-
Embracing Algorithms
When you imagine building a new app, what do you think about? Models, views, and controllers deserve their prominent place in the design process, but we don't often give the same attention to the underlying work our apps need to do. Understand how to identify and optimize the algorithms in your app, and discover how implementing algorithms as generic protocol extensions results in efficient, effective, and maintainable code.
Resources
Related Videos
WWDC21
WWDC18
-
Search this video…
Hi, everybody. It's great to see you all here today. I'm Dave, and the next 40 minutes are about understanding and honoring what makes our programs actually work.
There will be practical advice, but this is not a talk about tips and techniques or any specific algorithms even, though we will look at a few.
It's about revealing something fundamental, the potential of which is already present in your code. I hope that for at least a few of you it marks the beginning of a new relationship to the practice of programming.
Speaking personally, when I discovered this approach, it changed the course of my life and my career. It's the reason I care so much about software libraries, but it's also the source of the liability, maintainability, and performance in every piece of concrete code I've written since.
But before we get into that, let me introduce you to a friend of mine.
This is Crusty.
Crusty is old school. He doesn't trust debuggers or or mess around with integrated development environments. No, he favors an 80 x 24 terminal window in plain text, thank you very much.
Now, Crusty takes a dim view of the latest programming fads, so it can sometimes be an effort to drag him into the 21st century. He just thinks different.
But if you listen carefully, you can learn a thing or two. Now, sometimes his cryptic pronouncements like "programming reveals the real; border on the mystical." And to understand him, I found it helpful to actually write some code.
So, lately, I've been working on a little program called Shapes.
I'm hoping to make it into a full-featured vector drawing program, but so far it lets you arrange shapes on an infinite canvas.
Now, I want to tell you the story of the delete selection command because I learned so much from implementing this one feature.
I think we've probably all gone through part of this progression as programmers as we learn how to remove things from an array. Everybody starts out doing something like this.
That's the delete selection command.
We loop from 0 to count, and when we find something to delete, we remove that, and then we continue with our loop until, ouch, we walk off the end.
The array got shorter, but we picked the number of iterations when the loop started. Fortunately, you can't miss this bug if you Swift and test your code because it'll trap. But if you had to learn this lesson as a C-programmer, like I did, you might not be so lucky. Okay. So, we can fix it by replacing the for loop with a somewhat uglier while loop, which lets us examine the count at each iteration. But there's a subtle bug in this one too.
If two consecutive elements are selected, it'll remove the first one and then immediately hop over the next one. Now, this bug is a little more insidious because it hides from you unless your tests happen to exercise it. But if we're lucky enough to notice it, we press ahead and we fix the implementation again by guarding the increment in an else block. So, are we done now? Are we sure this one is correct? I think I can prove to myself that it works.
Anyway, having gone through this ordeal, what do we do? Well, of course, we lock this nine-line pattern into our brains so we can trot it out whenever we have to delete something. Now, I'm sure many of you have been holding yourselves back from screaming at me because that there's a much more elegant way to do it. I still remember the day I discovered this trick for myself because once you find it, you never do this nine-line dance again. The iteration limit and the index of the next item to examine kept shifting under our feet because remove(at: i) changes parts of the array after i.
But if you go backwards, you only iterate over the parts of the array that you haven't changed yet.
Slick, right? And this is the pattern I've used ever since because it's clean, and it never fails, until a few months ago. One morning, I had just finished my avocado toast, and I was idly fooling with my app when I tried deleting about half the shapes from a really complicated canvas.
My iPad, it froze up for like three seconds. So, I took a sip of my half caf triple shot latte in its bamboo thermal commuter cup, and I considered my options.
This was disturbing. I mean, it's a pretty straightforward operation, and my code was so clean, how could it be wrong? Profiling showed me that the hot spot was right here, but beyond that, I was stumped. So, just about then, Crusty walked up behind me carrying a can of off-brand coffee grounds from the local supermarket for his daily brew.
"Stuck?" he said. "Yeah," I sighed, and I explained the situation. "Well, did you even look at the documentation for that?" Well, I hadn't, so I popped up the Quick Help for Remove At, and Crusty leaned in. "There's your problem, right there," he said, leaving a smudge on my gorgeous retina display.
Now, I carefully wiped off the fingerprint with a handcrafted Italian microfiber cloth, and Crusty said, "What's that tell you, son?" "Well," I said, "it means that removing an element takes a number of steps proportional to the length of the array." And it kind of makes sense, since the array has to slide all of the following elements into their new positions.
"So, what's that mean about your Delete Selection command?" he asked.
"Uh," I said. That's when he pulled out a pack of mentholated lozenges and lined them up on my desk. "Try it yourself." So, I went through the process as I tried to answer his question. "Well, since Delete Selection has to do order n steps, once for each selected element, and you can select up to n elements, the total number of steps is proportional to n squared." Crusty added, "That's quadratic, son, whether you do it the ugly forward way or the fancy pants backward way." I realized then that for my little 10 to 20-element test cases, we'd only been talking about a few hundred steps, and since the steps are pretty fast, it seemed great.
But the problem is that it doesn't scale well. Fifty squared is 2,500 and 100 squared is 10,000. So, if you do all your testing in this little region down here, you'll probably never see it, but scalability matters because people are using their phones and iPads to manage more and more data, and we keep shipping devices with more memory to help them do it.
You care about this because scalability is predictability for your users. So, now, I understood the problem, but I still wasn't sure what to do about it. "Now what?" I asked Crusty.
"You know, kid," he said, popping a lozenge, "there is an algorithm for that." I told him, "Listen, Crusty, I'm an app developer.
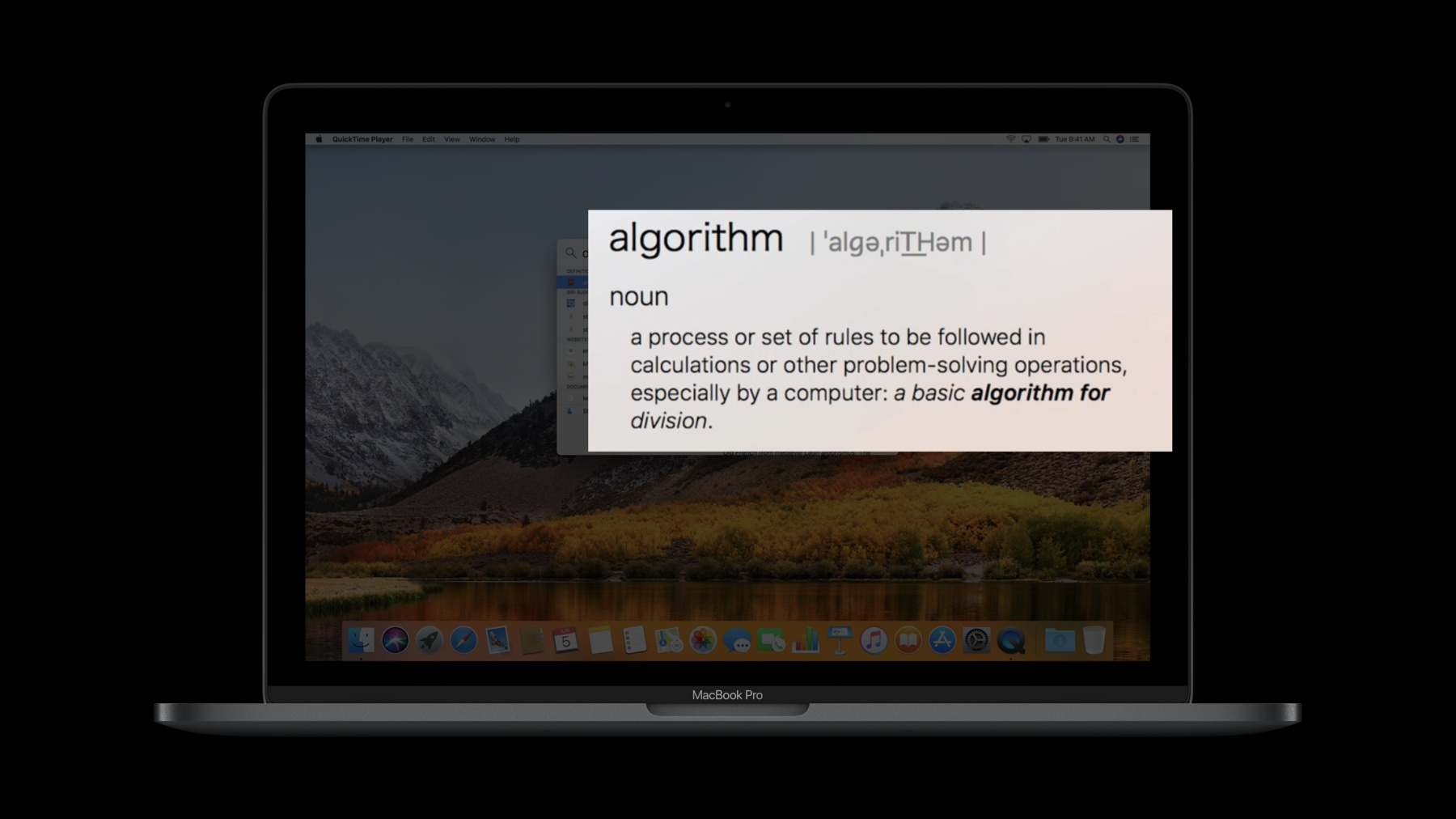
You say you don't do object oriented. Well, I don't 'do' algorithms." You pay attention to your data structures in algorithms class because you know when it's time to get a job, your interviewer is going to ask you about them. But in the real programming world, what separates the elite from the newbies is the ability to wire together controllers, delegates, and responders to build a working system. "Bonkey," he said; I don't know why he calls me that, "What do computers do?" "They compute." "Now, where's the computation in all that?" "Well," I replied, "I guess I don't see anything that looks like an algorithm in my code." But Crusty wasn't having it. "Oh, your app is full of them," he said, dropping an old dead tree dictionary on my desk, "Look it up." After I gathered my composure, I carefully slid the book to one side and typed Define Algorithm into Spotlight, which Crusty thought was a neat trick.
Hmm. A process or set of rules to be followed in calculations or other problem solving operations.
Well, come to think of it, that did sound like most code, but I still wasn't sure.
"You ever do a long division?" asked Crusty. "That's an algorithm." I started to type into Spotlight again, but he snapped, "On paper." And not wanting to embarrass myself, I turned the subject back to my code.
"Hmm." I asked, "So, what is this magic algorithm that will cure my performance problem?" "Well, if you'll just let me at your TTY there for a minute," he said, "How do you work this thing? Oh, it's a track pad. I'll try not to touch that. So, first, you do away with this foolishness.
Now, shapes.removeallwhere the shape is selected. Hmm. Try that on for size." Now, Crusty headed off to wash out the pitcher of his coffee maker, leaving me to figure out what had just happened in my code. First, I checked, and I found that the performance problem was fixed. Nice.
And I didn't want another earful from Crusty about looking at the documentation, so I popped up Quick Help for removeAll(where: and I saw that its complexity scales proportionally to the length of the collection just like removeAt. But since I didn't have to put it in a loop, that became the complexity of my whole operation.
Now, I want to give you some intuition for the kind of difference this makes. What are n means that the time the algorithm runs scales linearly with the problem size. The graph is a straight line.
Now, the orange line is the shape of order n squared.
As you can see, a linear algorithm may do worse on a small problem, but it's eventually faster than a quadratic algorithm.
The cool thing is though, it doesn't matter how expensive you make the steps of the linear algorithm, if you keep looking at larger problem sizes, you'll always find one where the linear algorithm wins and continues to win forever.
So, we're talking about scalability, not absolute performance.
Well, my scalability problem was fixed, but I really wanted to see how the standard library had improved on my backward deletion scheme.
Crusty reminded me that Swift is open source, so I could pull it up on what he calls "the hipster web." But the rest of us know as GitHub.
Now, the first thing I noticed was the dot comment, which was the source of all that Quick Help, describing both what the algorithm does and its complexity. Next, it turns out that removeAll(where) isn't just some method on a reg; it's a generic algorithm, which means that it works on a wide variety of different collections.
It depends on a couple of things, the ability to rearrange elements, which comes from mutable collection, and the ability to change the length and structure, which comes from range-replaceable collection. And it's built from a couple of other order n algorithms. The first is a half stable partition, which moves all of the elements satisfying some predicate to the end and tells us where that suffix starts.
The half stable in its name, that comes, that indicates that it preserves the order of the elements that it doesn't move, but it can scramble the elements that it moves to the end. Now, sometimes, that doesn't matter though; the second algorithm removes subrange. It's just going to delete them anyway.
Have we all seen this partial range notation? It's just a really convenient way of writing a range that extends to the end of the collection.
Okay. Now, remove subrange is part of the library's public API, so you can find its documentation online, but halfStablePartition is an implementation detail. Now, we're not going to step through all of it, but there are a few things worth noticing here.
First, it starts by calling yet another algorithm, firstIndex(where), to find the position of the first element that belongs in the suffix.
Next, it sets up a loop variable j, and there's a single loop, and the loop index j moves forward one on each iteration.
So, it's a sure bet that j makes just one pass over the elements. You can almost see the order and complexity just from that. Lastly, because this method needs to rearrange elements but not change the length or structure of the collection, it only depends on mutable collection conformance. So, this is the first lesson I learned.
Become familiar with what's in the Swift Standard Library.
It contains a suite of algorithms with documented meanings and performance characteristics.
And although we happened to peek at the implementation, and you can learn a lot that way, it's designed so that you do not have to.
The official documentation should tell you everything you need to know in order to use the library effectively. You'll even find a playground tutorial there.
Now, I realize there's a lot in Swift, so it can look daunting, but you don't need to remember everything. Having an idea of what's there and how to find it will take you a long way.
Now, before we move on, I want to point out something else that happened in my code when Crusty made this change. Which one of these most directly describes its meaning? Now, I actually have to read and think through the first one to know what it's doing. Hmm. Maybe I'd better add a comment. Okay. How does that look? Oh, even with that comment, the reverse iteration is kind of tricky, and I don't want somebody breaking this code because they don't understand it. So, I'd better explain that. Okay. While we're clarifying things, the After code actually reads better with a trailing closure syntax. Now, take a breath and look again.
Which one is more obviously correct? Even with all these comments, I still need to read through the first one just to see that it does inefficiently the same thing as the second one.
Using the algorithm just made the code better in every way. So, this is a guideline, an aspiration for your code first put forward by Shawn Perin.
Every time you write a loop, replace it with a call to an algorithm. If you can't find one, make that algorithm yourself and move the loop into its implementation.
Actually following this might seem unrealistic to you now, but by the end of the talk, I hope it won't.
For a little motivation though, think back to the last time you were looking at spaghetti code. Was it full of loops? I bet it was. All right. Done and done. I have just made the code shorter, faster, and better in every way. I was ready to call it a day. "Thanks for your help, Crusty," I said, fastening the titanium carabiners on my bespoke leather messenger bag, but he looked at me suspiciously, and said, "You suppose you might have made that mistake anywhere else?" I sighed, put my bag down and started hunting down the loops in my code.
There were lots in the file . Bring to front, send it back, bring forward, which sort of hops the selected shape over the one in front of it.
Let's do that a couple of more times. Send backward with hops, under the shape, below the selected shape, and last of all, dragging in the shape list at the left. Now, these sound really simple until you realize that they all need to operate on multiple selected shapes that might not even be contiguous in the list.
So, it turns out that the behavior that makes sense is to leave all of the selected elements next to each other after the operation is finished. So, when you're bringing shapes forward, you hop the front most selected shape in front of its neighbor, and then you group all the other ones behind it.
And when you send shapes backward, you hop the bottom most selected shape backward behind its neighbor and group the other ones in front of it.
So, if you didn't follow that completely, don't worry. We'll come back to it. But suffice it to say that I had some pretty carefully worked out code to get all of these details right.
For example, this was bringToFront, and when I looked at it, sure enough, there was an order n loop over the shapes containing two order n operations, remove(at:) and insert(at:), which makes this, you guessed it, n squared.
In fact, that same problem showed up in every one of my other four commands.
All of the implementations here loop over an array, performing insertions and removals, which means they're all quadratic. Now, I was kind of discouraged at this point, so I asked Crusty if he'd look at them with me.
He said, "Can't stay too late," he said, "I got my ballroom dancing tonight, but I guess we better get a move on." So, I pulled up bringToFront, and Crusty's first question was, "What does it actually do?" "Well," I said, "there's a while loop and j tracks the insertion point and i tracks the element we're looking at." "In words, not in codes," said Crusty.
"Describe it." "Okay. Let's see. It moves the selected shapes to the front, maintaining their relative order." "Write that down in a dot comment and read it back to me." I'm a superfast typist.
"Moves the selected shapes to the front, maintaining their relative order." "Sound familiar?" said Crusty.
That's when I realized that this was a lot like half stable partition, except it's fully stable. I was starting to get excited. And what do you think this one is called? So, I had to guess, "Stable partition?" "That's right. One of my old favorites, and you can find an implementation in this here file from the Swift Open Source project." So, I pulled the file into my project, while Crusty mumbled something about how that comment we added should have been there all along, and I started coding, getting about this far before I had a problem.
You see, stable partition takes a predicate that says whether to move an element into the suffix of the collection. So, I had to express bring to front in terms of moving things to the back.
I looked at Crusty.
"Visualize it," he said. So, I closed my eyes and watched as the unselected shapes gathered at the back, which gave me my answer. Now, I guess sendToBack was even easier because we just need to invert the predicate. We're sending the selected ones to the back. Now, I was just about to attack the bring forward command, and I figured that Crusty would be as eager to move on as I was, given his plans for the evening, but he stopped me. "Hold your horses, Snuffy.
I don't want to miss the opening tango, but aren't you going to check whether it'll scale?" He had a point, so I popped up the Quick Help for stable partition, and I saw that it had (n log n) complexity. So, for a way to think about (n log n) take a look at log n. It starts to level off really quickly, and the bigger it gets, the slower it grows, and the closer it comes to being a constant. So, when you multiply that by n, you get something that doesn't scale quite as well as order n but that gets closer and closer to linear as it grows.
So, order n login is rightly often treated as being almost the same as order n. I was pretty happy with that. So, we moved on to bring forward. Now, as we said earlier, bring forward bumps the front most selected shape forward by one position and gathers the other selected shapes behind it.
But Crusty didn't like that way of thinking about it at all. "That little do-si-do at the beginning is making a line dance look like a Fox Trot." he said, "You don't need it." When I looked at him blankly, he broke out the lozenges again, and with five of his free digits, he executed the bringForward command.
"See it again?" he asked.
I felt a little like a mark in a Three-card Monte, but I played along. "Look familiar?" "No." He threw a hanky over the first few.
"How about now?" That's when I realized it was just another stable partition.
Okay. I got this, I thought.
If we find the front most selected shape, then move to its predecessor, and isolate the section of the array that starts there, we could just partition that.
"But how do you modify just part of a collection?" I asked Crusty.
"Ain't you never heard of a slice?" he said, taking over the keyboard.
"Shapes, starting with predecessor.
There. Stick that in your algorithm and mutate it." Which I promptly did.
So, human knowledge about how to compute things correctly and efficiently predates computers by thousands of years, going back at least to ancient Egypt, and since the invention of computers, there's been an explosion of work in this area.
If the standard library doesn't have what you need, what you do need is probably out there with tests, with documentation, often with a proof of correctness. Learn how to search the web for research that applies to your problem domain.
Okay. Back to the code. I was intrigued by this slice thing, and when I checked out its type, I saw that it wasn't an array. Since we had used stable partition on an array and bringToFront and sendToBack, and now we were using it on an array slice, I guessed out loud that it must be generic. "Of course, it is. What's stable partition got to do with the specifics of array?" "That's right, nothing. Speaking of which, Blonkey, just what does bringForward have to do with shapes and selection?" "Well," I said, "it works on shapes, and it brings forward the selected ones." "That's right, nothing," he went on without listening.
"Can you run bring forward on a row of lozenges? Of course, you can. So, it's got nothing to do with shapes." Hmm. "Are you suggesting we make it generic?" I asked. "Isn't that premature generalization?" Answering a question with a question, Crusty replied, "Well, just how do you plan to test this method?" "Okay," I said, "I'll create a canvas. I'll add a bunch of random shapes. I'll select some of them, and then finally..." But I didn't even finish the sentence because I knew it was a bad idea. If I did all of that, would I really be testing my function, or would I be testing the initializers of Canvas and various shapes, the addShape method, the isSelected property of the various shapes if it's computed? I have to build test cases for sure, but ideally, that code shouldn't depend on other code that I also have to test.
If I can bring the lozenges forward, it should be possible to do something casual with in a playground, like this, which brings forward the number divisible by 3.
Now, at the other end of the spectrum, I should be able to throw vast quantities of randomly generated test data at it and make sure that the algorithm scales. Neither of those was going to be easy as long as the code was tied to Canvas and shapes.
And so, I admitted to Crusty that he was right and started making this non-generic bringForward into a generic one.
The first step was to decouple it from Canvas and move it to arrays of shapes.
Of course, this array is the shape, so I had to replace shapes with self, and then I decoupled it from selection by passing a predicate indicating whether a given shape should be brought forward.
And everything kept compiling. Awesome! At that point, I was pleased to find there were no dependencies left on shape, and I could just delete the where clause. Pretty cool, I thought. Now, I can bring forward on any array.
I looked over at Crusty, who had been quietly practicing the cha-cha-cha in the corner, but he didn't seem to think I was finished.
"What does bring forward have to do with arrays?" he asked. "Well, nothing," I sighed and started thinking about how to remove this dependency.
Let's see, there's a stable partition here, which requires mutable collection conformance. So, maybe I'll just move it to mutable collection. Hmm. I thought, clearly the index type doesn't match Int. Okay. So, there's a simple fix for this, right? Have you done this? Don't do this.
It compiled, but Crusty had suddenly stopped dancing, and I knew something was wrong. "What?" I said. "Rookies always do that," said Crusty, shaking his head.
"First, you got that comparison with 0, which is going to be wrong for array slice. So, did you know that array slices, their indices don't start at 0? The indices of all slices start with the corresponding index in the underlying collection that they were sliced from. That relationship is critical if you want to be able to compose generic algorithms using slices, so it's really important." Well, this problem, I knew to fix. Just compare it with start index.
But the real problem is "What does bringForward have to do with having integer indices?" I interrupted. "Yeah, I know." "Well, I do have to get the index before i, which I can do with subtraction." Crusty just sighed and broke out the lozenges again.
And then, he laid two fingers down on the desk and walked them across until his right hand was pointing at the first green lozenge. "Not a backwards step in the whole dance," he said. And I realized that Crusty had just shown me a new algorithm.
Let's call that one indexBeforeFirst.
"Now, the trick here is to keep your focus by assuming somebody already wrote it for you." And he proceeded to hack away all the code that we didn't need, like that and that.
"Predecessor is the index before the first one where the predicate is satisfied.
Now, just look how pretty that reads." Now, if you look at it, you can see that he's right.
Taking away all the irrelevant detail about shapes, selections, arrays, and integers had left me with clearer code because it only traffics in the essentials of the problem. "I already showed you how indexBeforeFirst works. See if you could write it," he said. So, I think I was starting to catch on now because I got it right the first time. I told you, I'm a superfast typist. All right. So, return the first index whose successor matches the predicate. I was pretty excited about how well this was going.
"All right, Crusty," I said, "let's do the next one." "Ain't you forgetting something, Bonkey?" he asked. I didn't know what he was talking about. The code was clean, and it worked.
"Semantics, son. How am I supposed to use these from other code if I don't know what they mean?" And that's when I realized every time we'd use the new algorithm, we had leaned on his documentation to draw conclusions about the meaning and efficiency of our own code.
And because most algorithms are built out of other algorithms, they lean on the same thing. Recently, I was interviewing a perspective intern and asked him about the role of documentation, and he began with a phrase I won't forget. "Oh, it's incredibly important," he said.
"We're building these towers of abstraction," and now I'm paraphrasing, "the reason we can build without constantly inspecting the layers below us is that the parts that we build on are documented." Now, as an app developer, you are working at the very top of a tower that stretches through your system frameworks, DOS, and into the hardware, which rests on the laws of physics.
But as soon as you call one of your own methods, it becomes part of your foundation; so, document your code. The intern was hired, by the way, and he's sitting right there. So, I took the hint and documented Crusty's new algorithm, which meant that we could forget about the implementation and just use it, knowing that Quick Help had everything that we needed.
Now, I also documented bringForward.
Cool! Now, because it seemed to be solving all of my problems, at this point, I was really curious to see what was going on inside stablePartition.
It turns out I was well rewarded because it's a really beautiful and instructive algorithm.
The public method gets the collections count and passes it on to this helper, which uses a divide and conquer strategy.
So, first, it takes care of the base cases when the count is less than 2, we're done. We just need to figure out whether the partition point is at the beginning or at the end of the collection. Next, we divide the collection in two.
Now, at this point, you have to temporarily take it on faith that the algorithm works because we're going to stable partition the left half and the right half. Now, if you take a look at these two ends, you can see that everything is exactly in the right place, but this center section has two parts that need to be exchanged.
Now, they won't always have the same length as they do in this example, and fortunately there's an algorithm for that. We call it rotate. Okay.
I'm not going to go into rotate here, but it's actually quite beautiful, and if you're interested, you can find its implementation in the same file as stable partitions. Okay.
Back to shapes.
Now, this mess implemented the dragging in the shapes list, and it had always been one of my most complicated and buggy operations.
The strategy had been to allocate the temporary buffer; then, loop over the shapes before the insertion point, extracting the selected ones and adjusting the insertion point, and then separately loop over the rest of the shapes without adjusting the insertion point, extracting the selected ones. And then, finally, reinsert them.
Honestly, I was a little scared to touch the code because I thought I finally had it right. It had been almost a week since the last time I discovered a new bug. But I had gotten pretty good at this process now, so I tried visualizing the operation happening all at once. Hey, that looks familiar. Let's see it again. Hmm.
Suppose we do this first, and then take care of the parts separately.
That's right. This is just two stable partitions with inverted predicates. So, the generic algorithm collapsed down to this two-liner, and here's what's left in canvas. Now, let's just see that next to the old code.
That's not bad, but we got a reusable efficient documented general purpose algorithm out of it, which is spectacular. Okay.
So, this is a learned skill to look past the details that are specific to your application domain, see what your code is doing fundamentally, and capture that in reusable generic code. It takes practice.
So, why bother? Well, the practical answer is that because they're decoupled from those irrelevant details, generic algorithms are more reusable, testable, and even clearer than their non-generic counterparts. But I also think it's just deeply rewarding for anyone that really loves programming.
It's a search for truth and beauty but not some abstract untouchable truth because the constraints of actual hardware keep you honest.
As Crusty likes to say, "Programming reveals the real." So, treat your computation as a first class citizen with all the rights and obligations that you take seriously for types and application architecture. Identify it, give it a name, unit test it, and document its semantics and performance. Now, I want to close by putting this advice you saw from Shawn Perin in its full context. "If you want to improve the code quality in your organization, replace all of your coding standards with one goal, No Raw Loops." Thank you. [ Applause ]
-