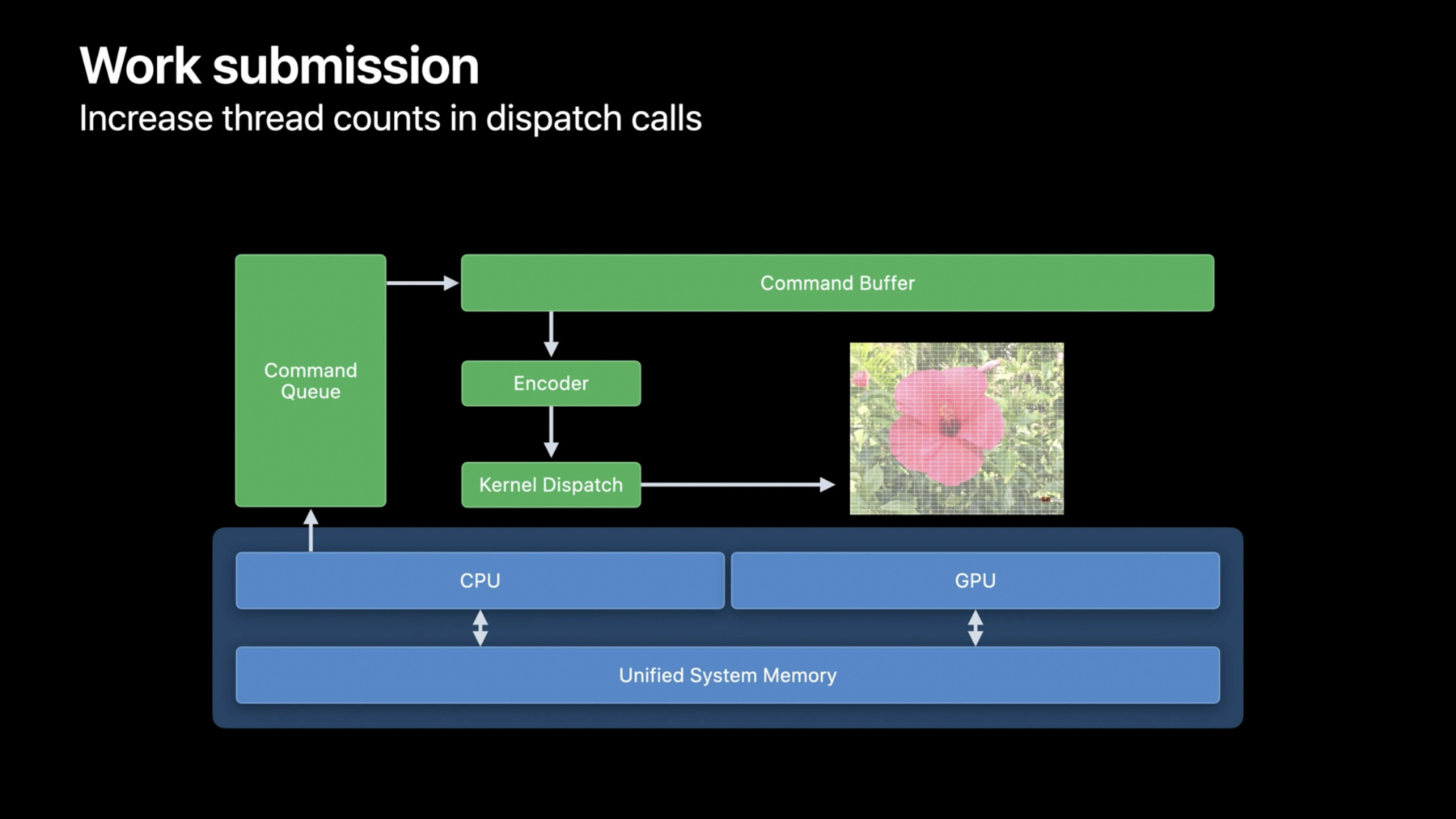
The top layer is the command queue.
As per its name, this object allows an application to queue work for execution at some points on the GPU.
The commands are batched up on the CPU through a command buffer.
These objects are transient, and you'll create a lot of these at the granularity that makes sense for your app.
You may find this is imposed by requirements around CPU and GPU synchronization, but in short, you'll want to ensure you have enough work to keep the GPU fully busy.
To put instructions into the command buffer, we'll need a command encoder.
There are different types of command encoders targeting different types of work.
There's a graphics encoder for 3D draws, a blit encoder for copying resources around, but for this talk, we'll focus on the compute encoder for kernel dispatches.
With a compute encoder in place, we're now ready to encode a kernel dispatch.
Along with the kernel function itself, the encoder is how resources needed by the kernel are bound to it.
In fact we can encode multiple kernel dispatches to the same encoder.
We can change kernel, or bound resources between each dispatch and also inform Metal whether a dispatch can be executed concurrently or should be serialized and executed after the previous dispatch has completed.
With our encoding complete, we end the encoder which makes the command buffer available to either start encoding a new encoder or to commit the command buffer to the GPU for execution.
Here we've encoded a total of three compute encoders to the GPU.
This represents a body of work from start to finish, and we're ready to instruct the GPU to start executing it.
A call to commit returns immediately, and Metal will ensure that the work is scheduled and executed on the GPU once all other work before it in the queue has completed.
The CPU thread is now available to start building a new command buffer, or perform any other app work that's appropriate while the GPU is busy.
The CPU is likely going to need to know when a body of work has been completed, though, so that its results can be read back.
For this, the command buffer has two techniques for us.
Here, before committing the work, the application can add a completion handler function that will be invoked by Metal once the work has completed.
For simple cases, there is a synchronous method called waitUntilComplete that will block the calling CPU thread, but here we're using the asynchronous method.
So this is our basic execution model.
One final feature of the API is that multiple command buffers can be encoded simultaneously.
Multiple CPU threads can encode multiple command buffers at once, and commit the work once encoding is complete.
If ordering is important, either reserve the command buffer's place for execution in the command queue by calling enqueue, or alternatively, simply call commit in the desired order.
Use whichever approach fits your application best.
With the possibility of creating multiple command queues too, the flexibility of Metal enables an app to encode work to the GPU in a pattern most efficient for its needs.
So that's the recap of the execution model Metal exposes.
Let's build on that and take a look at how to optimize for it.
We've a handful of recommendations on how your app should access GPU memory to take advantage of our Unified Memory Architecture, how to submit work to the GPU to align with the compute model we just went over, and how to choose which resources to allocate to align best with our UMA.
First up to talk about is definitely the Unified Memory Architecture.
This set of best practices is about minimizing the amount of work necessary on the GPU.
With a Unified Memory Architecture, the traditional management of copies between system RAM and video RAM goes away.
Metal exposes the UMA through shared resources that allow the GPU and CPU to read and write the same memory.
Resource management is then about synchronizing the access between the CPU and GPU to happen safely at the right time, rather than duplicating or shadowing data between system memory and video memory.
Working from a single instance of a resource in memory drastically reduces the requirements on memory bandwidth your app may have, enabling large performance gains.
Where there is possible contention -- such as the CPU needing to update a buffer for a second batch of work while the GPU is still executing the first batch -- an explicit multi-buffer model is necessary.
The CPU prepares content in buffer n, while the GPU is reading from buffer n-1 and then increments n for the next batch.
This allows you as the app developer to tune for your memory overheads and access patterns, and avoid unnecessary CPU/GPU stalls or copies.
The limit on amount of GPU resources an app can allocate has two values to be aware of.
The total amount of GPU resources that can be allocated, and more critically, the amount of memory a single command encoder can reference at any one time.
This limit is known as the working set limit.
It can be fetched from the Metal device at runtime through reading recommendedMaxWorkingSetSize.
We recommend you make use of this in your app to help control how much memory you look to use and rely on being available.
While a single command encoder has this working set limit, Metal's able to allocate further resources beyond this.
Metal manages the residency of these resources for you, and just like system memory allocations, the GPU allocations are also virtually allocated and made resident before execution.
By breaking up your resource usage across multiple command encoders, an application can use total resources in excess of the working set size and avoid the traditional constraints associated with hard VRAM limits.
For the new MacBook Pros, the GPU working set size is shown in this table.
Now, for an M1 Pro or M1 Max with 32GB of system RAM, the GPU can access 21GB of memory, and for an M1 Max with 64GB of RAM, the GPU can access 48GB of memory.
This is by far the highest amount of memory we've ever made available to the GPU in a Mac, and the new MacBook Pro lineup offers greatly expanded capabilities to users.
We're really excited to see what experiences you'll be able to empower users with and to experience what they'll create with it.
That's our best practices for working with UMA, and we're ready for our next topic.
At the command buffer level, there's latency with submitting it.
Small amounts of work can lead to more time spent waiting than working.
Look to batch more encoders together into each command buffer before making that call to commit.
If your app spends time waiting for GPU results to inform what should be dispatched next, then bubbles will appear in the GPU timeline.
In these bubbles, the GPU is sitting idle, waiting for the next dispatch to arrive.
To hide this, consider using multiple CPU threads working on multiple pieces of work and keep the GPU busy.
Either by creating multiple command buffers, or by creating multiple command queues.
For the kernel dispatches themselves, the GPU is kept busy by having enough threads to work on, and with enough work within each thread to justify the overheads of launching it.
In our image processing example here, each pixel is processed by a single thread.
When you can, increase the number of total threads in the kernel dispatches to ensure all processing cores of the GPU can be utilized.
Here, a single kernel dispatch is used to process the entire image allowing Metal and the GPU to optimally distribute the work across all available processing cores.
Finally, where you do have and need smaller thread counts, use the concurrent dispatch model instead of the default serialize model.
We've observed many applications that run great on M1, but fall short of their potential on M1 Pro and M1 Max.
Submitting work in larger volumes using these techniques is an easy way for your application to scale and reach its potential.
The next consideration I want to talk about are L1 caches.
Apple Silicon GPUs contain separate L1 caches for texture reads and buffer reads.
With Metal being a unified API across graphics and compute, the full suite of texture objects and samplers are available to apps.
So if your application is only using buffers for its data sources, there are performance benefits to be had from moving some of these resources to textures.
This will allow better utilization of the GPU's high performance caches, reduce traffic from RAM, and increase performance.
Let's see what that looks like.
While the GPU accesses RAM for reads of all resources, there's a cache for improving the performance of future buffer reads to the same local area of memory.
The cache is of a limited size, though, and will fill quickly, so older data that hasn't been read for a while will be discarded to make way for newer reads.
Hypothetically, if our kernel operated on a small enough set of data, once the cache is populated, all future reads would hit the cache and complete with no stalls or delays caused by waiting for a system memory loads to complete.
The bandwidth to the cache is significantly higher, and with lower latency than of that to system RAM.
When reads miss the cache, the calling threads will stall while the read is fetched from RAM and placed into the cache.
Data reads become limited by the system memory bandwidth rather than the on-chip cache bandwidth.
A kernel accessing large amounts of data from buffers can thrash the cache in this way and result in reduced performance.
Apple silicon GPUs contains a second cache alongside the buffer cache that's dedicated to texture reads.
Applications can move some of their source data from Metal buffer objects to Metal texture objects, and effectively increase the amount of cache space and increase performance.
Also, texture data can be twiddled, and Metal will do this for you automatically on upload.
Twiddling means the texels are ordered more optimally for a random access pattern and can help improve cache efficiency further, giving another performance gain over a regular buffer.
This is transparent to the kernel when reading, so it doesn't add complexity to your kernel source.
Actually, textures are a gift that keeps on giving.
Apple Silicon can also perform a lossless compression of a texture -- after it's been created and when possible -- to further reduce the memory bandwidth of reading from it, and again, increase performance.
This, too, is transparent to the shader kernel as the decompression happens automatically on the texture read or sample.
A Metal texture will be compressed by default if it's private to the GPU, but shared and managed textures can explicitly be compressed after upload through a call to optimizeContentsForGPUAccess on a blit command encoder.
For lossless texture compression to be available, textures need to have their usage set to either shaderRead or renderTarget.
Ensure this is set on your descriptor when creating the texture object.
And if your texture data is actual image data, or being used in a way where lossy compression would be acceptable, then consider higher ratio lossy compression formats such as ASTC or BC.
This will further reduce both the memory footprint and bandwidth utilization, increasing the kernel's performance.
BC and ASTC can both be generated using offline tools, giving a great image quality, and have compression ratios ranging from 4:1 through to 36:1.
With our work now batched optimally, utilizing buffers and textures for our data input, and being UMA aware to reduce the amount of copy work we're performing, we're ready to look at kernel optimizations.
All of these best practices are aimed at increasing your kernel's performance.
Let's take a look at some of them.
I'm going to focus on memory indexing, global atomics, and occupancy as areas of opportunity in your kernels.
We'll also take a look at where to look in our profiling tools to understand your kernel's bottlenecks and how to measure any improvements any optimizations may have.
At last year's WWDC, our GPU software team released a video on Metal optimization techniques for Apple silicon.
I'll recap briefly some of that talk's content here, but for complete details and examples, please do watch that presentation.
First up, I want to talk about memory indexing.
When indexing into an array, use signed integer types over unsigned types.
Here we have a for loop, with count variable i declared as unsigned.
Due to the wrapping characteristics of uint in the shader language spec, this disables vectorized loads.
Usually, this is not what you want, and the extra code generated can be avoided by using a signed type.
And here, as the wrapping behavior of int is undefined, the load will be vectorized and likely give a performance improvement.
With the increase of GPU cores and memory bandwidth in the new MacBook Pros, we have seen the primary bottlenecks of some GPU workloads shift from ALU or memory bandwidth usage to other areas.
One of those areas is global atomics.
Our recommendation is to minimize the use of atomic operations in your kernels, or use techniques built around thread-group atomics instead.
As with all good optimization workflows, profile your shaders first to understand if this is a problem you're experiencing, as moderate use of atomics won't be a problem.
So how do we get this vital profiling information? By using the GPU frame debugger inside Xcode.
It is a great tool for this evaluation work.
It provides a wealth of insight into the work occurring on the GPU and once we have our capture, we're able to browse it.
The timeline view gives us a great overview of our workload, and shows us graphs visualizing the major performance counters of the GPU.
Many of these counters give both a utilization and a limiter value.
Using ALU as an example here, the utilization number is telling us that the kernel used about 27 percent of the GPU's ALU capabilities during execution.
Other time was spent doing other tasks, such as data reads and writes, making control logic decisions, et cetera.
The limiter figure means the GPU is bottlenecked by ALU utilization for about 31 percent of the kernel's execution time.
So how can the GPU be utilizing 27 percent of the GPU's ALU capabilities but be bottlenecked by ALU for 31 percent? The limiter can be thought of as the efficiency of the ALU work that was done.
It is the time spent doing actual work, plus the time spent on internal stalls or inefficiency.
In best case, these times are equal, but in practice, there is a difference.
A large difference indicates that the GPU has work to do, but is unable to do it for some reason.
Complex ALU operations such as log() for instance, or using expensive texture formats, can result in underutilization, and signify that there could be scope to optimize the kernel's math.
These two figures work hand in hand to help you understand the general makeup of work your kernels are performing, and how efficient each category of work is to perform.
With this particular kernel, we can see that occupancy is at 37 percent.
This value looks low and certainly worthy of investigation to understand if it can be increased.
Let's take a closer look at occupancy.
It is the measure of how many threads are currently active on the GPU, relative to the maximum that could be.
When this figure is low, it is important to understand why, to determine if this is expected or signifies a problem.
Low occupancy sometimes isn't surprising nor avoidable, if for instance your submitted work has a comparatively low number of threads because the work to perform is simply small.
It can also be okay if the GPU is limited by other counters, such as ALU.
However a low occupancy coupled with low limiter counters signifies that the GPU has capacity to execute more threads simultaneously.
So what may be causing problematic low occupancy? A common reason for this is exhausting thread or thread-group memory.
Both of these resources are finite on the GPU and shared among the running threads.
Thread memory is backed by registers, and as the pressure for registers increases, occupancy can be decreased to accommodate.
With a high thread-group memory usage, the only way to increase occupancy is to reduce the amount of shared memory used.
Reducing threrad-group memory can also help reduce the impact of thread-register pressure.
There is scope for the compiler to spill registers more efficiently when the maximum thread count in a thread group is known at pipeline state creation time.
These optimizations can be enabled by setting either maxThreadsPerThreadgroup on the compute pipeline state descriptor or by using the Metal Shader langauge max_total_threads_per threadgroup attribute directly in your kernel source.
Tune this value to find the balance that works best for your kernels.
Aim for a value that is the smallest multiple of the thread execution width that works for your algorithm.
Let's go deeper into register pressure.
When this is high, we will see register spill in Xcode's GPU profiler.
With this kernel example, we can see that our occupancy is at 16 percent, and this is really low.
Looking at the compiler statistics for this kernel shows the relative instruction costs of it, including the spilled bytes.
This spill, along with the temporary registers, is likely the cause of our poor occupancy.
We are exhausting the thread memory, and occupancy is reduced to free up more registers for the threads that will run.
Registers are allocated to a kernel in register blocks, and as such, you'll need to reduce the usage by up to the block size to see a potential increase in occupancy.
Optimizing for minimal register usage is a great way to make impactful performance improvements to complex kernels, but how do we do this? Preferring 16bit types over 32bit types increases the number of registers available to other parts of the kernel.
Conversion between these types to their 32bit counterparts is usually free.
And reducing the data stored on the stack -- for example, large arrays or structs -- can consume a large number of registers and reducing them is an effective tool.
Look to tune your shader inputs to make the best use of the constant address space.
This can drastically reduce the number of general purpose registers being used unnecessarily.
And final tip is to avoid indexing into arrays stored on the stack or in constant data with a dynamic index.
An example of this is shown here, where an array is initialized at runtime.
If index is not known to the compiler at compile time, the array will likely spill to memory.
In this second example, though, index is known at compile time, and the compiler will likely unroll the loop and be able to optimize away any spill.
Each of these techniques will reduce the allocation of registers, reduce spill, and help increase occupancy for more performant kernels.
For more insights into Metal optimization techniques for Apple Silicon, do watch the WWDC 2020 video, "Optimize Metal Performance for Apple Silicon Macs." And there you have it.
Let's review what we covered today.
We started with a review in the role of command queues, command buffers, and command encoders to remind ourselves about the submission model, and how work is queued to the GPU in Metal, and we explored how to encode Metal commands from multiple threads to reduce the CPU encoding time and cost.
With that knowledge, we looked at recommendations on how to tune your applications; avoiding unnecessary copies to take advantage of the unified memory architecture; submitting larger quantities of work; and using Metal textures as well as Metal buffers for our kernel's resources.
And finally, we took a walkthrough of how to use our tools to identify performance bottlenecks.
We understood how to interpret the GPU's utilization and limiter values, and how we can tackle problematic low occupancy if we discover it.
Thank you very much, and I hope you're as excited as I am by what's possible with the most powerful MacBook Pro lineup ever.
-